Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Azure Synapse Analytics menawarkan berbagai mesin analitik untuk membantu Anda menyerap, mengubah, memodelkan, menganalisis, dan melayani data Anda. Kumpulan Apache Spark menawarkan kemampuan komputasi big data sumber terbuka. Setelah Anda membuat kumpulan Apache Spark di ruang kerja Synapse Anda, data dapat dimuat, dimodelkan, diproses, dan dilayani untuk mendapatkan wawasan.
Panduan cepat ini menjelaskan langkah-langkah untuk membuat kumpulan Apache Spark di ruang kerja Synapse dengan Synapse Studio.
Important
Penagihan untuk instans Spark diprorata per menit, terlepas apakah digunakan atau tidak. Pastikan Anda mematikan instans Spark setelah selesai menggunakannya, atau atur waktu jangka pendek. Untuk informasi selengkapnya, lihat bagian Membersihkan sumber daya di artikel ini.
Note
Synapse Studio akan terus mendukung file konfigurasi berbasis terraform atau bicep.
Jika Anda tidak memiliki langganan Azure, buat akun gratis sebelum Anda memulai.
Prerequisites
- Anda akan memerlukan langganan Azure. Jika diperlukan, buat akun Azure gratis
- Anda akan menggunakan Synapse workspace.
Masuk ke portal Microsoft Azure
Masuk ke portal Microsoft Azure.
Mengarahkan ke ruang kerja Synapse
Navigasi ke workspace Synapse tempat pool Apache Spark akan dibuat dengan mengetik nama layanan (atau nama sumber daya secara langsung) ke bilah pencarian.
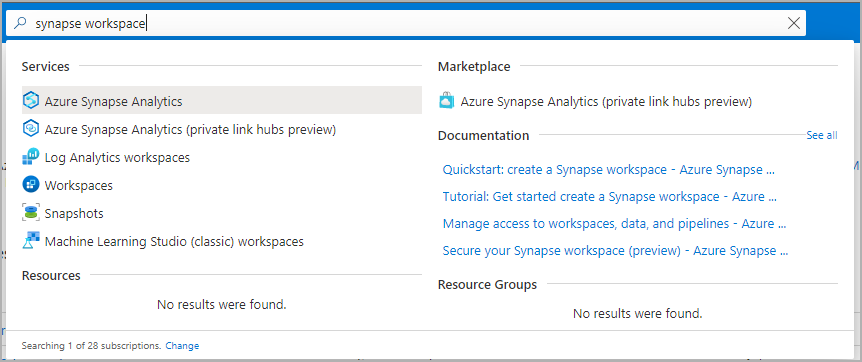
Dari daftar ruang kerja, ketik nama (atau bagian dari nama) ruang kerja untuk membukanya. Untuk contoh ini, kami menggunakan ruang kerja bernama contosoanalytics.
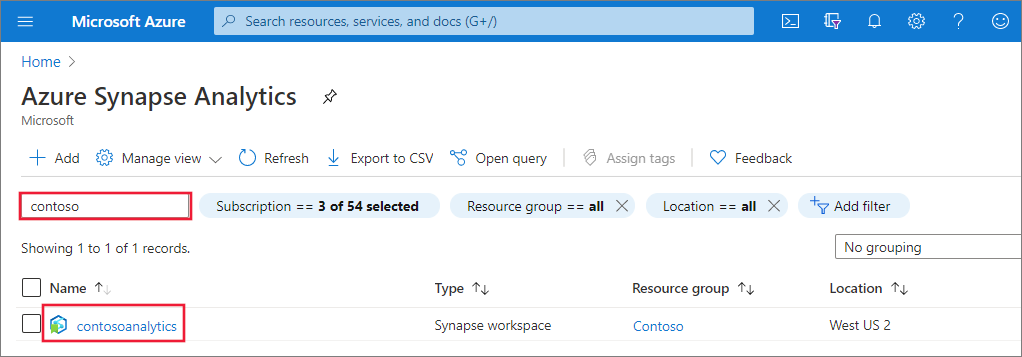


Luncurkan Synapse Studio
Dari gambaran umum ruang kerja, pilih URL web Ruang Kerja untuk membuka Synapse Studio.

