Considerazioni sulla piattaforma applicativa per carichi di lavoro cruciali in Azure
Azure offre molti servizi di calcolo per l'hosting di applicazioni a disponibilità elevata. I servizi differiscono in termini di funzionalità e complessità. È consigliabile scegliere i servizi in base a:
- Requisiti non funzionali per affidabilità, disponibilità, prestazioni e sicurezza.
- Fattori decisionali come scalabilità, costi, operabilità e complessità.
La scelta di una piattaforma di hosting di applicazioni è una decisione fondamentale che influisce su tutte le altre aree di progettazione. Ad esempio, il software di sviluppo legacy o proprietario potrebbe non essere eseguito nei servizi PaaS o nelle applicazioni in contenitori. Questa limitazione influisce sulla scelta della piattaforma di calcolo.
Un'applicazione mission-critical può usare più di un servizio di calcolo per supportare più carichi di lavoro compositi e microservizi, ognuno con requisiti distinti.
Questa area di progettazione fornisce raccomandazioni relative alle opzioni di calcolo, progettazione e configurazione. È anche consigliabile acquisire familiarità con l'albero delle decisioni di calcolo.
Importante
Questo articolo fa parte della serie di carichi di lavoro cruciali di Azure Well-Architected Framework. Se non si ha familiarità con questa serie, è consigliabile iniziare con Che cos'è un carico di lavoro cruciale?.
Distribuzione globale delle risorse della piattaforma
Un modello tipico per un carico di lavoro mission-critical include risorse globali e risorse regionali.
I servizi di Azure, che non sono vincolati a una determinata area di Azure, vengono distribuiti o configurati come risorse globali. Alcuni casi d'uso includono la distribuzione del traffico tra più aree, l'archiviazione dello stato permanente per un'intera applicazione e la memorizzazione nella cache dei dati statici globali. Se è necessario supportare sia un'architettura di unità di scala che una distribuzione globale, valutare come le risorse vengano distribuite o replicate in modo ottimale tra aree di Azure.
Altre risorse vengono distribuite a livello di area. Queste risorse, distribuite come parte di un timbro di distribuzione, corrispondono in genere a un'unità di scala. Tuttavia, un'area può avere più di un timbro e un timbro può avere più di un'unità. L'affidabilità delle risorse a livello di area è fondamentale perché è responsabile dell'esecuzione del carico di lavoro principale.
L'immagine seguente mostra la progettazione generale. Un utente accede all'applicazione tramite un punto di ingresso globale centrale che reindirizza quindi le richieste a un indicatore di distribuzione a livello di area appropriato:
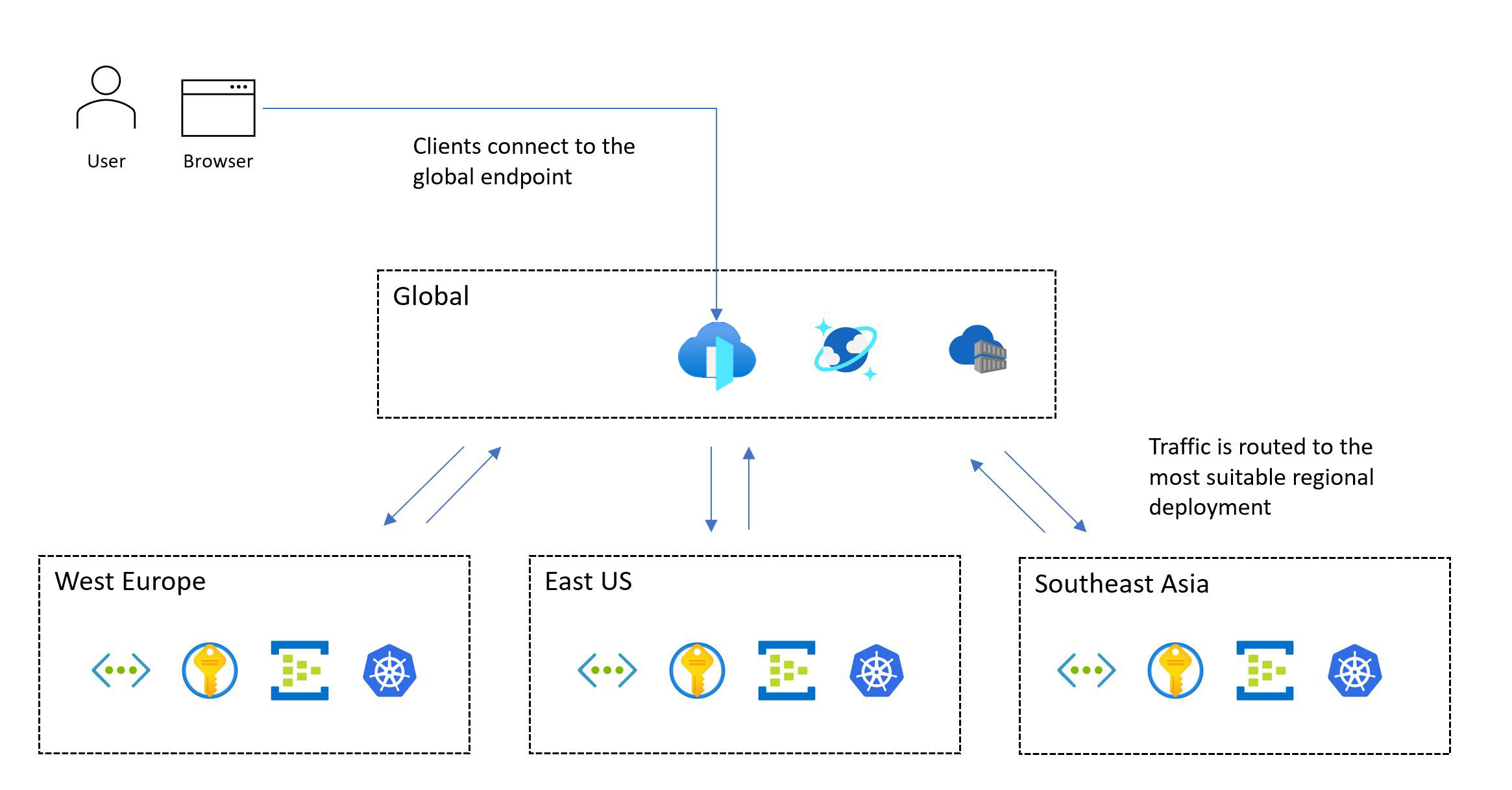
La metodologia di progettazione cruciale richiede una distribuzione in più aree. Questo modello garantisce la tolleranza di errore a livello di area, in modo che l'applicazione rimanga disponibile anche quando un'intera area diventa inattiva. Quando si progetta un'applicazione in più aree, prendere in considerazione strategie di distribuzione diverse, ad esempio attivo/attivo/attivo/passivo, insieme ai requisiti dell'applicazione, perché esistono compromessi significativi per ogni approccio. Per i carichi di lavoro cruciali, è consigliabile usare il modello attivo/attivo.
