Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Tutorial ini menunjukkan kepada Anda cara membangun pemberi rekomendasi film dengan ML.NET dalam aplikasi konsol .NET Core. Langkah-langkahnya menggunakan C# dan Visual Studio 2019.
Dalam tutorial ini, Anda akan mempelajari cara:
- Pilih algoritma pembelajaran mesin
- Menyiapkan dan memuat data Anda
- Membangun dan melatih model
- Mengevaluasi model
- Menyebarkan dan menggunakan model
Anda dapat menemukan kode sumber untuk tutorial ini di repositori dotnet/samples .
Alur kerja pembelajaran mesin
Anda akan menggunakan langkah-langkah berikut untuk menyelesaikan tugas Anda, serta tugas ML.NET lainnya:
Prasyarat
Pilih tugas pembelajaran mesin yang sesuai
Ada beberapa cara untuk mendekati masalah rekomendasi, seperti merekomendasikan daftar film atau merekomendasikan daftar produk terkait, tetapi dalam hal ini Anda akan memprediksi peringkat apa (1-5) yang akan diberikan pengguna ke film tertentu dan merekomendasikan film tersebut jika lebih tinggi dari ambang batas yang ditentukan (semakin tinggi peringkat, semakin tinggi kemungkinan pengguna menyukai film tertentu).
Membuat aplikasi konsol
Membuat proyek
Buat Aplikasi Konsol C# yang disebut "MovieRecommender". Klik tombol Berikutnya.
Pilih .NET 6 sebagai kerangka kerja yang akan digunakan. Klik tombol Buat.
Buat direktori bernama Data di proyek Anda untuk menyimpan himpunan data:
Di Penjelajah Solusi, klik kanan proyek dan pilih Tambahkan>Folder Baru. Ketik "Data" dan tekan Enter.
Instal Paket NuGet Microsoft.ML dan Microsoft.ML.Recommender :
Catatan
Sampel ini menggunakan versi stabil terbaru dari paket NuGet yang disebutkan kecuali dinyatakan lain.
Di Penjelajah Solusi, klik kanan proyek, lalu pilih Kelola Paket NuGet. Pilih "nuget.org" sebagai Sumber paket, pilih tab Telusuri , cari Microsoft.ML, pilih paket dalam daftar, dan pilih tombol Instal . Pilih tombol OK pada dialog Pratinjau Perubahan lalu pilih tombol Saya Terima pada dialog Penerimaan Lisensi jika Anda setuju dengan ketentuan lisensi untuk paket yang tercantum. Ulangi langkah-langkah ini untuk Microsoft.ML.Recommender.
Tambahkan pernyataan berikut
usingdi bagian atas file Program.cs Anda:using Microsoft.ML; using Microsoft.ML.Trainers; using MovieRecommendation;
Unduh data Anda
Unduh dua himpunan data dan simpan ke folder Data yang sebelumnya Anda buat:
Klik kanan padarecommendation-ratings-train.csv dan pilih "Simpan Tautan (atau Target) Sebagai..."
Klik kanan padarecommendation-ratings-test.csv dan pilih "Simpan Tautan (atau Target) Sebagai..."
Pastikan Anda menyimpan *.csv file ke folder Data , atau setelah Anda menyimpannya di tempat lain, pindahkan file *.csv ke folder Data .
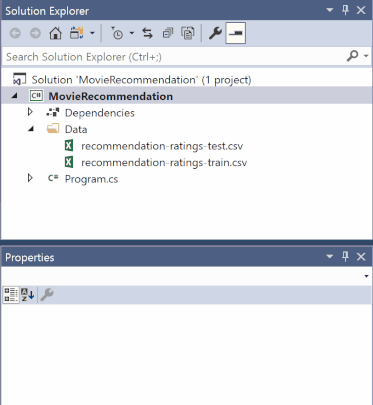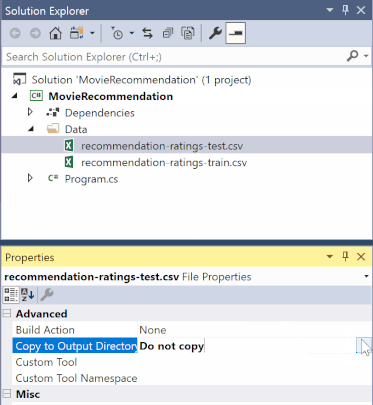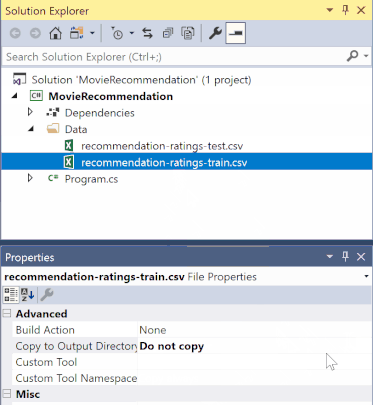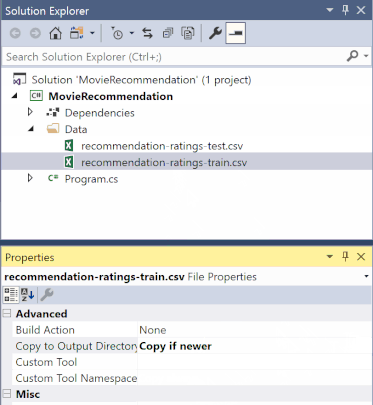
Di Penjelajah Solusi, klik kanan setiap file *.csv dan pilih Properti. Di bawah Tingkat Lanjut, ubah nilai Salin ke Direktori Output menjadi Salin jika lebih baru.
Memuat data Anda
Langkah pertama dalam proses ML.NET adalah menyiapkan dan memuat data pelatihan dan pengujian model Anda.
Data peringkat rekomendasi dibagi menjadi Train himpunan data dan Test . Data Train digunakan agar sesuai dengan model Anda. Data Test digunakan untuk membuat prediksi dengan model terlatih Anda dan mengevaluasi performa model. Biasanya memiliki pemisahan 80/20 dengan Train data dan Test .
Di bawah ini adalah pratinjau data dari *file .csv Anda:
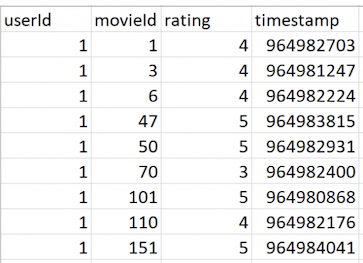
Dalam file *.csv, ada empat kolom:
userIdmovieIdratingtimestamp
Dalam pembelajaran mesin, kolom yang digunakan untuk membuat prediksi disebut Fitur, dan kolom dengan prediksi yang dikembalikan disebut Label.
Anda ingin memprediksi peringkat film, sehingga kolom peringkat adalah Label. Tiga kolom lainnya, userId, movieId, dan timestamp semuanya Features digunakan untuk memprediksi Label.
| Fitur | Label |
|---|---|
userId |
rating |
movieId |
|
timestamp |
Terserah Anda untuk memutuskan mana Features yang digunakan untuk memprediksi Label. Anda juga dapat menggunakan metode seperti kepentingan fitur permutasi untuk membantu memilih yang terbaik Features.
Dalam hal ini, Anda harus menghilangkan timestamp kolom sebagai a Feature karena tanda waktu tidak benar-benar memengaruhi bagaimana pengguna menilai film tertentu dan dengan demikian tidak akan berkontribusi untuk membuat prediksi yang lebih akurat:
| Fitur | Label |
|---|---|
userId |
rating |
movieId |
Selanjutnya Anda harus menentukan struktur data Anda untuk kelas input.
Tambahkan kelas baru ke proyek Anda:
Di Penjelajah Solusi, klik kanan proyek, lalu pilih Tambahkan > Item Baru.
Dalam kotak dialog Tambahkan Item Baru, pilih Kelas dan ubah bidang Nama menjadi MovieRatingData.cs. Kemudian, pilih tombol Tambahkan .
File MovieRatingData.cs terbuka di editor kode. Tambahkan pernyataan berikut using ke bagian atas MovieRatingData.cs:
using Microsoft.ML.Data;
Buat kelas yang disebut MovieRating dengan menghapus definisi kelas yang ada dan menambahkan kode berikut di MovieRatingData.cs:
public class MovieRating
{
[LoadColumn(0)]
public float userId;
[LoadColumn(1)]
public float movieId;
[LoadColumn(2)]
public float Label;
}
MovieRating menentukan kelas data input. Atribut LoadColumn menentukan kolom mana (menurut indeks kolom) dalam himpunan data yang harus dimuat. Kolom userId dan movieId adalah milik Anda Features (input yang akan Anda berikan kepada model untuk memprediksi Label), dan kolom peringkat adalah Label yang akan Anda prediksi (output model).
Buat kelas lain, MovieRatingPrediction, untuk mewakili hasil yang diprediksi dengan menambahkan kode berikut setelah MovieRating kelas di MovieRatingData.cs:
public class MovieRatingPrediction
{
public float Label;
public float Score;
}
Di Program.cs, ganti Console.WriteLine("Hello World!") dengan kode berikut:
MLContext mlContext = new MLContext();
Kelas MLContext adalah titik awal untuk semua operasi ML.NET, dan menginisialisasi mlContext membuat lingkungan ML.NET baru yang dapat dibagikan di seluruh objek alur kerja pembuatan model. Ini mirip, secara konseptual, ke DBContext dalam Kerangka Kerja Entitas.
Di bagian bawah file, buat metode yang disebut LoadData():
(IDataView training, IDataView test) LoadData(MLContext mlContext)
{
}
Catatan
Metode ini akan memberi Anda kesalahan hingga Anda menambahkan pernyataan pengembalian dalam langkah-langkah berikut.
Inisialisasi variabel jalur data Anda, muat data dari file *.csv, dan kembalikan Train data dan Test sebagai IDataView objek dengan menambahkan yang berikut ini sebagai baris kode berikutnya di LoadData():
var trainingDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "recommendation-ratings-train.csv");
var testDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "recommendation-ratings-test.csv");
IDataView trainingDataView = mlContext.Data.LoadFromTextFile<MovieRating>(trainingDataPath, hasHeader: true, separatorChar: ',');
IDataView testDataView = mlContext.Data.LoadFromTextFile<MovieRating>(testDataPath, hasHeader: true, separatorChar: ',');
return (trainingDataView, testDataView);
Data dalam ML.NET direpresentasikan sebagai antarmuka IDataView.
IDataView adalah cara yang fleksibel dan efisien untuk menjelaskan data tabular (numerik dan teks). Data dapat dimuat dari file teks atau secara real time (misalnya, database SQL atau file log) ke IDataView objek.
LoadFromTextFile() mendefinisikan skema data dan membaca dalam file. Dibutuhkan variabel jalur data dan mengembalikan IDataView. Dalam hal ini, Anda menyediakan jalur untuk file dan Train Anda Test dan menunjukkan header file teks (sehingga dapat menggunakan nama kolom dengan benar) dan pemisah data karakter koma (pemisah default adalah tab).
Tambahkan kode berikut untuk memanggil metode Anda LoadData() dan mengembalikan Train data dan Test :
(IDataView trainingDataView, IDataView testDataView) = LoadData(mlContext);
Membangun dan melatih model Anda
BuildAndTrainModel() Buat metode , tepat setelah LoadData() metode , menggunakan kode berikut:
ITransformer BuildAndTrainModel(MLContext mlContext, IDataView trainingDataView)
{
}
Catatan
Metode ini akan memberi Anda kesalahan hingga Anda menambahkan pernyataan pengembalian dalam langkah-langkah berikut.