Membuat kumpulan Apache Spark di Synapse Studio
Important
Azure Synapse Runtime untuk Apache Spark 2.4 telah ditolak dan secara resmi tidak didukung sejak September 2023. Mengingat Spark 3.1 dan Spark 3.2 juga Merupakan Akhir Dukungan yang diumumkan, kami sarankan pelanggan bermigrasi ke Spark 3.3.
Pada beranda Synapse Studio, navigasikan ke Hub Manajemen di navigasi kiri dengan memilih ikon Kelola .
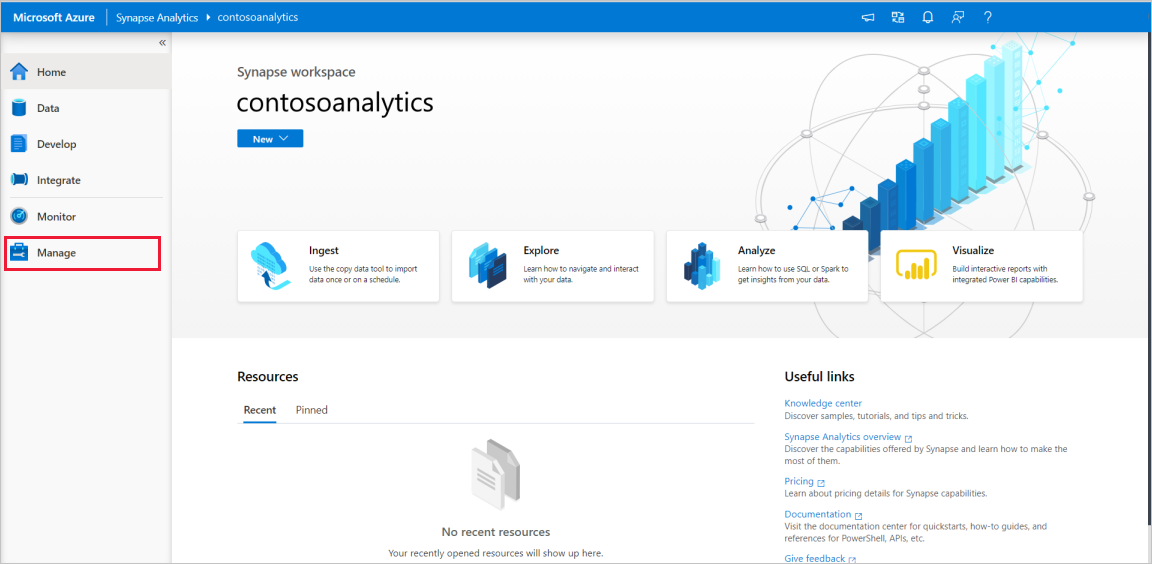
Setelah berada di Hub Manajemen, navigasikan ke bagian kumpulan Apache Spark untuk melihat daftar kumpulan Apache Spark saat ini yang tersedia di ruang kerja.

Pilih + Baru dan wizard untuk membuat kumpulan Apache Spark baru akan muncul.
Masukkan detail berikut ini pada tab Dasar:
Setting Nilai yang disarankan Description Nama kumpulan Apache Spark Nama kumpulan yang valid, seperti contososparkIni adalah nama yang akan dimiliki oleh kumpulan Apache Spark. Ukuran simpul Kecil (4 vCPU / 32 GB) Atur ke ukuran terkecil untuk mengurangi biaya pada panduan cepat ini Autoscale Disabled Kita tidak akan membutuhkan penyesuaian skala otomatis dalam panduan memulai cepat ini Jumlah simpul 8 Gunakan ukuran kecil untuk membatasi biaya dalam panduan memulai cepat ini Mengalokasikan pelaksana secara dinamis Disabled Pengaturan ini memetakan ke properti alokasi dinamis dalam konfigurasi Spark untuk alokasi eksekutor Aplikasi Spark. Kita tidak perlu skala otomatis dalam mulai cepat ini. 
Important
Ada batasan khusus untuk nama yang dapat digunakan kumpulan Apache Spark. Nama harus berisi huruf atau angka saja, harus 15 karakter atau kurang, harus dimulai dengan huruf, tidak berisi kata khusus, dan unik di ruang kerja.
Di tab berikutnya, Pengaturan tambahan, biarkan semua pengaturan sebagai default.
Pilih Tag. Pertimbangkan untuk menggunakan tag Azure. Misalnya, tag "Pemilik" atau "CreatedBy" untuk mengidentifikasi siapa yang membuat sumber daya, dan tag "Lingkungan" untuk mengidentifikasi apakah sumber daya ini berada di Produksi, Pengembangan, dll. Untuk informasi selengkapnya, lihat Mengembangkan strategi penamaan dan pemberian tag untuk sumber daya Azure. Setelah siap, pilih Tinjau + buat.
Di tab Tinjau + buat , pastikan detail terlihat benar berdasarkan apa yang dimasukkan sebelumnya, dan tekan Buat.

Kumpulan Apache Spark akan memulai proses penyediaan.
Setelah proses provisi selesai, kumpulan Apache Spark baru akan muncul dalam daftar.






Membersihkan sumber daya kumpulan Apache Spark menggunakan Synapse Studio
Langkah-langkah berikut menghapus kumpulan Apache Spark dari ruang kerja menggunakan Synapse Studio.
Warning
Menghapus kumpulan Spark akan menghapus mesin analitik dari ruang kerja. Tidak akan mungkin lagi terhubung ke kumpulan, dan semua kueri, alur, dan buku catatan yang menggunakan kumpulan Spark ini tidak akan berfungsi lagi.
Jika Anda ingin menghapus kumpulan Apache Spark, lakukan langkah-langkah berikut:
Navigasikan ke kumpulan Apache Spark di Hub Manajemen di Synapse Studio.
Pilih elipsis di samping kumpulan Apache yang akan dihapus (dalam hal ini, contosospark) untuk menampilkan perintah untuk kumpulan Apache Spark.

Pilih Hapus.
Konfirmasi penghapusan, dan tekan tombol Hapus .
Ketika proses tersebut telah berhasil, kumpulan Apache Spark tidak akan lagi terdaftar di sumber daya ruang kerja.
