Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Tip
Microsoft Fabric Data Warehouse adalah gudang relasional skala perusahaan pada fondasi data lake, dengan arsitektur siap masa depan, AI bawaan, dan fitur baru. Jika Anda baru menggunakan pergudangan data, mulailah dengan Fabric Data Warehouse. Beban kerja kumpulan SQL terdedikasi yang ada dapat ditingkatkan ke Fabric untuk mengakses kemampuan baru di seluruh ilmu data, analitik waktu nyata, dan pelaporan.
Tabel eksternal menunjuk ke data yang terletak di Hadoop, blob Azure Storage, atau Azure Data Lake Storage (ADLS).
Anda dapat menggunakan tabel eksternal untuk membaca data dari file atau menulis data ke file di Azure Storage. Dengan Azure Synapse SQL, Anda dapat menggunakan tabel eksternal untuk membaca data eksternal menggunakan kumpulan SQL khusus atau kumpulan SQL tanpa server.
Bergantung pada jenis sumber data eksternalnya, Anda dapat menggunakan dua jenis tabel eksternal:
- Tabel eksternal Hadoop yang dapat Anda gunakan untuk membaca dan mengekspor data dalam berbagai format data seperti CSV, Parquet, dan ORC. Tabel eksternal Hadoop tersedia di kumpulan SQL khusus, tetapi tidak tersedia di kumpulan SQL tanpa server.
- Tabel eksternal asli yang dapat Anda gunakan untuk membaca dan mengekspor data dalam berbagai format data seperti CSV dan Parquet. Tabel eksternal asli tersedia di kumpulan SQL tanpa server dan di kumpulan SQL khusus. Menulis/mengekspor data menggunakan CETAS dan tabel eksternal asli hanya tersedia di kumpulan SQL tanpa server, tetapi tidak di kumpulan SQL khusus.
Perbedaan utama antara Hadoop dan tabel eksternal asli:
| Jenis tabel eksternal | Hadoop | Asli |
|---|---|---|
| Kumpulan SQL khusus | Tersedia | Parquet saja |
| Kumpulan SQL tanpa server | Tidak tersedia | Tersedia |
| Format yang didukung | Terbatas/CSV, Parquet, ORC, Hive RC, dan RC | Kumpulan SQL tanpa server: Dibatasi/CSV, Parquet, dan Delta Lake Kumpulan SQL khusus: Parquet |
| Penghapusan partisi folder | Tidak | Penghapusan partisi hanya tersedia dalam tabel yang dipartisi yang dibuat pada format Parquet atau CSV yang disinkronkan dari kumpulan Apache Spark. Anda mungkin membuat tabel eksternal pada folder yang dipartisi Parquet, tetapi kolom partisi tidak dapat diakses dan diabaikan, sementara eliminasi partisi tidak akan diterapkan. Jangan membuat tabel eksternal di folder Delta Lake karena tidak didukung. Gunakan tampilan terpartisi Delta untuk mengkueri data Delta Lake yang terpartisi, jika Anda perlu. |
| Penghapusan file (predicate pushdown) | Tidak | Ya, di kumpulan SQL tanpa server. Untuk melakukan pushdown pada string, Anda perlu menggunakan kolasi Latin1_General_100_BIN2_UTF8 pada kolom VARCHAR untuk mengaktifkan pushdown. Untuk informasi selengkapnya tentang kolase, lihat Dukungan kolase database untuk Synapse SQL di Azure Synapse Analytics. |
| Format kustom untuk lokasi | Tidak | Ya, gunakan wildcard seperti /year=*/month=*/day=* untuk format Parquet atau CSV. Jalur folder kustom tidak tersedia di Delta Lake. Di kumpulan SQL tanpa server, Anda juga dapat menggunakan wildcard /logs/** rekursif untuk mereferensikan file Parquet atau CSV di subfolder apa pun di bawah folder yang direferensikan. |
| Pemindaian folder rekursif | Ya | Ya. Pada kumpulan SQL tanpa server, /** harus ditentukan di akhir jalur lokasi. Dalam Dedicated pool, folder selalu dipindai secara rekursif. |
