Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Topik ini menjelaskan cara menginstal Deduplikasi Data, mengevaluasi beban kerja untuk deduplikasi, dan mengaktifkan Deduplikasi Data pada volume tertentu.
Note
Jika Anda berencana untuk menjalankan Deduplikasi Data di Kluster Failover, setiap simpul dalam kluster harus memiliki peran server Deduplikasi Data yang terinstal.
Instalasi Deduplikasi Data
Important
KB4025334 berisi roll up perbaikan untuk Deduplikasi Data, termasuk perbaikan keandalan penting, dan kami sangat menyarankan untuk menginstalnya saat menggunakan Deduplikasi Data dengan Windows Server 2016.
Menginstal Deduplikasi Data dengan menggunakan Manajer Server
- Di wizard Tambahkan Peran dan Fitur, pilih Peran Server, lalu pilih Deduplikasi Data.
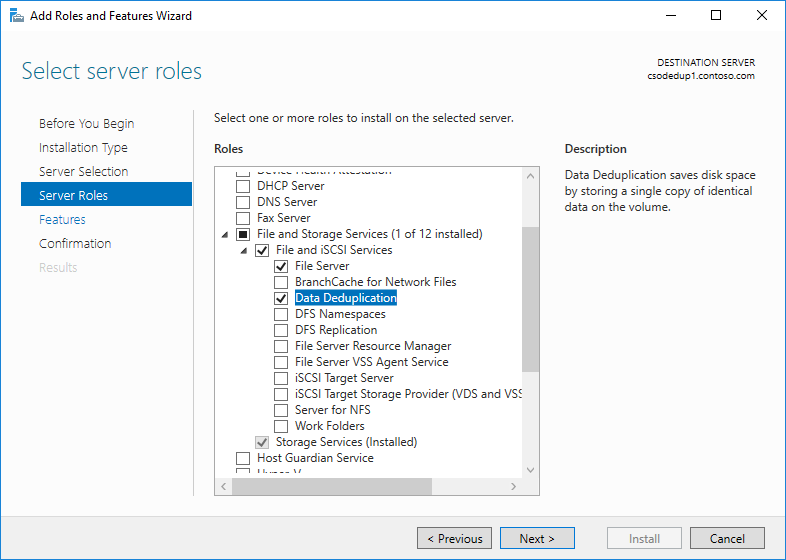
- Klik Berikutnya hingga tombol Instal aktif, lalu klik Instal.
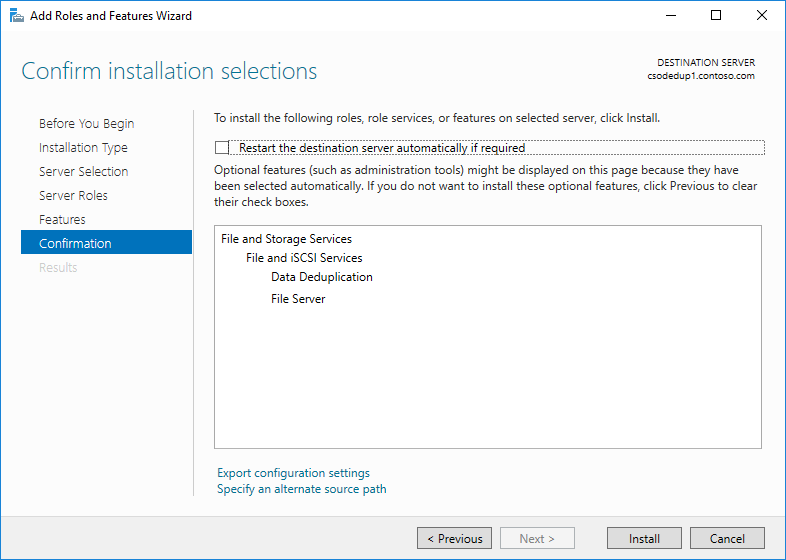
Menginstal Deduplikasi Data dengan menggunakan PowerShell
Untuk menginstal Deduplikasi Data, jalankan perintah PowerShell berikut ini sebagai administrator: Install-WindowsFeature -Name FS-Data-Deduplication
Untuk menginstal Deduplikasi Data:
Dari server yang menjalankan Windows Server 2016 atau yang lebih baru, atau dari PC Windows dengan Remote Server Administration Tools (RSAT) diinstal, instal Deduplikasi Data dengan referensi eksplisit ke nama server (ganti 'MyServer' dengan nama asli instans server):
Install-WindowsFeature -ComputerName <MyServer> -Name FS-Data-DeduplicationOr
Sambungkan secara jarak jauh ke instans server dengan PowerShell remoting dan instal Deduplikasi Data menggunakan DISM.