Tentukan transformasi data dengan menambahkan kode berikut ke BuildAndTrainModel():
IEstimator<ITransformer> estimator = mlContext.Transforms.Conversion.MapValueToKey(outputColumnName: "userIdEncoded", inputColumnName: "userId")
.Append(mlContext.Transforms.Conversion.MapValueToKey(outputColumnName: "movieIdEncoded", inputColumnName: "movieId"));
Karena userId dan movieId mewakili pengguna dan judul film, bukan nilai nyata, Anda menggunakan metode MapValueToKey() untuk mengubah masing-masing userIdmovieId menjadi kolom jenis Feature kunci numerik (format yang diterima oleh algoritma rekomendasi) dan menambahkannya sebagai kolom himpunan data baru:
| userId | movieId | Label | userIdEncoded | movieIdEncoded |
|---|---|---|---|---|
| 1 | 1 | 4 | userKey1 | movieKey1 |
| 1 | 3 | 4 | userKey1 | movieKey2 |
| 1 | 6 | 4 | userKey1 | movieKey3 |
Pilih algoritma pembelajaran mesin dan tambahkan ke definisi transformasi data dengan menambahkan yang berikut ini sebagai baris kode berikutnya di BuildAndTrainModel():
var options = new MatrixFactorizationTrainer.Options
{
MatrixColumnIndexColumnName = "userIdEncoded",
MatrixRowIndexColumnName = "movieIdEncoded",
LabelColumnName = "Label",
NumberOfIterations = 20,
ApproximationRank = 100
};
var trainerEstimator = estimator.Append(mlContext.Recommendation().Trainers.MatrixFactorization(options));
MatrixFactorizationTrainer adalah algoritma pelatihan rekomendasi Anda. Matrix Factorization adalah pendekatan umum untuk rekomendasi ketika Anda memiliki data tentang bagaimana pengguna telah menilai produk di masa lalu, yang terjadi untuk himpunan data dalam tutorial ini. Ada algoritma rekomendasi lain ketika Anda memiliki data yang berbeda yang tersedia (lihat bagian Algoritma rekomendasi lainnya di bawah ini untuk mempelajari lebih lanjut).
Dalam hal ini, Matrix Factorization algoritma menggunakan metode yang disebut "pemfilteran kolaboratif", yang mengasumsikan bahwa jika Pengguna 1 memiliki pendapat yang sama dengan Pengguna 2 pada masalah tertentu, maka Pengguna 1 lebih mungkin merasakan cara yang sama seperti Pengguna 2 tentang masalah yang berbeda.
Misalnya, jika pengguna 1 dan pengguna 2 menilai film serupa, maka Pengguna 2 lebih mungkin untuk menikmati film yang telah ditonton pengguna 1 dan dinilai tinggi:
Incredibles 2 (2018) |
The Avengers (2012) |
Guardians of the Galaxy (2014) |
|
|---|---|---|---|
| Pengguna 1 | Menonton dan menyukai film | Menonton dan menyukai film | Menonton dan menyukai film |
| Pengguna 2 | Menonton dan menyukai film | Menonton dan menyukai film | Belum menonton -- REKOMENDASIkan film |
Pelatih Matrix Factorization memiliki beberapa Opsi, yang dapat Anda baca lebih lanjut di bagian Hiperparameter algoritma di bawah ini.
Paskan model ke Train data dan kembalikan model terlatih dengan menambahkan yang berikut ini sebagai baris kode berikutnya dalam BuildAndTrainModel() metode :
Console.WriteLine("=============== Training the model ===============");
ITransformer model = trainerEstimator.Fit(trainingDataView);
return model;
Metode Fit() melatih model Anda dengan himpunan data pelatihan yang disediakan. Secara teknis, ia menjalankan Estimator definisi dengan mengubah data dan menerapkan pelatihan, dan mengembalikan model terlatih, yang merupakan Transformer.