| Autentikasi penyimpanan | Kunci Akses Penyimpanan (SAK), Passthrough Entra Microsoft, Identitas yang dikelola, identitas aplikasi kustom Microsoft Entra | Tanda Tangan Akses Bersama(SAS), Microsoft Entra passthrough, Identitas Terkelola, Identitas aplikasi kustom Microsoft Entra. |
| Pemetaan kolom | Ordinal - kolom dalam definisi tabel eksternal dipetakan ke kolom dalam file Parquet yang mendasarinya berdasarkan posisi. | Kumpulan tanpa server: berdasarkan nama. Kolom dalam definisi tabel eksternal dipetakan ke kolom dalam file Parquet yang mendasarinya berdasarkan pencocokan nama kolom. Pool khusus: pencocokan berurutan. Kolom di dalam definisi tabel eksternal dipetakan ke kolom dalam file Parquet yang mendasarinya berdasarkan posisi. |
| CETAS (ekspor/transformasi) | Ya | CETAS dengan tabel asli sebagai target hanya berfungsi di kumpulan SQL tanpa server. Anda tidak dapat menggunakan kumpulan SQL khusus untuk mengekspor data menggunakan tabel asli. |
Catatan
Tabel eksternal bawaan adalah solusi yang direkomendasikan di kumpulan tempat tabel tersebut tersedia secara umum. Jika Anda perlu mengakses data eksternal, selalu gunakan tabel bawaan di kumpulan serverless atau kumpulan yang didedikasikan. Gunakan tabel Hadoop hanya jika Anda perlu mengakses beberapa jenis yang tidak didukung dalam tabel eksternal asli (misalnya - ORC, RC), atau jika versi asli tidak tersedia.
Tabel eksternal dalam kumpulan SQL khusus dan kumpulan SQL tanpa server
Anda dapat menggunakan tabel eksternal untuk:
- Kueri Azure Blob Storage dan ADLS Gen2 dengan pernyataan Transact-SQL.
- Simpan hasil kueri ke file di Azure Blob Storage atau Azure Data Lake Storage menggunakan CETAS dengan Synapse SQL.
- Mengimpor data dari Blob Azure Storage dan Azure Data Lake Storage dan menyimpannya di kumpulan SQL khusus (hanya tabel Hadoop di kumpulan khusus).
Catatan
Saat digunakan dengan instruksi CREATE TABLE AS SELECT, dengan memilih dari tabel eksternal, data diimpor ke tabel dalam kumpulan SQL yang berdedikasi.
Jika performa tabel eksternal Hadoop di kumpulan khusus tidak memenuhi tujuan performa Anda, pertimbangkan untuk memuat data eksternal ke dalam tabel Gudang data menggunakan pernyataan COPY.
Untuk tutorial pemuatan, lihat Menggunakan PolyBase untuk memuat data dari Blob Azure Storage.
Anda dapat membuat tabel eksternal di kumpulan Synapse SQL melalui langkah-langkah berikut:
- CREATE EXTERNAL DATA SOURCE untuk mereferensikan penyimpanan Azure eksternal dan menentukan info masuk yang akan digunakan untuk mengakses penyimpanan.
- CREATE EXTERNAL FILE FORMAT untuk mendeskripsikan format file CSV atau Parquet.
- CREATE EXTERNAL TABLE di atas file yang ditempatkan di sumber data dengan format file yang sama.
Penghapusan partisi folder
Tabel eksternal asli di kumpulan Synapse dapat mengabaikan file yang ditempatkan di folder yang tidak relevan untuk kueri. Jika file Anda disimpan dalam hierarki folder (misalnya - /year=2020/month=03/day=16) dan nilai untuk year, month, dan day diekspos sebagai kolom, kueri yang berisi filter seperti year=2020 akan membaca file hanya dari subfolder yang ditempatkan dalam year=2020 folder. File dan folder yang ditempatkan di folder lain (year=2021 atau year=2022) akan diabaikan dalam kueri ini. Eliminasi ini dikenal sebagai eliminasi partisi.
