Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a:![]() database SQL di Azure
database SQL di Azure![]() database SQL in Fabric
database SQL in Fabric
Questo articolo illustra come identificare i deadlock, usare grafici deadlock e Query Store per identificare le query nel deadlock e pianificare e testare le modifiche per evitare che i deadlock vengano eseguiti di nuovo. Questo articolo si applica al database SQL di Azure e al database SQL di Azure in Fabric, che condivide molte funzionalità del database SQL di Azure.
Questo articolo è incentrato sull'identificazione e l'analisi dei deadlock causati da contesa dei blocchi. Altre informazioni su altri tipi di deadlock in Risorse che possono causare un deadlock.
Come si verificano i deadlock
Ogni nuovo database in Azure SQL ha l'impostazione del database read committed snapshot isolation (RCSI) abilitata per impostazione predefinita. Il bloccaggio tra le sessioni che leggono i dati e le sessioni di scrittura dei dati è minimizzato in RCSI, che usa il controllo delle versioni delle righe per aumentare la concorrenza. Tuttavia, il blocco e i deadlock possono comunque verificarsi nei database nel database SQL di Azure perché:
Le query che modificano i dati potrebbero bloccarsi tra loro.
Le query possono essere eseguite con livelli di isolamento che aumentano il blocco. I livelli di isolamento possono essere specificati tramite metodi di libreria client, suggerimenti di queryo SET TRANSACTION ISOLATION LEVEL in Transact-SQL.
RCSI potrebbe essere disabilitato, causando l'uso di blocchi condivisi (S) per proteggere le istruzioni
SELECTeseguite sotto il livello di isolamento "read committed". Ciò potrebbe aumentare il blocco e i deadlock.
Un esempio di deadlock
Un deadlock si verifica quando due o più attività si bloccano reciprocamente in modo permanente, in quanto ogni attività ha un blocco su una risorsa che l'altra attività sta cercando di bloccare. Un deadlock è anche chiamato dipendenza ciclica: nel caso di un deadlock a due attività, la transazione A ha una dipendenza dalla transazione B e la transazione B chiude il cerchio avendo una dipendenza dalla transazione A.
Ad esempio:
La sessione A avvia una transazione esplicita ed esegue un'istruzione di aggiornamento che acquisisce un blocco di aggiornamento (U) su una riga della tabella
SalesLT.Productconvertita in un blocco esclusivo (X).La sessione B esegue un'istruzione di aggiornamento che modifica la tabella
SalesLT.ProductDescription. L'istruzione di aggiornamento viene aggiunta alla tabellaSalesLT.Productper trovare le righe corrette da aggiornare.La sessione B acquisisce un blocco di aggiornamento (U) su 72 righe nella tabella
SalesLT.ProductDescription.La sessione B richiede un blocco condiviso sulle righe della tabella
SalesLT.Product, inclusa la riga bloccata dalla sessione A. La sessione B è bloccata inSalesLT.Product.
La sessione A continua la transazione e ora esegue un aggiornamento sulla tabella
SalesLT.ProductDescription. La sessione A è bloccata dalla sessione B inSalesLT.ProductDescription.

Tutte le transazioni in un deadlock sono in attesa illimitata a meno che non venga eseguito il rollback di una delle transazioni partecipanti, ad esempio perché la sessione è stata terminata.
La funzionalità di monitoraggio dei deadlock del motore di ricerca del database ricerca periodicamente le attività interessate da un deadlock. Se il monitor del deadlock rileva una dipendenza ciclica, sceglie una delle attività da considerare vittima e termina la sua transazione con l'errore 1205: Transaction (Process ID <N>) was deadlocked on lock resources with another process and is chosen as the deadlock victim. Rerun the transaction.. Interrompere il deadlock in questo modo consente alle altre attività coinvolte nel deadlock di completare le loro transazioni.
Nota
Per altre informazioni sui criteri per la scelta di una vittima di deadlock, vedere la sezione Elenco dei processi di deadlock di questo articolo.

L'applicazione con la transazione scelta come vittima del deadlock deve riprovare la transazione, che in genere viene completata al termine delle altre transazioni coinvolte nel deadlock.
È consigliabile introdurre un breve ritardo casuale prima di riprovare per evitare di incontrare di nuovo lo stesso deadlock. Altre informazioni su come progettare la logica di ripetizione dei tentativi per errori temporanei.
Livello di isolamento predefinito di database SQL di Azure
Nei nuovi database di Azure SQL, lo snapshot Read Committed (RCSI) è abilitato per impostazione predefinita. RCSI modifica il comportamento del livello di isolamento read committed per utilizzare la gestione delle versioni delle righe , al fine di fornire coerenza a livello di istruzione senza utilizzare blocchi condivisi (S) per le istruzioni SELECT.
Con RCSI abilitato:
- Le istruzioni che leggono i dati non bloccano le istruzioni che modificano i dati.
- Le istruzioni che modificano i dati non bloccano le istruzioni che leggono i dati.
Il livello di isolamento dello snapshot è abilitato per impostazione predefinita anche per i nuovi database in database SQL di Azure. L'isolamento dello snapshot è un livello di isolamento aggiuntivo basato su righe che garantisce coerenza a livello di transazione per i dati e che usa le versioni delle righe per selezionare le righe da aggiornare. Per usare l'isolamento dello snapshot, le query o le connessioni devono impostare in modo esplicito il livello di isolamento della transazione su SNAPSHOT. Questa operazione può essere eseguita solo quando l'isolamento dello snapshot è abilitato per il database.
È possibile identificare se l'isolamento RCSI e/o dello snapshot è abilitato con Transact-SQL. Connetti al database SQL di Azure e esegui la query seguente.
SELECT name,
is_read_committed_snapshot_on,
snapshot_isolation_state_desc
FROM sys.databases
WHERE name = DB_NAME();
GO
Se RCSI è abilitato, la colonna is_read_committed_snapshot_on restituisce il valore 1. Se l'isolamento dello snapshot è abilitato, la colonna snapshot_isolation_state_desc restituisce il valore ON.
