Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Anda dapat memigrasikan data dari penyimpanan HDFS lokal kluster Hadoop Anda ke Azure Storage (penyimpanan blob atau Data Lake Storage) dengan menggunakan perangkat Data Box. Anda dapat memilih dari Data Box Disk, Data Box dengan kapasitas 80, 120, atau 525 TiB, atau Data Box Heavy 770 TiB.
Artikel ini membantu Anda menyelesaikan tugas-tugas ini:
- Bersiap untuk memigrasikan data Anda
- Menyalin data Anda ke Data Box Disk, Data Box, atau perangkat Data Box Heavy
- Kirim perangkat kembali ke Microsoft
- Menerapkan izin akses ke file dan direktori (hanya Data Lake Storage)
Prasyarat
Anda memerlukan hal-hal ini untuk menyelesaikan migrasi.
Akun Azure Storage.
Kluster Hadoop lokal yang berisi data sumber Anda.
Perangkat Azure Data Box.
Pesanlah Data Box atau Data Box Heavy milik Anda.
Kabel dan sambungkan Data Box atau Data Box Heavy Anda ke jaringan lokal.
Jika Anda siap, mari kita mulai.
Menyalin data Anda ke perangkat Data Box
Jika data Anda cocok dengan satu perangkat Data Box, maka Anda menyalin data ke perangkat Data Box.
Jika ukuran data Anda melebihi kapasitas perangkat Data Box, gunakan prosedur opsional untuk membagi data di beberapa perangkat Data Box lalu lakukan langkah ini.
Untuk menyalin data dari penyimpanan HDFS lokal Anda ke perangkat Data Box, Anda mengatur beberapa hal, lalu menggunakan alat DistCp .
Ikuti langkah-langkah ini untuk menyalin data melalui REST API penyimpanan Blob/Object ke perangkat Data Box Anda. Antarmuka REST API membuat perangkat muncul sebagai penyimpanan HDFS ke kluster Anda.
Sebelum menyalin data melalui REST, identifikasi protokol keamanan dan koneksi yang diperlukan untuk terhubung ke antarmuka REST pada Data Box atau Data Box Heavy. Masuk ke antarmuka pengguna web lokal Data Box dan buka halaman Sambungkan dan salin . Untuk akun penyimpanan Azure untuk perangkat Anda, di bawah pengaturan akses, temukan dan pilih REST.
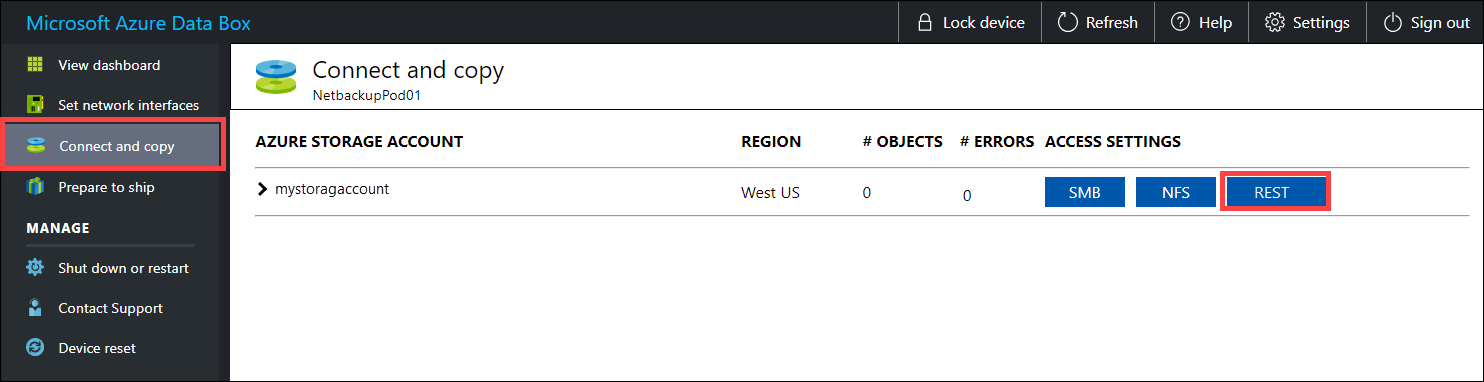
Dalam dialog Akses akun penyimpanan dan unggah data, salin titik akhir layanan Blob dan kunci akun Penyimpanan. Dari titik akhir layanan blob, hilangkan
https://dan garis miring di akhir.Dalam hal ini, titik akhirnya adalah:
https://mystorageaccount.blob.mydataboxno.microsoftdatabox.com/. Bagian host dari URI yang Anda gunakan adalah:mystorageaccount.blob.mydataboxno.microsoftdatabox.com. Misalnya, lihat cara Menyambungkan ke REST melalui http.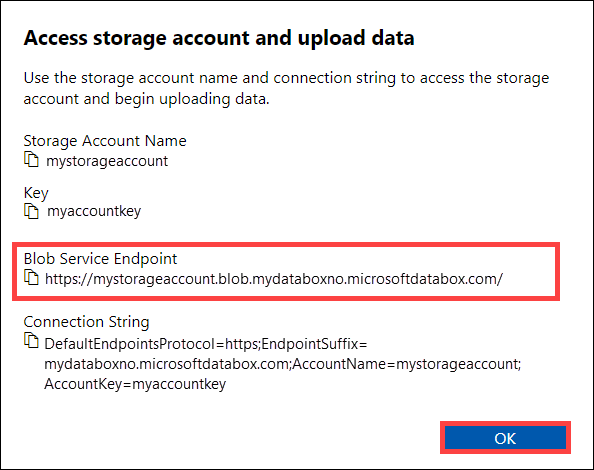
Tambahkan titik akhir dan alamat IP simpul Data Box atau Data Box Heavy ke
/etc/hostspada setiap simpul.10.128.5.42 mystorageaccount.blob.mydataboxno.microsoftdatabox.comJika Anda menggunakan beberapa mekanisme lain untuk DNS, Anda harus memastikan bahwa titik akhir Data Box dapat diselesaikan.
