Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Dokumen ini menjelaskan cara kerja Deduplikasi Data .
Bagaimana cara kerja Deduplikasi Data?
Deduplikasi Data di Windows Server dibuat dengan dua prinsip berikut:
Pengoptimalan tidak boleh menghalangi penulisan ke disk Deduplikasi Data mengoptimalkan data dengan menggunakan model pasca-pemrosesan. Semua data ditulis dalam kondisi belum optimal ke cakram dan kemudian dioptimalkan nanti oleh Deduplikasi Data.
Pengoptimalan tidak boleh mengubah semantik akses Pengguna dan aplikasi yang mengakses data pada volume yang dioptimalkan sama sekali tidak menyadari bahwa file yang mereka akses telah dideduplikasi.
Setelah diaktifkan untuk volume, Deduplikasi Data berjalan di latar belakang untuk:
- Identifikasi pola berulang di seluruh file pada volume tersebut.
- Pindahkan bagian tersebut dengan mulus, atau gugus, dengan pointer khusus yang disebut titik pilah ulang yang menunjuk ke salinan unik gugus itu.
Ini terjadi dalam empat langkah berikut:
- Pindai sistem file untuk file yang memenuhi kebijakan pengoptimalan.

- Memecah file menjadi potongan ukuran variabel.

- Identifikasi potongan unik.
- Tempatkan potongan di penyimpanan potongan dan kompres secara opsional.
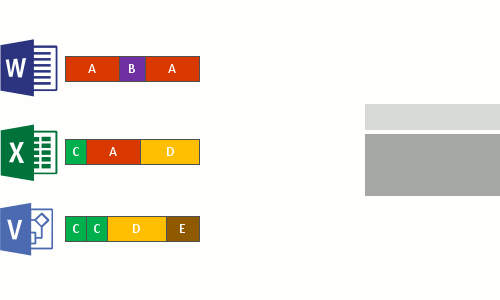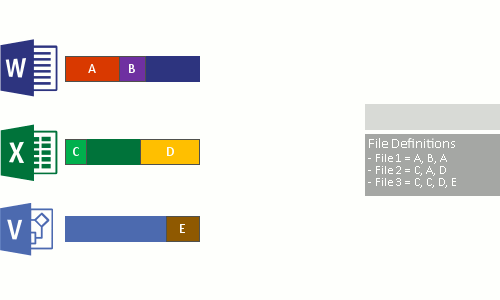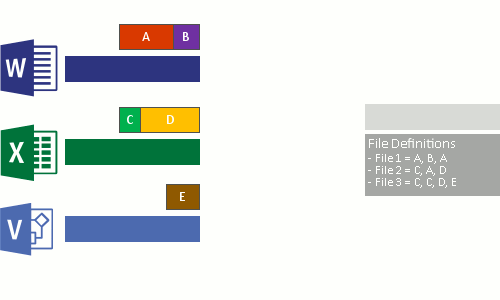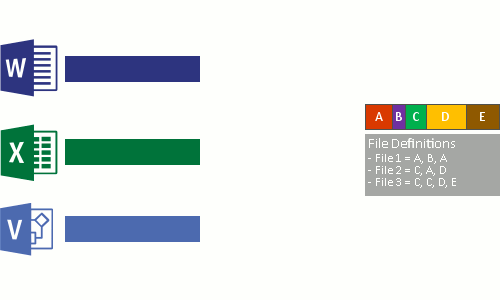
- Ganti aliran file asli dari file yang sekarang dioptimalkan dengan titik pemisahan ulang ke penyimpanan gugus.
Ketika file yang dioptimalkan dibaca, sistem file mengirim file dengan titik reparse ke filter sistem file Deduplikasi Data (Dedup.sys). Filter mengalihkan operasi baca ke potongan yang sesuai yang merupakan aliran untuk file tersebut di penyimpanan gugus. Modifikasi pada rentang file yang dideduplikasi ditulis tidak optimal ke disk dan dioptimalkan oleh pekerjaan Pengoptimalan saat berikutnya dijalankan.