Untuk informasi selengkapnya tentang alur kerja pelatihan model di ML.NET, lihat Apa itu ML.NET dan bagaimana cara kerjanya?.
Tambahkan yang berikut ini sebagai baris kode berikutnya di bawah panggilan ke LoadData() metode untuk memanggil metode Anda BuildAndTrainModel() dan mengembalikan model terlatih:
ITransformer model = BuildAndTrainModel(mlContext, trainingDataView);
Mengevaluasi model Anda
Setelah Melatih model, gunakan data pengujian untuk mengevaluasi performa model Anda.
EvaluateModel() Buat metode , tepat setelah BuildAndTrainModel() metode , menggunakan kode berikut:
void EvaluateModel(MLContext mlContext, IDataView testDataView, ITransformer model)
{
}
Test Ubah data dengan menambahkan kode berikut ke EvaluateModel():
Console.WriteLine("=============== Evaluating the model ===============");
var prediction = model.Transform(testDataView);
Metode Transform() membuat prediksi untuk beberapa baris input yang disediakan dari himpunan data pengujian.
Evaluasi model dengan menambahkan yang berikut ini sebagai baris kode berikutnya dalam EvaluateModel() metode :
var metrics = mlContext.Regression.Evaluate(prediction, labelColumnName: "Label", scoreColumnName: "Score");
Setelah Anda memiliki set prediksi, metode Evaluate() menilai model, yang membandingkan nilai yang diprediksi dengan aktual Labels dalam himpunan data pengujian dan mengembalikan metrik tentang performa model.
Cetak metrik evaluasi Anda ke konsol dengan menambahkan yang berikut ini sebagai baris kode berikutnya dalam EvaluateModel() metode :
Console.WriteLine("Root Mean Squared Error : " + metrics.RootMeanSquaredError.ToString());
Console.WriteLine("RSquared: " + metrics.RSquared.ToString());
Tambahkan berikut ini sebagai baris kode berikutnya di bawah panggilan ke BuildAndTrainModel() metode untuk memanggil metode Anda EvaluateModel() :
EvaluateModel(mlContext, testDataView, model);
Output sejauh ini akan terlihat mirip dengan teks berikut:
=============== Training the model ===============
iter tr_rmse obj
0 1.5403 3.1262e+05
1 0.9221 1.6030e+05
2 0.8687 1.5046e+05
3 0.8416 1.4584e+05
4 0.8142 1.4209e+05
5 0.7849 1.3907e+05
6 0.7544 1.3594e+05
7 0.7266 1.3361e+05
8 0.6987 1.3110e+05
9 0.6751 1.2948e+05
10 0.6530 1.2766e+05
11 0.6350 1.2644e+05
12 0.6197 1.2541e+05
13 0.6067 1.2470e+05
14 0.5953 1.2382e+05
15 0.5871 1.2342e+05
16 0.5781 1.2279e+05
17 0.5713 1.2240e+05
18 0.5660 1.2230e+05
19 0.5592 1.2179e+05
=============== Evaluating the model ===============
Rms: 0.994051469730769
RSquared: 0.412556298844873
Dalam output ini, ada 20 iterasi. Dalam setiap perulangan, ukuran kesalahan menurun dan menyangga lebih dekat dan mendekati 0.
root of mean squared error (RMS atau RMSE) digunakan untuk mengukur perbedaan antara nilai yang diprediksi model dan nilai himpunan data pengujian yang diamati. Secara teknis itu adalah akar kuadrat dari rata-rata kuadrat kesalahan. Semakin rendah, semakin baik modelnya.
