Cara membuat kumpulan Spark kustom di Microsoft Fabric
Dalam dokumen ini, kami menjelaskan cara membuat kumpulan Apache Spark kustom di Microsoft Fabric untuk beban kerja analitik Anda. Kumpulan Apache Spark memungkinkan pengguna untuk membuat lingkungan komputasi yang disesuaikan berdasarkan persyaratan spesifik mereka, memastikan performa dan pemanfaatan sumber daya yang optimal.
Anda menentukan simpul minimum dan maksimum untuk penskalaan otomatis. Berdasarkan nilai-nilai tersebut, sistem secara dinamis memperoleh dan menghentikan simpul saat persyaratan komputasi pekerjaan berubah, yang menghasilkan penskalaan yang efisien dan meningkatkan performa. Alokasi dinamis pelaksana di kumpulan Spark juga meringankan kebutuhan akan konfigurasi pelaksana manual. Sebaliknya, sistem menyesuaikan jumlah pelaksana tergantung pada volume data dan kebutuhan komputasi tingkat pekerjaan. Proses ini memungkinkan Anda untuk fokus pada beban kerja Anda tanpa khawatir tentang pengoptimalan performa dan manajemen sumber daya.
Catatan
Untuk membuat kumpulan Spark kustom, Anda memerlukan akses admin ke ruang kerja. Admin kapasitas harus mengaktifkan opsi Kumpulan ruang kerja yang dikustomisasi di bagian Komputasi Spark dari pengaturan Admin Kapasitas. Untuk mempelajari lebih lanjut, lihat Spark Compute Pengaturan untuk Fabric Capacities.
Membuat kumpulan Spark kustom
Untuk membuat atau mengelola kumpulan Spark yang terkait dengan ruang kerja Anda:
Buka ruang kerja Anda dan pilih Pengaturan ruang kerja.
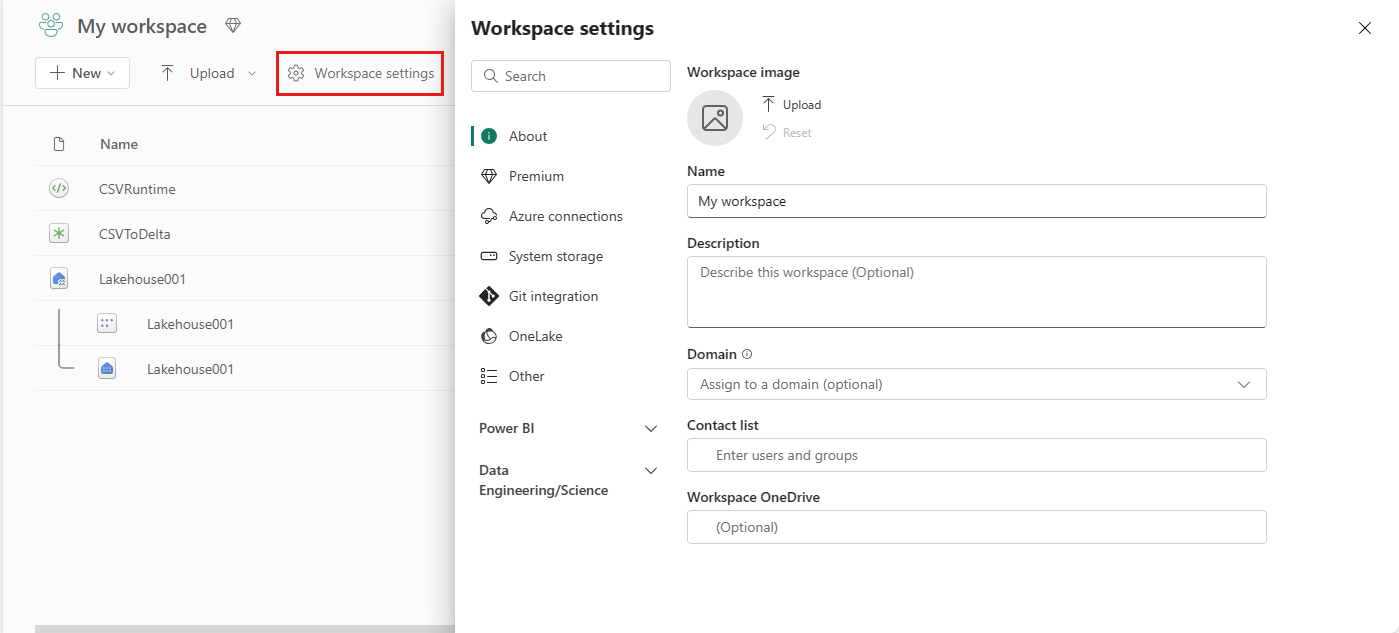
Pilih opsi Rekayasa Data/Sains untuk memperluas menu lalu pilih Spark Compute.

Pilih opsi Kumpulan Baru. Di layar Buat Kumpulan, beri nama kumpulan Spark Anda. Pilih juga keluarga Node, dan pilih ukuran Node dari ukuran yang tersedia (Kecil, Sedang, Besar, X-Besar, dan XX-Large) berdasarkan persyaratan komputasi untuk beban kerja Anda.
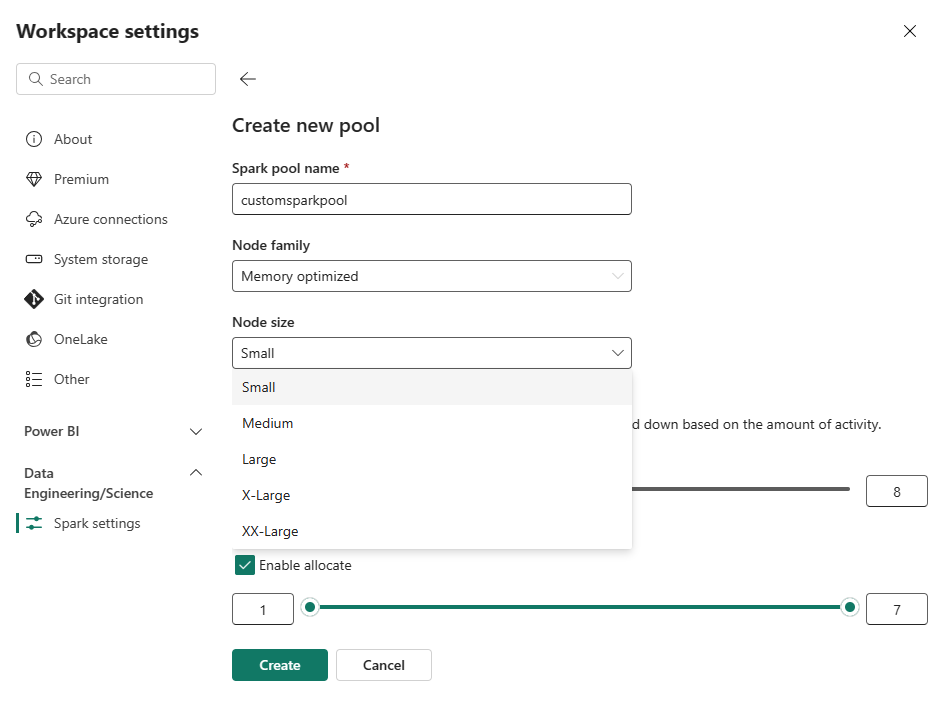
Anda dapat mengatur konfigurasi simpul minimum untuk kumpulan kustom Anda ke 1. Karena Fabric Spark menyediakan ketersediaan yang dapat disembuhkan untuk kluster dengan satu simpul, Anda tidak perlu khawatir tentang kegagalan pekerjaan, kehilangan sesi selama kegagalan, atau lebih dari membayar komputasi untuk pekerjaan Spark yang lebih kecil.
Anda dapat mengaktifkan atau menonaktifkan penskalaan otomatis untuk kumpulan Spark kustom Anda. Saat penskalaan otomatis diaktifkan, kumpulan akan secara dinamis memperoleh simpul baru hingga batas node maksimum yang ditentukan oleh pengguna, lalu menghentikannya setelah eksekusi pekerjaan. Fitur ini memastikan performa yang lebih baik dengan menyesuaikan sumber daya berdasarkan persyaratan pekerjaan. Anda diizinkan untuk mengukur simpul, yang sesuai dengan unit kapasitas yang dibeli sebagai bagian dari SKU kapasitas Fabric.
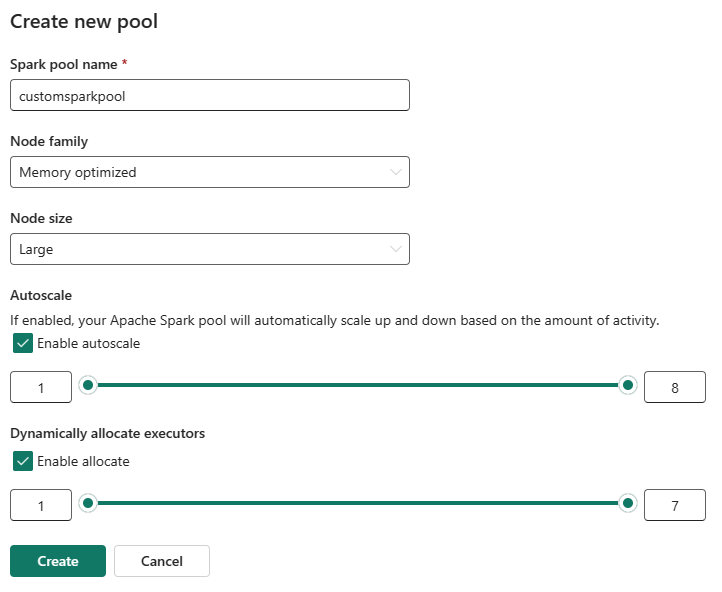
Anda juga dapat memilih untuk mengaktifkan alokasi pelaksana dinamis untuk kumpulan Spark Anda, yang secara otomatis menentukan jumlah pelaksana optimal dalam batas maksimum yang ditentukan pengguna. Fitur ini menyesuaikan jumlah pelaksana berdasarkan volume data, menghasilkan peningkatan performa dan pemanfaatan sumber daya.

Kumpulan kustom ini memiliki durasi autopause default 2 menit. Setelah durasi jeda otomatis tercapai, sesi kedaluwarsa dan kluster tidak dialokasikan. Anda dikenakan biaya berdasarkan jumlah simpul dan durasi penggunaan kumpulan Spark kustom.
Konten terkait
- Pelajari selengkapnya dari dokumentasi publik Apache Spark.
- Mulai menggunakan pengaturan administrasi ruang kerja Spark di Microsoft Fabric.
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk