Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Agen data Fabric memungkinkan organisasi untuk membangun sistem percakapan menggunakan AI generatif. Dengan menyambungkan model semantik Power BI sebagai sumber data, tim dapat mengajukan pertanyaan bahasa alami dan menerima jawaban yang akurat dan kaya konteks tanpa menulis kueri DAX atau SQL yang kompleks.
Namun, kualitas respons AI sangat bergantung pada seberapa baik Anda menyiapkan sumber data Anda. Meskipun agen data Fabric mendukung beberapa jenis sumber data termasuk lakehouse, gudang, eventhouse, dan ontologi, panduan ini berfokus khusus pada model semantik Power BI dan menelusuri praktik terbaik untuk mengonfigurasinya guna memaksimalkan akurasi dan relevansi.
Cara kerja agen data Fabric
Agen data menggunakan arsitektur berlapis tempat pertanyaan pengguna mengalir melalui Orchestrator. Orchestrator menentukan sumber data yang sesuai dan memanggil alat khusus, termasuk alat pembuatan DAX untuk model semantik Power BI untuk menghasilkan, memvalidasi, dan menjalankan kueri.
Proses pemrosesan kueri
Penguraian Pertanyaan: Agen memproses pertanyaan pengguna melalui Azure OpenAI, memastikan kepatuhan terhadap protokol dan izin keamanan dan mematuhi prinsip Microsoft Responsible AI.
Pemilihan Sumber Data: Sistem mengevaluasi pertanyaan terhadap sumber yang tersedia menggunakan informasi skema dan instruksi AI yang Anda berikan.
Pembuatan Kueri: Untuk model semantik, alat pembuatan DAX menghasilkan kueri DAX berdasarkan skema, metadata (sinonim, nilai min dan maks kolom numerik, metadata visual laporan, dan banyak lagi), konteks yang dikonfigurasi dalam Data persiapan untuk AI, dan riwayat percakapan.
Pemformatan Respons: Agen memformat hasil menjadi respons yang dapat dibaca manusia dengan tabel, ringkasan, atau wawasan berdasarkan instruksi agen.

Persiapan untuk AI: Siapkan AI model semantik
Fitur Prep for AI Power BI menyediakan tiga komponen konfigurasi yang berdampak langsung pada bagaimana agen data Fabric menginterpretasikan model semantik Anda. Anda dapat mengakses komponen ini di Power BI Desktop dan layanan Power BI. Power BI Copilot juga menggunakan konfigurasi Persiapan AI, jadi menginvestasikan waktu untuk melakukan pengaturan ini bermanfaat bagi respons dari Copilot dan agen data.
Penting
Saat membuat kueri model semantik, alat pembangkit DAX yang digunakan oleh agen data hanya bergantung pada metadata model semantik dan konfigurasi AI yang telah dipersiapkan. Alat pembuatan DAX mengabaikan instruksi apa pun yang Anda tambahkan di tingkat agen data untuk pembuatan kueri DAX. Persiapan yang Tepat untuk konfigurasi AI sangat penting untuk hasil yang akurat.
Skema data AI
Skema data AI memungkinkan Anda menentukan subset model yang berfokus untuk prioritas AI. Meskipun agen data juga memiliki pilihan tabelnya sendiri saat menambahkan model semantik sebagai sumber data, konfigurasikan skema Anda di Prep untuk AI terlebih dahulu. Alat pembuatan DAX menggunakan skema ini untuk membuat kueri DAX.
Anda bisa mengonfigurasi skema ini di Power BI Desktop atau layanan Power BI dengan memilih Siapkan data untuk AI dari pita Beranda. Kemudian, navigasikan ke tab Sederhanakan skema data . Dari sana, pilih tabel, kolom, dan pengukuran AI mana yang harus digunakan saat menghasilkan respons. Untuk instruksi penyiapan terperinci, lihat Mengatur skema data AI.

Saat Anda menambahkan model semantik ke agen data, pilih tabel yang sama dengan yang Anda tentukan di Persiapan untuk AI untuk memastikan perilaku yang konsisten. Pertama, tentukan cakupan agen data Anda (jenis pertanyaan yang harus dijawab). Kemudian, pilih hanya objek yang relevan. Pendekatan ini mengurangi ambiguitas, meningkatkan akurasi, dan mengurangi latensi respons.
