Mengintegrasikan OneLake dengan Azure Synapse Analytics
Azure Synapse adalah layanan analitik tanpa batas yang menyatukan pergudangan data perusahaan dan analitik Big Data. Tutorial ini menunjukkan cara menyambungkan ke OneLake menggunakan Azure Synapse Analytics.
Menulis data dari Synapse menggunakan Apache Spark
Ikuti langkah-langkah ini untuk menggunakan Apache Spark untuk menulis data sampel ke OneLake dari Azure Synapse Analytics.
Buka ruang kerja Synapse Anda dan buat kumpulan Apache Spark dengan parameter pilihan Anda.
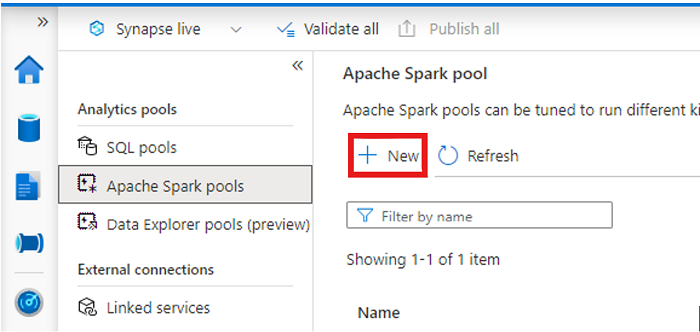
Buat buku catatan Apache Spark baru.
Buka buku catatan, atur bahasa ke PySpark (Python), dan sambungkan ke kumpulan Spark yang baru dibuat.
Di tab terpisah, navigasikan ke microsoft Fabric lakehouse Anda dan temukan folder Tabel tingkat atas.
Klik kanan pada folder Tabel dan pilih Properti.
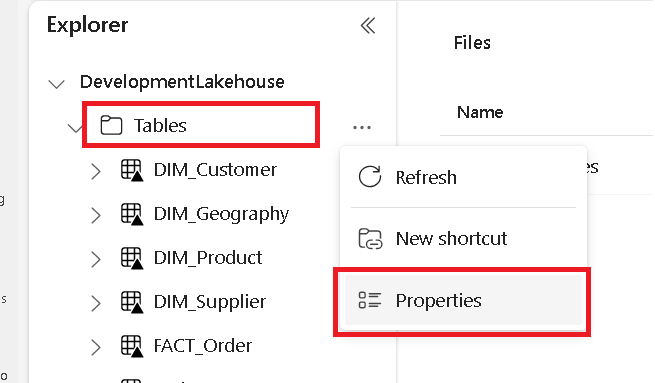
Salin jalur ABFS dari panel properti.
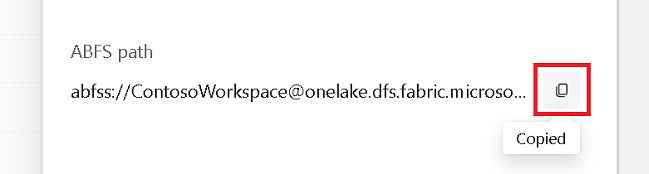
Kembali ke notebook Azure Synapse, di sel kode baru pertama, berikan jalur lakehouse. Lakehouse ini adalah tempat data Anda ditulis nanti. Jalankan sel.
# Replace the path below with the ABFS path to your lakehouse Tables folder. oneLakePath = 'abfss://WorkspaceName@onelake.dfs.fabric.microsoft.com/LakehouseName.lakehouse/Tables'Di sel kode baru, muat data dari himpunan data terbuka Azure ke dalam dataframe. Himpunan data ini adalah himpunan data yang Anda muat ke lakehouse Anda. Jalankan sel.
yellowTaxiDf = spark.read.parquet('wasbs://nyctlc@azureopendatastorage.blob.core.windows.net/yellow/puYear=2018/puMonth=2/*.parquet') display(yellowTaxiDf.limit(10))Di sel kode baru, filter, transformasi, atau siapkan data Anda. Untuk skenario ini, Anda dapat memangkas himpunan data untuk pemuatan yang lebih cepat, bergabung dengan himpunan data lain, atau memfilter ke hasil tertentu. Jalankan sel.
filteredTaxiDf = yellowTaxiDf.where(yellowTaxiDf.tripDistance>2).where(yellowTaxiDf.passengerCount==1) display(filteredTaxiDf.limit(10))Di sel kode baru, menggunakan jalur OneLake Anda, tulis dataframe yang difilter ke tabel Delta-Parquet baru di lakehouse Fabric Anda. Jalankan sel.
filteredTaxiDf.write.format("delta").mode("overwrite").save(oneLakePath + '/Taxi/')Terakhir, di sel kode baru, uji bahwa data Anda berhasil ditulis dengan membaca file Anda yang baru dimuat dari OneLake. Jalankan sel.
lakehouseRead = spark.read.format('delta').load(oneLakePath + '/Taxi/') display(lakehouseRead.limit(10))
Selamat. Anda sekarang dapat membaca dan menulis data di OneLake menggunakan Apache Spark di Azure Synapse Analytics.
Membaca data dari Synapse menggunakan SQL
Ikuti langkah-langkah ini untuk menggunakan SQL tanpa server untuk membaca data dari OneLake dari Azure Synapse Analytics.
Buka Fabric lakehouse dan identifikasi tabel yang ingin Anda kueri dari Synapse.
Klik kanan pada tabel dan pilih Properti.
Salin jalur ABFS untuk tabel.
Buka ruang kerja Synapse Anda di Synapse Studio.
Buat skrip SQL baru.
Di editor kueri SQL, masukkan kueri berikut, ganti
ABFS_PATH_HEREdengan jalur yang Anda salin sebelumnya.SELECT TOP 10 * FROM OPENROWSET( BULK 'ABFS_PATH_HERE', FORMAT = 'delta') as rows;Jalankan kueri untuk menampilkan 10 baris teratas tabel Anda.
Selamat. Anda sekarang dapat membaca data dari OneLake menggunakan SQL tanpa server di Azure Synapse Analytics.