Non tutti i carichi di lavoro supportano o richiedono l'esecuzione simultanea di più aree. È consigliabile valutare requisiti specifici dell'applicazione rispetto ai compromessi per determinare una decisione di progettazione ottimale. Per determinati scenari di applicazione con destinazioni di affidabilità inferiori, il partizionamento orizzontale o attivo/passivo può essere un'alternativa adatta.
Le zone di disponibilità possono offrire distribuzioni a livello di area a disponibilità elevata in diversi data center all'interno di un'area. Quasi tutti i servizi di Azure sono disponibili in una configurazione di zona, in cui il servizio viene delegato a una zona specifica o a una configurazione con ridondanza della zona, in cui la piattaforma garantisce automaticamente che il servizio si estende su più zone e possa resistere a un'interruzione della zona. Queste configurazioni forniscono la tolleranza di errore fino al livello del data center.
Considerazioni relative alla progettazione
Funzionalità regionali e di zona. Non tutti i servizi e le funzionalità sono disponibili in ogni area di Azure. Questa considerazione può influire sulle aree scelte. Inoltre, le zone di disponibilità non sono disponibili in ogni area.
Coppie regionali. Le aree di Azure vengono raggruppate in coppie di aree che sono costituite da due aree in un'unica area geografica. Alcuni servizi di Azure usano aree abbinate per garantire la continuità aziendale e fornire un livello di protezione contro la perdita di dati. Ad esempio, l'archiviazione con ridondanza geografica di Azure replica automaticamente i dati in un'area associata secondaria, assicurandosi che i dati siano durevoli se l'area primaria non è recuperabile. Se un'interruzione influisce su più aree di Azure, almeno un'area in ogni coppia ha la priorità per il ripristino.
Coerenza dei dati. Per i problemi di coerenza, è consigliabile usare un archivio dati distribuito a livello globale, un'architettura a livello di area stampata e una distribuzione parzialmente attiva/attiva. In una distribuzione parziale, alcuni componenti sono attivi in tutte le aree, mentre altri si trovano centralmente all'interno dell'area primaria.
Distribuzione sicura. Il framework SDP (Safe Deployment Practice) di Azure garantisce che tutte le modifiche di codice e configurazione (manutenzione pianificata) alla piattaforma Azure vengano sottoposte a un'implementazione in più fasi. L'integrità viene analizzata per la riduzione delle prestazioni durante il rilascio. Al termine delle fasi canary e pilota, gli aggiornamenti della piattaforma vengono serializzati tra coppie di aree, quindi viene aggiornata una sola area in ogni coppia in un determinato momento.
Capacità della piattaforma. Come qualsiasi provider di servizi cloud, Azure ha risorse limitate. L'indisponibilità può essere il risultato di limitazioni di capacità nelle aree. Se si verifica un'interruzione a livello di area, si verifica un aumento della domanda di risorse quando il carico di lavoro tenta di eseguire il ripristino all'interno dell'area abbinata. L'interruzione potrebbe creare un problema di capacità, in cui l'offerta temporaneamente non soddisfa la domanda.
Suggerimenti per la progettazione
Distribuire la soluzione in almeno due aree di Azure per proteggersi da interruzioni a livello di area. Distribuirlo in aree con funzionalità e caratteristiche richieste dal carico di lavoro. Le funzionalità devono soddisfare obiettivi di prestazioni e disponibilità, rispettando al tempo stesso i requisiti di residenza e conservazione dei dati.
Ad esempio, alcuni requisiti di conformità dei dati potrebbero limitare il numero di aree disponibili e potenzialmente forzare i compromessi di progettazione. In questi casi, è consigliabile aggiungere investimenti aggiuntivi nei wrapper operativi per prevedere, rilevare e rispondere agli errori. Si supponga di essere vincolati a un'area geografica con due aree e solo una di queste aree supporta le zone di disponibilità (modello di data center 3 + 1). Creare un modello di distribuzione secondario usando l'isolamento del dominio di errore per consentire la distribuzione di entrambe le aree in una configurazione attiva e assicurarsi che l'area primaria contenga più indicatori di distribuzione.
