Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Dalam artikel ini, Anda akan mempelajari cara menulis kueri menggunakan kumpulan Synapse SQL tanpa server untuk membaca file Delta Lake. Delta Lake adalah lapisan penyimpanan sumber terbuka yang menghadirkan transaksi ACID (atomisitas, konsistensi, isolasi, dan daya tahan) ke Apache Spark dan beban kerja big data. Anda dapat mempelajari selengkapnya dari video cara mengkueri tabel delta lake.
Penting
Kumpulan SQL tanpa server dapat mengkueri Delta Lake versi 1.0. Perubahan yang telah diperkenalkan sejak versi Delta Lake 1.2 (seperti mengganti nama kolom) tidak didukung dalam tanpa server. Jika Anda menggunakan versi Delta yang lebih tinggi dengan vektor penghapusan data, titik pemeriksaan v2, dan lainnya, Anda harus mempertimbangkan untuk menggunakan mesin kueri lain seperti Microsoft Fabric SQL endpoint untuk Lakehouses.
Kumpulan SQL tanpa server di ruang kerja Synapse memungkinkan Anda membaca data yang disimpan dalam format Delta Lake, dan menyajikannya ke alat pelaporan. Kumpulan SQL tanpa server dapat membaca file Delta Lake yang dibuat menggunakan Apache Spark, Azure Databricks, atau produsen lain dari format Delta Lake.
Kumpulan Apache Spark di Azure Synapse memungkinkan insinyur data untuk memodifikasi file Delta Lake menggunakan Scala, PySpark, dan .NET. Kumpulan SQL tanpa server membantu analis data untuk membuat laporan tentang file Delta Lake yang dibuat oleh insinyur data.
Penting
Mengkueri format Delta Lake menggunakan kumpulan SQL tanpa server umumnya tersedia fungsionalitas. Namun, melakukan kueri pada tabel Spark Delta masih dalam pratinjau publik dan belum siap untuk produksi. Ada masalah umum yang mungkin terjadi jika Anda mengkueri tabel Delta yang dibuat menggunakan kumpulan Spark. Lihat masalah yang diketahui di bantuan mandiri kumpulan SQL Tanpa Server.
Prasyarat
Penting
Sumber data hanya dapat dibuat dalam database kustom (bukan di database master atau database yang direplikasi dari kumpulan Apache Spark).
Untuk menggunakan sampel dalam artikel ini, Anda harus menyelesaikan langkah-langkah berikut:
- Membuat database dengan sumber data yang mereferensikan akun penyimpanan Taksi Kuning NYC.
- Inisialisasi objek dengan menjalankan skrip penyetelan pada database yang Anda buat di langkah 1. Skrip penyetelan ini akan membuat sumber data, info masuk lingkup database, dan format file eksternal yang digunakan dalam sampel ini.
Jika Anda membuat database, dan mengalihkan konteks ke database Anda (menggunakan USE database_name pernyataan atau dropdown untuk memilih database di beberapa editor kueri), Anda bisa membuat sumber data eksternal yang berisi URI akar ke himpunan data Anda dan menggunakannya untuk mengkueri file Delta Lake. Contohnya:
CREATE EXTERNAL DATA SOURCE DeltaLakeStorage
WITH ( LOCATION = 'https://<yourstorageaccount>.blob.core.windows.net/delta-lake/' );
GO
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'covid',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta'
) as rows;
Jika sumber data dilindungi menggunakan kunci SAS atau identitas khusus, Anda bisa mengonfigurasi sumber data dengan kredensial lingkup database.
Anda dapat membuat sumber data eksternal dengan lokasi yang menunjuk ke folder akar penyimpanan. Setelah Anda membuat sumber data eksternal, gunakan sumber data dan jalur relatif ke file dalam OPENROWSET fungsi. Dengan cara ini Anda tidak perlu menggunakan URI absolut penuh ke file Anda. Anda juga dapat menentukan kredensial kustom untuk mengakses lokasi penyimpanan.
Membaca folder Delta Lake
Penting
Gunakan skrip penyiapan dalam prasyarat untuk menyiapkan sumber data sampel dan tabel.
Fungsi OPENROWSET memungkinkan Anda membaca konten file Delta Lake dengan menyediakan URL ke folder akar Anda.
Cara termudah untuk melihat konten file DELTA Anda adalah dengan memberikan URL file tersebut ke fungsi OPENROWSET dan menentukan format DELTA. Jika file tersedia untuk umum atau jika identitas Microsoft Entra Anda dapat mengakses file ini, Anda akan dapat melihat konten file menggunakan kueri seperti yang diperlihatkan dalam contoh berikut:
SELECT TOP 10 *
FROM OPENROWSET(
BULK '/covid/',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta') as rows;
Nama kolom dan jenis data secara otomatis terbaca dari file Delta Lake. Fungsi OPENROWSETini menggunakan tipe tebakan terbaik seperti VARCHAR(1000) untuk kolom string.
URI dalam fungsi OPENROWSET harus mereferensikan folder Delta Lake akar yang berisi subfolder yang disebut _delta_log .
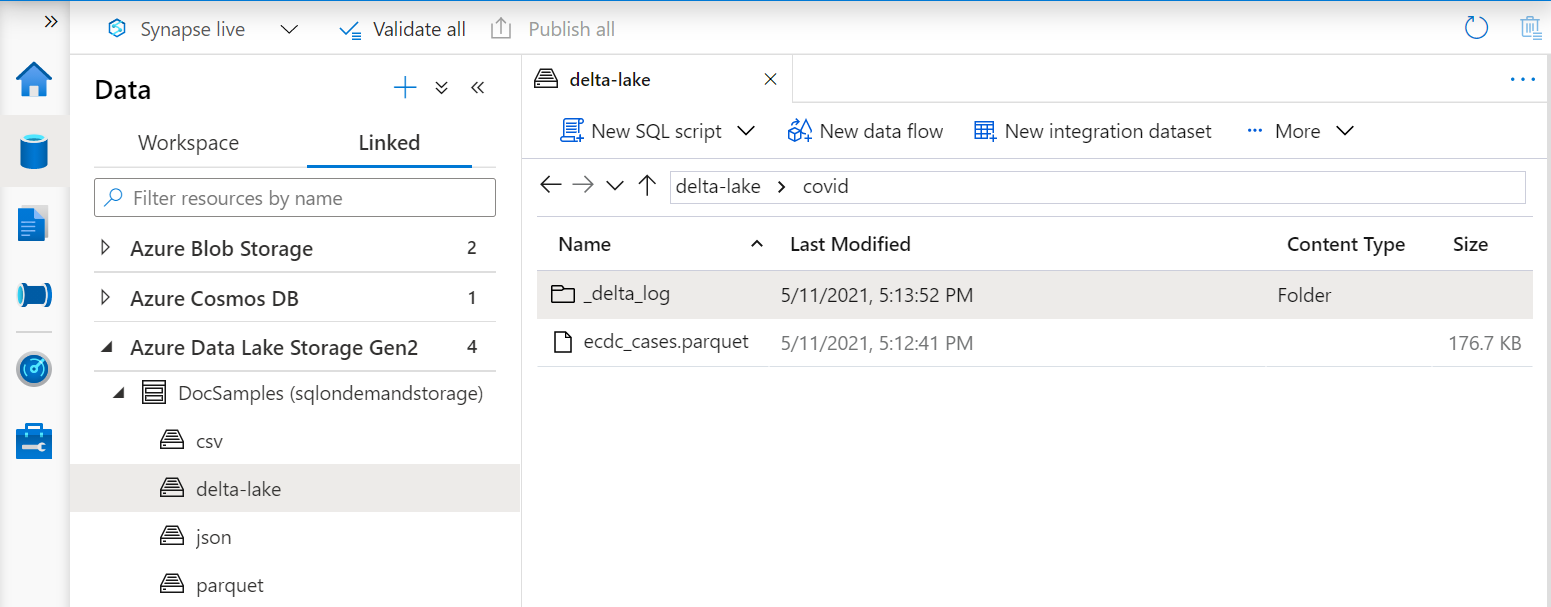
Jika Anda tidak memiliki subfolder ini, Anda tidak menggunakan format Delta Lake. Anda dapat mengonversi file Parquet biasa dalam folder ke format Delta Lake menggunakan skrip seperti contoh skrip Apache Spark Python berikut:
%%pyspark
from delta.tables import DeltaTable
deltaTable = DeltaTable.convertToDelta(spark, "parquet.`abfss://delta-lake@sqlondemandstorage.dfs.core.windows.net/covid`")
Untuk meningkatkan kinerja kueri Anda, pertimbangkan untuk menentukan tipe eksplisit dalamWITHklausa.