Se RCSI è disabilitato per un database nel database SQL di Azure, esaminare il motivo per cui RCSI è stato disabilitato prima di riabilitarlo. Il codice dell'applicazione potrebbe prevedere che le query che leggono i dati verranno bloccate dalle query che scrivono dati, generando risultati non corretti da race condition quando rcSI è abilitato.
Interpretare gli eventi deadlock
Un evento di deadlock viene generato dopo che il gestore di deadlock in database SQL di Azure rileva un deadlock e seleziona una transazione come vittima. In altre parole, se si configurano avvisi per deadlock, la notifica viene attivata dopo la risoluzione di un singolo deadlock. Non è necessario eseguire alcuna azione dell'utente per tale deadlock. Le applicazioni devono essere scritte per includere logica di ripetizione dei tentativi in modo che continuino automaticamente dopo la ricezione dell'errore 1205: Transaction (Process ID <N>) was deadlocked on lock resources with another process and has been chosen as the deadlock victim. Rerun the transaction.
È utile configurare gli avvisi, tuttavia, perché i deadlock possono verificarsi di nuovo. Gli avvisi di deadlock consentono di analizzare se si verifica un modello di deadlock ripetuti nel database, nel qual caso è possibile scegliere di intervenire per impedire la ricorsione dei deadlock. Altre informazioni sull'invio di avvisi nella sezione Monitoraggio e avvisi per i deadlock di questo articolo.
Metodi principali per evitare i deadlock
L'approccio a rischio più basso per impedire la ripetizione dei deadlock consiste in genere nell'ottimizzazione degli indici non cluster per ottimizzare le query coinvolte nel deadlock.
Il rischio per questo approccio è basso perché l'ottimizzazione degli indici non cluster non richiede modifiche al codice di query stesso, riducendo il rischio di un errore dell'utente durante la riscrittura di Transact-SQL che causa la restituzione di dati non corretti all'utente.
L'ottimizzazione efficace degli indici non cluster consente alle query di trovare in modo più efficiente i dati da leggere e modificare. Riducendo la quantità di dati a cui una query deve accedere, la probabilità di bloccaggio viene ridotta e spesso è possibile evitare i deadlock.
In alcuni casi, la creazione o l'ottimizzazione di un indice cluster può ridurre il bloccaggio e i deadlock. Poiché l'indice cluster è incluso in tutte le definizioni di indice non cluster, la creazione o la modifica di un indice cluster può essere un'operazione intensa a livello di I/O e dispendiosa in termini di tempo su tabelle di dimensioni maggiori con indici non cluster esistenti. Altre informazioni sulle linee guida per la progettazione di indici cluster.
Quando l'ottimizzazione dell'indice non riesce a prevenire i deadlock, ci sono altri metodi disponibili:
Se il deadlock si verifica solo quando viene scelto un piano specifico per una delle query coinvolte nel deadlock, forzare un piano di query con Query Store potrebbe impedire la ricorsione dei deadlock.
Anche la riscrittura di Transact-SQL per una o più transazioni coinvolte nel deadlock può aiutare a evitare i deadlock. Suddividere le transazioni esplicite in transazioni più piccole richiede un'attenta codifica e test per assicurare la validità dei dati quando si verificano modifiche simultanee.
Altre informazioni su ognuno di questi approcci nella sezione Impedire la ripetizione di un deadlock di questo articolo.
Monitoraggio e avvisi per i deadlock
In questo articolo viene usato il database di esempio AdventureWorksLT per configurare gli avvisi per i deadlock, causare un deadlock di esempio, analizzare il grafico dei deadlock per l'esempio di deadlock e testare le modifiche per impedire la ricorsione del deadlock.
In questo articolo viene usato il client SQL Server Management Studio (SSMS), perché contiene funzionalità per visualizzare grafici deadlock in modalità visiva interattiva. È possibile usare altri client, ad esempio l'estensione MSSQL per Visual Studio Code, sqlcmd o lo strumento di query preferito Transact-SQL per seguire gli esempi, ma potrebbe essere possibile visualizzare solo i grafici deadlock come XML.
Creare il database AdventureWorksLT
Per seguire gli esempi, creare un nuovo database in database SQL di Azure e selezionare Dati di esempio come Origine dati.
Per istruzioni dettagliate su come creare AdventureWorksLT con il portale di Azure, l'interfaccia della riga di comando di Azure o PowerShell, selezionare l'approccio preferito in Avvio rapido: Creare un database singolo nel database SQL di Azure.
Configurare gli avvisi di deadlock nel portale di Azure
Per configurare gli avvisi per gli eventi di deadlock, seguire la procedura descritta nell'articolo Creare avvisi per il database SQL di Azure e Azure Synapse Analytics usando il portale di Azure.
Selezionare Deadlocks come nome del segnale per l'avviso. Configurare il Gruppo di azioni in modo che invii una notifica usando il metodo scelto, ad esempio il tipo di azione Email/SMS/Push/Voce.
Raccogliere grafici dei deadlock nei database SQL di Azure con Eventi Estesi
I grafici dei deadlock sono un'ampia fonte di informazioni relative ai processi e ai blocchi coinvolti in un deadlock. Per raccogliere grafici di deadlock con eventi estesi (XEvent) nel database SQL di Azure e nel database SQL di Fabric, acquisire l'evento sqlserver.database_xml_deadlock_report.
