Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Tutorial ini menggambarkan cara mendeteksi hubungan di publik Synthea himpunan data, menggunakan tautan semantik.
Saat Anda bekerja dengan data baru atau bekerja tanpa model data yang ada, akan sangat membantu untuk menemukan hubungan secara otomatis. Deteksi hubungan ini dapat membantu Anda untuk:
- memahami model pada tingkat tinggi,
- mendapatkan lebih banyak wawasan selama analisis data eksploratif,
- memvalidasi data yang diperbarui atau data baru yang masuk, dan
- bersihkan data.
Bahkan jika hubungan diketahui sebelumnya, pencarian hubungan dapat membantu pemahaman yang lebih baik tentang model data atau identifikasi masalah kualitas data.
Dalam tutorial ini, Anda memulai dengan contoh garis besar sederhana di mana Anda hanya bereksperimen dengan tiga tabel sehingga koneksi di antara mereka mudah diikuti. Kemudian, Anda menampilkan contoh yang lebih kompleks dengan kumpulan tabel yang lebih besar.
Dalam tutorial ini, Anda mempelajari cara:
- Gunakan komponen pustaka Python tautan semantik (SemPy) yang mendukung integrasi dengan Power BI dan membantu mengotomatiskan analisis data. Komponen-komponen ini meliputi:
- FabricDataFrame - struktur seperti panda yang ditingkatkan dengan informasi semantik tambahan.
- Fungsi untuk menarik model semantik dari ruang kerja Fabric ke notebook Anda.
- Fungsi yang mengotomatiskan penemuan dan visualisasi hubungan dalam model semantik Anda.
- Mengatasi masalah dalam proses penemuan hubungan untuk model semantik yang melibatkan banyak tabel dan interdependensi.
Prasyarat
Dapatkan langganan Microsoft Fabric . Atau, daftar untuk uji coba Microsoft Fabric gratis.
Masuk ke Microsoft Fabric.
Beralih ke Fabric dengan menggunakan pengalih pengalaman di sisi kiri bawah halaman beranda Anda.

- Pilih Ruang Kerja dari panel navigasi kiri untuk menemukan dan memilih ruang kerja Anda. Ruang kerja ini menjadi ruang kerja Anda saat ini.
Ikuti langkah-langkah dalam buku catatan
Notebook relationships_detection_tutorial.ipynb menyertai tutorial ini.
Untuk membuka buku catatan yang menyertai tutorial ini, ikuti instruksi di Menyiapkan sistem Anda untuk tutorial ilmu data mengimpor buku catatan ke ruang kerja Anda.
Jika Anda lebih suka menyalin dan menempelkan kode dari halaman ini, Anda bisa membuat buku catatan baru.
Pastikan untuk melampirkan lakehouse pada notebook sebelum Anda mulai jalankan kode.
Menyiapkan buku catatan
Di bagian ini, Anda menyiapkan lingkungan notebook dengan modul dan data yang diperlukan.
