Configurare un gruppo di failover per il database SQL di Azure
Si applica a: ![]() Database SQL di Azure
Database SQL di Azure
Questo articolo mostra come configurare un gruppo di failover per database singoli e in pool nel database SQL di Azure usando il portale di Azure, Azure PowerShell e l'interfaccia della riga di comando di Azure.
Per gli script end-to-end, vedere come aggiungere un singolo database a un gruppo di failover con Azure PowerShell o con l'interfaccia della riga di comando di Azure.
Prerequisiti
Prendere in considerazione i prerequisiti seguenti per creare il gruppo di failover per un database singolo:
- Il database primario deve essere già stato creato. Creare un database singolo per iniziare.
- Se il server secondario è già presente in un'area diversa rispetto al server primario, le impostazioni del firewall e dell'account di accesso del server devono corrispondere a quelle del server primario.
Create failover group
È possibile creare il gruppo di failover e aggiungerci un singolo database usando il portale di Azure, PowerShell e l'interfaccia della riga di comando di Azure.
Importante
Se è necessario eliminare un database secondario dopo che è stato aggiunto a un gruppo di failover, rimuoverlo dal gruppo di failover prima di eliminare il database. L'eliminazione di un database secondario prima della rimozione dal gruppo di failover può causare comportamenti imprevisti.
Per creare il gruppo di failover e aggiungere il singolo database utilizzando il portale Azure, seguire i seguenti passaggi:
Se si conosce il server logico che ospita il database, passare direttamente al server nel portale di Azure. Se occorre trovare il server, seguire questa procedura:
- Selezionare Azure SQL nel menu di servizio. Se Azure SQL non è presente nell'elenco, selezionare Tutti i servizi e digitare
Azure SQLnella casella di ricerca. (Facoltativo) Selezionare la stella accanto ad Azure SQL per aggiungerlo ai Preferiti e come elemento nel menu di servizio. - Nella pagina SQL di Azure individuare il database da aggiungere al gruppo di failover e selezionarlo per aprire il riquadro del database SQL.
- Nel riquadro Panoramica del database SQL, selezionare il nome del server in Nome del server per aprire il riquadro SQL Server.

- Selezionare Azure SQL nel menu di servizio. Se Azure SQL non è presente nell'elenco, selezionare Tutti i servizi e digitare
Nel menu delle risorse del SQL Server selezionare Gruppi di failover in Gestione dei dati. Selezionare + Aggiungi gruppo per aprire la pagina Gruppi di failover in cui è possibile creare un nuovo gruppo di failover.
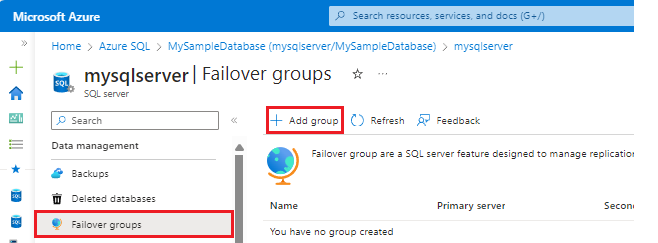
Nella pagina Gruppi di failover:
- Specificare un nome del gruppo di failover.
- Scegliere un server secondario esistente oppure creare un nuovo server selezionando Crea nuovo in Server. Il server secondario nel gruppo di failover deve trovarsi in un'area diversa rispetto al server primario.
- Selezionare Configura database per aprire la pagina Database per il gruppo di failover.
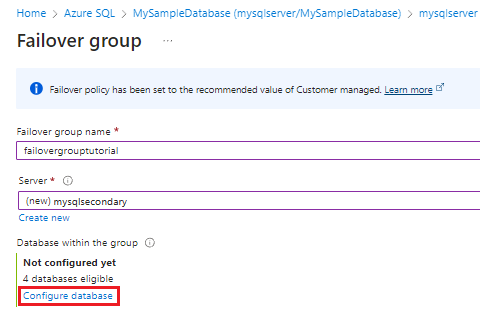
Nella pagina Database per il gruppo di failover:
- Scegliere i database che si desidera aggiungere al gruppo di failover (n. 1 nello screenshot).
- (Facoltativo) Scegliere Sì se si intende designare questi database come repliche di standby da usare solo per il ripristino di emergenza (n. 2 nello screenshot). Selezionare la casella per confermare che si userà la replica di standby.
- Usare Seleziona per salvare la selezione del database e tornare alla pagina Gruppi di failover (non visibile nello screenshot).
