Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Panduan cepat ini memberikan tips bermanfaat dan praktik terbaik untuk mengembangkan solusi kumpulan SQL khusus (sebelumnya SQL DW).
Grafik berikut menunjukkan proses merancang gudang data dengan kumpulan SQL khusus (sebelumnya SQL DW):
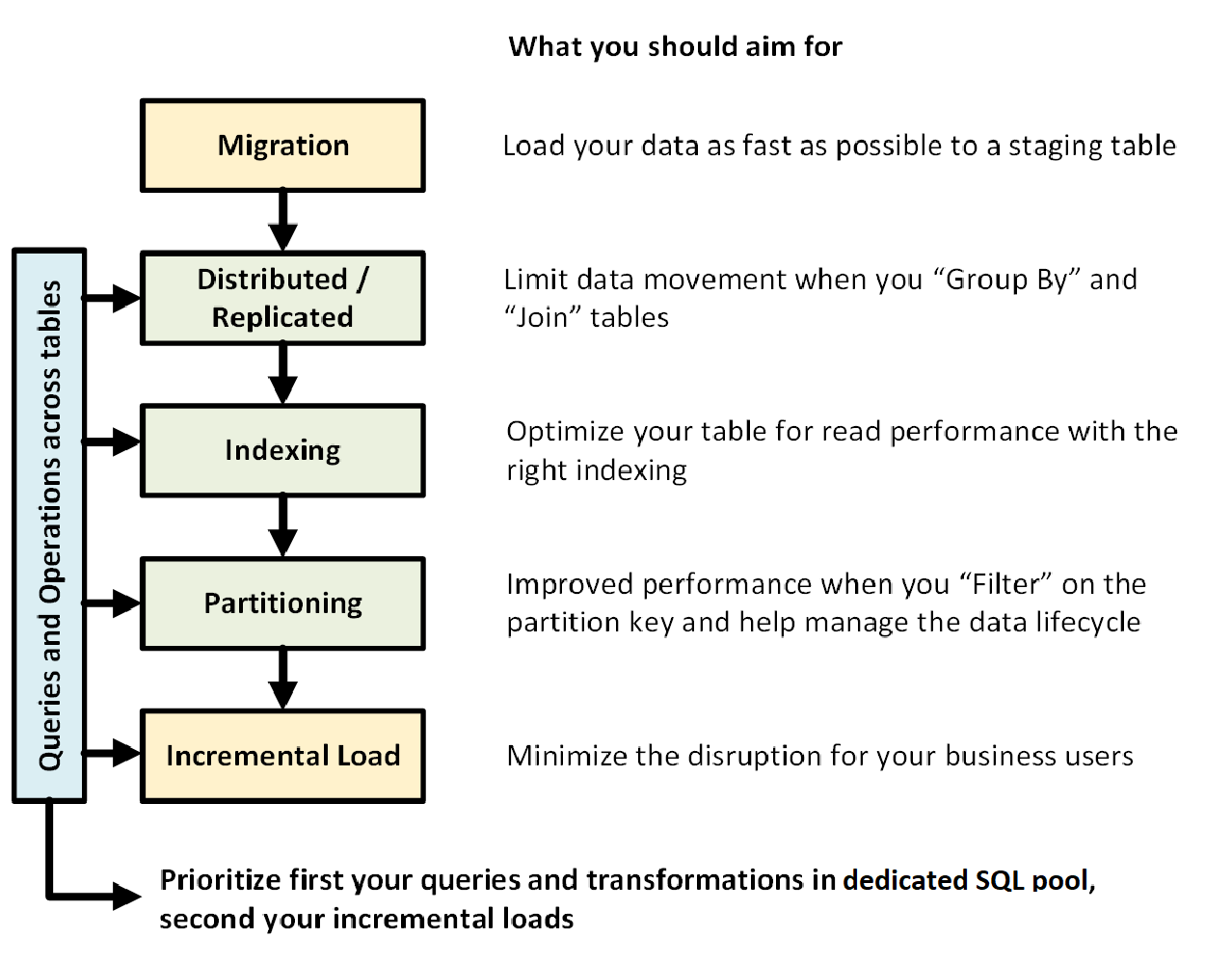
Kueri dan operasi antar tabel
Ketika Anda mengetahui terlebih dahulu operasi utama dan kueri yang akan dijalankan di gudang data, Anda dapat memprioritaskan arsitektur gudang data untuk operasi tersebut. Kueri dan operasi ini mungkin mencakup:
- Menggabungkan satu atau dua tabel fakta dengan tabel dimensi, memfilter tabel gabungan, lalu menambahkan hasilnya ke dalam data mart.
- Membuat pembaruan besar atau kecil ke dalam laporan penjualan akurat Anda.
- Hanya menambahkan data ke tabel Anda.
Mengetahui jenis operasi terlebih dahulu membantu Anda mengoptimalkan desain tabel Anda.