R Squared menunjukkan seberapa baik data cocok dengan model. Rentang dari 0 hingga 1. Nilai 0 berarti bahwa data acak atau tidak dapat sesuai dengan model. Nilai 1 berarti bahwa model sama persis dengan data. Anda ingin skor Anda R Squared sedekat mungkin dengan 1.
Membangun model yang sukses adalah proses berulang. Model ini memiliki kualitas awal yang lebih rendah karena tutorial menggunakan himpunan data kecil untuk memberikan pelatihan model cepat. Jika Anda tidak puas dengan kualitas model, Anda dapat mencoba meningkatkannya dengan menyediakan himpunan data pelatihan yang lebih besar atau dengan memilih algoritma pelatihan yang berbeda dengan parameter hiper yang berbeda untuk setiap algoritma. Untuk informasi selengkapnya, lihat bagian Meningkatkan model Anda di bawah ini.
Gunakan model Anda
Sekarang Anda dapat menggunakan model terlatih Anda untuk membuat prediksi pada data baru.
UseModelForSinglePrediction() Buat metode , tepat setelah EvaluateModel() metode , menggunakan kode berikut:
void UseModelForSinglePrediction(MLContext mlContext, ITransformer model)
{
}
PredictionEngine Gunakan untuk memprediksi peringkat dengan menambahkan kode berikut ke UseModelForSinglePrediction():
Console.WriteLine("=============== Making a prediction ===============");
var predictionEngine = mlContext.Model.CreatePredictionEngine<MovieRating, MovieRatingPrediction>(model);
PredictionEngine adalah API kenyamanan, yang memungkinkan Anda melakukan prediksi pada satu instans data.
PredictionEngine tidak aman untuk utas. Dapat digunakan di lingkungan rangkaian tunggal atau prototipe. Untuk meningkatkan performa dan keamanan utas di lingkungan produksi, gunakan PredictionEnginePool layanan , yang menciptakan ObjectPoolPredictionEngine objek untuk digunakan di seluruh aplikasi Anda. Lihat panduan ini tentang cara menggunakan PredictionEnginePool dalam ASP.NET Core Web API.
Catatan
PredictionEnginePool ekstensi layanan saat ini dalam pratinjau.
Buat instans yang MovieRating dipanggil testInput dan berikan ke Mesin Prediksi dengan menambahkan yang berikut ini sebagai baris kode berikutnya dalam UseModelForSinglePrediction() metode :
var testInput = new MovieRating { userId = 6, movieId = 10 };
var movieRatingPrediction = predictionEngine.Predict(testInput);
Fungsi Predict() membuat prediksi pada satu kolom data.
Anda kemudian dapat menggunakan Score, atau peringkat yang diprediksi, untuk menentukan apakah Anda ingin merekomendasikan film dengan movieId 10 kepada pengguna 6. Semakin tinggi Score, semakin tinggi kemungkinan pengguna menyukai film tertentu. Dalam hal ini, katakanlah Anda merekomendasikan film dengan prediksi peringkat > 3.5.
Untuk mencetak hasilnya, tambahkan yang berikut ini sebagai baris kode berikutnya dalam UseModelForSinglePrediction() metode :
if (Math.Round(movieRatingPrediction.Score, 1) > 3.5)
{
Console.WriteLine("Movie " + testInput.movieId + " is recommended for user " + testInput.userId);
}
else
{
Console.WriteLine("Movie " + testInput.movieId + " is not recommended for user " + testInput.userId);
}
Tambahkan yang berikut ini sebagai baris kode berikutnya setelah panggilan ke EvaluateModel() metode untuk memanggil metode Anda UseModelForSinglePrediction() :
UseModelForSinglePrediction(mlContext, model);
Output metode ini akan terlihat mirip dengan teks berikut:
=============== Making a prediction ===============
Movie 10 is recommended for user 6
Simpan model Anda
Untuk menggunakan model Anda untuk membuat prediksi dalam aplikasi pengguna akhir, Anda harus terlebih dahulu menyimpan model.