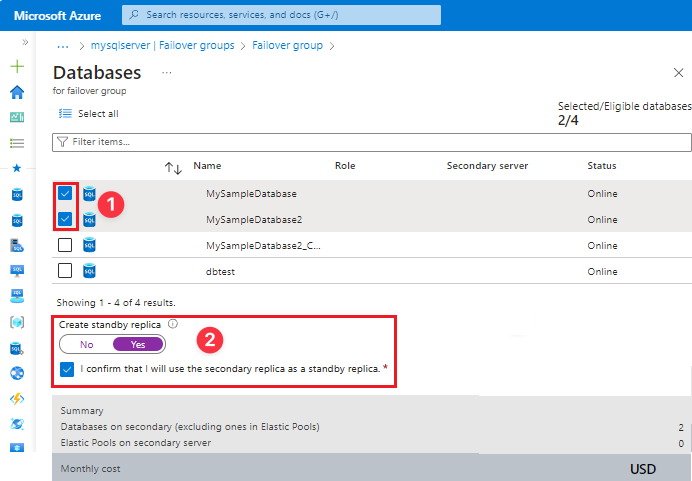
Utilizzare Crea nella pagina Gruppi di failover per creare il gruppo di failover.
Testare un failover pianificato
Testare un failover del gruppo di failover senza perdita di dati usando il portale di Azure o PowerShell.
Per verificare il failover del gruppo failover tramite il portale Azure, procedere come segue:
Se si conosce il server logico che ospita il database, passare direttamente al server nel portale di Azure. Se occorre trovare il server, seguire questa procedura:
- Selezionare Azure SQL nel menu di servizio. Se Azure SQL non è presente nell'elenco, selezionare Tutti i servizi e digitare
Azure SQLnella casella di ricerca. (Facoltativo) Selezionare la stella accanto ad Azure SQL per aggiungerlo ai Preferiti e come elemento nel menu di servizio. - Nella pagina Azure SQL individuare il database per testare il failover e selezionarlo per aprire il riquadro del database SQL.
- Nel riquadro Panoramica del database SQL, selezionare il nome del server in Nome del server per aprire il riquadro SQL Server.
- Selezionare Azure SQL nel menu di servizio. Se Azure SQL non è presente nell'elenco, selezionare Tutti i servizi e digitare
Nel menu delle risorse di SQL Server selezionare Gruppi di failover in Gestione dei dati e quindi scegliere un gruppo di failover esistente per aprire la pagina Gruppo di failover.
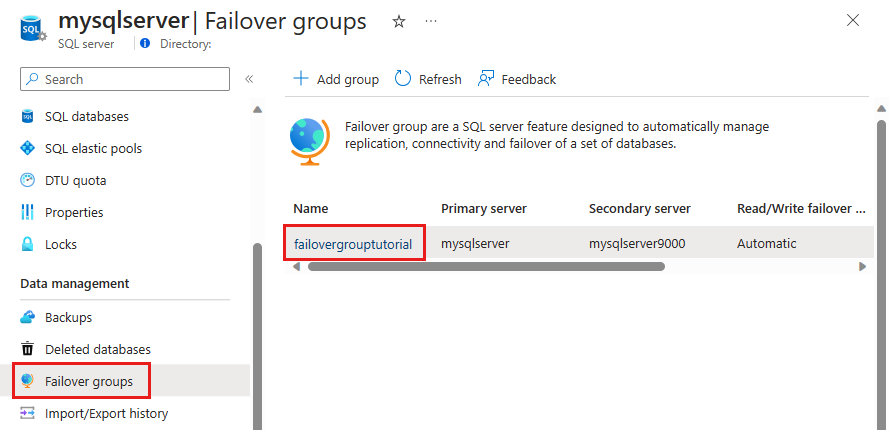
Nella pagina Gruppi di failover:
- Verificare qual è il server primario e quale quello secondario.
- Selezionare Failover nella barra dei comandi per eseguire il failover del gruppo di failover che contiene il database.
- Selezionare Sì nella finestra dell'avviso che informa che le sessioni TDS verranno disconnesse.
