Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Gunakan dependensi fungsi untuk membersihkan data. Dependensi fungsional ada saat satu kolom dalam model semantik (himpunan data Power BI) bergantung pada kolom lain. Misalnya, ZIP code kolom dapat menentukan nilai dalam city kolom. Dependensi fungsi muncul sebagai hubungan satu-ke-banyak antara nilai dalam dua kolom atau lebih dalam DataFrame. Tutorial ini menggunakan himpunan data Synthea untuk menunjukkan bagaimana dependensi fungsi membantu mendeteksi masalah kualitas data.
Dalam tutorial ini, Anda mempelajari cara:
- Terapkan pengetahuan domain untuk membentuk hipotesis tentang dependensi fungsi dalam model semantik.
- Kenali komponen pustaka Semantic Link Python (SemPy) yang mengotomatiskan analisis kualitas data. Komponen-komponen ini meliputi:
-
FabricDataFrame—struktur seperti panda dengan informasi semantik tambahan. - Fungsi yang mengotomatiskan evaluasi hipotesis tentang dependensi fungsional dan mengidentifikasi pelanggaran dalam model semantik Anda.
-
Prasyarat
Dapatkan langganan Microsoft Fabric . Atau, daftar untuk uji coba Microsoft Fabric gratis.
Masuk ke Microsoft Fabric.
Beralih ke Fabric dengan menggunakan pengalih pengalaman di sisi kiri bawah halaman beranda Anda.

- Pilih Ruang Kerja di panel navigasi, lalu pilih ruang kerja Anda untuk mengaturnya sebagai ruang kerja saat ini.
Ikuti penjelasan di buku catatan
Gunakan buku catatan data_cleaning_functional_dependencies_tutorial.ipynb untuk mengikuti tutorial ini.
Untuk membuka buku catatan yang menyertai tutorial ini, ikuti instruksi di Menyiapkan sistem Anda untuk tutorial ilmu data mengimpor buku catatan ke ruang kerja Anda.
Jika Anda lebih suka menyalin dan menempelkan kode dari halaman ini, Anda bisa membuat buku catatan baru.
Pastikan untuk melampirkan lakehouse ke notebook sebelum Anda mulai menjalankan kode.
Menyiapkan buku catatan
Di bagian ini, Anda menyiapkan lingkungan notebook.
Periksa versi Spark Anda. Jika Anda menggunakan Spark 3.4 atau yang lebih baru di Microsoft Fabric, Semantic Link disertakan secara default, sehingga Anda tidak perlu menginstalnya. Jika Anda menggunakan Spark 3.3 atau yang lebih lama, atau Anda ingin memperbarui ke Semantic Link terbaru, jalankan perintah berikut.
%pip install -U semantic-linkImpor modul yang Anda gunakan di buku catatan ini.
import pandas as pd import sempy.fabric as fabric from sempy.fabric import FabricDataFrame from sempy.dependencies import plot_dependency_metadataUnduh data sampel. Dalam tutorial ini, gunakan himpunan data Synthea dari catatan medis sintetis (versi kecil untuk kesederhanaan).
download_synthea(which='small')
Menjelajahi data
Menginisialisasi
FabricDataFramedengan konten file providers.csv .providers = FabricDataFrame(pd.read_csv("synthea/csv/providers.csv")) providers.head()Periksa masalah kualitas data dengan fungsi SemPy
find_dependenciesdengan merencanakan grafik dependensi fungsi yang terdeteksi otomatis.deps = providers.find_dependencies() plot_dependency_metadata(deps)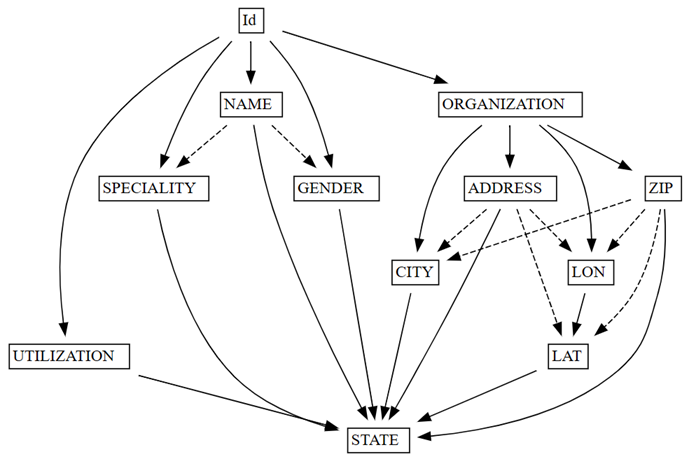
Grafik menunjukkan yang
IdmenentukanNAMEdanORGANIZATION. Hasil ini diharapkan karenaIdunik.Konfirmasikan bahwa
Iditu unik.providers.Id.is_uniqueKode mengembalikan
Trueuntuk mengonfirmasi bahwaIdunik.

