Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Dalam panduan cepat ini, Anda mempelajari cara membuat kumpulan Apache Spark serverless di Azure Synapse menggunakan perangkat web. Anda kemudian belajar menyambungkan ke kumpulan Apache Spark dan menjalankan kueri Spark SQL terhadap file dan tabel. Apache Spark memungkinkan analitik data dan komputasi kluster yang cepat menggunakan pemrosesan dalam memori. Untuk informasi tentang Spark di Azure Synapse, lihat Gambaran Umum: Apache Spark di Azure Synapse.
Penting
Biaya untuk instans Spark dihitung secara prorata per menit, baik Anda menggunakannya atau tidak. Pastikan Anda mematikan instans Spark setelah selesai menggunakannya, atau atur waktu jangka pendek. Untuk informasi selengkapnya, lihat bagian Membersihkan sumber daya di artikel ini.
Jika Anda tidak memiliki langganan Azure, buat akun gratis sebelum Anda memulai.
Prasyarat
- Anda akan memerlukan langganan Azure. Jika diperlukan, buat akun Azure gratis
- Ruang kerja Synapse Analytics
- Kumpulan Apache Spark nirserver
Masuk ke portal Microsoft Azure
Masuk ke portal Azure.
Jika tidak memiliki langganan Azure, buat akun Azure gratis sebelum Anda memulai.
Membuat buku catatan
Notebook adalah lingkungan interaktif yang mendukung berbagai bahasa pemrograman. Notebook memungkinkan Anda berinteraksi dengan data Anda, menggabungkan kode dengan markdown, teks, dan melakukan visualisasi sederhana.
Dari tampilan portal Microsoft Azure untuk ruang kerja Azure Synapse yang ingin Anda gunakan, pilih Luncurkan Synapse Studio.
Setelah Synapse Studio diluncurkan, pilih Kembangkan. Kemudian, pilih ikon "+" untuk menambahkan sumber daya baru.
Dari sana, pilih Notebook. Buku catatan baru dibuat dan dibuka dengan nama yang dibuat secara otomatis.

Di jendela Properti , berikan nama untuk buku catatan.
Pada toolbar, klik Terbitkan.
Jika hanya ada satu kumpulan Apache Spark di ruang kerja Anda, maka kumpulan tersebut dipilih secara default. Gunakan menu drop-down untuk memilih kumpulan Apache Spark yang benar jika tidak ada yang dipilih.
Klik Tambahkan kode. Bahasa defaultnya adalah
Pyspark. Anda akan menggunakan campuran Pyspark dan Spark SQL, sehingga pilihan defaultnya baik-baik saja. Bahasa lain yang didukung adalah Scala dan .NET untuk Spark.Selanjutnya Anda membuat objek Spark DataFrame sederhana untuk memanipulasi. Dalam hal ini, Anda membuatnya dari kode. Ada tiga baris dan tiga kolom:
new_rows = [('CA',22, 45000),("WA",35,65000) ,("WA",50,85000)] demo_df = spark.createDataFrame(new_rows, ['state', 'age', 'salary']) demo_df.show()Sekarang jalankan sel menggunakan salah satu metode berikut:
Tekan SHIFT + ENTER.
Pilih ikon putar biru di sebelah kiri sel.
Pilih tombol Jalankan semua pada toolbar.
Jika instans kumpulan Apache Spark belum berjalan, instans tersebut akan dimulai secara otomatis. Anda dapat melihat status instans kumpulan Apache Spark di bawah sel yang Anda jalankan dan juga pada panel status di bagian bawah notebook. Bergantung pada ukuran kolam, memulai dibutuhkan waktu 2-5 menit. Setelah kode selesai berjalan, informasi di bawah sel menampilkan berapa lama waktu yang dibutuhkan untuk dijalankan dan eksekusinya. Pada sel output, Anda melihat keluarannya.
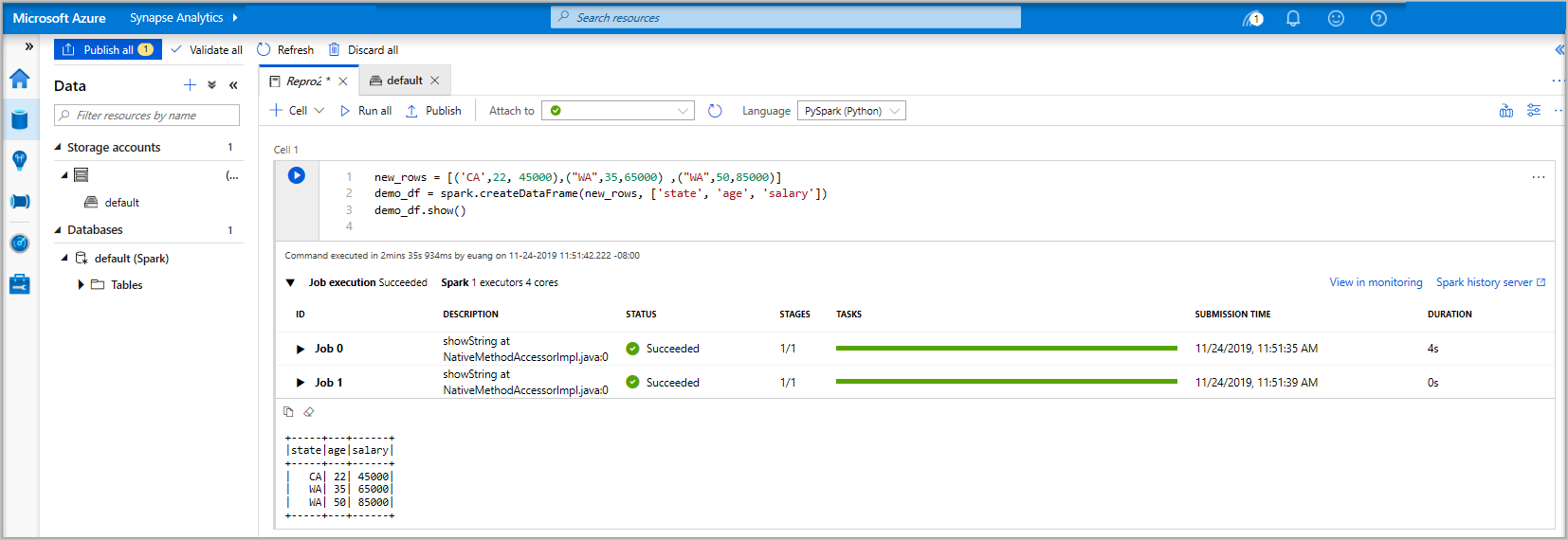
Data sekarang ada dalam DataFrame dari sana, Anda dapat menggunakan data dengan berbagai cara. Anda akan membutuhkannya dalam format yang berbeda untuk bagian selanjutnya dari panduan ringkas ini.
Masukkan kode di bawah ini di sel lain dan jalankan, ini membuat tabel Spark, CSV, dan file Parquet semuanya dengan salinan data:
demo_df.createOrReplaceTempView('demo_df') demo_df.write.csv('demo_df', mode='overwrite') demo_df.write.parquet('abfss://<<TheNameOfAStorageAccountFileSystem>>@<<TheNameOfAStorageAccount>>.dfs.core.windows.net/demodata/demo_df', mode='overwrite')Jika Anda menggunakan penjelajah penyimpanan, dimungkinkan untuk melihat dampak dari dua cara berbeda untuk menulis file yang digunakan di atas. Ketika tidak ada sistem file yang ditentukan maka default digunakan, dalam hal
default>user>trusted-service-user>demo_dfini . Data disimpan ke lokasi sistem file yang ditentukan.Perhatikan bahwa dalam format "csv" dan "parquet", operasi tulis akan membuat direktori dengan banyak file yang dipartisi.