Migrasi data
Pertama, muat data Anda ke Azure Data Lake Storage atau Azure Blob Storage. Selanjutnya, gunakan pernyataan COPY untuk memuat data Anda ke dalam tabel penahapan. Gunakan pengaturan konfigurasi berikut:
| Desain | Rekomendasi |
|---|---|
| Distribusi | Round Robin |
| Pengindeksan | Tumpukan |
| Pembagian | Tidak ada |
| Kelas Sumber Daya | largerc atau xlargerc |
Pelajari selengkapnya tentang migrasi data, pemuatan data, dan proses Ekstrak, Muat, dan Transformasi (ELT).
Tabel terdistribusi atau direplikasi
Gunakan strategi berikut, tergantung pada properti tabel:
| Tipe | Sangat cocok untuk... | Awas jika... |
|---|---|---|
| Direplikasi | * Tabel dimensi kecil dalam skema bintang dengan penyimpanan kurang dari 2 GB setelah pemadatan (~kompresi 5x) | * Banyak transaksi penulisan yang ada pada tabel (seperti sisipan, penambahan, penghapusan, pembaruan) * Anda sering mengubah provisi Unit Gudang Data (DWU) * Anda hanya menggunakan 2-3 kolom tetapi tabel Anda memiliki banyak kolom * Anda mengindeks tabel yang direplikasi |
| Round Robin (default) | * Tabel sementara/pementasan * Tidak ada kunci gabungan yang jelas atau kolom kandidat yang baik |
* Performa lambat karena pergerakan data |
| Hash | * Tabel fakta * Tabel dimensi besar |
* Kunci distribusi tidak dapat diperbarui |
Tips :
- Mulailah dengan Round Robin, tetapi berusaha untuk menggunakan strategi distribusi hash agar dapat memanfaatkan arsitektur paralel yang sangat besar.
- Pastikan bahwa kunci hash umum memiliki format data yang sama.
- Jangan distribusikan pada format varchar.
- Tabel dimensi yang memiliki kunci hash umum dengan tabel fakta yang sering melakukan operasi penggabungan dapat didistribusikan menggunakan metode hash.
- Gunakan sys.dm_pdw_nodes_db_partition_stats untuk menganalisis kemiringan apa pun dalam data.
- Gunakan sys.dm_pdw_request_steps untuk menganalisis pergerakan data di balik kueri, memantau waktu yang dibutuhkan untuk siaran, dan operasi pengocokan. Ini sangat membantu untuk meninjau strategi distribusi Anda.
Pelajari selengkapnya tentang tabel yang direplikasi dan tabel terdistribusi.
Mengindeks tabel Anda
Pengindeksan berguna untuk membaca tabel dengan cepat. Ada serangkaian teknologi unik yang dapat Anda gunakan berdasarkan kebutuhan Anda:
| Tipe | Sangat cocok untuk... | Awas jika... |
|---|---|---|
| Tumpukan | * Tabel penahapan/sementara * Tabel kecil dengan pencarian kecil |
* Setiap pencarian memindai tabel lengkap |
| Indeks dalam kluster | * Tabel dengan hingga 100 juta baris * Tabel besar (lebih dari 100 juta baris) dengan hanya 1-2 kolom yang banyak digunakan |
* Digunakan pada tabel yang direplikasi * Anda memiliki kueri kompleks yang melibatkan beberapa operasi JOIN dan GROUP BY * Anda membuat pembaruan pada kolom terindeks: dibutuhkan memori |
| Indeks kolom penyimpanan berkluster (CCI) (default) | * Tabel besar (lebih dari 100 juta baris) | * Digunakan pada tabel yang direplikasi * Anda membuat operasi pembaruan besar-besaran di tabel Anda * Anda membuat partisi berlebih pada tabel Anda: grup baris tidak mencakup node distribusi dan partisi yang berbeda |
Tips :
- Di atas indeks berkluster, Anda mungkin ingin menambahkan indeks non-kluster ke kolom yang sangat digunakan untuk pemfilteran.
- Berhati-hatilah dengan cara Anda mengelola memori pada tabel dengan CCI. Saat memuat data, Anda ingin pengguna (atau kueri) mendapatkan manfaat dari kelas sumber daya besar. Pastikan untuk menghindari pemangkasan dan menghasilkan banyak kelompok baris terkompresi yang kecil.
- Pada Gen2, tabel CCI di-cache secara lokal pada simpul komputasi untuk memaksimalkan performa.
- Untuk CCI, performa lambat dapat terjadi karena kompresi grup baris Anda yang buruk. Jika hal ini terjadi, bangun kembali atau susun ulang CCI Anda. Anda menginginkan setidaknya 100.000 baris per grup baris terkompresi. Yang ideal adalah 1 juta baris dalam satu grup baris.
- Berdasarkan frekuensi dan ukuran beban bertahap, Anda ingin mengotomatiskan saat mengatur ulang atau membangun ulang indeks Anda. Pembersihan musim semi selalu membantu.