È possibile raccogliere grafici dei deadlock con XEvent usando la destinazione del buffer circolare o una destinazione file di eventi. Le considerazioni per la selezione del tipo di destinazione appropriato sono riepilogate nella seguente tabella:
| Approccio | Vantaggi | Considerazioni | Scenari di utilizzo |
|---|---|---|---|
| Destinazione del buffer circolare | - Configurazione semplice solo con Transact-SQL. | - I dati degli eventi vengono cancellati quando la sessione XEvents viene arrestata per qualsiasi motivo, ad esempio l'esecuzione offline del database o un failover del database. - Le risorse del database vengono usate per gestire i dati nel buffer circolare e per eseguire query sui dati della sessione. |
- Raccogliere dati di traccia di esempio per i test e l'apprendimento. - Creare per esigenze a breve termine se non è possibile configurare una sessione usando immediatamente una destinazione del file di eventi. - Usare come punto di atterraggio per i dati di traccia, quando è stato configurato un processo automatizzato per memorizzare permanentemente i dati di traccia in una tabella. |
| Destinazione file di eventi | - Rende persistenti i dati degli eventi in un BLOB in Archiviazione di Azure in modo che i dati siano disponibili anche dopo l'arresto della sessione. - I file di eventi possono essere scaricati dal portale di Azure o Azure Storage Explorer e analizzati in locale, che non richiede l'uso delle risorse di database per eseguire query sui dati della sessione. |
- Il programma di installazione è più complesso e richiede la configurazione di un contenitore di Archiviazione di Azure e di credenziali con ambito database. | - Utilizzo generale quando si desidera rendere persistenti i dati dell'evento anche dopo l'arresto della sessione eventi. - Si vuole eseguire una traccia che genera grandi quantità di dati dell'evento rispetto a quanto si vuole rendere persistente in memoria. |
Selezionare il tipo di destinazione da usare:
La destinazione del buffer circolare è comoda e facile da configurare, ma ha una capacità limitata, e questo può portare alla perdita di eventi meno recenti. Il buffer circolare non rende persistenti gli eventi nell'archiviazione e la destinazione del buffer circolare viene cancellata quando la sessione XEvents viene arrestata. Ciò significa che tutti gli eventi XEvent raccolti non sono disponibili quando il motore di database viene riavviato per qualsiasi motivo, ad esempio un failover. La destinazione del buffer circolare è più adatta all'apprendimento e alle esigenze a breve termine se non si ha la possibilità di configurare immediatamente una sessione XEvents su una destinazione del file di eventi.
Questo codice di esempio crea una sessione XEvents che acquisisce grafici dei deadlock in memoria usando la destinazione del buffer circolare. La memoria massima consentita per la destinazione del buffer circolare è di 4 MB e la sessione viene eseguita automaticamente quando il database viene online, ad esempio dopo un failover.
Per creare e quindi avviare una sessione XEvents per l'evento sqlserver.database_xml_deadlock_report che scrive nella destinazione del buffer circolare, connettersi al database ed eseguire il seguente codice Transact-SQL:
CREATE EVENT SESSION [deadlocks] ON DATABASE
ADD EVENT sqlserver.database_xml_deadlock_report
ADD TARGET package0.ring_buffer
WITH
(
STARTUP_STATE = ON,
MAX_MEMORY = 4 MB
);
GO
ALTER EVENT SESSION [deadlocks] ON DATABASE
STATE = START;
GO
Causa un deadlock
Poiché il blocco ottimizzato è sempre abilitato nel database SQL di Azure e nel database SQL di Fabric, i deadlock sono meno probabili. Per altre informazioni e per un esempio di deadlock che può verificarsi con il blocco ottimizzato, vedere Locking ottimizzato e deadlock.
Visualizzare grafici dei deadlock da una sessione di XEvents
Se si configura una sessione XEvents per raccogliere deadlock e si verifica un deadlock dopo l'avvio della sessione, è possibile visualizzare un display grafico interattivo del grafo deadlock e del codice XML per il grafo deadlock.
Sono disponibili vari metodi per ottenere informazioni sui deadlock per la destinazione del buffer circolare e la destinazione del file di eventi. Selezionare la destinazione usata per la sessione di XEvents:
Se si configura una sessione di XEvents che scrive nel buffer circolare, è possibile eseguire query sulle informazioni dei deadlock con il codice Transact-SQL seguente. Prima di eseguire la query, sostituire il valore di @tracename con il nome della sessione XEvents.
DECLARE @tracename AS sysname = N'deadlocks';
WITH ring_buffer
AS (SELECT CAST (target_data AS XML) AS rb
FROM sys.dm_xe_database_sessions AS s
INNER JOIN sys.dm_xe_database_session_targets AS t
ON CAST (t.event_session_address AS BINARY (8)) = CAST (s.address AS BINARY (8))
WHERE s.name = @tracename
AND t.target_name = N'ring_buffer'),
dx
AS (SELECT dxdr.evtdata.query('.') AS deadlock_xml_deadlock_report
FROM ring_buffer
CROSS APPLY rb.nodes('/RingBufferTarget/event[@name=''database_xml_deadlock_report'']') AS dxdr(evtdata))
SELECT d.query('/event/data[@name=''deadlock_cycle_id'']/value').value('(/value)[1]', 'int') AS [deadlock_cycle_id],
d.value('(/event/@timestamp)[1]', 'DateTime2') AS [deadlock_timestamp],
d.query('/event/data[@name=''database_name'']/value').value('(/value)[1]', 'nvarchar(256)') AS [database_name],
d.query('/event/data[@name=''xml_report'']/value/deadlock') AS deadlock_xml,
LTRIM(RTRIM(REPLACE(REPLACE(d.value('.', 'nvarchar(2000)'), CHAR(10), ' '), CHAR(13), ' '))) AS query_text
FROM dx
CROSS APPLY deadlock_xml_deadlock_report.nodes('(/event/data/value/deadlock/process-list/process/inputbuf)') AS ib(d)
ORDER BY [deadlock_timestamp] DESC;
GO
Visualizzare e salvare un grafico di deadlock in XML
La visualizzazione di un grafico di deadlock in formato XML consente di copiare il inputbuffer delle istruzioni Transact-SQL coinvolte nel deadlock. È anche possibile analizzare i deadlock in un formato basato su testo.
Se è stata usata una query Transact-SQL per restituire informazioni sul grafico di deadlock, per visualizzare il codice XML del grafico di deadlock, selezionare il valore nella colonna deadlock_xml da qualsiasi riga per aprire il codice XML del grafico di deadlock in una nuova finestra di SSMS.