Jenis Penggunaan
Jenis Penggunaan berikut menyediakan konfigurasi Deduplikasi Data yang wajar untuk beban kerja umum:
| Jenis Penggunaan | Beban kerja yang ideal | Apa yang berbeda |
|---|---|---|
| Default | Server file tujuan umum:
|
|
| Hyper-V | Server Infrastruktur Desktop Virtualisasi (VDI) |
|
| Cadangan | Aplikasi cadangan virtual, seperti Microsoft Data Protection Manager (DPM) |
|
Jobs
Deduplikasi Data menggunakan strategi pasca-pemrosesan untuk mengoptimalkan dan mempertahankan efisiensi ruang volume.
| Nama pekerjaan | Deskripsi pekerjaan | Jadwal default |
|---|---|---|
| Optimasi | Pekerjaan Pengoptimalan mendeduplikasi dengan memotong data pada volume per pengaturan kebijakan volume, (opsional) mengompresi gugus tersebut, dan menyimpan gugus secara unik di penyimpanan gugus. Proses pengoptimalan yang digunakan Deduplikasi Data dijelaskan secara rinci dalam Bagaimana cara kerja Deduplikasi Data?. | Sekali setiap jam |
| Pengumpulan Sampah | Pekerjaan Pengumpulan Sampah mengklaim kembali ruang disk dengan menghapus potongan yang tidak perlu yang tidak lagi direferensikan oleh file yang baru saja dimodifikasi atau dihapus. | Setiap Sabtu pukul 02.35 |
| Menggosok Integritas | Pekerjaan Integrity Scrubbing mengidentifikasi kerusakan di penyimpanan gugus karena kegagalan disk atau sektor yang buruk. Jika memungkinkan, Deduplikasi Data dapat secara otomatis menggunakan fitur volume (seperti cermin atau paritas pada volume Ruang Penyimpanan) untuk membangun ulang data yang rusak. Selain itu, Deduplikasi Data menyimpan salinan cadangan gugus populer di area yang disebut hotspot ketika gugus tersebut direferensikan lebih dari 100 kali. | Setiap Sabtu pukul 03.35 |
| Tidak optimalisasi | Pekerjaan Unoptimization , yang merupakan pekerjaan khusus yang hanya boleh dijalankan secara manual, membatalkan pengoptimalan yang dilakukan oleh deduplikasi dan menonaktifkan Deduplikasi Data untuk volume tersebut. | Sesuai permintaan saja |
Terminologi Deduplikasi Data
| Term | Definition |
|---|---|
| Potongan | Potongan adalah bagian dari file yang telah dipilih oleh algoritma pemotongan Deduplikasi Data yang kemungkinan terjadi di file serupa lainnya. |
| Penyimpanan gugus | Penyimpanan potongan data adalah serangkaian file kontainer yang terorganisasi di folder Informasi Volume Sistem yang digunakan oleh Deduplikasi Data untuk menyimpan potongan-potongan data secara unik. |
| Dedup | Singkatan untuk Deduplikasi Data yang umumnya digunakan di PowerShell, API dan komponen Windows Server, dan komunitas Windows Server. |
| Metadata berkas | Setiap file berisi metadata yang menjelaskan properti menarik tentang file yang tidak terkait dengan konten utama file. Misalnya, Tanggal Dibuat, Tanggal Baca Terakhir, Penulis, dll. |
| Aliran file | Aliran file adalah konten utama file. Bagian inilah dari file yang dioptimalkan oleh Deduplikasi Data. |
| Sistem berkas | Sistem file adalah perangkat lunak dan struktur data pada disk yang digunakan sistem operasi untuk menyimpan file di media penyimpanan. Deduplikasi Data didukung pada volume berformat NTFS. |
| Filter file sistem | Filter sistem file adalah plugin yang memodifikasi perilaku default sistem file. Untuk mempertahankan semantik akses, Data Deduplication menggunakan filter sistem file (Dedup.sys) untuk mengalihkan bacaan ke konten yang dioptimalkan sepenuhnya transparan kepada pengguna atau aplikasi yang membuat permintaan baca. |
| Optimasi | File dianggap dioptimalkan (atau dideduplikasi) oleh Deduplikasi Data jika telah dipotong, dan potongan uniknya telah disimpan di penyimpanan potongan. |
| Kebijakan pengoptimalan | Kebijakan pengoptimalan menentukan file yang harus dipertimbangkan untuk Deduplikasi Data. Misalnya, file dapat dianggap di luar kebijakan jika mereka baru, terbuka, di jalur tertentu pada volume, atau jenis file tertentu. |
| Pilah ulang titik | Titik pemisahan ulang adalah tag khusus yang memberi tahu sistem file untuk meneruskan I/O ke filter sistem file tertentu. Ketika aliran file telah dioptimalkan, Deduplikasi Data mengganti aliran file dengan titik pemrosesan ulang, yang memungkinkan Deduplikasi Data untuk mempertahankan semantik akses untuk file tersebut. |
| Jilid | Volume adalah konstruksi Windows untuk drive penyimpanan logis yang dapat mencakup beberapa perangkat penyimpanan fisik di satu atau beberapa server. Deduplikasi diaktifkan berdasarkan volume demi volume. |
| Beban kerja | Beban kerja adalah aplikasi yang berjalan di Windows Server. Contoh beban kerja termasuk server file tujuan umum, Hyper-V, dan SQL Server. |
Warning
Kecuali diinstruksikan oleh Personel Dukungan Microsoft resmi, jangan mencoba memodifikasi penyimpanan gugus secara manual. Melakukannya dapat mengakibatkan kerusakan atau kehilangan data.