SaveModel() Buat metode , tepat setelah UseModelForSinglePrediction() metode , menggunakan kode berikut:
void SaveModel(MLContext mlContext, DataViewSchema trainingDataViewSchema, ITransformer model)
{
}
Simpan model terlatih Anda dengan menambahkan kode berikut dalam SaveModel() metode :
var modelPath = Path.Combine(Environment.CurrentDirectory, "Data", "MovieRecommenderModel.zip");
Console.WriteLine("=============== Saving the model to a file ===============");
mlContext.Model.Save(model, trainingDataViewSchema, modelPath);
Metode ini menyimpan model terlatih Anda ke file .zip (di folder "Data"), yang kemudian dapat digunakan di aplikasi .NET lainnya untuk membuat prediksi.
Tambahkan yang berikut ini sebagai baris kode berikutnya setelah panggilan ke UseModelForSinglePrediction() metode untuk memanggil metode Anda SaveModel() :
SaveModel(mlContext, trainingDataView.Schema, model);
Menggunakan model tersimpan Anda
Setelah menyimpan model terlatih, Anda dapat menggunakan model di lingkungan yang berbeda. Lihat Menyimpan dan memuat model terlatih untuk mempelajari cara mengoprasionalkan model pembelajaran mesin terlatih di aplikasi.
Hasil
Setelah mengikuti langkah-langkah di atas, jalankan aplikasi konsol Anda (Ctrl + F5). Hasil Anda dari prediksi tunggal di atas harus mirip dengan yang berikut ini. Anda mungkin melihat peringatan atau memproses pesan, tetapi pesan ini telah dihapus dari hasil berikut untuk kejelasan.
=============== Training the model ===============
iter tr_rmse obj
0 1.5382 3.1213e+05
1 0.9223 1.6051e+05
2 0.8691 1.5050e+05
3 0.8413 1.4576e+05
4 0.8145 1.4208e+05
5 0.7848 1.3895e+05
6 0.7552 1.3613e+05
7 0.7259 1.3357e+05
8 0.6987 1.3121e+05
9 0.6747 1.2949e+05
10 0.6533 1.2766e+05
11 0.6353 1.2636e+05
12 0.6209 1.2561e+05
13 0.6072 1.2462e+05
14 0.5965 1.2394e+05
15 0.5868 1.2352e+05
16 0.5782 1.2279e+05
17 0.5713 1.2227e+05
18 0.5637 1.2190e+05
19 0.5604 1.2178e+05
=============== Evaluating the model ===============
Rms: 0.977175077487166
RSquared: 0.43233349213192
=============== Making a prediction ===============
Movie 10 is recommended for user 6
=============== Saving the model to a file ===============
Selamat! Anda sekarang telah berhasil membangun model pembelajaran mesin untuk merekomendasikan film. Anda dapat menemukan kode sumber untuk tutorial ini di repositori dotnet/samples .
Tingkatkan model Anda
Ada beberapa cara agar Anda dapat meningkatkan performa model sehingga Anda bisa mendapatkan prediksi yang lebih akurat.
Data
Menambahkan lebih banyak data pelatihan yang memiliki sampel yang cukup untuk setiap pengguna dan id film dapat membantu meningkatkan kualitas model rekomendasi.
Validasi silang adalah teknik untuk mengevaluasi model yang secara acak membagi data menjadi subset (alih-alih mengekstrak data pengujian dari himpunan data seperti yang Anda lakukan dalam tutorial ini) dan mengambil beberapa grup sebagai data pelatihan dan beberapa grup sebagai data pengujian. Metode ini mengungguli pembuatan pemisahan uji pelatihan dalam hal kualitas model.
Fitur
Dalam tutorial ini, Anda hanya menggunakan tiga Features (user id, , movie iddan rating) yang disediakan oleh himpunan data.
Meskipun ini adalah awal yang baik, pada kenyataannya Anda mungkin ingin menambahkan atribut lain atau Features (misalnya, usia, jenis kelamin, lokasi geografis, dll.) jika mereka disertakan dalam himpunan data. Menambahkan yang lebih relevan Features dapat membantu meningkatkan performa model rekomendasi Anda.
Jika Anda tidak yakin tentang mana yang Features mungkin paling relevan untuk tugas pembelajaran mesin Anda, Anda juga dapat menggunakan Perhitungan Kontribusi Fitur (FCC) dan kepentingan fitur permutasi, yang ML.NET berikan untuk menemukan yang paling berpengaruh Features.
Hiperparameter algoritma
Meskipun ML.NET menyediakan algoritma pelatihan default yang baik, Anda dapat menyempurnakan performa lebih lanjut dengan mengubah hiperparameter algoritma.
Untuk Matrix Factorization, Anda dapat bereksperimen dengan hiperparameter seperti NumberOfIterations dan ApproximationRank untuk melihat apakah itu memberi Anda hasil yang lebih baik.
Misalnya, dalam tutorial ini opsi algoritmanya adalah:
var options = new MatrixFactorizationTrainer.Options
{
MatrixColumnIndexColumnName = "userIdEncoded",
MatrixRowIndexColumnName = "movieIdEncoded",
LabelColumnName = "Label",
NumberOfIterations = 20,
ApproximationRank = 100
};
Algoritma Rekomendasi Lainnya
Algoritma faktorisasi matriks dengan pemfilteran kolaboratif hanyalah satu pendekatan untuk melakukan rekomendasi film. Dalam banyak kasus, Anda mungkin tidak memiliki data peringkat yang tersedia dan hanya memiliki riwayat film yang tersedia dari pengguna. Dalam kasus lain, Anda mungkin memiliki lebih dari sekadar data peringkat pengguna.
| Algoritma | Skenario | Sampel |
|---|---|---|
| Faktorisasi Matriks Satu Kelas | Gunakan ini jika Anda hanya memiliki userId dan movieId. Gaya rekomendasi ini didasarkan pada skenario pembelian bersama, atau produk yang sering dibeli bersama-sama, yang berarti akan merekomendasikan kepada pelanggan serangkaian produk berdasarkan riwayat pesanan pembelian mereka sendiri. | >Cobalah |
| Mesin Faktorisasi Sadar Bidang | Gunakan ini untuk membuat rekomendasi saat Anda memiliki lebih banyak Fitur di luar userId, productId, dan peringkat (seperti deskripsi produk atau harga produk). Metode ini juga menggunakan pendekatan pemfilteran kolaboratif. | >Cobalah |
Skenario pengguna baru
Salah satu masalah umum dalam pemfilteran kolaboratif adalah masalah cold start, yaitu ketika Anda memiliki pengguna baru tanpa data sebelumnya untuk menarik inferensi. Masalah ini sering diselesaikan dengan meminta pengguna baru untuk membuat profil dan, misalnya, menilai film yang telah mereka lihat di masa lalu. Meskipun metode ini menempatkan beberapa beban pada pengguna, metode ini menyediakan beberapa data awal untuk pengguna baru tanpa riwayat peringkat.
Sumber
Data yang digunakan dalam tutorial ini berasal dari Himpunan Data MovieLens.
Langkah berikutnya
Di tutorial ini, Anda akan mempelajari cara:
- Pilih algoritma pembelajaran mesin
- Menyiapkan dan memuat data Anda
- Membangun dan melatih model
- Mengevaluasi model
- Menyebarkan dan mengonsumsi model
Lanjutkan ke tutorial berikutnya untuk mempelajari lebih lanjut
Berkolaborasi dengan kami di GitHub
Sumber untuk konten ini dapat ditemukan di GitHub, yang juga dapat Anda gunakan untuk membuat dan meninjau masalah dan menarik permintaan. Untuk informasi selengkapnya, lihat panduan kontributor kami.