Menerapkan arsitektur medallion lakehouse di Microsoft Fabric
Artikel ini memperkenalkan arsitektur medallion lake dan menjelaskan bagaimana Anda dapat menerapkan lakehouse di Microsoft Fabric. Ini ditargetkan pada beberapa audiens:
- Teknisi data: Staf teknis yang merancang, membangun, dan memelihara infrastruktur dan sistem yang memungkinkan organisasi mereka mengumpulkan, menyimpan, memproses, dan menganalisis data dalam jumlah besar.
- Tim Center of Excellence, IT, dan BI: Tim yang bertanggung jawab untuk mengawasi analitik di seluruh organisasi.
- Administrator Fabric: Administrator yang bertanggung jawab untuk mengawasi Fabric dalam organisasi.
Arsitektur medallion lakehouse, yang umumnya dikenal sebagai arsitektur medali, adalah pola desain yang digunakan oleh organisasi untuk mengatur data secara logis di lakehouse. Ini adalah pendekatan desain yang direkomendasikan untuk Fabric.
Arsitektur Medallion terdiri dari tiga lapisan atau zona yang berbeda. Setiap lapisan menunjukkan kualitas data yang disimpan di lakehouse, dengan tingkat yang lebih tinggi mewakili kualitas yang lebih tinggi. Pendekatan berlapis ini membantu Anda membangun satu sumber kebenaran untuk produk data perusahaan.
Yang penting, arsitektur medali menjamin kumpulan properti Atomitas, Konsistensi, Isolasi, dan Durabilitas (ACID) saat data berlangsung melalui lapisan. Dimulai dengan data mentah, serangkaian validasi dan transformasi menyiapkan data yang dioptimalkan untuk analitik yang efisien. Ada tiga tahap medali: perunggu (mentah), perak (divalidasi), dan emas (diperkaya).
Untuk informasi selengkapnya, lihat Apa itu arsitektur medallion lakehouse?.
OneLake dan lakehouse di Fabric
Dasar dari gudang data modern adalah data lake. Microsoft OneLake, yang merupakan data lake logis tunggal, terpadu untuk seluruh organisasi Anda. Ini disediakan secara otomatis dengan setiap penyewa Fabric, dan dirancang untuk menjadi satu lokasi untuk semua data analitik Anda.
Anda dapat menggunakan OneLake untuk:
- Hapus silo dan kurangi upaya manajemen. Semua data organisasi disimpan, dikelola, dan diamankan dalam satu sumber daya data lake. Karena OneLake disediakan dengan penyewa Fabric Anda, tidak ada lagi sumber daya untuk disediakan atau dikelola.
- Kurangi pergerakan data dan duplikasi. Tujuan OneLake adalah untuk menyimpan hanya satu salinan data. Lebih sedikit salinan data menghasilkan lebih sedikit proses pergerakan data, dan itu menyebabkan peningkatan efisiensi dan pengurangan kompleksitas. Jika perlu, Anda dapat membuat pintasan untuk mereferensikan data yang disimpan di lokasi lain, daripada menyalinnya ke OneLake.
- Gunakan dengan beberapa mesin analitik. Data di OneLake disimpan dalam format terbuka. Dengan begitu, data dapat dikueri oleh berbagai mesin analitik, termasuk Analysis Services (digunakan oleh Power BI), T-SQL, dan Apache Spark. Aplikasi non-Fabric lainnya juga dapat menggunakan API dan SDK untuk mengakses OneLake .
Untuk informasi selengkapnya, lihat OneLake, OneDrive untuk data.
Untuk menyimpan data di OneLake, Anda membuat lakehouse di Fabric. Lakehouse adalah platform arsitektur data untuk menyimpan, mengelola, dan menganalisis data terstruktur dan tidak terstruktur dalam satu lokasi. Ini dapat dengan mudah menskalakan ke volume data besar dari semua jenis dan ukuran file, dan karena disimpan dalam satu lokasi, data tersebut mudah dibagikan dan digunakan kembali di seluruh organisasi.
Setiap lakehouse memiliki titik akhir analitik SQL bawaan yang membuka kunci kemampuan gudang data tanpa perlu memindahkan data. Itu berarti Anda dapat mengkueri data Anda di lakehouse dengan menggunakan kueri SQL dan tanpa penyiapan khusus.
Untuk informasi selengkapnya, lihat Apa itu lakehouse di Microsoft Fabric?.
Tabel dan file
Saat Anda membuat lakehouse di Fabric, dua lokasi penyimpanan fisik disediakan secara otomatis untuk tabel dan file.