Il codice XML per questo grafico di deadlock di esempio è:
<deadlock>
<victim-list>
<victimProcess id="process24756e75088" />
</victim-list>
<process-list>
<process id="process24756e75088" taskpriority="0" logused="6528" waitresource="KEY: 8:72057594045202432 (98ec012aa510)" waittime="192" ownerId="1011123" transactionname="user_transaction" lasttranstarted="2022-03-08T15:44:43.490" XDES="0x2475c980428" lockMode="U" schedulerid="3" kpid="30192" status="suspended" spid="89" sbid="0" ecid="0" priority="0" trancount="2" lastbatchstarted="2022-03-08T15:44:49.250" lastbatchcompleted="2022-03-08T15:44:49.210" lastattention="1900-01-01T00:00:00.210" clientapp="Microsoft SQL Server Management Studio - Query" hostname="LAPTOP-CHRISQ" hostpid="16716" loginname="chrisqpublic" isolationlevel="read committed (2)" xactid="1011123" currentdb="8" currentdbname="AdventureWorksLT" lockTimeout="4294967295" clientoption1="671096864" clientoption2="128056">
<executionStack>
<frame procname="unknown" queryhash="0xef52b103e8b9b8ca" queryplanhash="0x02b0f58d7730f798" line="1" stmtstart="2" stmtend="792" sqlhandle="0x02000000c58b8f1e24e8f104a930776e21254b1771f92a520000000000000000000000000000000000000000">
unknown </frame>
</executionStack>
<inputbuf>
UPDATE SalesLT.ProductDescription SET Description = Description
FROM SalesLT.ProductDescription as pd
JOIN SalesLT.ProductModelProductDescription as pmpd on
pd.ProductDescriptionID = pmpd.ProductDescriptionID
JOIN SalesLT.ProductModel as pm on
pmpd.ProductModelID = pm.ProductModelID
JOIN SalesLT.Product as p on
pm.ProductModelID=p.ProductModelID
WHERE p.Color = 'Red' </inputbuf>
</process>
<process id="process2476d07d088" taskpriority="0" logused="11360" waitresource="KEY: 8:72057594045267968 (39e18040972e)" waittime="2641" ownerId="1013536" transactionname="UPDATE" lasttranstarted="2022-03-08T15:44:46.807" XDES="0x2475ca80428" lockMode="S" schedulerid="2" kpid="94040" status="suspended" spid="95" sbid="0" ecid="0" priority="0" trancount="2" lastbatchstarted="2022-03-08T15:44:46.807" lastbatchcompleted="2022-03-08T15:44:46.760" lastattention="1900-01-01T00:00:00.760" clientapp="Microsoft SQL Server Management Studio - Query" hostname="LAPTOP-CHRISQ" hostpid="16716" loginname="chrisqpublic" isolationlevel="read committed (2)" xactid="1013536" currentdb="8" currentdbname="AdventureWorksLT" lockTimeout="4294967295" clientoption1="671088672" clientoption2="128056">
<executionStack>
<frame procname="unknown" queryhash="0xef52b103e8b9b8ca" queryplanhash="0x02b0f58d7730f798" line="1" stmtstart="2" stmtend="798" sqlhandle="0x020000002c85bb06327c0852c0be840fc1e30efce2b7c8090000000000000000000000000000000000000000">
unknown </frame>
</executionStack>
<inputbuf>
UPDATE SalesLT.ProductDescription SET Description = Description
FROM SalesLT.ProductDescription as pd
JOIN SalesLT.ProductModelProductDescription as pmpd on
pd.ProductDescriptionID = pmpd.ProductDescriptionID
JOIN SalesLT.ProductModel as pm on
pmpd.ProductModelID = pm.ProductModelID
JOIN SalesLT.Product as p on
pm.ProductModelID=p.ProductModelID
WHERE p.Color = 'Silver'; </inputbuf>
</process>
</process-list>
<resource-list>
<keylock hobtid="72057594045202432" dbid="8" objectname="9e011567-2446-4213-9617-bad2624ccc30.SalesLT.ProductDescription" indexname="PK_ProductDescription_ProductDescriptionID" id="lock2474df12080" mode="U" associatedObjectId="72057594045202432">
<owner-list>
<owner id="process2476d07d088" mode="U" />
</owner-list>
<waiter-list>
<waiter id="process24756e75088" mode="U" requestType="wait" />
</waiter-list>
</keylock>
<keylock hobtid="72057594045267968" dbid="8" objectname="9e011567-2446-4213-9617-bad2624ccc30.SalesLT.Product" indexname="PK_Product_ProductID" id="lock2474b588580" mode="X" associatedObjectId="72057594045267968">
<owner-list>
<owner id="process24756e75088" mode="X" />
</owner-list>
<waiter-list>
<waiter id="process2476d07d088" mode="S" requestType="wait" />
</waiter-list>
</keylock>
</resource-list>
</deadlock>
Per salvare il grafico di deadlock come file XML:
- Selezionare File, quindi Salva come....
- Lasciare il valore Tipo file come da impostazione predefinita File XML (*.xml)
- Impostare il Nome file su un nome a scelta.
- Seleziona Salva.
Salvare un grafico di deadlock come file XDL che può essere visualizzato in modo interattivo in SSMS
La visualizzazione di una rappresentazione interattiva di un grafico di deadlock può essere utile per ottenere una rapida panoramica dei processi e delle risorse coinvolti in un deadlock e identificare rapidamente la vittima del deadlock.
Per salvare un grafico di deadlock come file che può essere visualizzato graficamente da SSMS:
Selezionare il valore nella colonna
deadlock_xmlda qualsiasi riga per aprire il file XML del grafico di deadlock in una nuova finestra in SSMS.Selezionare File, quindi Salva come....
Impostare Salva come tipo su Tutti i file.
Imposta il Nome file come desiderato, con l'estensione impostata su
.xdl.Seleziona Salva.

Chiudere il file selezionando la X nella scheda nella parte superiore della finestra, oppure selezionando File e quindi Chiudi.