Alat pembuatan DAX bergantung pada metadata model Anda untuk menafsirkan pertanyaan. Gunakan nama yang jelas dan ramah bisnis untuk tabel, kolom, dan pengukuran yang mencerminkan bagaimana pengguna secara alami merujuk ke data. Misalnya, gunakan 'Total Pendapatan' alih-alih 'TR_AMT' atau 'Wilayah Penjualan' alih-alih 'DIM_GEO_01'. Panduan ini sangat penting untuk model besar dengan bidang yang tumpang tindih atau bernama serupa, di mana nama ambigu dapat menyebabkan pembuatan kueri yang salah.
Contoh: Mengatasi ambiguitas bidang
| Tanpa Skema Data AI | Dengan Skema Data AI |
|---|---|
Pengguna bertanya: "What were our sales last quarter?" Model semantik berisi beberapa langkah terkait penjualan: Total Pendapatan, Penjualan Kotor, Penjualan Bersih, dan Penjualan Setelah Pengembalian. AI mengembalikan Gross Sales, tetapi tim Anda biasanya menggunakan Net Sales untuk pelaporan triwulanan. |
Setelah mengonfigurasi skema data AI untuk hanya menyertakan Penjualan Bersih dan mengecualikan langkah-langkah lain yang tidak relevan, pertanyaan yang sama sekarang mengembalikan metrik yang diharapkan. AI tidak lagi harus menebak ukuran "penjualan" yang dimaksudkan oleh pengguna. |
Tips untuk skema data AI
Untuk hasil yang konsisten dan akurat, pastikan Anda memilih tabel yang sama di agen data Fabric yang juga ditentukan melalui Skema Data AI di Persiapan untuk AI.
Saat memilih skema, sertakan juga objek dependen. Misalnya, jika ukuran Total Pendapatan mereferensikan dua langkah lain yang bergantung pada kolom tambahan, sertakan semua objek dependen tersebut dalam skema Anda. Untuk mengidentifikasi dependensi, gunakan fungsi get_measure_dependencies dari pustaka Semantic Link Labs .
Jika Anda memiliki model semantik besar, mengganti nama semua objek secara manual bisa melelahkan. Gunakan server MCP Pemodelan Power BI untuk membuat LLM menghasilkan nama yang ramah bisnis untuk tabel, kolom, dan pengukuran Anda. Tinjau dan validasi perubahan sebelum menyimpan untuk memastikan perubahan tidak merusak ekspresi, hubungan, atau objek dependen DAX apa pun.
Jawaban terverifikasi
Jawaban terverifikasi adalah respons visual yang disetujui pengguna yang memicu pertanyaan tertentu. Mereka memberikan respons yang konsisten dan andal terhadap pertanyaan umum atau kompleks yang mungkin disalahartikan. Karena Anda menyimpan jawaban terverifikasi di tingkat model semantik (bukan tingkat laporan), jawaban tersebut berfungsi di semua agen data yang menggunakan model yang sama. Untuk informasi selengkapnya, lihat Menyiapkan Data Anda untuk AI – Jawaban terverifikasi.
Saat Anda menggunakan jawaban terverifikasi dengan agen data, sistem tidak mengembalikan visual Power BI itu sendiri. Sebaliknya, ia menggunakan pertanyaan pengguna dan properti visual (kolom, pengukuran, filter) untuk memengaruhi pembuatan kueri DAX. Pendekatan ini berarti jawaban terverifikasi meningkatkan akurasi respons dengan memandu alat pembuatan DAX menuju struktur kueri yang benar. Ketika pengguna mengajukan pertanyaan ke agen data, sistem terlebih dahulu memeriksa kecocokan yang persis atau semantik dengan permintaan Anda yang ditentukan dalam jawaban terverifikasi sebelum menghasilkan respons baru.

Contoh: Menangani terminologi wilayah
| Tanpa Jawaban Terverifikasi | Dengan Jawaban Terverifikasi |
|---|---|
Pengguna bertanya: "Show me performance by territory" AI menginterpretasikan "wilayah" sebagai kategori produk karena ada kolom Wilayah dalam tabel Produk. Yang dimaksud pengguna sebenarnya adalah wilayah penjualan. |
Anda membuat jawaban terverifikasi menggunakan visual penjualan regional dengan pertanyaan pemicu seperti "What is the sales performance by territory?", "Tampilkan saya penjualan yang dipecah berdasarkan wilayah", dan "Bagaimana penjualan didistribusikan di seluruh wilayah?" Sekarang ketika pengguna bertanya tentang performa wilayah, mereka secara konsisten mendapatkan respons yang akurat berdasarkan objek yang digunakan dalam visual penjualan regional. |
Tips konfigurasi untuk jawaban terverifikasi
- Gunakan lima hingga tujuh pertanyaan pemicu per jawaban terverifikasi untuk mencakup variasi alami.