Penghapusan partisi folder tersedia di tabel eksternal bawaan yang disinkronkan dari pool Synapse Spark. Jika Anda memiliki himpunan data yang dipartisi dan Anda ingin menggunakan eliminasi partisi dengan tabel eksternal yang Anda buat, gunakan tampilan yang dipartisi alih-alih tabel eksternal.
Penghapusan file
Beberapa format data seperti Parquet dan Delta berisi statistik file untuk setiap kolom (misalnya, nilai min/maks untuk setiap kolom). Kueri yang memfilter data tidak akan membaca file di mana nilai kolom yang diperlukan tidak ada. Kueri pertama-tama akan menjelajahi nilai min/maks untuk kolom yang digunakan dalam predikat kueri untuk menemukan file yang tidak berisi data yang diperlukan. File-file ini diabaikan dan dihilangkan dari rencana kueri.
Teknik ini juga dikenal sebagai filter predikat pushdown dan dapat meningkatkan performa kueri Anda. Filter pushdown tersedia di kumpulan SQL tanpa server pada format Parquet dan Delta. Untuk menerapkan filter pendorongan untuk jenis string, gunakan jenis VARCHAR dengan kolasi Latin1_General_100_BIN2_UTF8. Untuk informasi selengkapnya tentang kolase, lihat Dukungan kolase database untuk Synapse SQL di Azure Synapse Analytics.
Keamanan
Pengguna harus memiliki izin SELECT pada tabel eksternal untuk membaca data.
Tabel eksternal mengakses penyimpanan Azure yang mendasarinya menggunakan kredensial yang tercakup dalam database yang ditentukan dalam sumber data dengan aturan-aturan berikut:
- Sumber data tanpa kredensial memungkinkan tabel eksternal mengakses file yang tersedia untuk umum di penyimpanan Azure.
- Sumber data dapat memiliki info masuk yang memungkinkan tabel eksternal hanya mengakses file di penyimpanan Azure menggunakan token SAS atau Identitas Terkelola ruang kerja. Misalnya, lihat artikel Mengembangkan kontrol akses untuk file di penyimpanan.
Komentar
Untuk memastikan eksekusi kueri yang andal, file dan folder sumber yang direferensikan oleh tabel eksternal harus tetap tidak berubah selama durasi operasi.
- Memodifikasi, menghapus, atau mengganti file atau folder yang direferensikan saat kueri berjalan dapat menyebabkan kegagalan atau menyebabkan hasil yang tidak konsisten.
- Sebelum mengkueri tabel eksternal di kumpulan SQL khusus, verifikasi bahwa semua data sumber stabil dan tidak akan diubah selama eksekusi.
Contoh untuk CREATE EXTERNAL DATA SOURCE
Contoh berikut membuat sumber data eksternal Hadoop di kumpulan SQL khusus untuk ADLS Gen2 yang menunjuk ke himpunan data New York publik:
CREATE DATABASE SCOPED CREDENTIAL [ADLS_credential]
WITH IDENTITY='SHARED ACCESS SIGNATURE',
SECRET = 'sv=2022-11-02&ss=b&srt=co&sp=rl&se=2042-11-26T17:40:55Z&st=2024-11-24T09:40:55Z&spr=https&sig=DKZDuSeZhuCWP9IytWLQwu9shcI5pTJ%2Fw5Crw6fD%2BC8%3D'
GO
CREATE EXTERNAL DATA SOURCE AzureDataLakeStore
WITH
-- Please note the abfss endpoint when your account has secure transfer enabled
( LOCATION = 'abfss://data@newyorktaxidataset.dfs.core.windows.net' ,
CREDENTIAL = ADLS_credential ,
TYPE = HADOOP
) ;
Contoh berikut membuat sumber data eksternal untuk ADLS Gen2 yang menunjuk ke himpunan data New York yang tersedia untuk umum:
CREATE EXTERNAL DATA SOURCE YellowTaxi
WITH ( LOCATION = 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/',
TYPE = HADOOP)
Contoh dari CREATE EXTERNAL FILE FORMAT
Berikut contoh membuat format file eksternal untuk file sensus:
CREATE EXTERNAL FILE FORMAT census_file_format
WITH
(
FORMAT_TYPE = PARQUET,
DATA_COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
)
Contoh CREATE EXTERNAL TABLE
Berikut contoh membuat tabel eksternal. Ini mengembalikan baris pertama:
CREATE EXTERNAL TABLE census_external_table
(
decennialTime varchar(20),
stateName varchar(100),
countyName varchar(100),
population int,
race varchar(50),
sex varchar(10),
minAge int,
maxAge int
)
WITH (
LOCATION = '/parquet/',
DATA_SOURCE = population_ds,
FILE_FORMAT = census_file_format
)
GO
SELECT TOP 1 * FROM census_external_table
Membuat dan mengkueri tabel eksternal dari file di Azure Data Lake
Menggunakan kemampuan eksplorasi Data Lake dari Synapse Studio, Anda sekarang dapat membuat dan mengkueri tabel eksternal menggunakan kumpulan Synapse SQL dengan klik kanan pada file. Gerakan satu klik untuk membuat tabel eksternal dari akun penyimpanan ADLS Gen2 hanya didukung untuk file Parquet.
Prasyarat
Anda harus memiliki akses ke ruang kerja dengan setidaknya
Storage Blob Data Contributorperan akses ke akun ADLS Gen2 atau Daftar Kontrol Akses (ACL) yang memungkinkan Anda mengakses file.Anda harus memiliki setidaknya izin untuk membuat tabel eksternal dan mengkueri tabel eksternal pada kumpulan Synapse SQL (khusus atau tanpa server).
Dari panel Data, pilih file yang ingin Anda buat tabel eksternalnya:

Jendela dialog akan terbuka. Pilih kumpulan SQL khusus atau kumpulan SQL tanpa server, beri nama untuk tabel lalu pilih skrip terbuka:
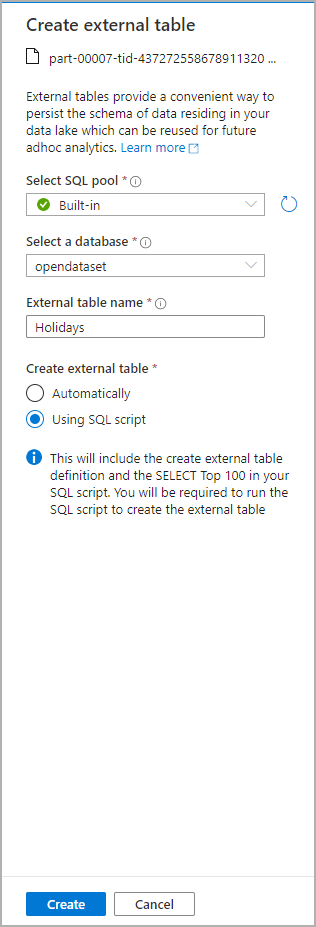
Skrip SQL secara otomatis dibuat dengan menyimpulkan skema dari file:

Jalankan skrip. Skrip akan secara otomatis menjalankan SELECT TOP 100 *:

Tabel eksternal telah dibuat. Sekarang Anda bisa mengkueri tabel eksternal langsung dari panel Data.
Konten terkait
Lihat artikel CETAS tentang cara menyimpan hasil kueri ke tabel eksternal di Azure Storage. Atau Anda dapat mulai mengkueri Apache Spark untuk tabel eksternal Azure Synapse.