Enter-PSSession -ComputerName MyServer dism /online /enable-feature /featurename:dedup-core /all
Mengaktifkan Deduplikasi Data
Menentukan beban kerja mana yang merupakan kandidat untuk Deduplikasi Data
Deduplikasi Data dapat secara efektif meminimalkan biaya konsumsi data aplikasi server dengan mengurangi jumlah ruang disk yang digunakan oleh data yang berlebihan. Sebelum mengaktifkan deduplikasi, penting untuk memahami karakteristik beban kerja Anda untuk memastikan bahwa Anda mendapatkan performa maksimum dari penyimpanan Anda. Ada dua kelas beban kerja yang perlu dipertimbangkan:
-
Beban kerja yang direkomendasikan yang telah terbukti memiliki kedua himpunan data yang sangat mendapat manfaat dari deduplikasi dan memiliki pola konsumsi sumber daya yang kompatibel dengan model pasca-pemrosesan Data Deduplication. Kami menyarankan agar Anda selalu mengaktifkan Deduplikasi Data pada beban kerja ini:
- Server file tujuan umum (GPFS) yang melayani berbagi seperti berbagi tim, folder beranda pengguna, folder kerja, dan berbagi pengembangan perangkat lunak.
- Server infrastruktur desktop tervirtualisasi (VDI).
- Aplikasi cadangan virtual, seperti Microsoft Data Protection Manager (DPM).
- Beban kerja yang mungkin mendapat manfaat dari deduplikasi, tetapi tidak selalu calon yang ideal untuk deduplikasi. Misalnya, beban kerja berikut dapat bekerja dengan baik dengan deduplikasi, tetapi Anda harus mengevaluasi manfaat deduplikasi terlebih dahulu:
- Host Hyper-V tujuan umum
- Server SQL
- Server lini bisnis (LOB)
Mengevaluasi beban kerja untuk Deduplikasi Data
Important
Jika Anda menjalankan beban kerja yang direkomendasikan, Anda dapat melewati bagian ini dan masuk ke Aktifkan Data Deduplikasi untuk beban kerja Anda.
Untuk menentukan apakah beban kerja berfungsi dengan baik dengan deduplikasi, jawab pertanyaan berikut. Jika Anda tidak yakin tentang beban kerja, pertimbangkan untuk melakukan penyebaran percontohan Deduplikasi Data pada himpunan data pengujian untuk melihat performanya pada beban kerja Anda.
Apakah himpunan data beban kerja saya memiliki duplikasi yang cukup untuk mendapatkan manfaat dari mengaktifkan deduplikasi? Sebelum mengaktifkan Deduplikasi Data untuk beban kerja, selidiki berapa banyak duplikasi yang dimiliki himpunan data beban kerja Anda dengan menggunakan alat Evaluasi Penghematan Deduplikasi Data, atau DDPEval. Setelah menginstal Deduplikasi Data, Anda dapat menemukan alat ini di
C:\Windows\System32\DDPEval.exe. DDPEval dapat mengevaluasi potensi pengoptimalan terhadap volume yang terhubung langsung (termasuk drive lokal atau Volume Bersama Kluster) serta share jaringan yang dipetakan atau tidak dipetakan.Menjalankan DDPEval.exe akan mengembalikan output yang mirip dengan yang berikut ini:
Data Deduplication Savings Evaluation Tool Copyright 2011-2012 Microsoft Corporation. All Rights Reserved. Evaluated folder: E:\Test Processed files: 34 Processed files size: 12.03MB Optimized files size: 4.02MB Space savings: 8.01MB Space savings percent: 66 Optimized files size (no compression): 11.47MB Space savings (no compression): 571.53KB Space savings percent (no compression): 4 Files with duplication: 2 Files excluded by policy: 20 Files excluded by error: 0Seperti apa pola I/O beban kerja saya ke himpunan datanya? Performa apa yang saya miliki untuk beban kerja saya? Deduplikasi Data mengoptimalkan file sebagai tugas berkala, daripada ketika file ditulis ke cakram. Akibatnya, penting untuk memeriksa pola baca beban kerja yang diharapkan ke volume yang dideduplikasi. Karena Data Deduplication memindahkan konten file ke dalam Chunk Store dan mencoba mengatur Chunk Store berdasarkan file sebanyak mungkin, operasi baca berkinerja terbaik ketika diterapkan ke rentang berurutan dari sebuah file.
Beban kerja seperti database biasanya memiliki pola baca yang lebih acak daripada pola baca berurutan karena database biasanya tidak menjamin bahwa tata letak database akan optimal untuk semua kueri yang mungkin dijalankan. Karena bagian dari Chunk Store mungkin menyebar di seluruh volume, mengakses rentang data di Chunk Store untuk kueri database dapat menyebabkan latensi tambahan. Beban kerja berkinerja tinggi sangat sensitif terhadap latensi ekstra ini, tetapi beban kerja seperti database lainnya mungkin tidak.
Note
Kekhawatiran ini terutama berlaku untuk beban kerja penyimpanan pada volume yang terdiri dari media penyimpanan rotasi tradisional (juga dikenal sebagai drive Hard Disk, atau HDD). Infrastruktur penyimpanan all-flash (juga dikenal sebagai drive Solid State Disk, atau SSD), kurang terpengaruh oleh pola I/O acak karena salah satu properti media flash adalah waktu akses yang sama dengan semua lokasi di media. Oleh karena itu, deduplikasi tidak akan memperkenalkan jumlah latensi yang sama untuk membaca himpunan data beban kerja yang disimpan di media all-flash seperti pada media penyimpanan rotasi tradisional.
Apa saja persyaratan sumber daya beban kerja saya di server? Karena Deduplikasi Data menggunakan model pasca-pemrosesan, Deduplikasi Data secara berkala perlu memiliki sumber daya sistem yang memadai untuk menyelesaikan pengoptimalannya dan pekerjaan lainnya. Ini berarti bahwa beban kerja yang memiliki waktu diam, seperti di malam hari atau pada akhir pekan, adalah kandidat yang sangat baik untuk deduplikasi, dan beban kerja yang berjalan sepanjang hari, setiap hari mungkin tidak. Beban kerja yang tidak memiliki waktu diam mungkin masih menjadi kandidat yang baik untuk deduplikasi jika beban kerja tidak memiliki persyaratan sumber daya yang tinggi di server.
Mengaktifkan Deduplikasi Data
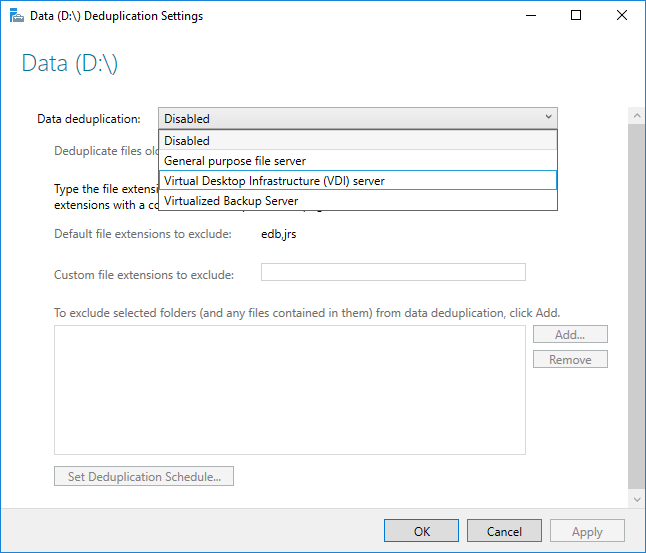
Sebelum mengaktifkan Deduplikasi Data, Anda harus memilih Jenis Penggunaan yang paling menyerupai beban kerja Anda. Ada tiga Jenis Penggunaan yang disertakan dengan Deduplikasi Data.
- Default - disetel khusus untuk server file tujuan umum
- Hyper-V - disetel khusus untuk server VDI
- Pencadangan - disetel khusus untuk aplikasi cadangan virtual, seperti Microsoft DPM
Mengaktifkan Deduplikasi Data dengan menggunakan Manajer Server
- Pilih Layanan File dan Penyimpanan di Manajer Server.
- Pilih Volume dari Layanan File dan Penyimpanan.
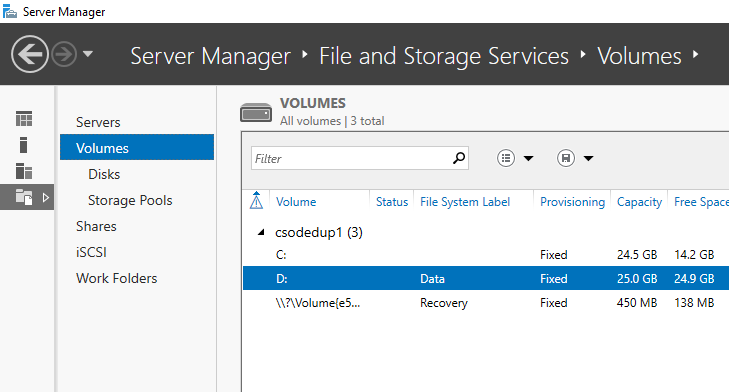
- Klik kanan volume yang diinginkan dan pilih Konfigurasikan Deduplikasi Data.
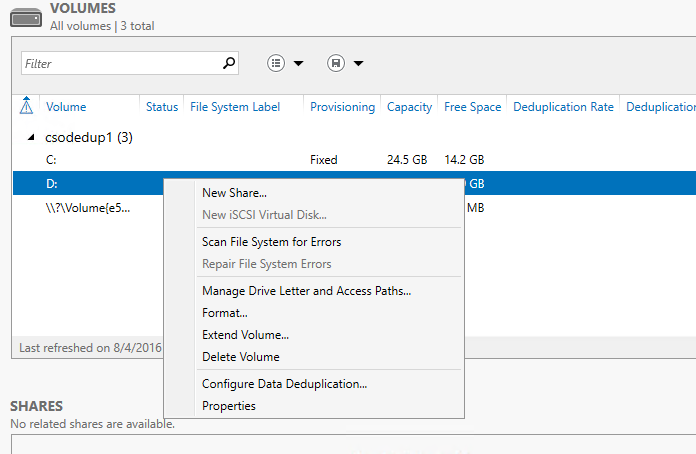
- Pilih Jenis Penggunaan yang diinginkan dari kotak drop-down dan pilih OK.
- Jika Anda menjalankan beban kerja yang direkomendasikan, Anda sudah selesai. Untuk beban kerja lainnya, lihat Pertimbangan lain.
Note
Anda dapat menemukan informasi selengkapnya tentang mengecualikan ekstensi file atau folder dan memilih jadwal deduplikasi, termasuk mengapa Anda ingin melakukan ini, dalam Mengonfigurasi Deduplikasi Data.
Mengaktifkan Deduplikasi Data dengan menggunakan PowerShell
Dengan konteks administrator, jalankan perintah PowerShell berikut ini:
Enable-DedupVolume -Volume <Volume-Path> -UsageType <Selected-Usage-Type>Jika Anda menjalankan beban kerja yang direkomendasikan, Anda sudah selesai. Untuk beban kerja lainnya, lihat Pertimbangan lain.
Note
Cmdlet PowerShell Deduplikasi Data, termasuk Enable-DedupVolume, dapat dijalankan dari jarak jauh dengan menyertakan parameter -CimSession melalui Sesi CIM. Ini sangat berguna untuk menjalankan cmdlet PowerShell Deduplikasi Data terhadap instans server dari jarak jauh. Untuk menjalankan Sesi CIM baru, jalankan New-CimSession.
