Keandalan di Azure Event Hubs
Artikel ini menjelaskan dukungan keandalan di Azure Event Hubs, dan mencakup ketahanan intra-regional dengan zona ketersediaan dan pemulihan bencana lintas wilayah dan kelangsungan bisnis. Untuk gambaran umum yang lebih rinci tentang prinsip keandalan di Azure, lihat Keandalan Azure.
Dukungan zona ketersediaan
Zona ketersediaan Azure adalah setidaknya tiga grup pusat data yang terpisah secara fisik dalam setiap wilayah Azure. Pusat data dalam setiap zona dilengkapi dengan infrastruktur daya, pendinginan, dan jaringan independen. Dalam kasus kegagalan zona lokal, zona ketersediaan dirancang sehingga jika satu zona terpengaruh, layanan regional, kapasitas, dan ketersediaan tinggi didukung oleh dua zona yang tersisa.
Kegagalan dapat berkisar dari kegagalan perangkat lunak dan perangkat keras hingga peristiwa seperti gempa bumi, banjir, dan kebakaran. Toleransi terhadap kegagalan dicapai dengan redundansi dan isolasi logis layanan Azure. Untuk informasi selengkapnya tentang zona ketersediaan di Azure, lihat Wilayah dan zona ketersediaan.
Layanan berkemampuan zona ketersediaan Azure dirancang untuk memberikan tingkat keandalan dan fleksibilitas yang tepat. Mereka dapat dikonfigurasi dalam dua cara. Mereka dapat berupa zona redundan,dengan replikasi otomatis di seluruh zona, atau zonal, dengan instans yang disematkan ke zona tertentu. Anda juga dapat menggabungkan pendekatan ini. Untuk informasi selengkapnya tentang arsitektur zonal vs. zona-redundan, lihat Rekomendasi untuk menggunakan zona dan wilayah ketersediaan.
Azure Event Hubs menerapkan deteksi kegagalan transparan dan mekanisme failover sehingga, ketika kegagalan terjadi, layanan terus beroperasi dalam tingkat layanan yang terjaga dan tanpa gangguan yang nyata. Jika Anda membuat namespace Layanan Pusat Aktivitas di wilayah yang mendukung zona ketersediaan, redundansi zona diaktifkan secara otomatis. Dengan redundansi zona, toleransi kesalahan ditingkatkan dan layanan memiliki cadangan kapasitas yang cukup untuk mengatasi pemadaman seluruh fasilitas. Metadata dan data (peristiwa) direplikasi di seluruh pusat data di setiap zona.
Prasyarat
Dukungan zona ketersediaan hanya tersedia di wilayah Azure dengan zona ketersediaan.
Membuat sumber daya dengan zona ketersediaan diaktifkan
Saat Anda menggunakan portal Azure, redundansi zona diaktifkan secara otomatis. Saat membuat namespace, Anda akan melihat pesan yang disorot berikut saat memilih wilayah yang mendukung zona ketersediaan.
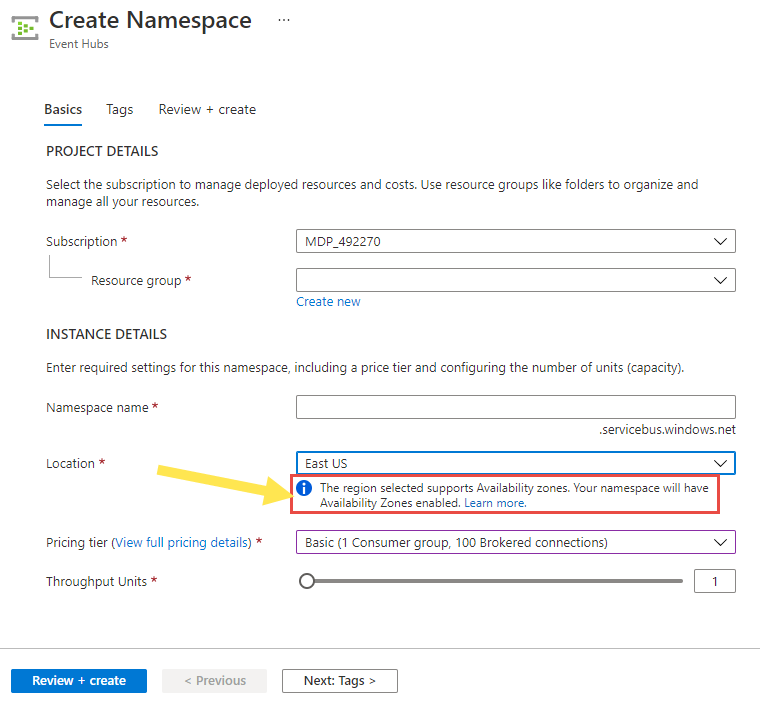
Menonaktifkan zona ketersediaan
portal Azure tidak mendukung penonaktifan zona ketersediaan. Untuk menonaktifkan zona ketersediaan, gunakan salah satu metode berikut:
Perintah
az eventhubs namespaceAzure CLI dengan--zone-redundant=falsePerintah
New-AzEventHubNamespacePowerShell dengan-ZoneRedundant=falseuntuk membuat namespace dengan redundansi zona dinonaktifkan.
