Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo fornisce linee guida sulle procedure consigliate che consentono di ottimizzare le prestazioni, ridurre i costi e proteggere l'account di Data Lake Storage abilitato Archiviazione di Azure.
Per suggerimenti generali sulla strutturazione di un data lake, vedere questi articoli:
- Panoramica di Azure Data Lake Storage per lo scenario di analisi e gestione dei dati
- Effettuare il provisioning di tre account di Azure Data Lake Storage per ogni zona di destinazione dei dati
Trova la documentazione
Azure Data Lake Storage non è un servizio dedicato né un tipo di account di archiviazione. Si tratta di un set di funzionalità che supportano carichi di lavoro analitici a velocità effettiva elevata. La documentazione di Data Lake Storage fornisce procedure consigliate e indicazioni per l'uso di queste funzionalità. Per tutti gli altri aspetti della gestione degli account, ad esempio la configurazione della sicurezza di rete, la progettazione per la disponibilità elevata e il ripristino di emergenza, vedere il contenuto della documentazione sull'archiviazione BLOB.
Valutare il supporto delle funzionalità e i problemi noti
Usare il modello seguente durante la configurazione dell'account per l'uso delle funzionalità di archiviazione BLOB.
Esaminare il supporto della funzionalità di archiviazione BLOB nell'articolo Archiviazione di Azure account per determinare se una funzionalità è completamente supportata nell'account. Alcune funzionalità non sono ancora supportate o hanno supporto parziale negli account abilitati per Data Lake Storage. Il supporto delle funzionalità è sempre in espansione, quindi assicurarsi di esaminare periodicamente questo articolo per gli aggiornamenti.
Vedere l'articolo Problemi noti relativi ad Azure Data Lake Storage per verificare se sono presenti limitazioni o indicazioni speciali sulla funzionalità che si intende usare.
Analizzare gli articoli sulle funzionalità per eventuali indicazioni specifiche per gli account abilitati per Data Lake Storage.
Comprendere i termini usati nella documentazione
Quando si passa da un set di contenuto all'altro, si notano alcune lievi differenze di terminologia. Ad esempio, il contenuto presente nella documentazione dell'archiviazione BLOB userà il termine BLOB anziché file. Tecnicamente, i file inseriti nell'account di archiviazione diventano BLOB nell'account. Pertanto, il termine è corretto. Tuttavia, il termine BLOB può causare confusione se si usa il termine file. Verrà anche visualizzato il termine contenitore usato per fare riferimento a un file system. È opportuno considerare questi termini come sinonimi.
Prendere in considerazione premium
Se i carichi di lavoro richiedono una bassa latenza coerente e/o richiedono un numero elevato di operazioni di output di input al secondo (IOP), è consigliabile usare un account di archiviazione BLOB in blocchi Premium. Questo tipo di account rende i dati disponibili tramite hardware ad alte prestazioni. I dati vengono archiviati in unità SSD ottimizzate per la bassa latenza. Le unità SSD offrono una velocità effettiva superiore rispetto ai dischi rigidi tradizionali. I costi di archiviazione delle prestazioni Premium sono più elevati, ma i costi delle transazioni sono inferiori. Pertanto, se i carichi di lavoro eseguono un numero elevato di transazioni, un account BLOB in blocchi di prestazioni Premium può essere economico.
Se l'account di archiviazione verrà usato per l'analisi, è consigliabile usare Azure Data Lake Storage insieme a un account di archiviazione BLOB in blocchi Premium. Questa combinazione di uso di account di archiviazione BLOB in blocchi Premium insieme a un account abilitato per Data Lake Storage è detto livello Premium per Azure Data Lake Storage.
Ottimizzare l'inserimento dei dati
Quando si inseriscono dati da un sistema di origine, l'hardware di origine, l'hardware di rete di origine o la connettività di rete all'account di archiviazione può essere un collo di bottiglia.