Se le aree di Azure appropriate non offrono tutte le funzionalità necessarie, essere pronti a compromettere la coerenza dei francobolli di distribuzione a livello di area per classificare in ordine di priorità la distribuzione geografica e ottimizzare l'affidabilità. Se è adatta solo una singola area di Azure, distribuire più indicatori di distribuzione (unità di scala a livello di area) nell'area selezionata per attenuare alcuni rischi e usare le zone di disponibilità per fornire la tolleranza di errore a livello di data center. Tuttavia, un compromesso significativo nella distribuzione geografica vincola drasticamente l'SLO composito raggiungibile e l'affidabilità complessiva.
Per scenari di applicazioni su larga scala con volumi significativi di traffico, progettare la soluzione per la scalabilità in più aree per esplorare i potenziali vincoli di capacità all'interno di una singola area. Altri indicatori di distribuzione a livello di area possono ottenere un SLO composito più elevato. Per altre informazioni, vedere come implementare destinazioni multiregione.
Definire e convalidare gli obiettivi del punto di ripristino (RPO) e gli obiettivi del tempo di ripristino (RTO).
All'interno di una singola area geografica, assegnare priorità all'uso di coppie di aree per trarre vantaggio dalle implementazioni serializzate SDP per la manutenzione pianificata e la definizione delle priorità a livello di area per la manutenzione non pianificata.
La condivisione geografica delle risorse di Azure con gli utenti consente di ridurre al minimo la latenza di rete e ottimizzare le prestazioni end-to-end.
- È anche possibile usare soluzioni come una rete CDN (rete per la distribuzione di contenuti) o la memorizzazione nella cache perimetrale per favorire una latenza di rete ottimale per le basi utente distribuite. Per altre informazioni, vedere Routing del traffico globale, Servizi di distribuzione di applicazioni e Memorizzazione nella cache e distribuzione di contenuti statici.
Allineare la disponibilità del servizio corrente alle roadmap dei prodotti quando si scelgono le aree di distribuzione. Alcuni servizi potrebbero non essere immediatamente disponibili in ogni area.
Containerizzazione
Un contenitore include il codice dell'applicazione e i file di configurazione, le librerie e le dipendenze correlati che l'applicazione deve eseguire. La containerizzazione fornisce un livello di astrazione per il codice dell'applicazione e le relative dipendenze e crea la separazione dalla piattaforma host sottostante. Il singolo pacchetto software è altamente portatile e può essere eseguito in modo coerente tra varie piattaforme di infrastruttura e provider di servizi cloud. Gli sviluppatori non devono riscrivere il codice e possono distribuire applicazioni più velocemente e in modo più affidabile.
Importante
È consigliabile usare i contenitori per i pacchetti di applicazioni cruciali. Migliorano l'utilizzo dell'infrastruttura perché è possibile ospitare più contenitori nella stessa infrastruttura virtualizzata. Inoltre, poiché tutto il software è incluso nel contenitore, è possibile spostare l'applicazione in vari sistemi operativi, indipendentemente dai runtime o dalle versioni della libreria. La gestione è anche più semplice con i contenitori rispetto all'hosting virtualizzato tradizionale.
Le applicazioni cruciali devono essere ridimensionate rapidamente per evitare colli di bottiglia delle prestazioni. Poiché le immagini del contenitore sono predefinite, è possibile limitare l'avvio solo durante il bootstrap dell'applicazione, che offre scalabilità rapida.
Considerazioni relative alla progettazione
Monitoraggio. Può essere difficile per i servizi di monitoraggio accedere alle applicazioni presenti in contenitori. In genere è necessario software di terze parti per raccogliere e archiviare indicatori di stato del contenitore, ad esempio l'utilizzo della CPU o della RAM.
Protezione. Il kernel del sistema operativo della piattaforma di hosting viene condiviso tra più contenitori, creando un singolo punto di attacco. Tuttavia, il rischio di accesso alle macchine virtuali host è limitato perché i contenitori sono isolati dal sistema operativo sottostante.
Stato. Anche se è possibile archiviare i dati in un file system del contenitore in esecuzione, i dati non verranno mantenuti quando il contenitore viene ricreato. Rendere persistenti invece i dati montando l'archiviazione esterna o usando un database esterno.
Suggerimenti per la progettazione
In contenitori tutti i componenti dell'applicazione. Usare le immagini del contenitore come modello principale per i pacchetti di distribuzione dell'applicazione.
Classificare in ordine di priorità i runtime dei contenitori basati su Linux, quando possibile. Le immagini sono più leggere e le nuove funzionalità per nodi/contenitori Linux vengono rilasciate di frequente.
Rendere i contenitori non modificabili e sostituibili, con cicli di vita brevi.
Assicurarsi di raccogliere tutti i log e le metriche pertinenti dal contenitore, dall'host del contenitore e dal cluster sottostante. Inviare i log e le metriche raccolti a un sink di dati unificato per un'ulteriore elaborazione e analisi.
Archiviare le immagini del contenitore in Registro Azure Container. Usare la replica geografica per replicare le immagini del contenitore in tutte le aree. Abilitare Microsoft Defender per i registri contenitori per fornire l'analisi delle vulnerabilità per le immagini del contenitore. Assicurarsi che l'accesso al Registro di sistema sia gestito da Microsoft Entra ID.
Hosting e orchestrazione di contenitori
Diverse piattaforme applicative di Azure possono ospitare in modo efficace i contenitori. Esistono vantaggi e svantaggi associati a ognuna di queste piattaforme. Confrontare le opzioni nel contesto dei requisiti aziendali. Tuttavia, ottimizzare sempre l'affidabilità, la scalabilità e le prestazioni. Vedi questi articoli per ulteriori informazioni:
Importante
servizio Azure Kubernetes (AKS) e App azure Container devono essere tra le prime scelte per la gestione dei contenitori a seconda dei requisiti. Anche se app Azure Servizio non è un agente di orchestrazione, come piattaforma contenitore a basso attrito, è comunque un'alternativa fattibile al servizio Azure Kubernetes.