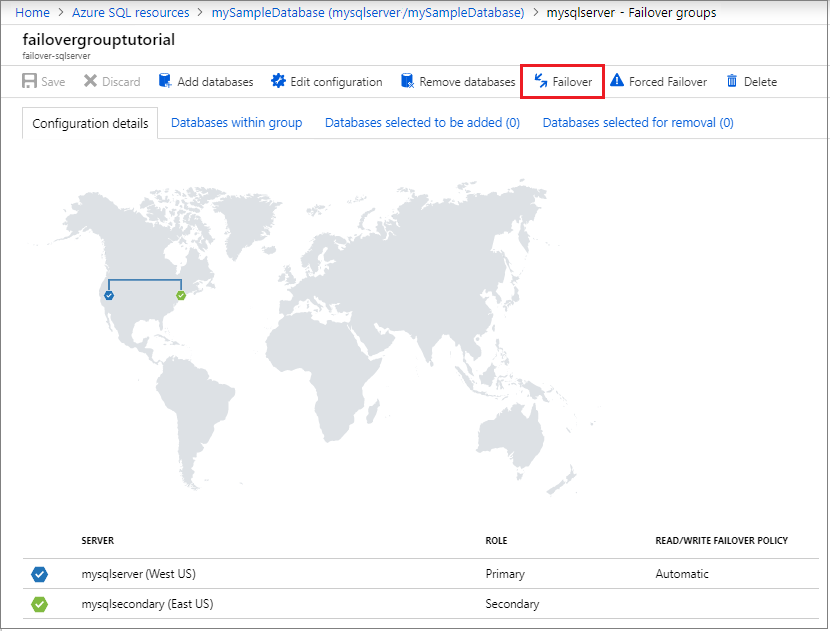
Verificare quale server è ora il server primario e quale quello secondario. Al termine del failover, i due server scambiano i ruoli, in modo che il precedente database primario diventi secondario.
(Facoltativo) Selezionare di nuovo Failover per ripristinare i ruoli originali dei server.
Per gli script end-to-end, vedere come aggiungere un pool elastico a un gruppo di failover con Azure PowerShell o l'interfaccia della riga di comando di Azure.
Prerequisiti
Prendere in considerazione i seguenti prerequisiti per la creazione del gruppo di failover per un database in pool:
- Il pool elastico primario dovrebbe già essere disponibile. Creare un pool elastico per cominciare.
- Se il server secondario esiste già, il login del server e le impostazioni del firewall devono corrispondere a quelle del server primario.
Create failover group
Creare il gruppo di failover per il pool elastico usando il portale di Azure, PowerShell o l'interfaccia della riga di comando di Azure.
Importante
Se è necessario eliminare un database secondario dopo che è stato aggiunto a un gruppo di failover, rimuoverlo dal gruppo di failover prima di eliminare il database. L'eliminazione di un database secondario prima della rimozione dal gruppo di failover può causare comportamenti imprevisti.
Per creare il gruppo failover e aggiungerci il pool elastico utilizzando il portale Azure, procedere come segue:
Andare alla pagina Crea pool elastico SQL nel portale Azure. Creare un pool elastico che:
- Ha lo stesso nome del pool elastico nel server primario.
- Usa il server secondario selezionato per il gruppo di failover. Il server secondario deve trovarsi in un'area diversa dal server primario e le impostazioni di accesso e di firewall del server devono corrispondere a quelle del server primario. Creare un nuovo server se il server secondario non è già stato creato.
Se si conosce il server logico che ospita il pool elastico primario, passare direttamente al server nel portale di Azure. Se occorre trovare il server, seguire questa procedura:
- Selezionare Azure SQL nel menu di servizio. Se Azure SQL non è presente nell'elenco, selezionare Tutti i servizi e digitare
Azure SQLnella casella di ricerca. (Facoltativo) Selezionare la stella accanto ad Azure SQL per aggiungerlo ai Preferiti e come elemento nel menu di servizio. - Nella pagina Azure SQL, individuare il pool elastico da aggiungere al gruppo di failover e selezionarlo per aprire il riquadro Pool elastico SQL.
- Nel riquadro Panoramica del Pool elastico SQL, selezionare il nome del server in Nome del server per aprire il riquadro SQL Server.
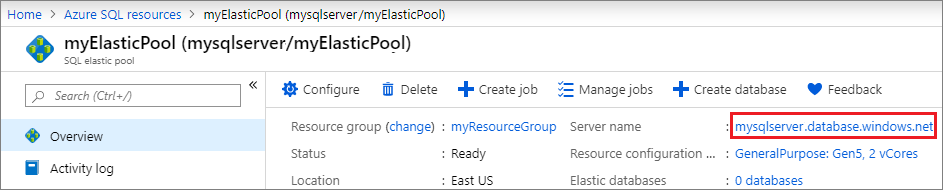
- Selezionare Azure SQL nel menu di servizio. Se Azure SQL non è presente nell'elenco, selezionare Tutti i servizi e digitare
Nel menu delle risorse del SQL Server selezionare Gruppi di failover in Gestione dei dati. Selezionare + Aggiungi gruppo per aprire la pagina Gruppi di failover in cui è possibile creare un nuovo gruppo di failover.