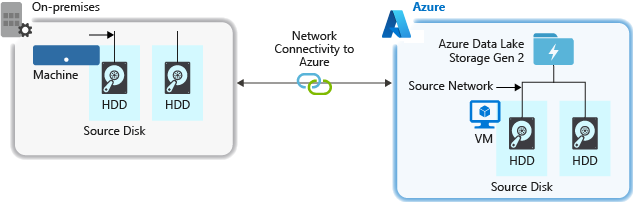
Hardware di origine
Indipendentemente dal fatto che si usino computer locali o Macchine virtuali (VM) in Azure, assicurarsi di selezionare attentamente l'hardware appropriato. Per l'hardware del disco, prendere in considerazione l'uso di unità SSD (Solid State Drive) e selezionare l'hardware del disco con spindle più veloci. Per l'hardware di rete, usare la scheda di interfaccia di rete più veloce possibile. In Azure è consigliabile usare macchine virtuali di Azure D14, che dispongono dell'hardware di rete e del disco appropriato.
Connettività di rete all'account di archiviazione
La connettività di rete tra i dati di origine e l'account di archiviazione può talvolta essere un collo di bottiglia. Quando i dati di origine sono locali, è consigliabile usare un collegamento dedicato con Azure ExpressRoute. Se i dati di origine si trovano in Azure, le prestazioni sono ottimali quando i dati si trovano nella stessa area di Azure dell'account abilitato per Data Lake Storage.
Configurare gli strumenti di inserimento dei dati per la massima parallelizzazione
Per ottenere prestazioni ottimali, usare tutta la velocità effettiva disponibile eseguendo il maggior numero possibile di letture e scritture in parallelo.
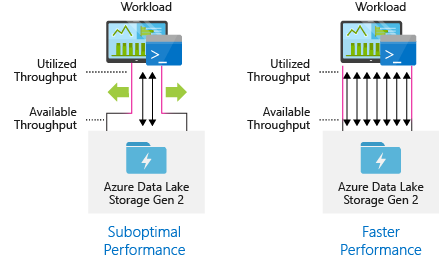
La tabella seguente riepiloga le impostazioni principali per diversi strumenti di inserimento comuni.
| Strumento | Impostazione |
|---|---|
| DistCp | -m (mappatore) |
| Azure Data Factory | copie parallele |
| Sqoop | fs.azure.block.size, -m (mapper) |
| AzCopy | AZCOPY_CONCURRENCY_VALUE |
Nota
Le prestazioni complessive delle operazioni di inserimento dipendono da altri fattori specifici dello strumento usato per inserire i dati. Per indicazioni aggiornate, vedere la documentazione per ogni strumento che si intende usare.
L'account può essere ridimensionato per fornire la velocità effettiva necessaria per tutti gli scenari di analisi. Per impostazione predefinita, un account abilitato per Data Lake Storage offre una velocità effettiva sufficiente nella configurazione predefinita per soddisfare le esigenze di un'ampia categoria di casi d'uso. Se si verifica il limite predefinito, l'account può essere configurato per fornire una maggiore velocità effettiva contattando il supporto tecnico di Azure.
Set di dati struttura
Prendere in considerazione la pre-pianificazione della struttura dei dati. Il formato di file, le dimensioni dei file e la struttura di directory possono influire negativamente sulle prestazioni e sui costi.
Formati di file
I dati possono essere inseriti in vari formati. I dati possono essere visualizzati in formati leggibili, ad esempio JSON, CSV o XML o come formati binari compressi, .tar.gzad esempio . I dati possono venire anche in varie dimensioni. I dati possono essere costituiti da file di grandi dimensioni (alcuni terabyte), ad esempio i dati di un'esportazione di una tabella SQL dai sistemi locali. I dati possono anche venire sotto forma di un numero elevato di file di piccole dimensioni (pochi kilobyte), ad esempio i dati provenienti da eventi in tempo reale da una soluzione Internet delle cose (IoT). È possibile ottimizzare l'efficienza e i costi scegliendo un formato di file e dimensioni di file appropriati.
Hadoop supporta un set di formati di file ottimizzati per l'archiviazione e l'elaborazione di dati strutturati. Alcuni formati comuni sono il formato Avro, Parquet e Optimized Row Columnar (ORC). Tutti questi formati sono formati di file binari leggibili dal computer. Sono compressi per facilitare la gestione delle dimensioni dei file. Hanno uno schema incorporato in ogni file, che li rende autodescrittura. La differenza tra questi formati è la modalità di archiviazione dei dati. Avro archivia i dati in un formato basato su righe e i formati Parquet e ORC archiviano i dati in un formato a colonne.