Menjalankan pernyataan Spark SQL
Bahasa Kueri Terstruktur (SQL) adalah bahasa yang paling umum dan banyak digunakan untuk mengkueri dan menentukan data. Spark SQL berfungsi sebagai ekstensi untuk Apache Spark guna memproses data terstruktur, menggunakan sintaksis SQL yang sudah diketahui.
Tempelkan kode berikut dalam sel kosong, lalu jalankan kode. Perintah mencantumkan tabel pada pool.
%%sql SHOW TABLESSaat Anda menggunakan Notebook dengan pool Apache Spark di Azure Synapse, Anda mendapatkan preset
sqlContextyang dapat Anda gunakan untuk menjalankan kueri menggunakan Spark SQL.%%sqlmenginstruksikan notebook untuk menggunakan prasetelsqlContextuntuk menjalankan kueri. Kueri mengambil 10 baris teratas dari tabel sistem yang tersedia di semua kumpulan Apache Spark Azure Synapse secara default.Jalankan kueri lain untuk melihat data dalam
demo_df.%%sql SELECT * FROM demo_dfKode menghasilkan dua sel output, satu yang berisi hasil data yang lain, yang menunjukkan tampilan pekerjaan.
Secara default tampilan hasil memperlihatkan kisi. Tapi, ada pengalih tampilan di bawah kisi yang memungkinkan tampilan beralih antara tampilan kisi dan grafik.

Di pengalih Tampilan , pilih Bagan.
Pilih ikon Opsi tampilan dari paling kanan.
Di bidang Jenis bagan, pilih "bagan batang".
Di bidang kolom Sumbu-X, pilih "negara".
Di bidang kolom sumbu Y, pilih "gaji".
Di bidang Agregasi , pilih "AVG".
Pilih Terapkan.

Dimungkinkan untuk mendapatkan pengalaman yang sama dalam menjalankan SQL tetapi tanpa harus beralih bahasa. Anda dapat melakukan ini dengan mengganti sel SQL di atas dengan sel PySpark ini, pengalaman outputnya sama karena perintah tampilan digunakan:
display(spark.sql('SELECT * FROM demo_df'))Setiap sel yang sebelumnya dijalankan memiliki opsi untuk masuk ke Server Riwayat dan Pemantauan. Mengklik tautan akan membawa Anda ke berbagai bagian Pengalaman Pengguna.
Nota
Beberapa dokumentasi resmi Apache Spark bergantung pada penggunaan konsol Spark, yang tidak tersedia di Synapse Spark. Gunakan antarmuka notebook atau IntelliJ sebagai gantinya.
Membersihkan sumber daya
Azure Synapse menyimpan data Anda di Azure Data Lake Storage. Anda dapat dengan aman membiarkan instans Spark dimatikan saat tidak digunakan. Anda dikenakan biaya untuk kumpulan Apache Spark tanpa server selama itu berjalan, bahkan ketika tidak digunakan.
Karena biaya untuk kolam jauh lebih tinggi daripada biaya untuk penyimpanan, masuk akal secara ekonomi untuk membiarkan instance Spark dimatikan ketika tidak digunakan.
Untuk memastikan instans Spark dimatikan, akhiri semua sesi yang tersambung (notebook). Kolam akan dimatikan ketika waktu menganggur yang ditentukan dalam pool Apache Spark tercapai. Anda juga dapat memilih akhiri sesi dari bilah status di bagian bawah buku catatan.
Langkah berikutnya
Dalam panduan cepat ini, Anda mempelajari cara membuat kluster Apache Spark nirkabel dan menjalankan kueri Spark SQL dasar.