- Sertakan frasa formal dan percakapan yang mungkin digunakan oleh pengguna.
- Konfigurasikan hingga tiga filter untuk pemotongan fleksibel tanpa membuat beberapa jawaban terverifikasi.
- Jika Anda mengganti nama tabel, kolom, atau pengukuran apa pun yang direferensikan dalam jawaban terverifikasi, perbarui jawaban terverifikasi dan simpan lagi agar perubahan diterapkan.
Instruksi AI
Instruksi AI di Prep for AI menyediakan konteks, logika bisnis, dan panduan langsung pada model semantik. Mereka membantu mengklarifikasi terminologi, memandu pendekatan analisis, dan memberikan konteks bisnis dan semantik yang tidak akan dipahami oleh AI.
Anda bisa mengonfigurasi instruksi ini di Power BI Desktop atau layanan Power BI dengan memilih Menyiapkan data untuk AI dari pita Beranda, lalu menavigasi ke tab Tambahkan instruksi AI . Untuk instruksi penyiapan terperinci, lihat Dokumentasi Instruksi AI.

Instruksi AI adalah panduan yang tidak terstruktur yang ditafsirkan LLM, tetapi tidak ada jaminan yang mengikutinya dengan tepat. Instruksi yang jelas dan spesifik lebih efektif daripada instruksi yang kompleks atau bertentangan.
Seperti disebutkan sebelumnya, alat pembuatan DAX hanya mengacu pada instruksi AI yang dikonfigurasi dalam Prep untuk AI model semantik. Instruksi agen data tidak diteruskan ke alat dan diabaikan saat mengkueri model semantik. Untuk alasan ini, jangan tambahkan instruksi spesifik model semantik di tingkat agen data. Sebagai gantinya, simpan semua instruksi model semantik di Prep for AI tempat alat pembuatan DAX dapat menggunakannya. Instruksi agen data hanya boleh menyertakan panduan yang berlaku di semua sumber data yang dikonfigurasi dalam agen, seperti preferensi pemformatan respons umum, aturan perutean lintas sumber, singkatan umum, nada, dan sebagainya. Perhatikan juga bahwa tidak seperti sumber data lainnya, agen data tidak mendukung instruksi atau deskripsi sumber data untuk model semantik.
Contoh: Menentukan terminologi bisnis
| Tanpa Instruksi AI | Dengan Instruksi AI |
|---|---|
| Pengguna bertanya: "Siapa pemain berkinerja teratas bulan lalu?" AI tidak memahami arti "performer teratas" di organisasi Anda dan mengembalikan kesalahan atau meminta klarifikasi. | Anda menambahkan instruksi: "Pemain berkinerja teratas adalah perwakilan penjualan yang mencapai 110% atau lebih dari kuota bulanan mereka. Gunakan tabel Rep_Performance dan filter di mana Quota_Attainment >= 1,1" Sekarang AI menginterpretasikan pertanyaan dengan benar dan mengembalikan hasil yang tepat. |
Pola instruksi yang efektif
- Definisi Periode Waktu: "Peak season berlangsung dari November hingga Januari. Di luar musim adalah Februari hingga April."
- Preferensi Metrik: "Ketika pengguna bertanya tentang profitabilitas, gunakan ukuran Contribution_Margin, bukan Gross_Profit."
- Perutean Sumber Data: "Untuk pertanyaan inventarisasi, prioritaskan tabel Warehouse_Inventory di atas Sales_Orders."
- Pengelompokan Default: "Kecuali ditentukan sebaliknya, analisis pendapatan berdasarkan triwulan fiskal daripada bulan kalender."
Selain Persiapan untuk AI, alat pembuatan kueri DAX juga menggunakan metadata dari visual laporan seperti judul visual, kolom, pengukuran, filter, dan sebagainya untuk meningkatkan akurasi kueri.
Alur kerja implementasi yang direkomendasikan
Optimalkan Model Semantik: Mulailah dengan mengoptimalkan model semantik Anda untuk performa. Performa agen data yang buruk sering kali berasal dari model semantik yang dirancang dengan buruk, ukuran DAX yang tidak efisien, atau campuran keduanya. Saat pengguna mengajukan pertanyaan, agen data menghasilkan kueri DAX dan menjalankannya terhadap model Anda. Model yang dioptimalkan dengan baik menggunakan lebih sedikit sumber daya dan mencapai eksekusi kueri yang lebih cepat. Dalam antarmuka percakapan, pengguna mengharapkan respons cepat, sehingga performa lambat secara langsung berdampak pada pengalaman dan adopsi pengguna.
Selain itu, model yang kembung dengan kolom, tabel, dan pengukuran yang tidak perlu menciptakan lebih banyak gangguan bagi alat pembuatan DAX untuk diproses, yang dapat mengurangi akurasi respons. Dengan mengoptimalkan model lebih awal, Anda juga mencegah masalah performa saat data Anda tumbuh dan model menjadi lebih kompleks. Anda bisa mempelajari selengkapnya dalam kursus Mengoptimalkan model untuk performa di Power BI .
Gunakan Penganalisis Praktik Terbaik dan Penganalisis Memori Model Semantik dalam buku catatan Fabric untuk mengidentifikasi masalah seperti jenis data yang salah, kolom yang tidak perlu, kolom kardinalitas tinggi, dan pola DAX yang tidak efisien. Tambahkan deskripsi ke tabel, kolom, dan pengukuran untuk membantu LLM memahami tujuan setiap objek yang disertakan dalam skema data AI.
Tentukan Persiapan untuk AI > Skema Data AI: Berdasarkan cakupan agen data Anda, konfigurasikan skema data AI di Persiapan untuk AI dengan hanya memilih tabel, kolom, dan pengukuran yang relevan dengan pertanyaan yang harus dijawab agen Anda.
Membuat Persiapan untuk AI > Jawaban Terverifikasi: Identifikasi pertanyaan paling umum Anda dan konfigurasikan jawaban terverifikasi di Persiapan untuk AI menggunakan visual yang sesuai. Gunakan pertanyaan lengkap dan kuat sebagai pemicu (bukan frasa parsial) untuk meningkatkan akurasi pencocokan.
Tambahkan Model Semantik ke agen data: Sebelum menambahkan instruksi AI di Persiapan untuk AI, uji dan validasi respons dari agen data. Langkah ini membantu Anda memahami di mana instruksi AI diperlukan untuk meningkatkan pembuatan kueri DAX.
Tambahkan Persiapan untuk AI > Instruksi AI: Berdasarkan temuan validasi Anda, tentukan terminologi bisnis, preferensi analisis, dan prioritas sumber data dalam instruksi Persiapan untuk AI (bukan dalam instruksi agen data).
Menyiapkan visual laporan: Tinjau laporan yang terhubung ke model semantik, termasuk visual dan halaman tersembunyi, untuk memastikan visual memiliki judul deskriptif. Visual terstruktur dengan baik membantu AI membumikan respons menggunakan metadata visual seperti judul visual, tabel, kolom, pengukuran yang digunakan, filter diterapkan, dan banyak lagi.
Verifikasi dan uji DAX: Akurasi respons tergantung pada kueri DAX yang dihasilkan. Saat menguji agen data Anda, tinjau kueri DAX di setiap respons untuk memverifikasi bahwa kueri tersebut valid dan menjawab pertanyaan dengan benar. Jika hasilnya salah, analisis DAX untuk mengidentifikasi konfigurasi mana (model semantik, skema data AI, jawaban terverifikasi, atau instruksi AI) yang memerlukan penyesuaian.
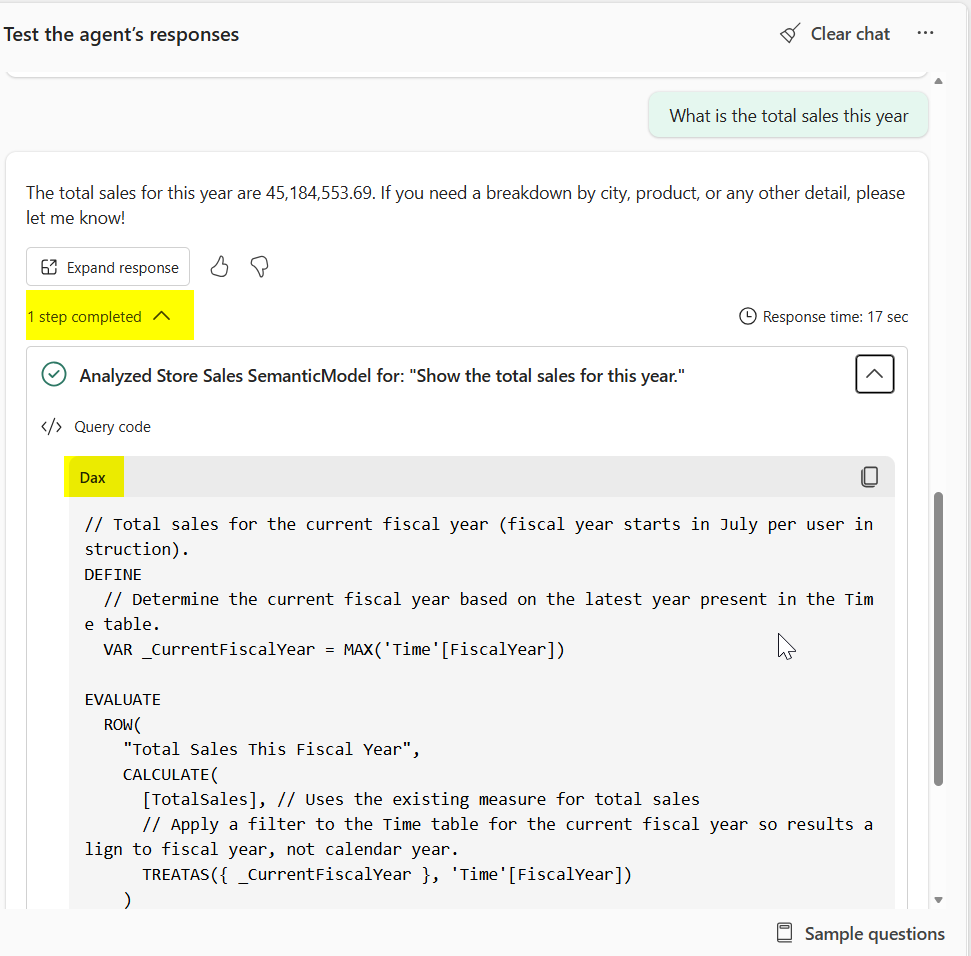
Mengonfigurasi Instruksi agen data: Tambahkan instruksi di tingkat agen data hanya untuk panduan yang berlaku di semua sumber data yang dikonfigurasi di agen. Panduan ini mencakup preferensi pemformatan respons umum, aturan perutean lintas sumber, singkatan umum, dan nada. Jangan tambahkan instruksi spesifik model semantik di sini karena tidak diteruskan ke alat generasi DAX. Untuk panduan tentang mengonfigurasi instruksi agen, lihat panduan konfigurasi.
Validasi & Iterasi: LLM dapat menghasilkan hasil yang salah tanpa konteks yang tepat. Lakukan iterasi secara terus-menerus terhadap konfigurasi Anda dan memvalidasi respons agar membangun kepercayaan pada agen data Anda. Untuk mengevaluasi respons secara terprogram, Anda dapat menggunakan agen data Fabric Python SDK untuk menjalankan evaluasi otomatis terhadap pasangan jawaban atas pertanyaan kebenaran dasar dan menganalisis metrik akurasi. Perhatikan bahwa SDK hanya untuk evaluasi dalam hal ini dan tidak dapat memodifikasi Persiapan model semantik untuk konfigurasi AI. Untuk detailnya, lihat Mengevaluasi agen data Anda. Selain itu, libatkan pemangku kepentingan dan pengguna akhir dalam proses evaluasi. Umpan balik mereka memastikan bahwa respons selaras dengan harapan dan kegunaan dunia nyata, membantu Anda mengidentifikasi celah yang mungkin terlewatkan oleh pemeriksaan otomatis.
Menerapkan Kontrol Sumber dan Alur Penyebaran: Gunakan alur integrasi dan penyebaran Git untuk mengelola konfigurasi agen data Anda di seluruh ruang kerja pengembangan, pengujian, dan produksi. Praktik ini memastikan perubahan konfigurasi diuji dan divalidasi sebelum dipromosikan ke produksi tempat pengguna akhir mengaksesnya. Untuk detailnya, lihat Kontrol Sumber, CI/CD, dan ALM untuk agen data Fabric.


Petunjuk / Saran
Anda dapat menggunakan sumber daya dalam repositori fabric-toolbox sebagai referensi untuk membantu Anda melalui alur kerja ini. Repositori ini berisi:
- Daftar periksa untuk menyiapkan dan mengonfigurasi model semantik sebagai sumber data
- buku catatan Utilitas agen data dengan cuplikan kode yang berguna dan fungsi pembantu
Perangkap umum untuk dihindari
Tidak menggunakan skema bintang: Model semantik yang menggunakan tabel datar dan denormalisasi atau struktur data pivot membuat DAX kurang efisien dan lebih sulit ditulis dengan benar. DAX dioptimalkan untuk skema bintang dengan tabel fakta dan dimensi yang jelas. Batalkan pivot dari tabel dengan format lebar menjadi struktur yang dinormalisasi di mana setiap baris mewakili satu pengamatan.
Mengandalkan bidang tersembunyi: Jawaban terverifikasi tidak akan berfungsi jika mereferensikan kolom tersembunyi dalam model.
Termasuk langkah-langkah yang tidak perlu: Model semantik sering berisi tindakan pembantu dan objek perantara yang digunakan untuk meningkatkan interaktivitas laporan. Saat mengonfigurasi skema data AI Anda, sertakan hanya langkah-langkah yang menghitung metrik bisnis aktual. Mengecualikan langkah-langkah pembantu mengurangi kebisingan dan membantu alat pembuatan DAX menghasilkan kueri yang lebih akurat.
Tindakan duplikat atau tumpang tindih: Beberapa langkah yang menghitung metrik serupa (misalnya, Total Penjualan, Jumlah Penjualan, Pendapatan) menciptakan ambiguitas. Mengonsolidasikan atau membedakan langkah-langkah dengan jelas dan mengecualikan duplikat dari skema data AI Anda.
Penamaan non-deskriptif: Nama objek seperti TR_AMT, F_SLS, atau DIM_GEO_01 tidak menyediakan konteks untuk alat pembuatan DAX. Gunakan nama yang jelas dan ramah bisnis seperti Total Pendapatan, Penjualan, atau Geografi Pelanggan. Jika Anda tidak dapat mengganti nama objek, pastikan deskripsi dan sinonim memberikan konteks yang diperlukan bagi AI untuk memahami tujuannya.
Mengandalkan langkah-langkah implisit: Tindakan implisit dapat menyebabkan hasil yang tidak dapat diprediksi. Buat langkah-langkah DAX eksplisit untuk perhitungan yang Anda inginkan agar dikueri pengguna, dan atur ringkasan default yang benar (Jumlah, Rata-rata, Tidak Ada, dan sebagainya) pada kolom numerik untuk mencegah agregasi yang tidak diinginkan.
Bidang tanggal ambigu: Beberapa kolom tanggal (Tanggal Pesanan, Tanggal Pengiriman, Tanggal Jatuh Tempo, Kuartal Kalender/Kuartal FY, dan sebagainya) tanpa panduan yang jelas membingungkan AI. Gunakan jawaban terverifikasi dan instruksi AI di Persiapan untuk AI untuk menentukan bidang tanggal mana yang akan digunakan secara default atau untuk jenis pertanyaan tertentu.
Instruksi yang bertentangan: Instruksi AI yang bertentangan dengan konfigurasi Jawaban Terverifikasi membuat perilaku yang tidak dapat diprediksi.
Melompati penyempurnaan skema: Model besar dengan banyak bidang bernama serupa membutuhkan skema data AI yang berfokus.
Instruksi yang terlalu kompleks: Jaga agar instruksi tetap fokus dan spesifik. AI menafsirkan tetapi tidak menjamin mengikuti panduan yang kompleks dan bertentangan. Instruksi kompleks juga dapat menambah latensi.
Tools
Untuk mengikuti panduan ini, Anda dapat menggunakan alat di bawah ini dari repositori GitHub fabric-toolbox:
- Daftar periksa dengan rekomendasi. Ini adalah panduan dan tidak semua item dalam daftar periksa mungkin berlaku untuk skenario Anda.
- Notebook berisi kumpulan utilitas di satu tempat.
- Power BI MCP Server untuk mempercepat pengembangan dan pengujian di Visual Studio Code
- Semantic link labs pustaka untuk memperbarui model semantik secara programatis dalam buku catatan Fabric.
Sumber daya tambahan
- Dokumentasi konsep agen data Fabric
- Kotak alat fabric dengan daftar periksa dan notebook
- Menambahkan model semantik sebagai sumber data ke agen data
- Menyiapkan data Anda untuk AI di Power BI
- Optimalkan model semantik Anda untuk Copilot
- Mengoptimalkan model untuk performa di Power BI - Pelatihan
- Tanya Jawab Umum untuk Persiapan untuk AI