Migrasi zona ketersediaan
Saat Anda membuat zona ketersediaan di wilayah yang mendukungnya, zona ketersediaan diaktifkan secara otomatis. Jika Anda ingin mempelajari cara memindahkan namespace layanan Azure Event Hubs ke wilayah baru yang mendukung zona ketersediaan, lihat Merelokasi Azure Event Hubs ke wilayah lain.
Pemulihan bencana lintas wilayah dan kelangsungan bisnis
Pemulihan bencana (DR) adalah tentang pemulihan dari peristiwa berdampak tinggi, seperti bencana alam atau penyebaran gagal yang mengakibatkan waktu henti dan kehilangan data. Terlepas dari penyebabnya, obat terbaik untuk bencana adalah rencana DR yang terdefinisi dan teruji dengan baik dan desain aplikasi yang secara aktif mendukung DR. Sebelum Anda mulai berpikir tentang membuat rencana pemulihan bencana Anda, lihat Rekomendasi untuk merancang strategi pemulihan bencana.
Ketika datang ke DR, Microsoft menggunakan model tanggung jawab bersama. Dalam model tanggung jawab bersama, Microsoft memastikan bahwa infrastruktur dasar dan layanan platform tersedia. Pada saat yang sama, banyak layanan Azure tidak secara otomatis mereplikasi data atau mundur dari wilayah yang gagal untuk mereplikasi silang ke wilayah lain yang diaktifkan. Untuk layanan tersebut, Anda bertanggung jawab untuk menyiapkan rencana pemulihan bencana yang berfungsi untuk beban kerja Anda. Sebagian besar layanan yang berjalan pada penawaran platform as a service (PaaS) Azure menyediakan fitur dan panduan untuk mendukung DR dan Anda dapat menggunakan fitur khusus layanan untuk mendukung pemulihan cepat untuk membantu mengembangkan rencana DR Anda.
Model kluster Azure Event Hubs yang aktif dengan dukungan zona ketersediaan memberikan ketahanan terhadap pemadaman perangkat keras dan pusat data. Namun, jika bencana di mana seluruh wilayah dan semua zona tidak tersedia, Anda dapat menggunakan pemulihan bencana geografis untuk memulihkan beban kerja dan konfigurasi aplikasi Anda.
Ada dua fitur yang menyediakan pemulihan bencana geografis di Azure Event Hubs.
Pemulihan bencana geografis (Metadata DR), yang hanya menyediakan replikasi hanya metadata.
Pemulihan Geo-Disaster memastikan bahwa seluruh konfigurasi namespace layanan (Azure Event Hubs, Grup Konsumen, dan pengaturan) terus direplikasi dari namespace utama ke namespace layanan sekunder saat dipasangkan.
Fitur pemulihan bencana Geo Azure Service Bus adalah solusi pemulihan bencana. Konsep dan alur kerja yang dijelaskan dalam artikel ini berlaku untuk skenario bencana, dan bukan untuk pemadaman sementara. Untuk diskusi terperinci tentang pemulihan bencana di Microsoft Azure, lihat artikel ini.
Dengan pemulihan Geo-Disaster, Anda dapat memulai perpindahan failover sekali-saja dari primer ke sekunder kapan saja. Pemindahan failover menunjuk nama alias yang dipilih untuk namespace ke namespace sekunder. Setelah pemindahan, pemasangan kemudian dihapus. Failover hampir dijalankan seketika setelah dimulai.
Untuk informasi terperinci, sampel, dan dokumentasi lebih lanjut, tentang pemulihan Bencana Geografis di Azure Event Hubs, lihat Azure Event Hubs - Pemulihan bencana geografis.
Replikasi geografis (pratinjau publik), yang menyediakan replikasi metadata dan data, mereplikasi informasi konfigurasi dan semua data dari namespace utama ke satu, atau beberapa namespace sekunder. Ketika failover dilakukan, sekunder yang dipilih menjadi primer dan primer sebelumnya menjadi sekunder. Pengguna dapat melakukan failover kembali ke primer asli jika diinginkan.
Untuk informasi terperinci, sampel, dan dokumentasi lebih lanjut, tentang Replikasi geografis di Azure Event Hubs, lihat Replikasi geografis .