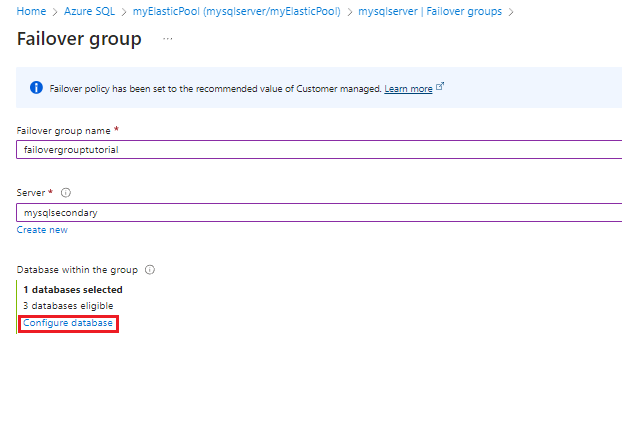
Nella pagina Gruppi di failover:
- Specificare un nome del gruppo di failover.
- Scegliere un server secondario esistente. Il server secondario del gruppo di failover deve trovarsi in una regione diversa da quella del server primario e deve includere un pool elastico con lo stesso nome del server primario.
- Selezionare Configura database per aprire la pagina Database per il gruppo di failover.
Nella pagina Database per il gruppo di failover scegliere i database in pool da aggiungere al gruppo di failover. Usare Seleziona per salvare la selezione del database e tornare alla pagina Gruppi di failover.
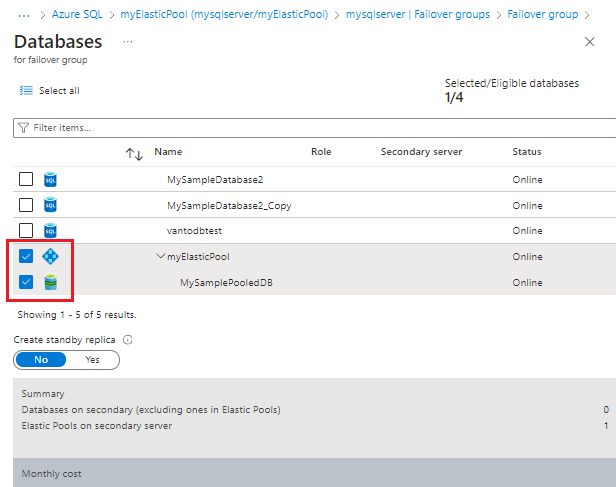
Selezionare Crea nella pagina Gruppi di failover per creare il gruppo di failover. Aggiungendo il pool elastico al gruppo di failover si avvia automaticamente il processo di replica geografica.
Testare un failover pianificato
Testare un failover senza perdita di dati del pool elastico usando il portale di Azure, PowerShell o l'interfaccia della riga di comando.
Eseguire il failover del gruppo di failover sul server secondario e quindi eseguire il failback utilizzando il portale di Azure.
Se si conosce il server logico che ospita il pool elastico primario, passare direttamente al server nel portale di Azure. Se occorre trovare il server, seguire questa procedura:
- Selezionare Azure SQL nel menu di servizio. Se Azure SQL non è presente nell'elenco, selezionare Tutti i servizi e digitare
Azure SQLnella casella di ricerca. (Facoltativo) Selezionare la stella accanto ad Azure SQL per aggiungerlo ai Preferiti e come elemento nel menu di servizio. - Nella pagina Azure SQL, individuare il pool elastico da aggiungere al gruppo di failover e selezionarlo per aprire il riquadro Pool elastico SQL.
- Nel riquadro Panoramica del Pool elastico SQL, selezionare il nome del server in Nome del server per aprire il riquadro SQL Server.
- Selezionare Azure SQL nel menu di servizio. Se Azure SQL non è presente nell'elenco, selezionare Tutti i servizi e digitare
Nel menu delle risorse di SQL Server selezionare Gruppi di failover in Gestione dei dati e quindi scegliere un gruppo di failover esistente per aprire la pagina Gruppo di failover.
Nella pagina Gruppi di failover:
- Verificare qual è il server primario e quale quello secondario.
- Selezionare Failover nella barra dei comandi per eseguire il failover del gruppo di failover che contiene il database.
- Selezionare Sì nella finestra dell'avviso che informa che le sessioni TDS verranno disconnesse.
Verificare quale server è ora il server primario e quale quello secondario. Al termine del failover, i due server scambiano i ruoli, in modo che il precedente database primario diventi secondario.
(Facoltativo) Selezionare di nuovo Failover per ripristinare i ruoli originali dei server.
Modificare gruppo di failover esistente
Si possono aggiungere o rimuovere database da un gruppo di failover esistente o modificare le impostazioni di configurazione del gruppo tramite il portale di Azure, PowerShell e l'interfaccia della riga di comando di Azure.
Per modificare un gruppo di failover esistente tramite il portale di Azure, seguire questi passaggi:
Se si conosce il server logico che ospita il database o il pool elastico, passare direttamente al server nel portale di Azure. Se occorre trovare il server, seguire questa procedura:
- Selezionare Azure SQL nel menu di servizio. Se Azure SQL non è presente nell'elenco, selezionare Tutti i servizi e digitare
Azure SQLnella casella di ricerca. (Facoltativo) Selezionare la stella accanto ad Azure SQL per aggiungerlo ai Preferiti e come elemento nel menu di servizio. - Nella pagina Azure SQL individuare il database o il pool elastico da modificare e selezionarlo per aprire il riquadro Database SQL o Pool elastico SQL.
- Nel riquadro Panoramica, per il database SQL o il pool elastico SQL selezionare il nome del server in Nome server per aprire il riquadro SQL Server.
- Selezionare Azure SQL nel menu di servizio. Se Azure SQL non è presente nell'elenco, selezionare Tutti i servizi e digitare
Nel menu delle risorse di SQL Server selezionare Gruppi di failover in Gestione dei dati e quindi scegliere un gruppo di failover esistente per aprire la pagina Gruppo di failover.
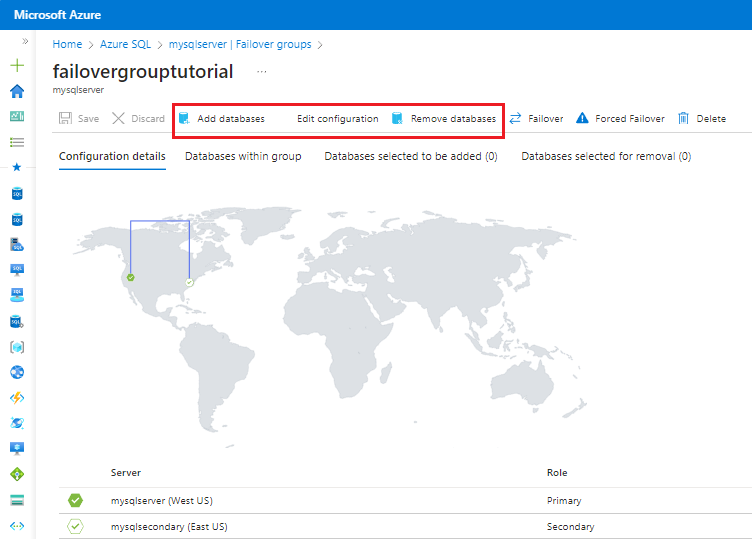
Nella pagina dei gruppi di failover, utilizzare la barra dei comandi:
- Per aggiungere un database, selezionare Aggiungi database per aprire il riquadro Aggiungi database al gruppo di failover e quindi espandere #Database per visualizzare l'elenco dei database nel server primario. Selezionare la casella accanto ai database da aggiungere al gruppo di failover e quindi usare Seleziona per salvare le modifiche e aggiungere i database.
- Per rimuovere un database, selezionare Rimuovi database per aprire il riquadro Rimuovi database dal gruppo di failover e quindi espandere #Database per elencare i database nel gruppo di failover. Selezionare la casella accanto ai database da rimuovere dal gruppo di failover e quindi usare Seleziona per salvare le modifiche e rimuovere i database.
- Per modificare i criteri di failover o configurare un periodo di tolleranza, selezionare Modifica configurazione per aprire il riquadro Modifica configurazioni dei gruppi di failover e modificare le impostazioni. Premere Seleziona per salvare le modifiche.
Usare Collegamento privato
L'uso di un collegamento privato consente di associare un server logico a un indirizzo IP privato specifico all'interno della rete virtuale e della subnet.
Per usare un collegamento privato con il gruppo di failover, attenersi alla procedura seguente:
- Assicurarsi che i server primario e secondario si trovino in un'area associata.
- Creare la rete virtuale e la subnet in ogni area per ospitare gli endpoint privati per i server primari e secondari, in modo che gli spazi degli indirizzi IP non siano sovrapposti. Ad esempio, l'intervallo di indirizzi della rete virtuale primaria di 10.0.0.0/16 e l'intervallo di indirizzi della rete virtuale secondario di 10.0.0.1/16 si sovrappongono. Per altre informazioni sugli intervalli di indirizzi di rete virtuale, vedere il blog sulla progettazione di reti virtuali di Azure.
- Creare un endpoint privato e una zona di DNS privato di Azure per il server primario.
- Creare un endpoint privato anche per il server secondario, ma questa volta scegliere di riutilizzare la stessa zona di DNS privato creata per il server primario.
- Dopo aver stabilito il collegamento privato, è possibile creare il gruppo di failover seguendo i passaggi descritti in precedenza in questo articolo.
Individuare l'endpoint del listener
Dopo aver configurato il gruppo di failover, aggiornare la stringa di connessione dell'applicazione per puntare all'endpoint del listener di lettura/scrittura in modo che l'applicazione continui a connettersi al database primario dopo il failover. Usando l'endpoint del listener, non è necessario aggiornare manualmente la stringa di connessione ogni volta che il gruppo di failover esegue il failover perché il traffico viene sempre indirizzato all'istanza primaria corrente. È anche possibile indirizzare il carico di lavoro di sola lettura all'endpoint del listener di sola lettura.
Per ricercare l'endpoint del listener nel portale di Azure, passare al server logico nel portale di Azure e in Gestione dati selezionare Gruppi di failover. Selezionare il gruppo di failover a cui si è interessati.
Scorrere verso il basso per trovare gli endpoint del listener:
- L'endpoint del listener di lettura/scrittura, sotto forma di
fog-name.database.windows.net, instrada il traffico al database primario. - L'endpoint deò listener di sola lettura, sotto forma di
fog-name.secondary.database.windows.net, instrada il traffico al database secondario.

Dimensionare un database in un gruppo di failover
È possibile aumentare o ridurre un database primario a una dimensione di calcolo diversa (nello stesso livello di servizio) senza disconnettere i database secondari con replica geografica. Quando si aumentano le prestazioni, è consigliabile aumentare prima quelle del database secondario geografico e quindi quelle del database primario. In caso di riduzione delle prestazioni, invertire l'ordine: prima ridurre le prestazioni del database primario e poi le prestazioni di quello secondario. Quando si aumenta/riduce un database passando a un livello di servizio diverso, viene imposta questa raccomandazione.
Questa sequenza è consigliata specificamente per evitare il problema in cui il geo-secondario con uno SKU inferiore viene sovraccaricato e deve essere eseguito un nuovo processo di seeding durante la procedura di aggiornamento o downgrade. È possibile evitare il problema anche rendendo la replica primaria di sola lettura, a scapito di tutti i carichi di lavoro di lettura/scrittura sul componente primario.
Nota
Se è stato creato un database secondario con replica geografica come parte della configurazione di un gruppo di failover, non è consigliabile ridurne le prestazioni. Ciò garantisce che il livello dati disponga della capacità sufficiente per elaborare il carico di lavoro normale dopo un failover geografico. Potrebbe non essere possibile dimensionare un database geografico secondario dopo un failover imprevisto quando il database geografico primario precedente non è disponibile a causa di un'interruzione. Si tratta di una limitazione nota.
Il database primario in un gruppo di failover non può essere ridimensionato a un livello di servizio superiore (edizione), a meno che il database secondario non venga prima ridimensionato al livello superiore. Ad esempio, se si vuole aumentare le prestazioni del database primario da Utilizzo generico a Business Critical, è necessario prima ridimensionare la replica geografica secondaria portandola a Business Critical. Se si tenta di ridimensionare il database primario o quello geografico secondario in modo da violare questa regola, verrà visualizzato l'errore seguente:
The source database 'Primaryserver.DBName' cannot have higher edition than the target database 'Secondaryserver.DBName'. Upgrade the edition on the target before upgrading the source.
Evitare la perdita di dati critici
A causa della latenza elevata delle reti Wide Area Network, per la replica geografica viene usato un meccanismo di replica asincrona. La replica asincrona può comportare la perdita di dati nel caso in cui il database primario abbia esito negativo. Per proteggere questi aggiornamenti critici dalla perdita di dati, uno sviluppatore di applicazioni può richiamare la stored procedure sp_wait_for_database_copy_sync subito dopo il commit della transazione. La chiamata sp_wait_for_database_copy_sync blocca il thread chiamante fino a quando l'ultima transazione sottoposta a commit non viene trasmessa e sottoposta a protezione avanzata nel log delle transazioni del database secondario. Tuttavia, non attende che le transazioni trasmesse vengano riprodotta (eseguite nuovamente) nel database secondario. sp_wait_for_database_copy_sync è limitato a un collegamento di replica geografica specifico. La procedura può essere chiamata da qualsiasi utente che abbia diritti di connessione al database primario.
Nota
sp_wait_for_database_copy_sync impedisce la perdita di dati dopo il failover geografico per transazioni specifiche, ma non garantisce la sincronizzazione completa per l'accesso in lettura. Il ritardo causato da una chiamata di procedura sp_wait_for_database_copy_sync può essere significativo e dipende dalle dimensioni del log delle transazioni non ancora trasmesso al database primario al momento della chiamata.
Modificare l'area secondaria
Per illustrare la sequenza di modifiche, si presuppone che il server A sia il server primario, il server B sia il server secondario esistente e il server C sia il nuovo secondario nella terza area. Per eseguire la transizione, seguire questi passaggi:
- Creare repliche secondarie aggiuntive di ogni database nel server A al server C usando la replica geografica attiva. Ogni database nel server A avrà due database secondari, uno nel server B e uno nel server C. Ciò garantisce che i database primari rimangano protetti durante la transizione.