Atur variabel shell
azjarske lokasi file jarhadoop-azuredanazure-storage. Anda dapat menemukan file-file ini di bawah direktori penginstalan Hadoop.Untuk menentukan apakah file-file ini ada, gunakan perintah berikut:
ls -l $<hadoop_install_dir>/share/hadoop/tools/lib/ | grep azure. Ganti tempat penampung<hadoop_install_dir>dengan jalur ke direktori tempat Anda menginstal Hadoop. Pastikan untuk menggunakan jalur yang sepenuhnya memenuhi syarat.Contoh:
azjars=$hadoop_install_dir/share/hadoop/tools/lib/hadoop-azure-2.6.0-cdh5.14.0.jarazjars=$azjars,$hadoop_install_dir/share/hadoop/tools/lib/microsoft-windowsazure-storage-sdk-0.6.0.jarBuat kontainer penyimpanan yang ingin Anda gunakan untuk salinan data. Anda juga harus menentukan direktori tujuan sebagai bagian dari perintah ini. Ini bisa menjadi direktori tujuan sementara saat ini.
hadoop fs -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint>=<account_key> \ -mkdir -p wasb://<container_name>@<blob_service_endpoint>/<destination_directory>Ganti placeholder
<blob_service_endpoint>dengan nama titik akhir layanan blob Anda.<account_key>Ganti tempat penampung dengan kunci akses akun Anda.<container-name>Ganti tempat penampung dengan nama kontainer Anda.<destination_directory>Ganti tempat penampung dengan nama direktori yang ingin Anda salin datanya.
Jalankan perintah daftar untuk memastikan bahwa kontainer dan direktori Anda dibuat.
hadoop fs -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint>=<account_key> \ -ls -R wasb://<container_name>@<blob_service_endpoint>/Ganti placeholder
<blob_service_endpoint>dengan nama titik akhir layanan blob Anda.<account_key>Ganti tempat penampung dengan kunci akses akun Anda.<container-name>Ganti tempat penampung dengan nama kontainer Anda.
Salin data dari Hadoop HDFS ke penyimpanan Blob Data Box, ke dalam kontainer yang Anda buat sebelumnya. Jika direktori yang Anda salin tidak ditemukan, perintah akan membuatnya secara otomatis.
hadoop distcp \ -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint<>=<account_key> \ -filters <exclusion_filelist_file> \ [-f filelist_file | /<source_directory> \ wasb://<container_name>@<blob_service_endpoint>/<destination_directory>Ganti placeholder
<blob_service_endpoint>dengan nama titik akhir layanan blob Anda.<account_key>Ganti tempat penampung dengan kunci akses akun Anda.<container-name>Ganti tempat penampung dengan nama kontainer Anda.<exclusion_filelist_file>Ganti tempat penampung dengan nama file yang berisi daftar pengecualian file Anda.<source_directory>Ganti tempat penampung dengan nama direktori yang berisi data yang ingin Anda salin.<destination_directory>Ganti tempat penampung dengan nama direktori yang ingin Anda salin datanya.