Riaprire il file in SSMS selezionando File, quindi Apri e poi File. Selezionare il file salvato con l'estensione
.xdl.Il grafico deadlock ora viene visualizzato in SSMS con una rappresentazione visiva dei processi e delle risorse coinvolti nel deadlock.



Analizzare un deadlock per il database SQL di Azure
Un grafico di deadlock ha in genere tre nodi:
Victim-list. Identificatore di processo della vittima del deadlock.
Elenco dei processi. Informazioni su tutti i processi coinvolti nel deadlock. I grafici di deadlock usano il termine "processo" per rappresentare una sessione che esegue una transazione.
Resource-list. Informazioni sulle risorse coinvolte nel deadlock.
Quando si analizza un deadlock, è utile esaminare questi nodi.
Elenco delle vittime del deadlock
L'elenco delle vittime del deadlock indica il processo che è stato scelto come vittima del deadlock. Nella rappresentazione visiva di un grafico di deadlock, i processi sono rappresentati da ovali. Il processo coinvolto nel deadlock ha una "X" disegnata sull'ovale.

Nella visualizzazione XML di un grafico di deadlock il nodo victim-list fornisce un ID per il processo vittima del deadlock.
Nell'esempio di stallo, l'ID della vittima del processo è process24756e75088. È possibile usare questo ID quando si esaminano i nodi elenco processi e elenco risorse per ottenere maggiori informazioni sul processo vittima e sulle risorse che stava bloccando o che stava cercando di bloccare.
Elenco dei processi di deadlock
L'elenco dei processi di deadlock è un'ampia fonte di informazioni sulle transazioni coinvolte nel deadlock.
La rappresentazione grafica del grafico di deadlock mostra solo un sottoinsieme di informazioni contenute nel file XML del grafico di deadlock. Gli ovali nel grafico di deadlock rappresentano il processo e mostrano informazioni tra cui:
ID di sessione, noto anche come SPID.
Priorità di stallo della sessione. Se le priorità di deadlock di due sessioni sono diverse, come vittima del deadlock verrà scelta la sessione con la priorità inferiore. Nell'esempio, entrambe le sessioni hanno la medesima priorità di deadlock.
Quantità di log delle transazioni usata dalla sessione in byte. Se entrambe le sessioni hanno la stessa priorità di deadlock, il monitoraggio dei deadlock sceglie come vittima del deadlock la sessione per cui risulta meno oneroso eseguire il rollback. Il costo viene determinato confrontando il numero di byte di log scritti in quel punto in ogni transazione.
Nel deadlock di esempio,
session_id89 aveva usato una quantità inferiore di log delle transazioni ed è stata selezionata come vittima del deadlock.
Inoltre, è possibile visualizzare il buffer di input per l'ultima esecuzione dell'istruzione in ogni sessione prima del deadlock passando il mouse su ogni processo. Il buffer di input viene visualizzato in un tooltip.

Sono disponibili informazioni aggiuntive per i processi nella visualizzazione XML del grafico di deadlock, tra cui:
Informazioni di identificazione per la sessione, come ad esempio il nome client, il nome host e il nome di accesso.
Hash del piano di interrogazione per l'ultima istruzione eseguita da ogni sessione prima del deadlock. L'hash del piano di query è utile per ottenere informazioni più dettagliate sulla query da Query Store.
Nel nostro esempio di stallo:
È possibile notare che entrambe le sessioni sono state eseguite usando il client SSMS nell'account di accesso
chrisqpublic.L'hash del piano di query, dell'ultima istruzione eseguita prima del deadlock da parte della vittima del deadlock, è
0x02b0f58d7730f798. È possibile visualizzare il testo dell'istruzione nel buffer di input.Anche l'hash del piano di query dell'ultima istruzione eseguita dalla sessione opposta nel nostro deadlock è
0x02b0f58d7730f798. È possibile visualizzare il testo dell'istruzione nel buffer di input. In questo caso, entrambe le query hanno lo stesso hash del piano di query perché le query sono identiche ad eccezione di un valore letterale usato come predicato di uguaglianza.
Questi valori vengono usati più avanti in questo articolo per trovare informazioni aggiuntive in Query Store.
Limitazioni del buffer di input nell'elenco dei processi di deadlock
Esistono alcune limitazioni da tenere presenti riguardo alle informazioni sul buffer di input nell'elenco dei processi di deadlock.
Il testo della query potrebbe essere troncato nel buffer di input. Il buffer di input è limitato ai primi 4.000 caratteri dell'istruzione in esecuzione.
Inoltre, alcune istruzioni coinvolte nel deadlock potrebbero non essere incluse nel grafico di stallo. In questo esempio, la sessione A ha eseguito due istruzioni di aggiornamento all'interno di una singola transazione. Solo la seconda istruzione di aggiornamento, l'aggiornamento che ha causato il deadlock, è inclusa nel grafico di deadlock. La prima istruzione di aggiornamento eseguita da Sessione A ha avuto un ruolo nel deadlock bloccando Sessione B. Il buffer di input, query_hashe le informazioni correlate per la prima istruzione eseguita da sessione A non sono incluse nel grafico deadlock.
Per identificare il Transact-SQL completo eseguito in una transazione con più istruzioni coinvolte in un deadlock, è necessario trovare le informazioni pertinenti nella stored procedure o nel codice dell'applicazione che ha eseguito la query oppure eseguire una traccia usando Eventi Estesi per acquisire le istruzioni complete eseguite da sessioni coinvolte in un deadlock al momento in cui si verifica. Se un'istruzione coinvolta nel deadlock viene troncata e nel buffer di input viene visualizzata solo una Transact-SQL parziale, è possibile trovare il Transact-SQL per l'istruzione in Query Store con il piano di esecuzione.
Elenco delle risorse del deadlock
L'elenco delle risorse del deadlock mostra quali risorse bloccate sono di proprietà e attese dai processi nel deadlock.