Considerazioni sulla progettazione e raccomandazioni per servizio Azure Kubernetes
Il servizio Azure Kubernetes, un servizio Kubernetes gestito, consente il provisioning rapido del cluster senza richiedere attività complesse di amministrazione del cluster e offre un set di funzionalità che include funzionalità avanzate di rete e identità. Per un set completo di raccomandazioni, vedere Panoramica di Azure Well-Architected Framework - Servizio Azure Kubernetes.
Importante
Esistono alcune decisioni di configurazione fondamentali che non è possibile modificare senza ridribuire il cluster del servizio Azure Kubernetes. Gli esempi includono la scelta tra cluster del servizio Azure Kubernetes pubblici e privati, l'abilitazione di Criteri di rete di Azure, l'integrazione di Microsoft Entra e l'uso di identità gestite per il servizio Azure Kubernetes anziché per le entità servizio.
Affidabilità
Il servizio Azure Kubernetes gestisce il piano di controllo Kubernetes nativo. Se il piano di controllo non è disponibile, il carico di lavoro subisce tempi di inattività. Sfruttare le funzionalità di affidabilità offerte dal servizio Azure Kubernetes:
Distribuire cluster del servizio Azure Kubernetes in aree di Azure diverse come unità di scala per ottimizzare l'affidabilità e la disponibilità. Usare le zone di disponibilità per ottimizzare la resilienza all'interno di un'area di Azure distribuendo il piano di controllo del servizio Azure Kubernetes e i nodi agente tra data center separati fisicamente. Tuttavia, se la latenza di condivisione è un problema, è possibile eseguire la distribuzione del servizio Azure Kubernetes all'interno di una singola zona o usare gruppi di posizionamento di prossimità per ridurre al minimo la latenza internode.
Usare il contratto di servizio Tempo di attività del servizio Azure Kubernetes per i cluster di produzione per ottimizzare le garanzie di disponibilità degli endpoint dell'API Kubernetes.
Scalabilità
Prendere in considerazione i limiti di scalabilità del servizio Azure Kubernetes, ad esempio il numero di nodi, i pool di nodi per ogni cluster e i cluster per ogni sottoscrizione.
Se i limiti di scala sono un vincolo, sfruttare la strategia di unità di scala e distribuire più unità con cluster.
Abilitare la scalabilità automatica del cluster per regolare automaticamente il numero di nodi agente in risposta ai vincoli delle risorse.
Usare il ridimensionamento automatico orizzontale dei pod per regolare il numero di pod in una distribuzione in base all'utilizzo della CPU o ad altre metriche.
Per scenari con scalabilità elevata e burst, è consigliabile usare nodi virtuali per una scalabilità estesa e rapida.
Definire le richieste e i limiti delle risorse dei pod nei manifesti di distribuzione dell'applicazione. In caso contrario, potrebbero verificarsi problemi di prestazioni.
Isolamento
Mantenere i limiti tra l'infrastruttura usata dai carichi di lavoro e dagli strumenti di sistema. L'infrastruttura di condivisione potrebbe portare a un utilizzo elevato delle risorse e a scenari adiacenti rumorosi.
Usare pool di nodi separati per i servizi di sistema e carico di lavoro. I pool di nodi dedicati per i componenti del carico di lavoro devono essere basati sui requisiti per risorse di infrastruttura specializzate, ad esempio macchine virtuali GPU a memoria elevata. In generale, per ridurre il sovraccarico di gestione non necessario, evitare di distribuire un numero elevato di pool di nodi.
Usaretaints e tolerations per fornire nodi dedicati e limitare le applicazioni a elevato utilizzo di risorse.
Valutare i requisiti di affinità dell'applicazione e anti-affinità e configurare la corilevazione appropriata dei contenitori nei nodi.
Sicurezza
Il valore predefinito di Vanilla Kubernetes richiede una configurazione significativa per garantire un comportamento di sicurezza appropriato per scenari cruciali. Il servizio Azure Kubernetes risolve diversi rischi per la sicurezza. Le funzionalità includono cluster privati, controllo e accesso a Log Analytics, immagini dei nodi con protezione avanzata e identità gestite.
Applicare le linee guida di configurazione fornite nella baseline di sicurezza del servizio Azure Kubernetes.
Usare le funzionalità del servizio Azure Kubernetes per gestire l'identità del cluster e la gestione degli accessi per ridurre il sovraccarico operativo e applicare una gestione coerente degli accessi.
Usare le identità gestite anziché le entità servizio per evitare la gestione e la rotazione delle credenziali. È possibile aggiungere identità gestite a livello di cluster. A livello di pod, è possibile usare le identità gestite tramite ID dei carichi di lavoro di Microsoft Entra.
Usare l'integrazione di Microsoft Entra per la gestione centralizzata degli account e le password, la gestione degli accessi alle applicazioni e la protezione avanzata delle identità. Usare il controllo degli accessi in base al ruolo di Kubernetes con Microsoft Entra ID per privilegi minimi e ridurre al minimo la concessione dei privilegi di amministratore per proteggere l'accesso alla configurazione e ai segreti. Limitare anche l'accesso al file di configurazione del cluster Kubernetes usando il controllo degli accessi in base al ruolo di Azure. Limitare l'accesso alle azioni che i contenitori possono eseguire, fornire il minor numero di autorizzazioni ed evitare l'uso dell'escalation dei privilegi radice.