Opsi
-libjarsdigunakan untuk membuathadoop-azure*.jardan file dependenazure-storage*.jartersedia untukdistcp. Ini mungkin sudah terjadi untuk beberapa kluster.Contoh berikut menunjukkan bagaimana
distcpperintah digunakan untuk menyalin data.hadoop distcp \ -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.mystorageaccount.blob.mydataboxno.microsoftdatabox.com=myaccountkey \ -filter ./exclusions.lst -f /tmp/copylist1 -m 4 \ /data/testfiles \ wasb://hdfscontainer@mystorageaccount.blob.mydataboxno.microsoftdatabox.com/dataUntuk meningkatkan kecepatan penyalinan:
Coba ubah jumlah pemeta. (Jumlah default pemeta adalah 20. Contoh di atas menggunakan
m= 4 pemeta.)Coba
-D fs.azure.concurrentRequestCount.out=<thread_number>. Gantilah<thread_number>dengan jumlah utas untuk setiap mapper. Produk dari jumlah pemeta dan jumlah thread per pemeta,m*<thread_number>, tidak boleh melebihi 32.Coba jalankan beberapa
distcpsecara paralel.Ingatlah bahwa file besar berkinerja lebih baik daripada file kecil.
Jika Anda memiliki file yang lebih besar dari 200 GB, sebaiknya ubah ukuran blok menjadi 100 MB dengan parameter berikut:
hadoop distcp \ -libjars $azjars \ -Dfs.azure.write.request.size= 104857600 \ -Dfs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -Dfs.azure.account.key.<blob_service_endpoint<>=<account_key> \ -strategy dynamic \ -Dmapreduce.map.memory.mb=16384 \ -Dfs.azure.concurrentRequestCount.out=8 \ -Dmapreduce.map.java.opts=-Xmx8196m \ -m 4 \ -update \ /data/bigfile wasb://hadoop@mystorageaccount.blob.core.windows.net/bigfile
Mengirim Data Box ke Microsoft
Ikuti langkah-langkah ini untuk menyiapkan dan mengirimkan perangkat Data Box ke Microsoft.
Pertama, Bersiaplah untuk mengirim di Data Box atau Data Box Heavy Anda.
Setelah persiapan perangkat selesai, unduh file BOM. Anda menggunakan BOM atau file manifes ini nanti untuk memverifikasi data yang diunggah ke Azure.
Matikan perangkat dan lepaskan kabel.
Jadwalkan penjemputan dengan UPS.
Untuk perangkat Data Box, lihat Mengirim Data Box Anda.
Untuk perangkat Data Box Heavy, lihat Kirim Data Box Heavy Anda.
Setelah Microsoft menerima perangkat Anda, perangkat tersambung ke jaringan pusat data, dan data diunggah ke akun penyimpanan yang Anda tentukan saat Anda melakukan pemesanan perangkat. Verifikasi terhadap file BOM bahwa semua data Anda diunggah ke Azure.
Menerapkan izin akses ke file dan direktori (hanya Data Lake Storage)
Anda sudah memiliki data ke akun Azure Storage Anda. Sekarang Anda menerapkan izin akses ke file dan direktori.
Nota
Langkah ini diperlukan hanya jika Anda menggunakan Azure Data Lake Storage sebagai penyimpanan data Anda. Jika Anda hanya menggunakan akun penyimpanan blob tanpa namespace hierarkis sebagai penyimpanan data, Anda dapat melewati bagian ini.
Buat perwakilan layanan untuk akun Azure Data Lake Storage Anda yang diaktifkan
Untuk membuat perwakilan layanan, lihat Cara: Menggunakan portal untuk membuat aplikasi Microsoft Entra dan perwakilan layanan yang dapat mengakses sumber daya.
Saat melakukan langkah-langkah di bagian Tetapkan aplikasi ke peran di artikel, pastikan untuk menetapkan peran Kontributor Data Blob Penyimpanan ke perwakilan layanan.
Saat melakukan langkah-langkah di bagian Dapatkan nilai untuk masuk di artikel, simpan ID aplikasi, dan nilai rahasia klien ke dalam file teks. Kau membutuhkannya segera.
Membuat daftar file yang disalin dengan izinnya
Dari kluster Hadoop lokal, jalankan perintah ini:
sudo -u hdfs ./copy-acls.sh -s /{hdfs_path} > ./filelist.json
Perintah ini menghasilkan daftar file yang disalin dengan izinnya.
Nota
Bergantung pada jumlah file dalam HDFS, perintah ini dapat memakan waktu lama untuk dijalankan.
Membuat daftar identitas dan memetakannya ke identitas Microsoft Entra
Unduh
copy-acls.pyskrip. Lihat bagian Unduh skrip pembantu dan siapkan simpul tepi Anda untuk menjalankannya di artikel ini.Jalankan perintah ini untuk menghasilkan daftar identitas unik.