Menganalisis dependensi fungsi secara mendalam
Grafik dependensi fungsi ini juga menunjukkan bahwa ORGANIZATION menentukan ADDRESS dan ZIP, seperti yang diharapkan. Namun, Anda mungkin mengharapkan ZIP juga menentukan CITY, tetapi panah putus-putus menunjukkan bahwa ketergantungan tersebut hanya bersifat perkiraan, menunjuk ke masalah kualitas data.
Ada kekhasan lain dalam grafik. Misalnya, NAME tidak menentukan GENDER, Id, SPECIALITY, atau ORGANIZATION. Masing-masing kekhasan ini mungkin layak diselidiki.
- Lihat lebih dalam perkiraan hubungan antara
ZIPdanCITYdengan menggunakan fungsi SemPylist_dependency_violationsuntuk mencantumkan pelanggaran:
providers.list_dependency_violations('ZIP', 'CITY')
- Buat grafik dengan fungsi visualisasi
plot_dependency_violationsSemPy. Grafik ini berguna jika jumlah pelanggaran kecil:
providers.plot_dependency_violations('ZIP', 'CITY')
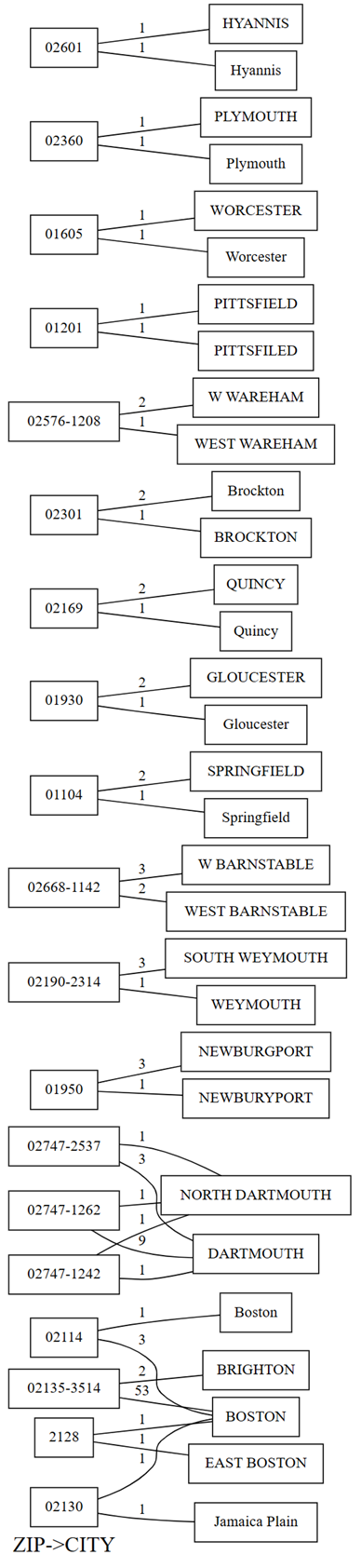
Plot pelanggaran dependensi menunjukkan nilai untuk ZIP di sisi kiri dan nilai untuk CITY di sisi kanan. Tepi menghubungkan kode pos di sisi kiri plot dengan kota di sisi kanan jika ada baris yang berisi dua nilai ini. Garis tepi diannotasi dengan jumlah baris yang sesuai. Misalnya, ada dua baris dengan kode pos 02747-1242, satu baris dengan kota "NORTH DARTHMOUTH" dan yang lainnya dengan kota "DARTHMOUTH", seperti yang ditunjukkan pada plot sebelumnya dan kode berikut:
- Konfirmasikan pengamatan dari plot dengan menjalankan kode berikut:
providers[providers.ZIP == '02747-1242'].CITY.value_counts()
Plot ini juga menunjukkan bahwa, di antara baris yang memiliki
CITY"DARTHMOUTH", sembilan baris memilikiZIP02747-1262. Satu baris memilikiZIP02747-1242. Satu baris memilikiZIP02747-2537. Konfirmasikan pengamatan ini dengan kode berikut:providers[providers.CITY == 'DARTHMOUTH'].ZIP.value_counts()Ada kode pos lain yang terkait dengan "DARTMOUTH", tetapi kode pos ini tidak ditampilkan dalam grafik pelanggaran dependensi karena tidak mengisyaratkan masalah kualitas data. Misalnya, kode pos "02747-4302" secara unik dikaitkan dengan "DARTMOUTH" dan tidak muncul dalam grafik pelanggaran dependensi. Konfirmasikan dengan menjalankan kode berikut:
providers[providers.ZIP == '02747-4302'].CITY.value_counts()
Meringkas masalah kualitas data yang terdeteksi dengan SemPy
Grafik pelanggaran dependensi menunjukkan beberapa masalah kualitas data dalam model semantik ini:
- Beberapa nama kota adalah huruf besar. Gunakan metode string untuk memperbaiki masalah ini.
- Beberapa nama kota memiliki kualifikasi (atau awalan), seperti "Utara" dan "Timur". Misalnya, Kode Pos "2128" memetakan ke "EAST BOSTON" sekali dan ke "BOSTON" sekali. Masalah serupa terjadi antara "NORTH DARTMOUTH" dan "DARTMOUTH". Jatuhkan kualifikasi ini atau petakan Kode Pos ke kota dengan kejadian yang paling umum.
- Ada kesalahan ketik dalam beberapa nama kota, seperti "PITTSFIELD" vs. "PITTSFILED" dan "NEWBURGPORT" vs. "NEWBURYPORT." Untuk "NEWBURGPORT", perbaiki kesalahan ketik ini dengan menggunakan kejadian yang paling umum. Untuk "PITTSFIELD," dengan hanya satu kemunculan masing-masing, disambiguasi otomatis jauh lebih sulit tanpa pengetahuan eksternal atau model bahasa.
- Terkadang, awalan seperti "Barat" disingkat dengan huruf tunggal "W." Ganti "W" dengan "Barat" jika semua kejadian "W" adalah singkatan dari "Barat."
- Kode Pos "02130" memetakan ke "BOSTON" sekali dan "Jamaika Plain" sekali. Masalah ini tidak mudah diperbaiki. Dengan lebih banyak data, petakan ke kejadian yang paling umum.
Membersihkan data
Perbaiki kapitalisasi dengan mengubah nilai menjadi huruf besar/kecil.
providers['CITY'] = providers.CITY.str.title()Jalankan deteksi pelanggaran lagi untuk mengonfirmasi bahwa ada lebih sedikit ambiguitas.
providers.list_dependency_violations('ZIP', 'CITY')
Persingkat data secara manual, atau jatuhkan baris yang melanggar batasan fungsional antar kolom dengan menggunakan fungsi SemPy drop_dependency_violations .
Untuk setiap nilai variabel determinan, drop_dependency_violations memilih nilai paling umum dari variabel dependen dan menghilangkan semua baris dengan nilai lain. Terapkan operasi ini hanya jika Anda yakin bahwa heuristik statistik ini mengarah pada hasil yang benar untuk data Anda. Jika tidak, tulis kode Anda sendiri untuk menangani pelanggaran yang terdeteksi.
Jalankan
drop_dependency_violationsfungsi padaZIPkolom danCITY.providers_clean = providers.drop_dependency_violations('ZIP', 'CITY')Cantumkan pelanggaran dependensi antara
ZIPdanCITY.providers_clean.list_dependency_violations('ZIP', 'CITY')
Kode mengembalikan daftar kosong untuk menunjukkan bahwa tidak ada lagi pelanggaran batasan fungsi.ZIP -> CITY
Konten terkait
Lihat tutorial lain untuk tautan semantik atau SemPy:
- tutorial : Menganalisis dependensi fungsi dalam contoh model semantik
- Tutorial : Mengekstrak dan menghitung pengukuran Power BI dari notebook Jupyter
- Tutorial: Menemukan hubungan dalam model semantik menggunakan tautan semantik
- Tutorial: Menemukan hubungan dalam himpunan data Synthea menggunakan tautan semantik
- Tutorial : Memvalidasi data menggunakan SemPy dan Great Expectations (GX)