Le risorse, nella rappresentazione visiva del deadlock, sono rappresentate da rettangoli:

Nota
I nomi dei database sono rappresentati come GUID (uniqueidentifier) nei grafici dei deadlock per i database nel database SQL di Azure e nel database SQL in Fabric. Si tratta dell'oggetto physical_database_name per il database elencato nelle viste di gestione dinamica sys.databases e sys.dm_user_db_resource_governance.
Nel deadlock di questo esempio:
La vittima del deadlock, che è stata chiamata sessione A:
Possiede un blocco esclusivo (X) su una chiave dell'indice
PK_Product_ProductIDnella tabellaSalesLT.Product.Richiede un blocco di aggiornamento (U) per una chiave nell'indice
PK_ProductDescription_ProductDescriptionIDdella tabellaSalesLT.ProductDescription.
L'altro processo, che è stato chiamato sessione B:
Possiede un blocco di aggiornamento (U) su una chiave nell'indice
PK_ProductDescription_ProductDescriptionIDdella tabellaSalesLT.ProductDescription.Richiede un blocco condiviso (S) su una chiave nell'indice
PK_ProductDescription_ProductDescriptionIDdella tabellaSalesLT.ProductDescription.
È possibile visualizzare le stesse informazioni nel codice XML del grafico di deadlock nel nodo resource-list.
Trovare i piani di esecuzione di query in Query Store
Spesso è utile esaminare i piani di esecuzione delle query per le dichiarazioni coinvolte nel deadlock. Questi piani di esecuzione sono spesso disponibili in Query Store usando l'hash del piano di query dalla visualizzazione XML dell'elenco processi del grafico di deadlock.
Questa query Transact-SQL ricerca piani di query che corrispondono all'hash del piano di query che abbiamo trovato per il nostro esempio di deadlock. Collegarsi al database utente del database SQL di Azure per eseguire la query.
DECLARE @query_plan_hash AS BINARY (8) = 0x02b0f58d7730f798;
SELECT qrsi.end_time AS interval_end_time,
qs.query_id,
qp.plan_id,
qt.query_sql_text,
TRY_CAST (qp.query_plan AS XML) AS query_plan,
qrs.count_executions
FROM sys.query_store_query AS qs
INNER JOIN sys.query_store_query_text AS qt
ON qs.query_text_id = qt.query_text_id
INNER JOIN sys.query_store_plan AS qp
ON qs.query_id = qp.query_id
INNER JOIN sys.query_store_runtime_stats AS qrs
ON qp.plan_id = qrs.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS qrsi
ON qrs.runtime_stats_interval_id = qrsi.runtime_stats_interval_id
WHERE query_plan_hash = @query_plan_hash
ORDER BY interval_end_time, query_id;
GO
Potrebbe non essere possibile ottenere un piano di esecuzione di query da Query Store, a seconda delle impostazioni di Query Store CLEANUP_POLICY o di QUERY_CAPTURE_MODE. In questo caso, è spesso possibile ottenere informazioni necessarie visualizzando il piano di esecuzione stimato per la query.
Cercare schemi che aumentano il bloccaggio
Quando si esaminano i piani di esecuzione delle query coinvolti in deadlock, cercare modelli che possono contribuire a blocchi e deadlock.
Analisi di tabelle o indici. Quando le query che modificano i dati vengono eseguite in RCSI, la selezione delle righe da aggiornare viene eseguita usando un'analisi di bloccaggio in cui viene eseguito un blocco di aggiornamento (U) sulla riga di dati man mano che vengono letti i valori dei dati. Se la riga di dati non soddisfa i criteri di aggiornamento, il blocco di aggiornamento viene rilasciato e la riga successiva viene bloccata e analizzata.
L'ottimizzazione degli indici per consentire alle query di modifica di trovare le righe più efficientemente riduce il numero di blocchi di aggiornamento emessi. Questo riduce le probabilità di bloccaggio e di deadlock.
Viste indicizzate che fanno riferimento a più tabelle. Quando si modifica una tabella a cui si fa riferimento in una vista indicizzata, il motore di database deve mantenere anche la vista indicizzata. Questo richiede l'utilizzo di più lock e può comportare un aumento del blocco e dei deadlock. Le viste indicizzate possono anche causare che le operazioni di aggiornamento vengano eseguite internamente al livello di isolamento di lettura confermata.
Modifiche alle colonne a cui si fa riferimento nei vincoli di chiave esterna. Quando si modificano colonne in una tabella a cui viene fatto riferimento in un vincolo
FOREIGN KEY, il motore di database deve cercare le righe correlate nella tabella di riferimento. Le versioni di riga non possono essere utilizzate per queste letture. Nei casi in cui gli aggiornamenti o le eliminazioni a catena sono abilitati, il livello di isolamento potrebbe essere elevato a serializzabile per la durata del comando per la protezione da inserimenti fantasma.Indicazioni di blocco. Cercare hint di tabella che specificano i livelli di isolamento che richiedono più blocchi. Questi hint includono
HOLDLOCK(che è equivalente a serializzabile),SERIALIZABLE,READCOMMITTEDLOCK(che disabilita RCSI) eREPEATABLEREAD. Inoltre, gli hint comePAGLOCK,TABLOCK,UPDLOCKeXLOCKpossono aumentare i rischi di bloccaggio e deadlock.Se questi hint sono presenti, cercare il motivo per cui sono stati implementati. Questi suggerimenti possono prevenire le condizioni di gara e garantire la validità dei dati. Potrebbe essere possibile lasciare questi suggerimenti e impedire future deadlock usando un metodo alternativo nella sezione Impedire che un deadlock si ripeta di questo articolo, se necessario.
Nota
Scopri di più sul comportamento usando il controllo delle versioni delle righe durante la modifica dei dati nella Guida per il controllo delle versioni delle righe e il blocco delle transazioni.
Quando si esamina il codice completo di una transazione, sia in un piano di esecuzione che nel codice di query dell'applicazione, cercare eventuali schemi problematici aggiuntivi.
Interazione dell'utente nelle transazioni. L'interazione dell'utente in una transazione esplicita con più istruzioni aumenta significativamente la durata delle transazioni. Questo rende più probabile che tali transazioni si sovrappongano e che si verifichino bloccaggi e deadlock.