Aggiornamenti
I cluster e i nodi devono essere aggiornati regolarmente. Il servizio Azure Kubernetes supporta le versioni di Kubernetes in allineamento con il ciclo di rilascio di Kubernetes nativo.
Sottoscrivere la roadmap pubblica del servizio Azure Kubernetes e le note sulla versione in GitHub per rimanere aggiornati sulle modifiche, i miglioramenti e, soprattutto, le versioni di Kubernetes e le deprecazioni.
Applicare le indicazioni fornite nell'elenco di controllo del servizio Azure Kubernetes per garantire l'allineamento con le procedure consigliate.
Tenere presente i vari metodi supportati dal servizio Azure Kubernetes per l'aggiornamento di nodi e/o cluster. Questi metodi possono essere manuali o automatizzati. È possibile usare manutenzione pianificata per definire le finestre di manutenzione per queste operazioni. Le nuove immagini vengono rilasciate settimanalmente. Il servizio Azure Kubernetes supporta anche i canali di aggiornamento automatico per l'aggiornamento automatico dei cluster del servizio Azure Kubernetes alle versioni più recenti delle immagini dei nodi e/o versioni più recenti quando sono disponibili.
Rete
Valutare i plug-in di rete più adatti al caso d'uso. Determinare se è necessario un controllo granulare del traffico tra pod. supporto tecnico di Azure kubenet, Azure CNI e bring your own CNI per casi d'uso specifici.
Classificare in ordine di priorità l'uso di Azure CNI dopo aver valutato i requisiti di rete e le dimensioni del cluster. Azure CNI consente l'uso dei criteri di rete di Azure o Calico per controllare il traffico all'interno del cluster.
Monitoraggio
Gli strumenti di monitoraggio devono essere in grado di acquisire log e metriche dall'esecuzione dei pod. È anche necessario raccogliere informazioni dall'API Metriche kubernetes per monitorare l'integrità delle risorse e dei carichi di lavoro in esecuzione.
Usare Monitoraggio di Azure e Application Insights per raccogliere metriche, log e diagnostica dalle risorse del servizio Azure Kubernetes per la risoluzione dei problemi.
Abilitare ed esaminare i log delle risorse kubernetes.
Configurare le metriche di Prometheus in Monitoraggio di Azure. Informazioni dettagliate sui contenitori in Monitoraggio offre l'onboarding, abilita le funzionalità di monitoraggio predefinite e abilita funzionalità più avanzate tramite il supporto predefinito di Prometheus.
Governance
Usare i criteri per applicare misure di sicurezza centralizzate ai cluster del servizio Azure Kubernetes in modo coerente. Applicare assegnazioni di criteri a un ambito di sottoscrizione o superiore per favorire la coerenza tra i team di sviluppo.
Controllare quali funzioni vengono concesse ai pod e se l'esecuzione di criteri contraddice, usando Criteri di Azure. Questo accesso viene definito tramite i criteri predefiniti forniti dal componente aggiuntivo Criteri di Azure per il servizio Azure Kubernetes.
Stabilire una baseline di sicurezza e affidabilità coerente per le configurazioni di cluster e pod del servizio Azure Kubernetes usando Criteri di Azure.
Usare il componente aggiuntivo Criteri di Azure per il servizio Azure Kubernetes per controllare le funzioni dei pod, ad esempio i privilegi radice, e per impedire i pod che non sono conformi ai criteri.
Nota
Quando si esegue la distribuzione in una zona di destinazione di Azure, i criteri di Azure per garantire affidabilità e sicurezza coerenti devono essere forniti dall'implementazione della zona di destinazione.
Le implementazioni di riferimento cruciali forniscono una suite di criteri di base per guidare le configurazioni di affidabilità e sicurezza consigliate.
Considerazioni sulla progettazione e consigli per il servizio app Azure
Per gli scenari di carico di lavoro basati su Web e API, servizio app potrebbe essere un'alternativa fattibile al servizio Azure Kubernetes. Offre una piattaforma contenitore a basso attrito senza la complessità di Kubernetes. Per un set completo di raccomandazioni, vedere Considerazioni sull'affidabilità per servizio app e Eccellenza operativa per servizio app.
Affidabilità
Valutare l'uso delle porte TCP e SNAT. Le connessioni TCP vengono usate per tutte le connessioni in uscita. Le porte SNAT vengono usate per le connessioni in uscita agli indirizzi IP pubblici. L'esaurimento delle porte SNAT è uno scenario di errore comune. È consigliabile rilevare questo problema tramite test di carico durante l'uso di Diagnostica di Azure per monitorare le porte. Se si verificano errori SNAT, è necessario ridimensionare i ruoli di lavoro più o più grandi o implementare procedure di codifica per mantenere e riutilizzare le porte SNAT. Esempi di procedure di codifica che è possibile usare includono il pool di connessioni e il caricamento differita delle risorse.
L'esaurimento delle porte TCP è un altro scenario di errore. Si verifica quando la somma delle connessioni in uscita da un determinato ruolo di lavoro supera la capacità. Il numero di porte TCP disponibili dipende dalle dimensioni del ruolo di lavoro. Per indicazioni, vedere Porte TCP e SNAT.
Scalabilità
Pianificare i requisiti di scalabilità futuri e la crescita delle applicazioni in modo da poter applicare le raccomandazioni appropriate fin dall'inizio. In questo modo, è possibile evitare il debito tecnico di migrazione man mano che la soluzione cresce.