Instal
SemPydari PyPI menggunakan fitur penginstalan sebaris%pipdalam notebook.%pip install semantic-linkLakukan impor modul SemPy yang diperlukan nanti:
import pandas as pd from sempy.samples import download_synthea from sempy.relationships import ( find_relationships, list_relationship_violations, plot_relationship_metadata )Impor pandas untuk menetapkan opsi konfigurasi yang membantu memformat keluaran:
import pandas as pd pd.set_option('display.max_colwidth', None)Ambillah data sampel. Untuk tutorial ini, Anda menggunakan Synthea himpunan data catatan medis sintetis (versi kecil untuk kesederhanaan):
download_synthea(which='small')
Mendeteksi hubungan pada subset kecil tabel Synthea
Pilih tiga tabel dari set yang lebih besar:
-
patientsmenentukan informasi pasien -
encountersmenentukan pasien yang mengalami pertemuan medis (misalnya, janji temu medis, prosedur) -
providersmenentukan penyedia medis mana yang merawat pasien
Tabel
encountersmenyelesaikan hubungan banyak ke banyak antarapatientsdanprovidersdan dapat dijelaskan sebagai entitas asosiatif :patients = pd.read_csv('synthea/csv/patients.csv') providers = pd.read_csv('synthea/csv/providers.csv') encounters = pd.read_csv('synthea/csv/encounters.csv')-
Temukan hubungan antara tabel menggunakan fungsi
find_relationshipsSemPy:suggested_relationships = find_relationships([patients, providers, encounters]) suggested_relationshipsVisualisasikan hubungan DataFrame sebagai grafik, menggunakan fungsi
plot_relationship_metadataSemPy.plot_relationship_metadata(suggested_relationships)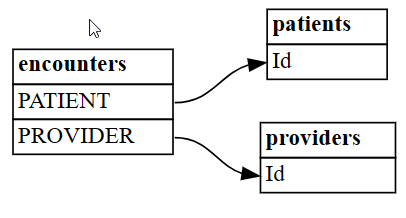
Fungsi ini menjabarkan hierarki hubungan dari sisi kiri ke sisi kanan, yang sesuai dengan tabel "dari" dan "ke" dalam output. Dengan kata lain, tabel "dari" independen di sisi kiri menggunakan kunci asing mereka untuk menunjuk ke tabel dependensi "ke" mereka di sisi kanan. Setiap kotak entitas menampilkan kolom-kolom yang berpartisipasi dalam sisi "dari" atau "ke" dalam suatu relasi.
Secara default, hubungan dihasilkan sebagai "m:1" (bukan sebagai "1:m") atau "1:1". Hubungan "1:1" dapat dihasilkan dalam satu arah atau kedua arah, tergantung pada apakah rasio nilai yang dipetakan dari semua nilai melebihi
coverage_thresholdhanya dalam satu atau kedua arah. Kemudian dalam tutorial ini, Anda akan membahas kasus hubungan "m:m" yang jarang terjadi.

Memecahkan masalah deteksi hubungan
Contoh garis besar menunjukkan deteksi hubungan yang berhasil pada data Synthea yang bersih. Dalam praktiknya, data jarang bersih, yang mencegah keberhasilan deteksi. Ada beberapa teknik yang dapat berguna ketika data tidak bersih.
Bagian tutorial ini membahas deteksi hubungan ketika model semantik berisi data kotor.
Mulailah dengan memanipulasi DataFrames asli untuk mendapatkan data "kotor", dan cetak ukuran data kotor.
# create a dirty 'patients' dataframe by dropping some rows using head() and duplicating some rows using concat() patients_dirty = pd.concat([patients.head(1000), patients.head(50)], axis=0) # create a dirty 'providers' dataframe by dropping some rows using head() providers_dirty = providers.head(5000) # the dirty dataframes have fewer records than the clean ones print(len(patients_dirty)) print(len(providers_dirty))Sebagai perbandingan, ukuran cetak tabel asli:
print(len(patients)) print(len(providers))Temukan hubungan antara tabel menggunakan fungsi
find_relationshipsSemPy:find_relationships([patients_dirty, providers_dirty, encounters])Output kode menunjukkan bahwa tidak ada hubungan terdeteksi karena kesalahan yang Anda tambahkan sebelumnya untuk membuat model semantik yang kacau.
Gunakan validasi
Validasi adalah alat terbaik untuk memecahkan masalah kegagalan deteksi hubungan karena:
- Ini melaporkan dengan jelas mengapa hubungan tertentu tidak mengikuti aturan Kunci Asing sehingga tidak dapat dideteksi.
- Ini berjalan cepat dengan model semantik besar karena hanya berfokus pada hubungan yang dideklarasikan dan tidak melakukan pencarian.