Analogamente, mantenere una transazione aperta ed eseguire query su un database o un sistema non correlati durante la transazione aumenta significativamente le probabilità di bloccaggio e deadlock.
Transazioni che accedono a oggetti in ordini diversi. È meno probabile che si verifichino deadlock quando transazioni simultanee, esplicite e con più istruzioni seguono gli stessi schemi e gli stessi oggetti di accesso nello stesso ordine.
Impedire la ripetizione di un deadlock
Sono disponibili più tecniche per impedire la ripetizione dei deadlock, come l'ottimizzazione degli indici, l'imposizione di piani con Query Store e la modifica delle query Transact-SQL.
Esaminare l'indice cluster della tabella. La maggior parte delle tabelle trae vantaggio dagli indici cluster, ma le tabelle spesso vengono implementate come heap per errore.
Un modo per verificare la presenza di un indice cluster consiste nell'usare la stored procedure di sistema sp_helpindex. Ad esempio, è possibile visualizzare un riepilogo degli indici nella tabella
SalesLT.Producteseguendo l'istruzione seguente:EXECUTE sp_helpindex 'SalesLT.Product'; GOEsaminare la colonna
index_description. Una tabella può avere un solo indice cluster. Se è stato implementato un indice cluster per la tabella, ilindex_descriptioncontiene la parolaclustered.Se non è presente un indice cluster, la tabella è un heap. In tal caso, verificare se la tabella è stata creata intenzionalmente come heap per risolvere un problema specifico di prestazioni. Prendere in considerazione l'implementazione di un indice cluster in base alle linee guida per la progettazione di indici cluster.
In alcuni casi, la creazione o l'ottimizzazione di un indice cluster può ridurre o eliminare il blocco nei deadlock. In altri casi, è possibile usare una tecnica aggiuntiva, ad esempio le altre in questo elenco.
Creare o modificare indici non clusterizzati. L'ottimizzazione degli indici non cluster consente alle query di modifica di trovare i dati da aggiornare in modo più rapido, riducendo così il numero di blocchi di aggiornamento necessari.
Nel deadlock di esempio, il piano di esecuzione della query trovato in Query Store contiene una scansione dell'indice clusterizzato sull'indice
PK_Product_ProductID. Il grafico di deadlock indica che l'attesa di un blocco condiviso (S) per questo indice è un componente nel deadlock.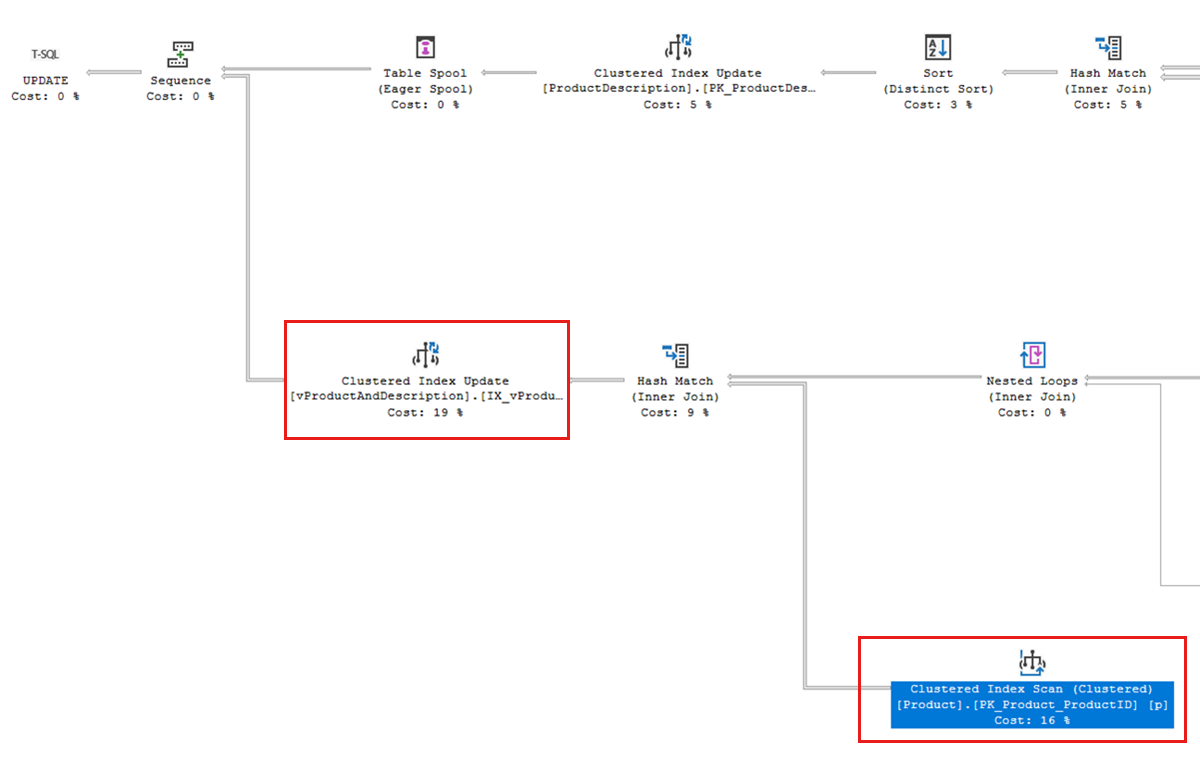
Questa analisi dell'indice viene eseguita perché la query di aggiornamento deve modificare una vista indicizzata con nome
vProductAndDescription. Come accennato nella sezione "Cerca modelli che aumentano il blocco" di questo articolo, le viste indicizzate che fanno riferimento a più tabelle potrebbero aumentare il blocco e la probabilità di deadlock.Se si crea l'indice non cluster seguente nel database
AdventureWorksLTche "copre" le colonne daSalesLT.Producta cui fa riferimento la vista indicizzata, questo consente alla query di trovare le righe in modo molto più efficiente:CREATE INDEX IX_Product_ProductID_Name_ProductModelID ON SalesLT.Product(ProductID, Name, ProductModelID); GODopo aver creato questo indice, il deadlock non si ripete più.