Abilitare la scalabilità automatica per garantire che le risorse adeguate siano disponibili per le richieste di servizio. Valutare il ridimensionamento per app per l'hosting ad alta densità in servizio app.
Tenere presente che servizio app ha un limite flessibile predefinito di istanze per ogni piano di servizio app.
Applicare le regole di scalabilità automatica. Un piano di servizio app aumenta il numero di istanze se viene soddisfatta una regola all'interno del profilo, ma viene ridimensionata solo se vengono soddisfatte tutte le regole all'interno del profilo. Usare una combinazione di regole di scalabilità orizzontale e scalabilità orizzontale per garantire che la scalabilità automatica possa intervenire sia per aumentare il numero di istanze che per aumentare il numero di istanze. Comprendere il comportamento di più regole di ridimensionamento in un singolo profilo.
Tenere presente che è possibile abilitare il ridimensionamento per app al livello del piano di servizio app per consentire a un'applicazione di essere ridimensionata in modo indipendente dal piano di servizio app che lo ospita. Le app vengono allocate ai nodi disponibili tramite un approccio ottimale per una distribuzione uniforme. Anche se non è garantita una distribuzione uniforme, la piattaforma garantisce che due istanze della stessa app non siano ospitate nella stessa istanza.
Monitoraggio
Monitorare il comportamento dell'applicazione e ottenere l'accesso ai log e alle metriche pertinenti per assicurarsi che l'applicazione funzioni come previsto.
È possibile usare la registrazione diagnostica per inserire log a livello di applicazione e a livello di piattaforma in Log Analytics, Archiviazione di Azure o in uno strumento di terze parti tramite Hub eventi di Azure.
Il monitoraggio delle prestazioni delle applicazioni con Application Insights offre informazioni approfondite sulle prestazioni dell'applicazione.
Le applicazioni cruciali devono avere la possibilità di auto-guarire in caso di errori. Abilita Correzione automatica per riciclare automaticamente i ruoli di lavoro non integri.
È necessario usare i controlli di integrità appropriati per valutare tutte le dipendenze downstream critiche, che consentono di garantire l'integrità complessiva. È consigliabile abilitare Controllo integrità per identificare i ruoli di lavoro non reattivi.
Distribuzione
Per aggirare il limite predefinito di istanze per ogni piano di servizio app, distribuire servizio app piani in più unità di scala in una singola area. Distribuire servizio app piani in una configurazione della zona di disponibilità per assicurarsi che i nodi di lavoro vengano distribuiti tra zone all'interno di un'area. Prendere in considerazione l'apertura di un ticket di supporto per aumentare il numero massimo di ruoli di lavoro al doppio del numero di istanze che è necessario gestire il carico di picco normale.
Registro contenitori
I registri contenitori ospitano immagini host distribuite in ambienti di runtime del contenitore come il servizio Azure Kubernetes. È necessario configurare con attenzione i registri contenitori per carichi di lavoro cruciali. Un'interruzione non dovrebbe causare ritardi nel pull delle immagini, in particolare durante le operazioni di ridimensionamento. Le considerazioni e le raccomandazioni seguenti sono incentrate su Registro Azure Container ed esplorare i compromessi associati ai modelli di distribuzione centralizzati e federati.
Considerazioni relative alla progettazione
Formato. Prendere in considerazione l'uso di un registro contenitori che si basa sul formato e sugli standard forniti da Docker per le operazioni push e pull. Queste soluzioni sono compatibili e per lo più intercambiabili.
Modello di distribuzione. È possibile distribuire il registro contenitori come servizio centralizzato usato da più applicazioni all'interno dell'organizzazione. In alternativa, è possibile distribuirlo come componente dedicato per un carico di lavoro specifico dell'applicazione.
Registri pubblici. Le immagini del contenitore vengono archiviate nell'hub Docker o in altri registri pubblici esistenti all'esterno di Azure e in una determinata rete virtuale. Questo non è necessariamente un problema, ma può causare vari problemi correlati alla disponibilità del servizio, alla limitazione e all'esfiltrazione dei dati. Per alcuni scenari di applicazione, è necessario replicare immagini di contenitori pubbliche in un registro contenitori privato per limitare il traffico in uscita, aumentare la disponibilità o evitare potenziali limitazioni.
Suggerimenti per la progettazione
Usare le istanze del Registro Azure Container dedicate al carico di lavoro dell'applicazione. Evitare di creare una dipendenza da un servizio centralizzato, a meno che i requisiti di disponibilità e affidabilità dell'organizzazione non siano completamente allineati all'applicazione.
Nel modello di architettura di base consigliato, i registri contenitori sono risorse globali di lunga durata. Prendere in considerazione l'uso di un singolo registro contenitori globale per ogni ambiente. Ad esempio, usare un registro di produzione globale.
Assicurarsi che il contratto di servizio per il Registro di sistema pubblico sia allineato agli obiettivi di affidabilità e sicurezza. Prendere nota dei limiti di limitazione per i casi d'uso che dipendono dall'hub Docker.
Classificare in ordine di priorità Registro Azure Container per l'hosting di immagini del contenitore.
Considerazioni e raccomandazioni sulla progettazione per Registro Azure Container
Questo servizio nativo offre una gamma di funzionalità, tra cui la replica geografica, l'autenticazione di Microsoft Entra, la compilazione automatizzata dei contenitori e l'applicazione di patch tramite attività del Registro Container.