Prendere in considerazione l'uso del formato di file Avro nei casi in cui i modelli di I/O sono più pesanti per la scrittura o i modelli di query favorisce il recupero di più righe di record nel loro insieme. Ad esempio, il formato Avro funziona bene con un bus di messaggi come Hub eventi o Kafka che scrivono più eventi/messaggi in successione.
Si considerino i formati di file Parquet e ORC quando i modelli di I/O sono più letti o quando i modelli di query sono incentrati su un subset di colonne nei record. Le transazioni di lettura possono essere ottimizzate per recuperare colonne specifiche anziché leggere l'intero record.
Apache Parquet è un formato di file open source ottimizzato per le pipeline di analisi con intensa attività di lettura. La struttura di archiviazione a colonne di Parquet consente di ignorare i dati non rilevanti. Le query sono molto più efficienti perché possono limitare l'ambito dei dati da inviare dall'archiviazione al motore di analisi. Inoltre, poiché i tipi di dati simili (per una colonna) vengono archiviati insieme, Parquet supporta schemi di codifica e compressione dei dati efficienti che possono ridurre i costi di archiviazione dei dati. I servizi come Azure Synapse Analytics, Azure Databricks e Azure Data Factory hanno funzionalità native che sfruttano i formati di file Parquet.
Dimensioni file
I file di dimensioni maggiori comportano prestazioni migliori e costi ridotti.
In genere, i motori di analisi, ad esempio HDInsight, presentano un sovraccarico per ogni file che comporta attività come l'elenco, il controllo dell'accesso e l'esecuzione di varie operazioni sui metadati. Se quindi si archiviano i dati in molti file di piccole dimensioni, questo può influire negativamente sulle prestazioni. In generale, organizzare i dati in file di dimensioni maggiori per ottenere prestazioni migliori (da 256 MB a 100 GB di dimensioni). Alcuni motori e applicazioni potrebbero avere problemi di elaborazione efficiente dei file con dimensioni superiori a 100 GB.
L'aumento delle dimensioni dei file può anche ridurre i costi delle transazioni. Le operazioni di lettura e scrittura vengono fatturate in incrementi di 4 megabyte, quindi viene addebitato un addebito per l'operazione indipendentemente dal fatto che il file contenga o meno 4 megabyte o solo pochi kilobyte. Per informazioni sui prezzi, vedere Prezzi di Azure Data Lake Storage.
Le pipeline di dati hanno talvolta un controllo limitato sui dati non elaborati costituiti da molti file di piccole dimensioni. In generale, è consigliabile che il sistema disponga di una sorta di processo per aggregare file di piccole dimensioni in file di dimensioni maggiori per l'uso da parte delle applicazioni downstream. Se si elaborano dati in tempo reale, è possibile usare un motore di streaming in tempo reale (ad esempio Analisi di flusso di Azure o Spark Streaming) insieme a un broker di messaggi (ad esempio Hub eventi o Apache Kafka) per archiviare i dati come file di dimensioni maggiori. Durante l'aggregazione di file di piccole dimensioni in file di dimensioni maggiori, è consigliabile salvarli in un formato ottimizzato per la lettura, ad esempio Apache Parquet per l'elaborazione downstream.
Struttura di directory
Ogni carico di lavoro ha requisiti diversi sulla modalità di utilizzo dei dati, ma si tratta di alcuni layout comuni da considerare quando si usa Internet delle cose (IoT), scenari batch o quando si ottimizzano i dati delle serie temporali.
Struttura IoT
Nei carichi di lavoro IoT può essere inserita una grande quantità di dati che si estende su numerosi prodotti, dispositivi, organizzazioni e clienti. È importante pre-pianificare il layout della directory per l'organizzazione, la sicurezza e l'elaborazione efficiente dei dati per i consumer down-stream. Un modello generale da prendere in considerazione può essere il layout seguente:
- {Region}/{SubjectMatter(s)}/{yyyy}/{mm}/{dd}/{hh}/
I dati di telemetria per gli atterraggi relativi a un motore di un aereo nel Regno Unito potrebbero ad esempio essere simili alla struttura seguente:
- Uk/Planes/BA1293/Engine1/2017/08/11/12/
In questo esempio, inserendo la data alla fine della struttura di directory, è possibile usare gli elenchi di controllo di accesso per proteggere più facilmente le aree e le questioni relative a utenti e gruppi specifici. Se si inserisce la struttura della data all'inizio, sarebbe molto più difficile proteggere queste regioni e le questioni soggette. Ad esempio, se si vuole fornire l'accesso solo ai dati del Regno Unito o a determinati piani, è necessario applicare un'autorizzazione separata per numerose directory nella directory ogni ora. Questa struttura aumenterebbe in modo esponenziale anche il numero di directory man mano che il tempo è andato avanti.
Struttura dei processi batch
Un approccio comunemente usato nell'elaborazione batch consiste nell'inserire i dati in una directory "in". Quindi, una volta elaborati i dati, inserire i nuovi dati in una directory "out" per i processi downstream da utilizzare. Questa struttura di directory viene talvolta usata per i processi che richiedono l'elaborazione su singoli file e potrebbe non richiedere un'elaborazione parallela elevata su set di dati di grandi dimensioni. Analogamente alla struttura IoT consigliata in precedenza, una buona struttura di directory include le directory a livello padre per elementi come area geografica e materia (ad esempio, organizzazione, prodotto o produttore). Prendere in considerazione data e ora nella struttura per consentire una migliore organizzazione, ricerche filtrate, sicurezza e automazione nell'elaborazione. Il livello di granularità per la struttura di data è determinato dall'intervallo con cui i dati vengono caricati o elaborati, ad esempio ogni ora, ogni giorno o anche ogni mese.
Talvolta l'elaborazione di file ha esito negativo a causa del danneggiamento dei dati o di formati imprevisti. In questi casi, una struttura di directory può trarre vantaggio da una cartella /bad per spostare i file in per un'ulteriore ispezione. Il processo batch può anche gestire la creazione di report o le notifiche per i file nella cartella bad, per gli interventi manuali. Si consideri la struttura di modelli seguente:
- {Region}/{SubjectMatter(s)}/In/{yyyy}/{mm}/{dd}/{hh}/
- {Area}/{SubjectMatter(s)}/Out/{aa}/{mm}/{dd}/{hh}/
- {Area}/{SubjectMatter(s)}/Bad/{aa}/{mm}/{dd}/{hh}/
Una società di marketing riceve ad esempio estratti giornalieri di dati degli aggiornamenti dei clienti dai committenti in America del Nord, che prima e dopo l'elaborazione possono essere come il frammento seguente:
- NA/Extracts/ACMEPaperCo/In/2017/08/14/updates_08142017.csv
- NA/Extracts/ACMEPaperCo/Out/2017/08/14/processed_updates_08142017.csv
Nel caso comune di dati batch elaborati direttamente in database come Hive o database SQL tradizionali, non è necessario usare una directory /in o /out perché l'output si trova già in una cartella separata per la tabella Hive o il database esterno. Ad esempio, gli estratti giornalieri dai clienti verrebbero inseriti nelle rispettive directory. Un servizio come Azure Data Factory, Apache Oozie o Apache Airflow attiverà quindi un processo Hive o Spark giornaliero per elaborare e scrivere i dati in una tabella Hive.
Struttura dei dati delle serie temporali
Per i carichi di lavoro Hive, l'eliminazione delle partizioni dei dati delle serie temporali può aiutare alcune query a leggere solo un subset dei dati, migliorando così le prestazioni.
Queste pipeline che inseriscono dati di serie temporali, spesso inseriscono i file con una denominazione strutturata per file e cartelle. Di seguito è riportato un esempio comune per i dati strutturati per data:
/DataSet/AAAA/MM/GG/datafile_YYYY_MM_DD.tsv
Si noti che le informazioni di data/ora vengono visualizzate sia come cartelle sia nel nome del file.
Per la data e l'ora, di seguito è riportato un modello comune
/DataSet/AAAA/MM/GG/HH/mm/datafile_YYYY_MM_DD_HH_mm.tsv
Anche in questo caso, la scelta relativa all'organizzazione di file e cartelle deve prevedere una gestione ottimizzata dei file di maggiori dimensioni e l'inclusione di un numero ragionevole di file in ogni cartella.