Validasi dapat menggunakan DataFrame apa pun dengan kolom yang mirip dengan yang dihasilkan oleh find_relationships. Dalam kode berikut, suggested_relationships DataFrame mengacu pada patients daripada patients_dirty, tetapi Anda dapat alias DataFrame dengan kamus:
dirty_tables = {
"patients": patients_dirty,
"providers" : providers_dirty,
"encounters": encounters
}
errors = list_relationship_violations(dirty_tables, suggested_relationships)
errors
Melonggarkan kriteria pencarian
Dalam situasi yang lebih tidak jelas, Anda dapat mencoba melonggarkan kriteria pencarian Anda. Metode ini meningkatkan kemungkinan positif palsu.
Atur
include_many_to_many=Truedan evaluasi jika membantu:find_relationships(dirty_tables, include_many_to_many=True, coverage_threshold=1)Hasilnya menunjukkan bahwa hubungan dari
encounterskepatientsterdeteksi, tetapi ada dua masalah:- Hubungan menunjukkan arah dari
patientskeencounters, yang merupakan inversi dari hubungan yang diharapkan. Ini karena semuapatientsternyata dicakup olehencounters(Coverage Fromadalah 1.0) sementaraencountershanya dicakup sebagian olehpatients(Coverage To= 0.85), karena terdapat baris pasien yang hilang. - Ada kecocokan yang tidak disengaja pada kolom
GENDERkardinalitas rendah, yang kebetulan cocok dengan nama dan nilai di kedua tabel, tetapi itu bukan hubungan minat "m:1". Kardinalitas rendah ditunjukkan oleh kolomUnique Count FromdanUnique Count To.
- Hubungan menunjukkan arah dari
Jalankan ulang
find_relationshipsuntuk mencari hubungan "m:1", tetapi dengancoverage_threshold=0.5yang lebih rendah :find_relationships(dirty_tables, include_many_to_many=False, coverage_threshold=0.5)Hasilnya menunjukkan arah hubungan yang benar dari
encounterskeproviders. Namun, hubungan dariencounterskepatientstidak terdeteksi, karenapatientstidak unik, sehingga tidak dapat berada di sisi "Satu" dari hubungan "m:1".Longgarkan
include_many_to_many=Truedancoverage_threshold=0.5:find_relationships(dirty_tables, include_many_to_many=True, coverage_threshold=0.5)Sekarang kedua hubungan minat terlihat, tetapi ada lebih banyak kebisingan:
- Ada kecocokan dengan kardinalitas rendah pada
GENDER. - Kecocokan kardinalitas "m:m" yang lebih tinggi pada
ORGANIZATIONmuncul, sehingga terlihat bahwaORGANIZATIONkemungkinan kolom didenormalisasi ke dalam kedua tabel.
- Ada kecocokan dengan kardinalitas rendah pada
Mencocokkan nama kolom
Secara default, SemPy menganggap sebagai kecocokan hanya atribut yang menunjukkan kesamaan nama, memanfaatkan fakta bahwa perancang database biasanya memberi nama kolom terkait dengan cara yang sama. Perilaku ini membantu menghindari hubungan yang salah, yang paling sering terjadi dengan kunci integer kardinalitas rendah. Misalnya, jika ada 1,2,3,...,10 kategori produk dan kode status pesanan 1,2,3,...,10, mereka akan bingung satu sama lain ketika hanya melihat pemetaan nilai tanpa memperhitungkan nama kolom. Hubungan semu seharusnya tidak menjadi masalah dengan kunci mirip GUID.
SemPy melihat kesamaan antara nama kolom dan nama tabel. Pencocokan adalah perkiraan dan tidak sensitif terhadap huruf besar/kecil. Ini mengabaikan substring "dekorator" yang paling sering ditemui seperti "id", "code", "name", "key", "pk", "fk". Akibatnya, kasus kecocokan yang paling umum adalah:
- atribut yang disebut 'kolom' dalam entitas 'foo' cocok dengan atribut yang disebut 'kolom' (juga 'KOLOM' atau 'Kolom') di entitas 'bar'.