Affidabilità
Configurare la replica geografica in tutte le aree di distribuzione per rimuovere le dipendenze a livello di area e ottimizzare la latenza. Registro Container supporta la disponibilità elevata tramite la replica geografica in più aree configurate, offrendo resilienza in caso di interruzioni a livello di area. Se un'area non è più disponibile, le altre aree continuano a gestire le richieste di immagine. Quando l'area è di nuovo online, Registro Container recupera e replica le modifiche apportate. Questa funzionalità offre anche la condivisione del Registro di sistema all'interno di ogni area configurata, riducendo la latenza di rete e i costi di trasferimento dei dati tra aree.
Nelle aree di Azure che forniscono supporto per la zona di disponibilità, il livello Registro Azure Container Premium supporta la ridondanza della zona per garantire la protezione da errori di zona. Il livello Premium supporta anche gli endpoint privati per impedire l'accesso non autorizzato al Registro di sistema, che può causare problemi di affidabilità.
Ospitare immagini vicine alle risorse di calcolo che usano, all'interno delle stesse aree di Azure.
Blocco delle immagini
Le immagini possono essere eliminate, a seguito di un errore manuale, ad esempio. Registro Container supporta il blocco di una versione dell'immagine o di un repository per impedire modifiche o eliminazioni. Quando viene modificata una versione dell'immagine distribuita in precedenza, le distribuzioni della stessa versione potrebbero fornire risultati diversi prima e dopo la modifica.
Se si vuole proteggere l'istanza del Registro Container dall'eliminazione, usare i blocchi delle risorse.
Immagini con tag
Le immagini del Registro Contenitori contrassegnate sono modificabili per impostazione predefinita, il che significa che lo stesso tag può essere usato in più immagini di cui viene eseguito il push nel Registro di sistema. Negli scenari di produzione questo può causare un comportamento imprevedibile che potrebbe influire sul tempo di attività dell'applicazione.
Gestione delle identità e dell'accesso
Usare l'autenticazione integrata di Microsoft Entra per eseguire il push e il pull delle immagini invece di basarsi sulle chiavi di accesso. Per una maggiore sicurezza, disabilitare completamente l'uso della chiave di accesso amministratore.
Calcolo serverless
L'elaborazione serverless fornisce risorse su richiesta ed elimina la necessità di gestire l'infrastruttura. Il provider di servizi cloud effettua automaticamente il provisioning, la scalabilità e gestisce le risorse necessarie per eseguire il codice dell'applicazione distribuito. Azure offre diverse piattaforme di calcolo serverless:
Funzioni di Azure. Quando si usa Funzioni di Azure, la logica dell'applicazione viene implementata come blocchi distinti di codice o funzioni eseguite in risposta a eventi, ad esempio una richiesta HTTP o un messaggio di coda. Ogni funzione viene ridimensionata in base alle esigenze per soddisfare la domanda.
App per la logica di Azure. App per la logica è ideale per la creazione e l'esecuzione di flussi di lavoro automatizzati che integrano varie app, origini dati, servizi e sistemi. Come Funzioni di Azure, App per la logica usa trigger predefiniti per l'elaborazione guidata dagli eventi. Tuttavia, invece di distribuire il codice dell'applicazione, è possibile creare app per la logica usando un'interfaccia utente grafica che supporta blocchi di codice come condizionali e cicli.
Gestione API di Azure. È possibile usare Gestione API per pubblicare, trasformare, gestire e monitorare le API di sicurezza avanzata usando il livello Consumo.
Power Apps e Power Automate. Questi strumenti offrono un'esperienza di sviluppo con poco codice o senza codice, con semplici integrazioni e logica del flusso di lavoro configurabili tramite connessioni in un'interfaccia utente.
Per le applicazioni cruciali, le tecnologie serverless offrono operazioni e sviluppo semplificate, che possono essere utili per semplici casi d'uso aziendali. Tuttavia, questa semplicità comporta il costo della flessibilità in termini di scalabilità, affidabilità e prestazioni e ciò non è fattibile per la maggior parte degli scenari di applicazioni cruciali.
Le sezioni seguenti forniscono considerazioni sulla progettazione e consigli per l'uso di app per la logica e Funzioni di Azure come piattaforme alternative per scenari di flusso di lavoro non critici.
Considerazioni e raccomandazioni sulla progettazione per Funzioni di Azure
I carichi di lavoro cruciali hanno flussi di sistema critici e non critici. Funzioni di Azure è una scelta praticabile per i flussi che non hanno gli stessi requisiti aziendali rigorosi dei flussi di sistema critici. È particolarmente adatto per i flussi basati su eventi che hanno processi di breve durata perché le funzioni eseguono operazioni distinte che vengono eseguite il più velocemente possibile.
Scegliere un'opzione di hosting Funzioni di Azure appropriata per il livello di affidabilità dell'applicazione. È consigliabile il piano Premium perché consente di configurare le dimensioni dell'istanza di calcolo. Il piano dedicato è l'opzione meno serverless. Offre scalabilità automatica, ma queste operazioni di scalabilità sono più lente rispetto a quelle degli altri piani. È consigliabile usare il piano Premium per ottimizzare l'affidabilità e le prestazioni.
Esistono alcune considerazioni sulla sicurezza. Quando si usa un trigger HTTP per esporre un endpoint esterno, usare un web application firewall (WAF) per fornire un livello di protezione per l'endpoint HTTP da vettori di attacco esterni comuni.
È consigliabile usare endpoint privati per limitare l'accesso alle reti virtuali private. Possono anche attenuare i rischi di esfiltrazione dei dati, ad esempio scenari di amministrazione dannosi.
È necessario usare gli strumenti di analisi del codice in Funzioni di Azure codice e integrare tali strumenti con pipeline CI/CD.