- Tabel adalah area terkelola untuk menghosting tabel dari semua format di Apache Spark (CSV, Parquet, atau Delta). Semua tabel, baik yang dibuat secara otomatis atau eksplisit, diakui sebagai tabel di lakehouse. Selain itu, setiap tabel Delta, yang merupakan file data Parquet dengan log transaksi berbasis file, juga dikenali sebagai tabel.
- File adalah area yang tidak dikelola untuk menyimpan data dalam format file apa pun. Setiap file Delta yang disimpan di area ini tidak secara otomatis dikenali sebagai tabel. Jika Anda ingin membuat tabel di atas folder Delta Lake di area yang tidak dikelola, Anda harus secara eksplisit membuat pintasan atau tabel eksternal dengan lokasi yang menunjuk ke folder tidak terkelola yang berisi file Delta Lake di Apache Spark.
Perbedaan utama antara area terkelola (tabel) dan area yang tidak dikelola (file) adalah penemuan tabel otomatis dan proses pendaftaran. Proses ini berjalan di atas folder apa pun yang dibuat di area terkelola saja, tetapi tidak di area yang tidak dikelola.
Di Microsoft Fabric, penjelajah Lakehouse menyediakan representasi grafis terpadu dari seluruh Lakehouse bagi pengguna untuk menavigasi, mengakses, dan memperbarui data mereka.
Untuk informasi selengkapnya tentang penemuan tabel otomatis, lihat Penemuan dan pendaftaran tabel otomatis.
Penyimpanan Delta Lake
Delta Lake adalah lapisan penyimpanan yang dioptimalkan yang menyediakan fondasi untuk menyimpan data dan tabel. Ini mendukung transaksi ACID untuk beban kerja big data, dan karena alasan ini adalah format penyimpanan default di Fabric lakehouse.
Yang penting, Delta Lake memberikan keandalan, keamanan, dan performa di lakehouse untuk operasi streaming dan batch. Secara internal, ia menyimpan data dalam format file Parquet, namun, ia juga mempertahankan log transaksi dan statistik yang menyediakan fitur dan peningkatan performa atas format Parquet standar.
Format Delta Lake melalui format file generik memberikan manfaat utama berikut.
- Dukungan untuk properti ACID, dan terutama durabilitas untuk mencegah kerusakan data.
- Kueri baca yang lebih cepat.
- Peningkatan kesegaran data.
- Dukungan untuk beban kerja batch dan streaming.
- Dukungan untuk pemutaran kembali data dengan menggunakan perjalanan waktu Delta Lake.
- Peningkatan kepatuhan peraturan dan audit dengan menggunakan riwayat tabel Delta Lake.
Fabric menstandarkan format file penyimpanan dengan Delta Lake, dan secara default, setiap mesin beban kerja di Fabric membuat tabel Delta saat Anda menulis data ke tabel baru. Untuk informasi selengkapnya, lihat Tabel Lakehouse dan Delta Lake.
Arsitektur medali dalam Fabric
Tujuan arsitektur medali adalah untuk secara bertahap dan progresif meningkatkan struktur dan kualitas data saat berlangsung melalui setiap tahap.
Arsitektur medali terdiri dari tiga lapisan berbeda (atau zona).
- Perunggu: Juga dikenal sebagai zona mentah, lapisan pertama ini menyimpan data sumber dalam format aslinya. Data dalam lapisan ini biasanya hanya ditambahkan dan tidak dapat diubah.
- Perak: Juga dikenal sebagai zona yang diperkaya, lapisan ini menyimpan data yang bersumber dari lapisan perunggu. Data mentah telah dibersihkan dan distandarkan, dan sekarang disusun sebagai tabel (baris dan kolom). Ini mungkin juga terintegrasi dengan data lain untuk memberikan tampilan perusahaan dari semua entitas bisnis, seperti pelanggan, produk, dan lainnya.
- Emas: Juga dikenal sebagai zona yang dikumpulkan, lapisan akhir ini menyimpan data yang bersumber dari lapisan perak. Data disempurnakan untuk memenuhi persyaratan bisnis dan analitik hilir tertentu. Tabel biasanya sesuai dengan desain skema bintang, yang mendukung pengembangan model data yang dioptimalkan untuk performa dan kegunaan.
Penting
Karena fabric lakehouse mewakili satu zona, Anda membuat satu lakehouse untuk masing-masing dari tiga zona.
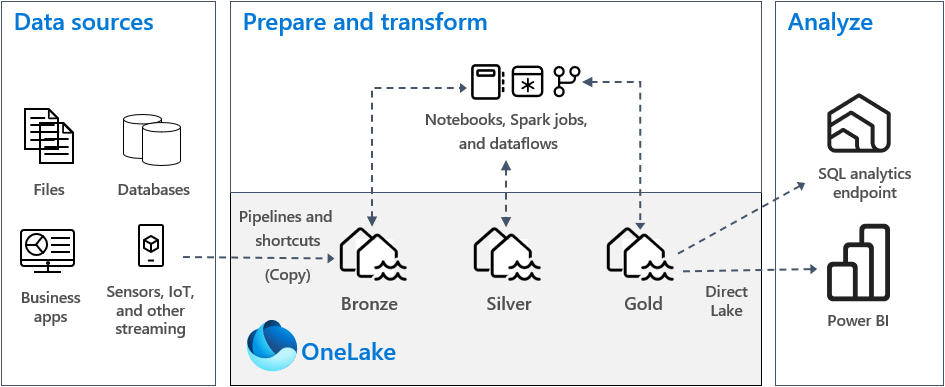
Dalam implementasi arsitektur medali yang khas di Fabric, zona perunggu menyimpan data dalam format yang sama dengan sumber data. Saat sumber data adalah database relasional, tabel Delta adalah pilihan yang baik. Zona perak dan emas berisi tabel Delta.
Tip
Untuk mempelajari cara membuat lakehouse, kerjakan tutorial skenario end-to-end Lakehouse.
Panduan fabric lakehouse
Bagian ini memberi Anda panduan terkait penerapan fabric lakehouse Anda menggunakan arsitektur medali.
Model Penyebaran
Untuk menerapkan arsitektur medali di Fabric, Anda dapat menggunakan lakehouse (satu untuk setiap zona), gudang data, atau kombinasi keduanya. Keputusan Anda harus didasarkan pada preferensi Anda dan keahlian tim Anda. Perlu diingat bahwa Fabric memberi Anda fleksibilitas: Anda dapat menggunakan mesin analitik berbeda yang bekerja pada satu salinan data Anda di OneLake.
Berikut adalah dua pola yang perlu dipertimbangkan.
- Pola 1: Buat setiap zona sebagai lakehouse. Dalam hal ini, pengguna bisnis mengakses data dengan menggunakan titik akhir analitik SQL.
- Pola 2: Buat zona perunggu dan perak sebagai lakehouse, dan zona emas sebagai gudang data. Dalam hal ini, pengguna bisnis mengakses data dengan menggunakan titik akhir gudang data.
Meskipun Anda dapat membuat semua lakehouse dalam satu ruang kerja Fabric, kami sarankan Anda membuat setiap lakehouse di ruang kerja Fabric sendiri yang terpisah. Pendekatan ini memberi Anda lebih banyak kontrol dan tata kelola yang lebih baik di tingkat zona.
Untuk zona perunggu, kami sarankan Anda menyimpan data dalam format aslinya, atau menggunakan Parquet atau Delta Lake. Jika memungkinkan, simpan data dalam format aslinya. Jika data sumber berasal dari OneLake, Azure Data Lake Store Gen2 (ADLS Gen2), Amazon S3, atau Google, buat pintasan di zona perunggu alih-alih menyalin data di seluruh.
Untuk zona perak dan emas, kami sarankan Anda menggunakan tabel Delta karena kemampuan ekstra dan peningkatan performa yang mereka berikan. Fabric menstandarkan pada format Delta Lake, dan secara default setiap mesin dalam Fabric menulis data dalam format ini. Selanjutnya, mesin ini menggunakan pengoptimalan write-time V-Order ke format file Parquet. Pengoptimalan tersebut memungkinkan pembacaan yang sangat cepat oleh mesin komputasi Fabric, seperti Power BI, SQL, Apache Spark, dan lainnya. Untuk informasi selengkapnya, lihat Pengoptimalan tabel Delta Lake dan V-Order.
Terakhir, saat ini banyak organisasi menghadapi pertumbuhan volume data yang masif, bersama dengan kebutuhan yang meningkat untuk mengatur dan mengelola data tersebut dengan cara yang logis sambil memfasilitasi penggunaan dan tata kelola yang lebih tepat sasaran dan efisien. Hal ini dapat mengarahkan Anda untuk membangun dan mengelola organisasi data terdesentralisasi atau federasi dengan tata kelola.
Untuk memenuhi tujuan ini, pertimbangkan untuk menerapkan arsitektur jala data. Jala data adalah pola arsitektur yang berfokus pada pembuatan domain data yang menawarkan data sebagai produk.
Anda dapat membuat arsitektur jala data untuk data estate Anda di Fabric dengan membuat domain data. Anda dapat membuat domain yang memetakan ke domain bisnis Anda, misalnya, pemasaran, penjualan, inventaris, sumber daya manusia, dan lainnya. Anda kemudian dapat menerapkan arsitektur medali dengan menyiapkan zona data dalam setiap domain Anda.
Untuk informasi selengkapnya tentang domain, lihat Domain.
Memahami penyimpanan data tabel Delta
Bagian ini menjelaskan topik panduan lain yang terkait dengan penerapan arsitektur medali lakehouse di Fabric.
Ukuran file
Umumnya, platform big data berkinerja lebih baik ketika memiliki sejumlah kecil file besar daripada sejumlah besar file kecil. Itu karena penurunan performa terjadi ketika mesin komputasi harus mengelola banyak metadata dan operasi file. Untuk performa kueri yang lebih baik, kami sarankan Anda membidik file data yang berukuran sekitar 1 GB.
Delta Lake memiliki fitur yang disebut pengoptimalan prediktif. Pengoptimalan prediktif menghilangkan kebutuhan untuk mengelola operasi pemeliharaan secara manual untuk tabel Delta. Ketika fitur ini diaktifkan, Delta Lake secara otomatis mengidentifikasi tabel yang akan mendapat manfaat dari operasi pemeliharaan, lalu mengoptimalkan penyimpanannya. Ini dapat secara transparan menyaring banyak file yang lebih kecil ke dalam file besar, dan tanpa dampak apa pun pada pembaca dan penulis data lainnya. Meskipun fitur ini harus menjadi bagian dari keunggulan operasional Anda dan pekerjaan persiapan data Anda, Fabric memiliki kemampuan untuk mengoptimalkan file data ini selama penulisan data juga. Untuk informasi selengkapnya, lihat Pengoptimalan prediktif untuk Delta Lake.
Retensi historis
Secara default, Delta Lake mempertahankan riwayat semua perubahan yang dibuat Itu berarti ukuran metadata historis tumbuh dari waktu ke waktu. Berdasarkan kebutuhan bisnis Anda, Anda harus bertujuan untuk menyimpan data historis hanya untuk jangka waktu tertentu untuk mengurangi biaya penyimpanan Anda. Pertimbangkan untuk menyimpan data historis hanya selama sebulan terakhir, atau periode waktu lain yang sesuai.
Anda dapat menghapus data historis yang lebih lama dari tabel Delta dengan menggunakan perintah VACUUM. Namun, ketahuilah bahwa secara default Anda tidak dapat menghapus data historis dalam tujuh hari terakhir—yaitu mempertahankan konsistensi dalam data. Jumlah hari default dikontrol oleh properti delta.deletedFileRetentionDuration = "interval <interval>"tabel . Ini menentukan periode waktu file harus dihapus sebelum dapat dianggap sebagai kandidat untuk operasi vakum.
Partisi tabel
Saat Anda menyimpan data di setiap zona, kami sarankan Anda menggunakan struktur folder yang dipartisi di mana pun berlaku. Teknik ini membantu meningkatkan pengelolaan data dan performa kueri. Umumnya, data yang dipartisi dalam struktur folder menghasilkan pencarian entri data tertentu yang lebih cepat berkat pemangkasan/penghapusan partisi.
Biasanya, Anda menambahkan data ke tabel target saat data baru tiba. Namun, dalam beberapa kasus Anda mungkin menggabungkan data karena Anda perlu memperbarui data yang ada secara bersamaan. Dalam hal ini, Anda dapat melakukan operasi upsert dengan menggunakan perintah MERGE. Saat tabel target Anda dipartisi, pastikan untuk menggunakan filter partisi untuk mempercepat operasi. Dengan begitu, mesin dapat menghilangkan partisi yang tidak memerlukan pembaruan.
Akses data
Terakhir, Anda harus merencanakan dan mengontrol siapa yang membutuhkan akses ke data tertentu di lakehouse. Anda juga harus memahami berbagai pola transaksi yang akan mereka gunakan saat mengakses data ini. Anda kemudian dapat menentukan skema pemartisian tabel yang tepat, dan kolokasi data dengan indeks pesanan Delta Lake Z.
Konten terkait
Untuk informasi selengkapnya tentang menerapkan Fabric lakehouse, lihat sumber daya berikut.
- Tutorial: Skenario end-to-end Lakehouse
- Tabel Lakehouse dan Delta Lake
- Panduan keputusan Microsoft Fabric: pilih penyimpanan data
- Pengoptimalan tabel Delta Lake dan V-Order
- Kebutuhan untuk mengoptimalkan penulisan di Apache Spark
- Pertanyaan? Coba tanyakan kepada komunitas Fabric.
- Ada saran? Berkontribusi ide untuk meningkatkan Fabric.