- Eliminare il gruppo di failover. A questo punto, i tentativi di accesso che usano gli endpoint del gruppo di failover iniziano a fallire.
- Ricreare il gruppo di failover con lo stesso nome tra i server A e C.
- Aggiungere tutti i database primari nel server A al nuovo gruppo di failover. A questo punto, i tentativi di accesso smettono di fallire.
- Eliminare il server B. Tutti i database in B verranno eliminati automaticamente.
Modificare l'area primaria
Per illustrare la sequenza di modifiche, si presuppone che il server A sia il server primario, il server B sia il server secondario esistente e il server C sia il nuovo server primario nella terza area. Per eseguire la transizione, seguire questi passaggi:
- Eseguire un failover geografico pianificato per passare il server primario a B. Il server A diventa il nuovo server secondario. Il failover potrebbe comportare diversi minuti di inattività. Il tempo effettivo dipende dalle dimensioni del gruppo di failover.
- Creare repliche secondarie aggiuntive di ogni database nel server B al server C usando la replica geografica attiva. Ogni database nel server B avrà due database secondari, uno nel server A e uno nel server C. Ciò garantisce che i database primari rimangano protetti durante la transizione.
- Eliminare il gruppo di failover. A questo punto, i tentativi di accesso che usano gli endpoint del gruppo di failover iniziano a fallire.
- Ricreare il gruppo di failover con lo stesso nome tra i server B e C.
- Aggiungere tutti i database primari in B al nuovo gruppo di failover. A questo punto, i tentativi di accesso smettono di fallire.
- Eseguire un failover geografico pianificato del gruppo di failover per passare da B a C. Il server C diventa ora primario e B il database secondario. Tutti i database secondari nel server A verranno collegati automaticamente a quelli primari in C. Come nel passaggio 1, il failover potrebbe comportare diversi minuti di inattività.
- Eliminare il server A. Tutti i database in A verranno eliminati automaticamente.
Importante
Quando il gruppo di failover viene eliminato, vengono eliminati anche i record DNS per gli endpoint del listener. A questo punto, esiste la probabilità che qualcun altro possa aver creato un gruppo di failover o un alias DNS del server con lo stesso nome. Poiché i nomi dei gruppi di failover e gli alias DNS devono essere univoci a livello globale, questo impedirà di usare di nuovo lo stesso nome. Per ridurre al minimo questo rischio, non usare nomi di gruppo di failover generici.
Gruppi di failover e sicurezza di rete
Per alcune applicazioni, le regole di sicurezza richiedono che l'accesso di rete al livello dati sia limitato a uno o più componenti specifici, ad esempio una macchina virtuale, un servizio Web e così via. Questo prerequisito presenta alcune difficoltà intrinseche per la progettazione della continuità aziendale e l’uso di gruppi di failover. Quando si implementa questo tipo di accesso con restrizioni, è necessario considerare le opzioni seguenti.
Usare i gruppi di failover e gli endpoint servizio di rete virtuale
Se si usano endpoint e regole servizio di rete virtuale per limitare l'accesso al database, tenere presente che ogni endpoint servizio di rete virtuale si applica a una sola area geografica di Azure. L'endpoint non consente ad altre aree di accettare le comunicazioni dalla subnet. Pertanto, solo le applicazioni client distribuite nella stessa area possono connettersi al database primario. Poiché un failover geografico comporta il reindirizzamento delle sessioni client del database SQL a un server in un'area diversa (secondaria), queste sessioni potrebbero avere esito negativo se originate da un client esterno a tale area. Per questo motivo, i criteri di failover gestito da Microsoft non possono essere abilitati se i server partecipanti sono inclusi nelle regole di rete virtuale. Per supportare il failover manuale, seguire questi passaggi:
- Effettuare il provisioning delle copie ridondanti dei componenti front-end dell'applicazione (servizio web, macchine virtuali e così via) nell'area secondaria.
- Configurare le regole di rete virtuale singolarmente per il server primario e per quello secondario.
- Abilitare il failover front-end usando una configurazione di Gestione traffico.
- Avviare il failover geografico manuale quando viene rilevata l'interruzione. Questa opzione è ottimizzata per le applicazioni che richiedono la latenza coerente tra il front-end e il livello dati e supporta il ripristino quando il front-end, il livello dati o entrambi sono interessati dall'interruzione del servizio.
Nota
Se si usa il listener di sola lettura per il bilanciamento di un carico di lavoro di sola lettura, assicurarsi che il carico di lavoro venga eseguito in una VM o in un'altra risorsa nell'area secondaria in modo da consentire la connessione al database secondario.