- Jadilah strategis saat Anda ingin memangkas grup baris. Seberapa besar grup baris terbuka? Berapa banyak data yang Anda harapkan untuk dimuat dalam beberapa hari mendatang?
Pelajari selengkapnya tentang indeks.
Pembagian
Anda mungkin mempartisi tabel Saat Anda memiliki tabel fakta besar (lebih dari 1 miliar baris). Dalam 99 persen kasus, kunci partisi harus didasarkan pada tanggal.
Dengan tabel staging yang memerlukan ELT, Anda dapat memperoleh manfaat dari pemartisian data. Ini memfasilitasi manajemen siklus hidup data. Berhati-hatilah jangan mempartisi secara berlebihan tabel fakta atau tabel penahapan Anda, terutama pada indeks kolom berkluster.
Pelajari selengkapnya tentang partisi.
Muatan bertambah bertahap
Jika Anda akan memuat data secara bertahap, pertama-tama pastikan Anda mengalokasikan kelas sumber daya yang lebih besar untuk memuat data Anda. Ini sangat penting saat memuat ke dalam tabel dengan indeks penyimpan kolom berkluster. Lihat kelas sumber daya untuk detail lebih lanjut.
Sebaiknya gunakan PolyBase dan ADF V2 untuk mengotomatiskan alur ELT Anda ke gudang data Anda.
Untuk batch besar pembaruan dalam data historis Anda, pertimbangkan untuk menggunakan CTAS untuk menulis data yang ingin Anda simpan dalam tabel daripada menggunakan INSERT, UPDATE, dan DELETE.
Menjaga statistik
Penting untuk memperbarui statistik karena perubahan signifikan terjadi pada data Anda. Lihat statistik pembaruan untuk menentukan apakah perubahan signifikan telah terjadi. Statistik yang diperbarui mengoptimalkan rencana kueri Anda. Jika Anda menemukan bahwa dibutuhkan waktu terlalu lama untuk mempertahankan semua statistik Anda, lebih selektif tentang kolom mana yang memiliki statistik.
Anda juga dapat menentukan frekuensi pembaruan. Misalnya, Anda mungkin ingin memperbarui kolom tanggal, di mana nilai baru mungkin ditambahkan, setiap hari. Anda mendapatkan manfaat paling besar dengan memiliki statistik pada kolom yang terlibat dalam gabungan, kolom yang digunakan dalam klausa WHERE, dan kolom yang ditemukan di GROUP BY.
Pelajari selengkapnya tentang statistik.
Kelas sumber daya
Grup sumber daya digunakan sebagai cara untuk mengalokasikan memori ke kueri. Jika Anda memerlukan lebih banyak memori untuk meningkatkan kueri atau kecepatan pemuatan, Anda harus mengalokasikan kelas sumber daya yang lebih tinggi. Di sisi lain, menggunakan kelas sumber daya yang lebih besar berdampak pada konkurensi. Anda ingin mempertimbangkannya sebelum memindahkan semua pengguna Anda ke kelas sumber daya besar.
Jika Anda melihat bahwa kueri memakan waktu terlalu lama, periksa apakah pengguna Anda tidak berjalan di kelas sumber daya besar. Kelas sumber daya yang besar menggunakan banyak slot untuk konkurensi. Mereka dapat menyebabkan kueri lain mengantre.
Terakhir, dengan menggunakan Gen2 dari kumpulan SQL khusus (sebelumnya SQL DW), setiap kelas sumber daya mendapatkan memori 2,5 kali lebih banyak daripada Gen1.
Pelajari selengkapnya cara bekerja dengan kelas sumber daya dan konkurensi.
Menurunkan biaya Anda
Fitur utama Azure Synapse adalah kemampuan untuk mengelola sumber daya komputasi. Anda dapat menjeda kumpulan SQL khusus Anda (sebelumnya SQL DW) saat Anda tidak menggunakannya, yang menghentikan penagihan sumber daya komputasi. Anda dapat menskalakan sumber daya untuk memenuhi tuntutan performa Anda. Untuk menjeda, gunakan portal Microsoft Azure atau PowerShell. Untuk menskalakan, gunakan portal Microsoft Azure, PowerShell, T-SQL, atau REST API.
Skala otomatis sekarang pada saat yang Anda inginkan dengan Azure Functions:

Optimalkan arsitektur Anda untuk performa
Sebaiknya pertimbangkan SQL Database dan Azure Analysis Services dalam arsitektur hub-and-spoke. Solusi ini dapat menyediakan isolasi beban kerja antara grup pengguna yang berbeda sekaligus menggunakan fitur keamanan tingkat lanjut dari SQL Database dan Azure Analysis Services. Ini juga merupakan cara untuk memberikan konkurensi tanpa batas kepada pengguna Anda.
Pelajari selengkapnya tentang arsitektur khas yang memanfaatkan kumpulan SQL khusus (sebelumnya SQL DW) di Azure Synapse Analytics.
Sebarkan spoke Anda di database SQL dari kumpulan SQL khusus (sebelumnya SQL DW):