Considerazioni e raccomandazioni sulla progettazione per App per la logica di Azure
Come Funzioni di Azure, App per la logica usa trigger predefiniti per l'elaborazione guidata dagli eventi. Tuttavia, invece di distribuire il codice dell'applicazione, è possibile creare app per la logica usando un'interfaccia utente grafica che supporta blocchi come condizionali, cicli e altri costrutti.
Sono disponibili più modalità di distribuzione. È consigliabile usare la modalità Standard per garantire una distribuzione a tenant singolo e attenuare gli scenari adiacenti rumorosi. Questa modalità usa il runtime di App per la logica a tenant singolo in contenitori, basato su Funzioni di Azure. In questa modalità, l'app per la logica può avere più flussi di lavoro con stato e senza stato. È necessario tenere presenti i limiti di configurazione.
Migrazioni vincolate tramite IaaS
Molte applicazioni con distribuzioni locali esistenti usano tecnologie di virtualizzazione e hardware ridondante per offrire livelli cruciali di affidabilità. La modernizzazione è spesso ostacolata da vincoli aziendali che impediscono l'allineamento completo con il modello di architettura di base nativa del cloud (North Star) consigliato per carichi di lavoro cruciali. Ecco perché molte applicazioni adottano un approccio graduale, con distribuzioni cloud iniziali che usano la virtualizzazione e Azure Macchine virtuali come modello di hosting dell'applicazione principale. L'uso di macchine virtuali IaaS (Infrastructure as a Service) potrebbe essere necessario in determinati scenari:
- I servizi PaaS disponibili non forniscono le prestazioni o il livello di controllo necessari.
- Il carico di lavoro richiede l'accesso al sistema operativo, driver specifici o configurazioni di rete e di sistema.
- Il carico di lavoro non supporta l'esecuzione in contenitori.
- Non è disponibile alcun supporto fornitore per carichi di lavoro di terze parti.
Questa sezione è incentrata sui modi migliori per usare Macchine virtuali e i servizi associati per ottimizzare l'affidabilità della piattaforma dell'applicazione. Evidenzia gli aspetti chiave della metodologia di progettazione mission-critical che trasposizione di scenari di migrazione IaaS e nativi del cloud.
Considerazioni relative alla progettazione
I costi operativi dell'uso delle macchine virtuali IaaS sono significativamente superiori ai costi dell'uso dei servizi PaaS a causa dei requisiti di gestione delle macchine virtuali e dei sistemi operativi. La gestione delle macchine virtuali richiede l'implementazione frequente di pacchetti software e aggiornamenti.
Azure offre funzionalità per aumentare la disponibilità delle macchine virtuali:
- Le zone di disponibilità consentono di ottenere livelli di affidabilità ancora più elevati distribuendo le macchine virtuali tra data center separati fisicamente all'interno di un'area.
- I set di scalabilità di macchine virtuali di Azure offrono funzionalità per ridimensionare automaticamente il numero di macchine virtuali in un gruppo. Forniscono anche funzionalità per il monitoraggio dell'integrità dell'istanza e il ripristino automatico delle istanze non integre.
- I set di scalabilità con orchestrazione flessibile consentono di proteggersi da errori di rete, disco e alimentazione distribuendo automaticamente le macchine virtuali tra domini di errore.
Suggerimenti per la progettazione
Importante
Usare i servizi e i contenitori PaaS quando possibile per ridurre la complessità operativa e i costi. Usare macchine virtuali IaaS solo quando è necessario.
Dimensioni corrette dello SKU della macchina virtuale per garantire un utilizzo effettivo delle risorse.
Distribuire tre o più macchine virtuali tra zone di disponibilità per ottenere la tolleranza di errore a livello di data center.
- Se stai distribuendo software commerciale off-the-shelf, consulta il fornitore del software e testa adeguatamente prima di distribuire il software nell'ambiente di produzione.
Per i carichi di lavoro che non è possibile distribuire tra zone di disponibilità, usare set di scalabilità di macchine virtuali flessibili che contengono tre o più macchine virtuali. Per altre informazioni su come configurare il numero corretto di domini di errore, vedere Gestire i domini di errore nei set di scalabilità.
Assegnare priorità all'uso di set di scalabilità di macchine virtuali per la scalabilità e la ridondanza della zona. Questo punto è particolarmente importante per i carichi di lavoro con carichi di lavoro variabili. Ad esempio, se il numero di utenti o richieste attive al secondo è un carico variabile.
Non accedere direttamente alle singole macchine virtuali. Quando possibile, usare i servizi di bilanciamento del carico.
Per proteggersi da interruzioni a livello di area, distribuire le macchine virtuali delle applicazioni in più aree di Azure.
Per i carichi di lavoro che non supportano distribuzioni attive/attive in più aree, è consigliabile implementare distribuzioni attive/passive usando macchine virtuali hot/warm standby per il failover a livello di area.
Usare immagini standard di Azure Marketplace anziché immagini personalizzate che devono essere mantenute.
Implementare processi automatizzati per distribuire e implementare le modifiche alle macchine virtuali, evitando qualsiasi intervento manuale. Per altre informazioni, vedere Considerazioni IaaS nell'area Progettazione procedure operative.
Implementare esperimenti chaos per inserire errori dell'applicazione nei componenti della macchina virtuale e osservare la mitigazione degli errori. Per altre informazioni, vedere Convalida e test continui.
Monitorare le macchine virtuali e assicurarsi che i log di diagnostica e le metriche vengano inseriti in un sink di dati unificato.
Implementare procedure di sicurezza per scenari di applicazioni cruciali, se applicabili e procedure consigliate per la sicurezza per i carichi di lavoro IaaS in Azure.
Passaggio successivo
Esaminare le considerazioni per la piattaforma dati.