Pertimbangan lain
Important
Jika Anda menjalankan beban kerja yang direkomendasikan, Anda dapat melewati bagian ini.
- Jenis Penggunaan Data Deduplication memberikan default yang masuk akal untuk beban kerja yang direkomendasikan, tetapi juga memberikan titik awal yang baik untuk semua beban kerja. Untuk beban kerja selain beban kerja yang direkomendasikan, dimungkinkan untuk memodifikasi pengaturan lanjutan Data Deduplication untuk meningkatkan performa deduplikasi.
- Jika beban kerja Anda memiliki persyaratan sumber daya yang tinggi di server Anda, tugas Deduplikasi Data harus dijadwalkan untuk dijalankan selama waktu idle yang diprediksi untuk beban kerja tersebut. Ini penting terutama saat menjalankan deduplikasi pada host hyper-converged, karena menjalankan Deduplikasi Data selama jam kerja yang diharapkan dapat membuat VM kekurangan sumber daya.
- Jika beban kerja Anda tidak memiliki persyaratan sumber daya yang tinggi, atau jika lebih penting bahwa pekerjaan pengoptimalan selesai daripada permintaan beban kerja dilayani, memori, CPU, dan prioritas pekerjaan Deduplikasi Data dapat disesuaikan.
Pertanyaan Umum (FAQ)
Saya ingin menjalankan Deduplikasi Data pada himpunan data untuk beban kerja X. Apakah ini didukung? Selain dari beban kerja yang diketahui tidak dapat dioperasikan bersama dengan Deduplikasi Data, kami sepenuhnya mendukung integritas data Deduplikasi Data dengan beban kerja apa pun. Beban kerja yang direkomendasikan juga didukung oleh Microsoft untuk performa. Performa beban kerja lain sangat tergantung pada apa yang mereka lakukan di server Anda. Anda harus menentukan dampak performa apa yang terjadi pada Deduplikasi Data pada beban kerja Anda, dan apakah ini dapat diterima untuk beban kerja ini.
Apa persyaratan ukuran volume untuk volume yang dideduplikasi? Di Windows Server 2012 dan Windows Server 2012 R2, volume harus diatur dengan cermat untuk memastikan bahwa Deduplikasi Data dapat mengikuti perubahan pada volume. Ini biasanya berarti bahwa ukuran maksimum rata-rata volume deduplikasi untuk beban kerja churn tinggi adalah 1-2 TB, dan ukuran maksimum absolut yang direkomendasikan adalah 10 TB. Di Windows Server 2016, batasan ini dihapus. Untuk informasi selengkapnya, lihat Apa yang baru dalam Deduplikasi Data.
Apakah saya perlu mengubah jadwal atau pengaturan Deduplikasi Data lainnya untuk beban kerja yang direkomendasikan? Tidak, Jenis Penggunaan yang disediakan dibuat untuk memberikan default yang wajar untuk beban kerja yang direkomendasikan.
Apa saja persyaratan memori untuk Deduplikasi Data?
Setidaknya, Deduplikasi Data harus memiliki 300 MB + 50 MB untuk setiap TB data logis. Misalnya, jika Anda mengoptimalkan volume 10 TB, Anda memerlukan minimal memori 800 MB yang dialokasikan untuk deduplikasi (300 MB + 50 MB * 10 = 300 MB + 500 MB = 800 MB). Meskipun Data Deduplication dapat mengoptimalkan volume dengan jumlah memori yang rendah ini, terbatasnya sumber daya akan memperlambat pekerjaan Data Deduplication.
Idealnya, deduplikasi data baiknya memiliki 1 GB RAM untuk setiap 1 TB data logis. Misalnya, jika Anda mengoptimalkan volume 10 TB, Anda akan secara optimal membutuhkan memori 10 GB yang dialokasikan untuk Deduplikasi Data (1 GB * 10). Rasio ini akan memastikan performa maksimum untuk pekerjaan Data Deduplication.
Apa saja persyaratan penyimpanan untuk Deduplikasi Data? Di Windows Server 2016, Deduplikasi Data dapat mendukung ukuran volume hingga 64 TB. Untuk informasi selengkapnya, lihat Perubahan Terbaru dalam Deduplikasi Data.