Quando i deadlock comportano modifiche alle colonne a cui si fa riferimento in vincoli di chiave esterna, assicurarsi che gli indici nella tabella di riferimento del
FOREIGN KEYsupportino in modo efficiente la ricerca di righe correlate.Anche se gli indici possono migliorare notevolmente le prestazioni delle query in alcuni casi, gli indici hanno anche costi generali e di gestione. Esaminare lelinee guida generali per la progettazione degli indici per valutare il vantaggio degli indici prima di crearli, in particolare per quanto riguarda indici estesi e indici su grandi tabelle.
Valutare il valore delle viste indicizzate. Un'altra opzione per impedire la ripetizione del deadlock di esempio consiste nell'escludere la vista indicizzata
SalesLT.vProductAndDescription. Se la vista indicizzata non viene usata, questo riduce il sovraccarico di gestione della vista indicizzata nel tempo.Usare l'isolamento dello snapshot. In alcuni casi, l'impostazione del livello di isolamento delle transazioni su snapshot per una o più delle transazioni coinvolte in deadlock potrebbe impedire il ripetersi di blocchi e deadlock.
È molto probabile che questa tecnica abbia esito positivo quando viene utilizzata nelle istruzioni
SELECTe la lettura confermata dello snapshot è disabilitata in un database. Quando lo snapshot "read committed" è disabilitato, le querySELECTche utilizzano il livello di isolamento "read committed" richiedono blocchi condivisi (S). L'uso dell'isolamento dello snapshot in queste transazioni elimina la necessità di blocchi condivisi, che possono impedire bloccaggi e deadlock.Nei database in cui è abilitato l'isolamento dello snapshot read committed, le query
SELECTnon richiedono blocchi condivisi (S), pertanto è probabile che si verifichino situazioni di stallo tra le transazioni che modificano i dati. Nei casi in cui si verificano deadlock tra più transazioni che modificano i dati, l'isolamento dello snapshot potrebbe comportare un conflitto di aggiornamento anziché un deadlock. In modo analogo, è necessario che una delle transazioni ritenti l'operazione.Forzare un piano tramite Query Store. Si potrebbe notare che una delle query nel deadlock include più piani di esecuzione e il deadlock si verifica solo quando viene usato un piano specifico. È possibile impedire la ripetizione del deadlock forzando un piano in Query Store.
Modificare il codice Transact-SQL. Potrebbe essere necessario modificare Transact-SQL per impedire la ricorsione del deadlock. La modifica del codice Transact-SQL deve essere eseguita con attenzione e le modifiche devono essere testate rigorosamente per assicurarsi che i dati siano corretti quando le modifiche vengono eseguite contemporaneamente. Quando si riscrive il codice Transact-SQL, prendere in considerazione:
Ordinare le istruzioni nelle transazioni in modo che accedano agli oggetti nello stesso ordine.
Quando possibile, suddividere le transazioni in transazioni più piccole.
Utilizzare suggerimenti per le query, se necessario, per ottimizzare le prestazioni. È possibile applicare hint senza modificare il codice applicazione tramite Query Store.

È possibile trovare altri modi per ridurre al minimo i deadlock nella Guida ai deadlock.
Nota
In alcuni casi, è possibile regolare la priorità del deadlock di una o più sessioni coinvolte in un deadlock se è importante che una delle sessioni venga completata correttamente senza riprovare o quando una delle query coinvolte nel deadlock non è critica e deve essere sempre scelta come vittima. Anche se ciò non impedisce la ripetizione del deadlock, potrebbe ridurre l'effetto dei deadlock futuri.
Escludere una sessione di XEvents
È possibile lasciare in esecuzione una sessione XEvents che raccoglie informazioni sui deadlock nei database critici durante lunghi periodi. Se si utilizza una destinazione di file di eventi, ciò potrebbe comportare file di grandi dimensioni se si verificano più deadlock. È possibile eliminare i file BLOB dall’archiviazione di Azure per una traccia attiva, ad eccezione del file che si sta scrivendo.
Quando si desidera rimuovere una sessione di XEvents, il codice Transact-SQL per l'esclusione della sessione è lo stesso, indipendentemente dal tipo di destinazione selezionato.
Per rimuovere una sessione di XEvents, eseguire il codice Transact-SQL seguente. Prima di eseguire il codice, sostituire il nome della sessione con il valore corretto.
ALTER EVENT SESSION [deadlocks] ON DATABASE
STATE = STOP;
GO
DROP EVENT SESSION [deadlocks] ON DATABASE;
GO
Usare Azure Storage Explorer
Azure Storage Explorer è un'applicazione autonoma che semplifica l'uso delle destinazioni file di eventi archiviate nei BLOB in Archiviazione di Azure. È possibile usare Azure Storage Explorer per:
Creare un contenitore BLOB per contenere i dati della sessione di XEvent.
Ottenere una firma di accesso condiviso (SAS) per il contenitore BLOB.
Come indicato in Raccogliere grafici di deadlock in database SQL di Azure con Eventi estesi, sono necessarie le autorizzazioni di lettura, scrittura ed elenco.
Rimuovere qualsiasi carattere iniziale
?daQuery stringper usare il valore come segreto durante la creazione di credenziali con ambito al database.
Visualizza e scarica i file di eventi estesi da un contenitore blob.
Scarica Azure Storage Explorer.
Contenuto correlato
- Comprendere e risolvere i problemi di blocco
- Guida al blocco delle transazioni e al controllo delle versioni delle righe
- Guida ai blocchi
- IMPOSTARE IL LIVELLO DI ISOLAMENTO DELLE TRANSAZIONI
- Database SQL di Azure: migliorare l'ottimizzazione delle prestazioni con l'ottimizzazione automatica
- Offrire prestazioni coerenti con Azure SQL
- logica di ripetizione dei tentativi per errori transitori