- atribut yang disebut 'kolom' dalam entitas 'foo' cocok dengan atribut yang disebut 'column_id' di 'bar'.
- atribut yang disebut 'bar' dalam entitas 'foo' cocok dengan atribut yang disebut 'code' di 'bar'.
Dengan mencocokkan nama kolom terlebih dahulu, deteksi berjalan lebih cepat.
Sesuaikan nama kolom:
- Untuk memahami kolom mana yang dipilih untuk evaluasi lebih lanjut, gunakan opsi
verbose=2(verbose=1hanya mencantumkan entitas yang sedang diproses). - Parameter
name_similarity_thresholdmenentukan bagaimana kolom dibandingkan. Ambang batas nilai 1 menunjukkan bahwa Anda hanya tertarik pada pencocokan 100% saja.
find_relationships(dirty_tables, verbose=2, name_similarity_threshold=1.0);Beroperasi pada 100% kesamaan gagal memperhitungkan perbedaan kecil antar nama. Dalam contoh Anda, tabel memiliki bentuk jamak dengan akhiran "s", yang tidak menghasilkan kecocokan yang tepat. Ini ditangani dengan baik dengan
name_similarity_threshold=0.8default .- Untuk memahami kolom mana yang dipilih untuk evaluasi lebih lanjut, gunakan opsi
Jalankan ulang dengan pengaturan default
name_similarity_threshold=0.8find_relationships(dirty_tables, verbose=2, name_similarity_threshold=0.8);Perhatikan bahwa ID untuk bentuk jamak
patientssekarang dibandingkan dengan bentuk tunggalpatienttanpa menambahkan terlalu banyak perbandingan yang tidak perlu terhadap waktu eksekusi.Jalankan ulang dengan pengaturan default
name_similarity_threshold=0find_relationships(dirty_tables, verbose=2, name_similarity_threshold=0);Mengubah
name_similarity_thresholdke 0 adalah yang ekstrem lainnya, dan menunjukkan bahwa Anda ingin membandingkan semua kolom. Ini jarang diperlukan dan menghasilkan peningkatan waktu eksekusi dan kecocokan palsu yang perlu ditinjau. Amati jumlah perbandingan dalam output verbose.
Ringkasan tips pemecahan masalah
- Mulai dari kecocokan yang tepat untuk relasi "m:1" (yaitu, default
include_many_to_many=Falsedancoverage_threshold=1.0). Ini biasanya yang Anda inginkan. - Gunakan fokus sempit pada subset tabel yang lebih kecil.
- Gunakan validasi untuk mendeteksi masalah kualitas data.
- Gunakan
verbose=2jika Anda ingin memahami kolom mana yang dipertimbangkan untuk hubungan. Ini dapat menghasilkan sejumlah besar output. - Waspadai kompromi dalam argumentasi pencarian.
include_many_to_many=Truedancoverage_threshold<1.0dapat menghasilkan hubungan semu yang mungkin lebih sulit untuk dianalisis dan perlu disaring.
Mendeteksi hubungan pada himpunan data Synthea lengkap
Contoh garis besar sederhana adalah alat pembelajaran dan pemecahan masalah yang nyaman. Dalam praktiknya, Anda dapat memulai dari model semantik seperti himpunan data Synthea lengkap, yang memiliki lebih banyak tabel. Jelajahi himpunan data synthea lengkap.