Catatan
Kumpulan Synapse SQL tanpa server menggunakan inferensi skema untuk menentukan kolom dan jenisnya secara otomatis. Aturan yang digunakan untuk inferensi skema sama dengan yang digunakan untuk file Parquet. Untuk pemetaan jenis Delta Lake ke jenis asli SQL, periksa pemetaan jenis untuk Parquet.
Pastikan Anda dapat mengakses file Anda. Jika file Anda dilindungi dengan kunci SAS atau identitas Azure kustom, Anda harus menyiapkan kredensial tingkat server untuk masuk sql.
Penting
Pastikan Anda menggunakan kolase database UTF-8 (misalnya Latin1_General_100_BIN2_UTF8) karena nilai string dalam file Delta Lake dikodekan menggunakan pengodean UTF-8.
Ketidakcocokan antara pengodean teks dalam file Delta Lake dan kolase dapat menyebabkan kesalahan konversi yang tidak terduga.
Anda dapat dengan mudah mengubah kolase default database saat ini menggunakan pernyataan T-SQL berikut:
ALTER DATABASE CURRENT COLLATE Latin1_General_100_BIN2_UTF8; Untuk informasi selengkapnya tentang kolase, lihat Jenis kolase yang didukung untuk Synapse SQL.
Secara eksplisit menentukan skema
OPENROWSET memungkinkan Anda secara eksplisit menentukan kolom apa yang ingin Anda baca dari file menggunakan klausul WITH:
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'covid',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta'
)
WITH ( date_rep date,
cases int,
geo_id varchar(6)
) as rows;
Dengan spesifikasi eksplisit dari skema kumpulan hasil, Anda dapat meminimalkan ukuran tipe dan menggunakan jenis VARCHAR(6) yang lebih tepat untuk kolom string alih-alih VARCHAR (1000) pesimistis. Minimalisasikan jenis mungkin secara signifikan meningkatkan kinerja kueri Anda.
Penting
Pastikan Anda secara eksplisit menentukan kolase UTF-8 (misalnya Latin1_General_100_BIN2_UTF8) untuk semua kolom string dalam WITH klausul atau mengatur kolase UTF-8 di tingkat database.
Ketidakcocokan antara pengkodean teks dalam file dan kolase kolom string dapat menyebabkan kesalahan konversi yang tidak terduga.
Anda dapat dengan mudah mengubah kolase default database saat ini menggunakan pernyataan T-SQL berikut:
alter database current collate Latin1_General_100_BIN2_UTF8 Anda dapat dengan mudah mengatur kolase pada jenis kolom menggunakan definisi berikut: geo_id varchar(6) collate Latin1_General_100_BIN2_UTF8
Dataset
Himpunan data Taksi Kuning NYC digunakan dalam sampel ini. Himpunan data asli PARQUET dikonversi ke format DELTA, dan versi DELTA digunakan dalam contoh.
Data yang dipartisi dikenai kueri
Kumpulan data yang disediakan dalam sampel ini dibagi (dipartisi) menjadi subfolder terpisah.
Tidak seperti Parquet,Anda tidak perlu menargetkan partisi tertentu menggunakan FILEPATH fungsi.
OPENROWSET ini akan mengidentifikasi kolom partisi dalam struktur folder Delta Lake Anda dan memungkinkan Anda untuk langsung mengkueri data menggunakan kolom ini. Contoh ini menunjukkan jumlah tarif menurut tahun, bulan, dan payment_type untuk tiga bulan pertama 2017.
SELECT
YEAR(pickup_datetime) AS year,
passenger_count,
COUNT(*) AS cnt
FROM
OPENROWSET(
BULK 'yellow',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT='DELTA'
) nyc
WHERE
nyc.year = 2017
AND nyc.month IN (1, 2, 3)
AND pickup_datetime BETWEEN CAST('1/1/2017' AS datetime) AND CAST('3/31/2017' AS datetime)
GROUP BY
passenger_count,
YEAR(pickup_datetime)
ORDER BY
YEAR(pickup_datetime),
passenger_count;
Fungsi OPENROWSET ini akan menghilangkan partisi yang tidak cocok dengan year dan month dalam klausa WHERE. Teknik pemangkasan file/partisi ini akan secara signifikan mengurangi kumpulan data Anda, meningkatkan kinerja, dan mengurangi biaya kueri.
Nama folder dalam fungsi OPENROWSET (yellow dalam contoh ini) dikonkatenasi menggunakan LOCATION dalam sumber data DeltaLakeStorage, dan harus mereferensikan folder akar Delta Lake yang berisi subfolder yang disebut _delta_log.
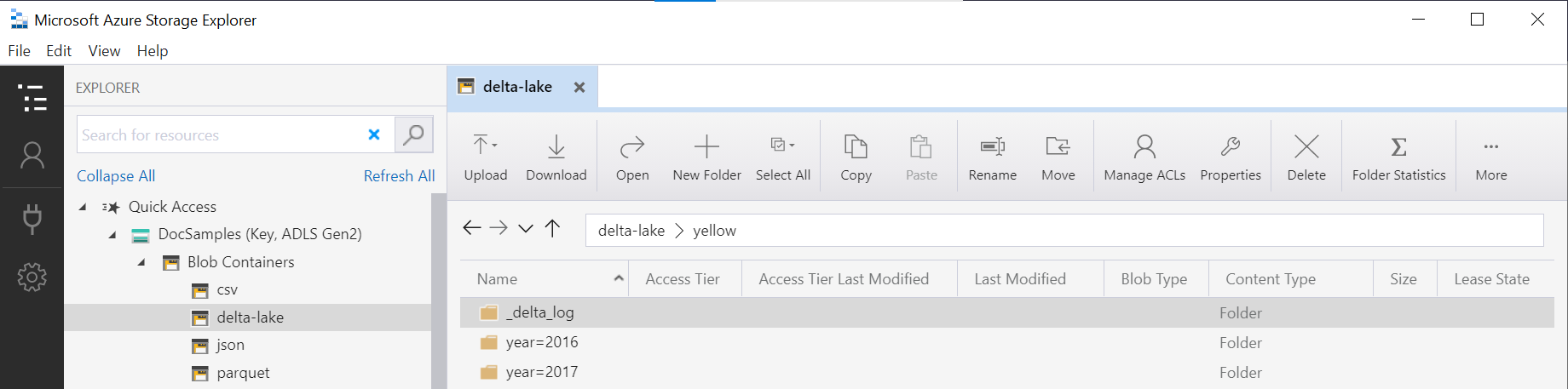
Jika Anda tidak memiliki subfolder ini, Anda tidak menggunakan format Delta Lake. Anda dapat mengonversi file Parquet biasa di folder ke format Delta Lake menggunakan skrip Apache Spark Python berikut:
%%pyspark
from delta.tables import DeltaTable
deltaTable = DeltaTable.convertToDelta(spark, "parquet.`abfss://delta-lake@sqlondemandstorage.dfs.core.windows.net/yellow`", "year INT, month INT")
Argumen kedua fungsi DeltaTable.convertToDeltaLake mewakili kolom partisi (tahun dan bulan) yang merupakan bagian dari pola folder (year=*/month=* dalam contoh ini) dan tipenya.
Batasan
- Tinjau batasan dan masalah yang diketahui di Halaman bantuan mandiri kumpulan SQL tanpa server Synapse.
Konten terkait
Lanjutkan ke artikel berikutnya untuk mempelajari cara Mengkueri tipe bertingkat Parquet. Jika Anda ingin terus membangun solusi Delta Lake, pelajari cara membuat tampilan atau tabel eksternal di folder Delta Lake.