Configurare la sicurezza
Per iniziare, vedere le raccomandazioni nell'articolo Raccomandazioni sulla sicurezza per l'archiviazione BLOB. Sono disponibili indicazioni sulle procedure consigliate su come proteggere i dati da eliminazioni accidentali o dannose, proteggere i dati dietro un firewall e usare Microsoft Entra ID come base della gestione delle identità.
Vedere quindi l'articolo Modello di controllo di accesso in Azure Data Lake Storage per indicazioni specifiche per gli account abilitati per Data Lake Storage. Questo articolo illustra come usare i ruoli di controllo degli accessi in base al ruolo di Azure insieme agli elenchi di controllo di accesso (ACL) per applicare le autorizzazioni di sicurezza per directory e file nel file system gerarchico.
Inserimento, elaborazione e analisi
Esistono molte origini di dati diverse e modi diversi in cui i dati possono essere inseriti in un account abilitato per Data Lake Storage.
Ad esempio, è possibile inserire grandi set di dati da cluster HDInsight e Hadoop o set più piccoli di dati ad hoc per la creazione di prototipi di applicazioni. È possibile inserire dati trasmessi generati da varie origini, ad esempio applicazioni, dispositivi e sensori. Per questo tipo di dati, è possibile usare gli strumenti per acquisire ed elaborare i dati in base all'evento in tempo reale e quindi scrivere gli eventi in batch nell'account. È anche possibile inserire i log del server Web, che contengono informazioni come la cronologia delle richieste di pagina. Per i dati di log, è consigliabile scrivere script o applicazioni personalizzati per caricarli in modo da avere la flessibilità necessaria per includere il componente di caricamento dei dati come parte dell'applicazione Big Data più grande.
Quando i dati sono disponibili nell'account, è possibile eseguire analisi su tali dati, creare visualizzazioni e persino scaricare i dati nel computer locale o in altri repository, ad esempio un database SQL di Azure o un'istanza di SQL Server.
La tabella seguente consiglia gli strumenti che è possibile usare per inserire, analizzare, visualizzare e scaricare i dati. Usare i collegamenti in questa tabella per trovare indicazioni su come configurare e usare ogni strumento.
Nota
Questa tabella non riflette l'elenco completo dei servizi di Azure che supportano Data Lake Storage. Per un elenco dei servizi di Azure supportati, vedere Servizi di Azure che supportano Azure Data Lake Storage.
Monitorare i dati di telemetria
Il monitoraggio dell'uso e delle prestazioni è una parte importante dell'operazionalizzazione del servizio. Gli esempi includono operazioni frequenti, operazioni con latenza elevata o operazioni che causano la limitazione lato servizio.
Tutti i dati di telemetria per l'account di archiviazione sono disponibili tramite Archiviazione di Azure log in Monitoraggio di Azure. Questa funzionalità integra l'account di archiviazione con Analisi dei log e Hub eventi, consentendo anche di archiviare i log in un altro account di archiviazione. Per visualizzare l'elenco completo dei log delle metriche e delle risorse e dello schema associato, consultare la sezione Archiviazione di Azure riferimento ai dati di monitoraggio.
La posizione in cui si sceglie di archiviare i log dipende dal modo in cui si prevede di accedervi. Ad esempio, se si vuole accedere ai log quasi in tempo reale e poter correlare gli eventi nei log con altre metriche di Monitoraggio di Azure, è possibile archiviare i log in un'area di lavoro Log Analytics. Eseguire quindi query sui log usando KQL e le query di creazione, che enumerare la tabella nell'area StorageBlobLogs di lavoro.
Se si vogliono archiviare i log sia per query quasi in tempo reale che per la conservazione a lungo termine, è possibile configurare le impostazioni di diagnostica per inviare i log a un'area di lavoro Log Analytics e a un account di archiviazione.
Per accedere ai log tramite un altro motore di query, ad esempio Splunk, è possibile configurare le impostazioni di diagnostica per inviare i log a un hub eventi e inserire i log dall'hub eventi alla destinazione scelta.
Archiviazione di Azure log in Monitoraggio di Azure possono essere abilitati tramite portale di Azure, PowerShell, l'interfaccia della riga di comando di Azure e i modelli di Azure Resource Manager. Per le distribuzioni su larga scala, è possibile usare Criteri di Azure con supporto completo per le attività di correzione. Per altre informazioni, vedere ciphertxt/AzureStoragePolicy.