Tanya jawab umum
Bagaimana Deduplikasi Data berbeda dari produk pengoptimalan lainnya? Ada beberapa perbedaan penting antara Deduplikasi Data dan produk pengoptimalan penyimpanan umum lainnya:
Bagaimana Deduplikasi Data berbeda dengan Penyimpanan Instansi Tunggal? Penyimpanan Instans Tunggal, atau SIS, adalah teknologi yang mendahului Deduplikasi Data dan pertama kali diperkenalkan di Windows Storage Server 2008 R2. Untuk mengoptimalkan volume, Penyimpanan Instans Tunggal mengidentifikasi file yang sepenuhnya identik dan menggantinya dengan tautan logis ke satu salinan file yang disimpan di penyimpanan umum SIS. Tidak seperti Penyimpanan Instans Tunggal, Deduplikasi Data bisa mendapatkan penghematan ruang dari file yang tidak identik tetapi berbagi banyak pola umum dan dari file yang sendiri berisi banyak pola berulang. Penyimpanan Instans Tunggal didepak di Windows Server 2012 R2 dan dihapus di Windows Server 2016 untuk mendukung Deduplikasi Data.
Bagaimana Deduplikasi Data berbeda dari kompresi NTFS? Kompresi NTFS adalah fitur NTFS yang dapat Anda aktifkan secara opsional di tingkat volume. Dengan kompresi NTFS, setiap file dioptimalkan secara individual melalui kompresi pada waktu tulis. Tidak seperti kompresi NTFS, Deduplikasi Data bisa mendapatkan penghematan spasi di semua file pada volume. Ini lebih baik daripada kompresi NTFS karena file mungkin memiliki duplikasi internal (yang ditangani oleh kompresi NTFS) dan memiliki kesamaan dengan file lain pada volume (yang tidak ditangani oleh kompresi NTFS). Selain itu, Deduplikasi Data memiliki model pasca-pemrosesan, yang berarti bahwa file baru atau yang dimodifikasi akan ditulis ke disk yang tidak optimal dan akan dioptimalkan nanti oleh Deduplikasi Data.
Bagaimana Deduplikasi Data berbeda dari format file arsip seperti zip, rar, 7z, cab, dll.? Format file arsip, seperti zip, rar, 7z, cab, dll., melakukan kompresi atas sekumpulan file tertentu. Seperti Deduplikasi Data, pola duplikat dalam file dan pola duplikat antara file dioptimalkan. Namun, Anda harus memilih file yang ingin Anda sertakan dalam arsip. Semantik akses juga berbeda. Untuk mengakses file tertentu dalam arsip, Anda harus membuka arsip, memilih file tertentu, dan mendekompresi file tersebut untuk digunakan. Deduplikasi Data beroperasi secara transparan bagi pengguna dan administrator dan tidak memerlukan inisiasi manual. Selain itu, Deduplikasi Data mempertahankan semantik akses: file yang dioptimalkan tampak tidak berubah setelah pengoptimalan.
Bisakah saya mengubah pengaturan Deduplikasi Data untuk Jenis Penggunaan yang saya pilih? Yes. Meskipun Deduplikasi Data menyediakan default yang wajar untuk beban kerja yang Direkomendasikan, Anda mungkin masih ingin mengubah pengaturan Deduplikasi Data untuk mendapatkan hasil maksimal dari penyimpanan Anda. Selain itu, beban kerja lain akan memerlukan beberapa penyesuaian untuk memastikan bahwa Deduplikasi Data tidak mengganggu beban kerja.
Bisakah saya menjalankan pekerjaan Deduplikasi Data secara manual? Ya, semua pekerjaan Deduplikasi Data dapat dijalankan secara manual. Ini mungkin diinginkan jika pekerjaan terjadwal tidak berjalan karena sumber daya sistem yang tidak mencukup atau karena kesalahan. Selain itu, pekerjaan Unoptimization hanya dapat dijalankan secara manual.
Dapatkah saya memantau hasil historis dari tugas Data Deduplication? Ya, semua pekerjaan Deduplikasi Data membuat entri di Log Peristiwa Windows.
Dapatkah saya mengubah jadwal default untuk pekerjaan Deduplikasi Data di sistem saya? Ya, semua jadwal dapat dikonfigurasi. Sangat penting untuk memodifikasi jadwal Deduplikasi Data default agar pekerjaan Deduplikasi Data dapat diselesaikan dan tidak harus bersaing dengan beban kerja untuk sumber daya.