Baca semua file dari direktori synthea/csv:
all_tables = { "allergies": pd.read_csv('synthea/csv/allergies.csv'), "careplans": pd.read_csv('synthea/csv/careplans.csv'), "conditions": pd.read_csv('synthea/csv/conditions.csv'), "devices": pd.read_csv('synthea/csv/devices.csv'), "encounters": pd.read_csv('synthea/csv/encounters.csv'), "imaging_studies": pd.read_csv('synthea/csv/imaging_studies.csv'), "immunizations": pd.read_csv('synthea/csv/immunizations.csv'), "medications": pd.read_csv('synthea/csv/medications.csv'), "observations": pd.read_csv('synthea/csv/observations.csv'), "organizations": pd.read_csv('synthea/csv/organizations.csv'), "patients": pd.read_csv('synthea/csv/patients.csv'), "payer_transitions": pd.read_csv('synthea/csv/payer_transitions.csv'), "payers": pd.read_csv('synthea/csv/payers.csv'), "procedures": pd.read_csv('synthea/csv/procedures.csv'), "providers": pd.read_csv('synthea/csv/providers.csv'), "supplies": pd.read_csv('synthea/csv/supplies.csv'), }Temukan hubungan antara tabel, menggunakan fungsi
find_relationshipsSemPy:suggested_relationships = find_relationships(all_tables) suggested_relationshipsMemvisualisasikan hubungan:
plot_relationship_metadata(suggested_relationships)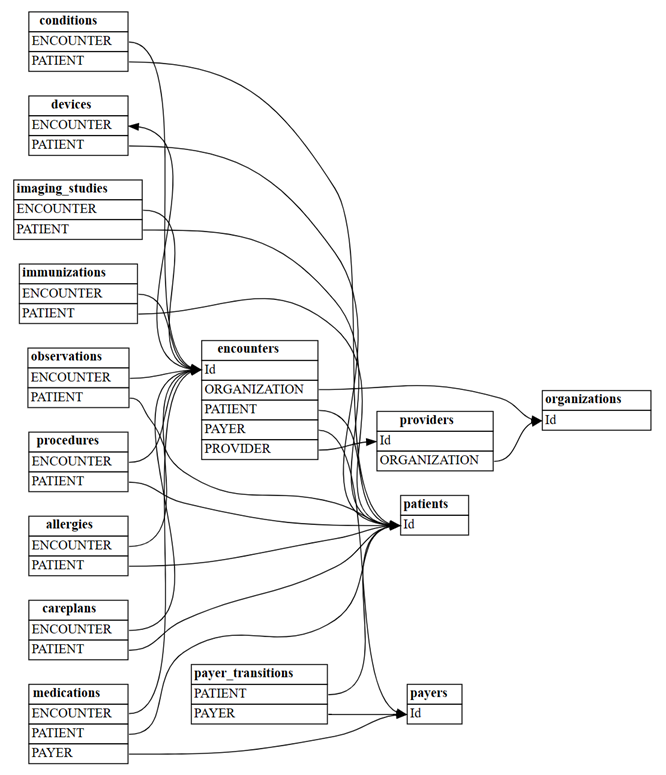
Hitung berapa banyak hubungan "m:m" baru yang akan ditemukan dengan
include_many_to_many=True. Hubungan ini di samping hubungan "m:1" yang ditunjukkan sebelumnya; oleh karena itu, Anda perlu menyaring denganmultiplicity:suggested_relationships = find_relationships(all_tables, coverage_threshold=1.0, include_many_to_many=True) suggested_relationships[suggested_relationships['Multiplicity']=='m:m']Anda dapat mengurutkan data hubungan menurut berbagai kolom untuk mendapatkan pemahaman yang lebih mendalam tentang sifatnya. Misalnya, Anda dapat memilih untuk mengurutkan output berdasarkan
Row Count FromdanRow Count To, yang membantu mengidentifikasi tabel terbesar.suggested_relationships.sort_values(['Row Count From', 'Row Count To'], ascending=False)Dalam model semantik yang berbeda, mungkin penting untuk fokus pada jumlah null
Null Count FromatauCoverage To.Analisis ini dapat membantu Anda memahami apakah salah satu hubungan bisa tidak valid, dan jika Anda perlu menghapusnya dari daftar kandidat.

Konten terkait
Lihat tutorial lain untuk tautan semantik / SemPy: