Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Un archivio data lake è un repository che contiene una grande quantità di dati nel relativo formato nativo non elaborato. Gli archivi Data Lake sono ottimizzati per ridimensionare le dimensioni in terabyte e petabyte di dati. I dati provengono in genere da più origini diverse e possono includere dati strutturati, semistrutturati o non strutturati. Un data lake consente di archiviare tutti gli elementi nello stato originale e non trasformabile. Questo metodo è diverso da un data warehouse tradizionale, che trasforma ed elabora i dati al momento dell'inserimento.
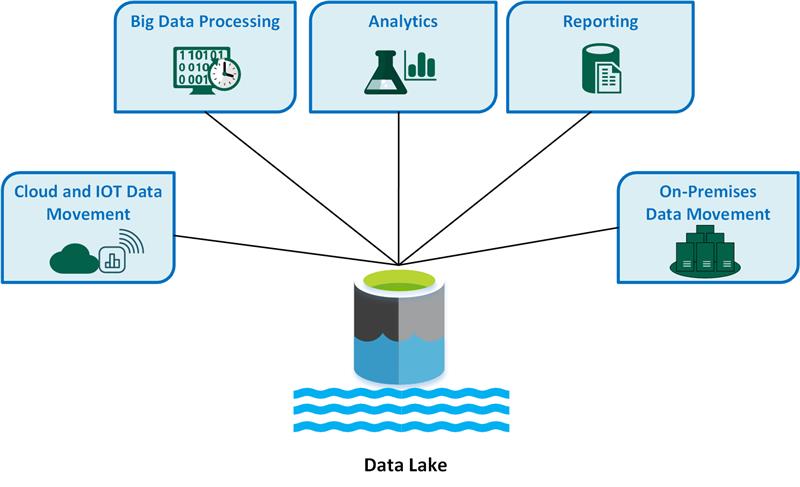
I casi d'uso di Data Lake principali includono:
- Movimento dei dati nel cloud e nell'Internet delle cose (IoT).
- Elaborazione di Big Data.
- Analisi.
- Creazione di report.
- Spostamento dei dati su infrastruttura interna.
Considerare i vantaggi seguenti di un data lake:
Un data lake non elimina mai i dati perché archivia i dati nel formato non elaborato. Questa funzionalità è particolarmente utile in un ambiente Big Data perché è possibile che non si conoscano in anticipo le informazioni dettagliate che è possibile ottenere dai dati.
Gli utenti possono esplorare i dati e creare le proprie query.
Un data lake potrebbe essere più veloce rispetto agli strumenti di estrazione, trasformazione, caricamento (ETL) tradizionali.
Un data lake è più flessibile di un data warehouse perché può archiviare dati non strutturati e semistrutturati.
Una soluzione data lake completa prevede l'archiviazione e l'elaborazione. Data Lake Storage è progettato per la tolleranza di errore, la scalabilità infinita e l'inserimento con velocità effettiva elevata di varie forme e dimensioni dei dati. L'elaborazione del data lake prevede uno o più motori di elaborazione che possono incorporare questi obiettivi e possono operare sui dati archiviati in un data lake su larga scala.
Quando è consigliabile usare un data lake
È consigliabile usare un data lake per l'esplorazione dei dati, l'analisi dei dati e l'apprendimento automatico.
Un data lake può fungere da origine dati per un data warehouse. Quando si usa questo metodo, il data lake inserisce dati non elaborati e quindi lo trasforma in un formato querybile strutturato. In genere, questa trasformazione usa una pipeline di estrazione, caricamento, trasformazione (ELT) in cui i dati vengono inseriti e trasformati sul posto. I dati di origine relazionale possono essere inseriti direttamente nel data warehouse tramite un processo ETL e ignorare il data lake.
È possibile usare gli archivi Data Lake in scenari di streaming di eventi o IoT perché i data lake possono rendere persistenti grandi quantità di dati relazionali e non relazionali senza trasformazione o definizione dello schema. I data lake possono gestire volumi elevati di scritture di piccole dimensioni a bassa latenza e sono ottimizzati per una velocità effettiva elevata.