./copy-acls.py -s ./filelist.json -i ./id_map.json -gSkrip ini menghasilkan file bernama
id_map.jsonyang berisi identitas yang harus Anda sesuaikan dengan identitas berbasis ADD.Buka file
id_map.jsondi editor teks.Untuk setiap objek JSON yang muncul dalam file, perbarui
targetatribut Nama Prinsipal (UPN) pengguna Microsoft Entra atau ObjectId (OID), dengan identitas yang dipetakan yang sesuai. Setelah selesai, simpan file. Anda akan memerlukan file ini di langkah berikutnya.
Terapkan izin ke file yang disalin dan terapkan pemetaan identitas
Jalankan perintah ini untuk menerapkan izin ke data yang Anda salin ke akun yang diaktifkan Data Lake Storage:
./copy-acls.py -s ./filelist.json -i ./id_map.json -A <storage-account-name> -C <container-name> --dest-spn-id <application-id> --dest-spn-secret <client-secret>
Ganti
<storage-account-name>placeholder dengan nama akun penyimpanan.<container-name>Ganti tempat penampung dengan nama kontainer Anda.Ganti tempat penampung
<application-id>dan<client-secret>dengan ID aplikasi dan rahasia klien yang Anda kumpulkan saat membuat perwakilan layanan.
Lampiran: Memisahkan data di beberapa perangkat Data Box
Sebelum memindahkan data ke perangkat Data Box, Anda perlu mengunduh beberapa skrip pembantu, memastikan bahwa data Anda diatur agar pas ke perangkat Data Box, dan mengecualikan file yang tidak perlu.
Unduh skrip bantu dan siapkan simpul tepi Anda agar dapat menjalankannya
Dari simpul tepi atau kepala kluster Hadoop lokal Anda, jalankan perintah ini:
git clone https://github.com/jamesbak/databox-adls-loader.git cd databox-adls-loaderPerintah ini mengkloning repositori GitHub yang berisi skrip pembantu.
Pastikan bahwa paket jq terinstal di komputer lokal Anda.
sudo apt-get install jqInstal paket python Permintaan .
pip install requestsAtur izin eksekusi pada skrip yang diperlukan.
chmod +x *.py *.sh
Pastikan data Anda diatur agar pas ke perangkat Data Box
Jika ukuran data Anda melebihi ukuran satu perangkat Data Box, Anda dapat membagi file menjadi grup yang dapat Anda simpan ke beberapa perangkat Data Box.
Jika data Anda tidak melebihi ukuran satu perangkat Data Box, Anda dapat melanjutkan ke bagian berikutnya.
Dengan izin yang ditingkatkan, jalankan
generate-file-listskrip yang Anda unduh dengan mengikuti panduan di bagian sebelumnya.Berikut adalah deskripsi parameter perintah:
sudo -u hdfs ./generate-file-list.py [-h] [-s DATABOX_SIZE] [-b FILELIST_BASENAME] [-f LOG_CONFIG] [-l LOG_FILE] [-v {DEBUG,INFO,WARNING,ERROR}] path where: positional arguments: path The base HDFS path to process. optional arguments: -h, --help show this help message and exit -s DATABOX_SIZE, --databox-size DATABOX_SIZE The size of each Data Box in bytes. -b FILELIST_BASENAME, --filelist-basename FILELIST_BASENAME The base name for the output filelists. Lists will be named basename1, basename2, ... . -f LOG_CONFIG, --log-config LOG_CONFIG The name of a configuration file for logging. -l LOG_FILE, --log-file LOG_FILE Name of file to have log output written to (default is stdout/stderr) -v {DEBUG,INFO,WARNING,ERROR}, --log-level {DEBUG,INFO,WARNING,ERROR} Level of log information to output. Default is 'INFO'.Salin daftar file yang dihasilkan ke HDFS sehingga dapat diakses oleh pekerjaan DistCp .
hadoop fs -copyFromLocal {filelist_pattern} /[hdfs directory]
Mengecualikan file yang tidak perlu
Ada beberapa direktori yang perlu dikecualikan dari tugas DisCp. Misalnya, kecualikan direktori yang berisi informasi status yang menjaga kluster tetap berjalan.
Pada kluster Hadoop lokal tempat Anda berencana untuk memulai pekerjaan DistCp, buat file yang menentukan daftar direktori yang ingin Anda kecualikan.
Berikut adalah sebuah contoh:
.*ranger/audit.*
.*/hbase/data/WALs.*
Langkah selanjutnya
Pelajari cara kerja Data Lake Storage dengan kluster HDInsight. Untuk informasi selengkapnya, lihat Menggunakan Azure Data Lake Storage dengan Azure HDInsight kluster.