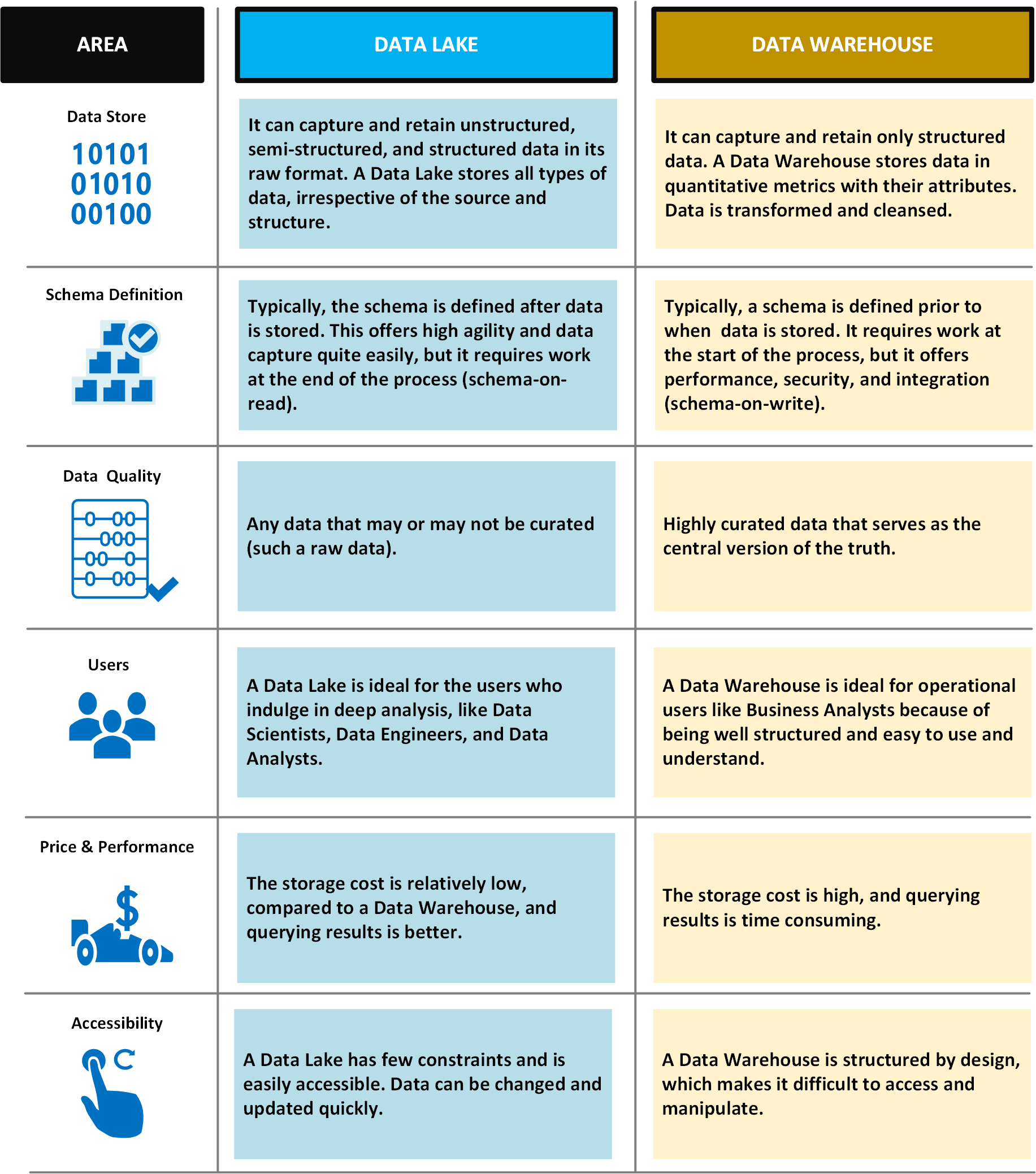
Nella tabella seguente vengono confrontati data lake e data warehouse.
Problematiche
Grandi volumi di dati: la gestione di grandi quantità di dati non elaborati e non strutturati può essere complessa e a elevato utilizzo di risorse, quindi sono necessari strumenti e infrastrutture affidabili.
Potenziali colli di bottiglia: l'elaborazione dei dati può introdurre ritardi ed inefficienze, soprattutto quando si hanno volumi elevati di dati e tipi di dati diversi.
Rischi di danneggiamento dei dati: la convalida e il monitoraggio dei dati non corretti comportano un rischio di danneggiamento dei dati, che può compromettere l'integrità del data lake.
Problemi di controllo qualità: la qualità corretta dei dati è una sfida a causa della varietà di origini dati e formati. È necessario implementare procedure rigorose per la governance dei dati.
Problemi di prestazioni: le prestazioni delle query possono peggiorare man mano che aumenta il data lake, quindi è necessario ottimizzare le strategie di archiviazione ed elaborazione.
Scelte di tecnologia
Quando si crea una soluzione Data Lake completa in Azure, prendere in considerazione le tecnologie seguenti:
Azure Data Lake Storage combina Azure Blob Storage con le capacità dei data lake, offrendo accesso compatibile con Apache Hadoop, funzionalità di namespace gerarchico e sicurezza avanzata per un'analisi efficiente dei Big Data.
Azure Databricks è una piattaforma unificata che è possibile usare per elaborare, archiviare, analizzare e monetizzare i dati. Supporta processi ETL, dashboard, sicurezza, esplorazione dei dati, Machine Learning e intelligenza artificiale generativa.
Azure Synapse Analytics è un servizio unificato che è possibile usare per inserire, esplorare, preparare, gestire e gestire i dati per esigenze immediate di Business Intelligence e Machine Learning. Si integra in modo approfondito con i data lake di Azure in modo da poter eseguire query e analizzare set di dati di grandi dimensioni in modo efficiente.
Azure Data Factory è un servizio di integrazione dei dati basato sul cloud che è possibile usare per creare flussi di lavoro basati sui dati per orchestrare e automatizzare lo spostamento e la trasformazione dei dati.
Microsoft Fabric è una piattaforma dati completa che unifica progettazione dei dati, data science, data warehouse, analisi in tempo reale e business intelligence in un'unica soluzione.
Collaboratori
Questo articolo viene gestito da Microsoft. Originariamente è stato scritto dai seguenti contributori.
Autore principale:
- Avijit Prasad | Consulente cloud
Per visualizzare i profili LinkedIn non pubblici, accedere a LinkedIn.
Passaggi successivi
- Che cos'è OneLake?
- Introduzione a Data Lake Storage
- Documentazione di Azure Data Lake Analytics
- Training: Introduzione a Data Lake Storage
- Integrazione di Hadoop e Azure Data Lake Storage
- Connettersi a Data Lake Storage e all'archiviazione BLOB
- Carica i dati in Data Lake Storage con Azure Data Factory