Usare gruppi di failover e regole del firewall
Se il piano di continuità aziendale richiede il failover tramite gruppi di failover, è possibile limitare l'accesso al database SQL utilizzando le regole del firewall IP pubblico. Questa configurazione garantisce che un failover geografico non blocchi le connessioni dai componenti front-end e presuppone che l'applicazione possa tollerare una latenza più lunga tra il front-end e il livello dati.
Per supportare il failover del gruppo, seguire questi passaggi:
- Creare un IP pubblico.
- Creare un servizio di bilanciamento del carico pubblico e assegnare l'indirizzo IP pubblico a tale servizio.
- Creare una rete virtuale e le macchine virtuali per i componenti front-end.
- Creare un gruppo di sicurezza di rete e configurare le connessioni in ingresso.
- Assicurarsi che le connessioni in uscita siano aperte al database SQL di Azure usando un tag del servizio.
Sql.<Region>. - Creare una regola del firewall del database SQL per consentire il traffico in ingresso dall'indirizzo IP pubblico creato nel passaggio 1.
Per maggiori informazioni su come configurare l'accesso in uscita e su quale indirizzo IP usare nelle regole del firewall, vedere Connessioni in uscita del servizio di bilanciamento del carico.
Importante
Per garantire la continuità aziendale durante le interruzioni regionali, è necessario garantire la ridondanza geografica sia per i componenti front-end che per i database.
Autorizzazioni
Le autorizzazioni per un gruppo di failover vengono gestite tramite il controllo degli accessi in base al ruolo di Azure (Azure RBAC).
L'accesso in scrittura del controllo degli accessi in base al ruolo di Azure è necessario per creare e gestire i gruppi di failover. Il ruolo Collaboratore SQL Server dispone di tutte le autorizzazioni necessarie a gestire i gruppi di failover.
Nella tabella seguente sono elencati gli ambiti di autorizzazione specifici per database SQL di Azure:
| Azione | Autorizzazione | Scope |
|---|---|---|
| Create failover group | Accesso in scrittura del controllo degli accessi in base al ruolo di Azure | Server primario Server secondario Tutti i database in un gruppo di failover |
| Aggiorna gruppo di failover | Accesso in scrittura del controllo degli accessi in base al ruolo di Azure | Gruppo di failover Tutti i database nel server primario corrente |
| Eseguire il failover del gruppo di failover | Accesso in scrittura del controllo degli accessi in base al ruolo di Azure | Gruppo di failover nel nuovo server |
Limiti
Tenere presente le limitazioni seguenti:
- Non è possibile creare gruppi di failover tra due server nella stessa area di Azure.
- I gruppi di failover supportano la replica geografica di tutti i database nel gruppo in un solo server logico secondario in un'area diversa.
- I gruppi di failover non possono essere rinominati. Sarà necessario eliminare il gruppo e ricrearlo con un nome diverso.
- La ridenominazione del database non è supportata per i database inclusi in un gruppo di failover. Per rinominare un database sarà necessario eliminare temporaneamente il gruppo di failover o rimuovere il database dal gruppo di failover.
- La rimozione di un gruppo di failover per un database singolo o in pool non interrompe la replica e non elimina il database replicato. Sarà necessario arrestare manualmente la replica geografica ed eliminare il database dal server secondario se si vuole aggiungere di nuovo un database singolo o in pool a un gruppo di failover dopo averlo rimosso. In caso contrario, potrebbe verificarsi un errore simile a
The operation cannot be performed due to multiple errorsquando si tenta di aggiungere il database al gruppo di failover. - Il nome del gruppo di failover è soggetto a restrizioni di denominazione.
- Quando si crea un nuovo gruppo di failover o quando si aggiungono database a un gruppo di failover esistente, si può solo designare i database come repliche di standby se si usa il portale di Azure. Azure PowerShell e l'interfaccia della riga di comando di Azure non sono attualmente disponibili.
Gestione programmatica di gruppi di failover
I gruppi di failover possono anche essere gestiti a livello di codice usando Azure PowerShell, l'interfaccia della riga di comando di Azure e l'API REST. Le tabelle seguenti descrivono il set di comandi disponibili. I gruppi di failover includono un set di API di Azure Resource Manager per la gestione, compresa l'API REST del database SQL di Azure e i cmdlet di Azure PowerShell. Queste API richiedono l'uso di gruppi di risorse e supportano la sicurezza basata sui ruoli (Azure RBAC). Per ulteriori informazioni su come implementare i ruoli di accesso, vedere Controllo degli accessi in base al ruolo di Azure (Azure RBAC).
| Cmdlet | Descrizione |
|---|---|
| New-AzSqlDatabaseFailoverGroup | Questo comando crea un gruppo di failover e lo registra nei server primario e secondario |
| Add-AzSqlDatabaseToFailoverGroup | Aggiunge uno o più database a un gruppo di failover |
| Remove-AzSqlDatabaseFromFailoverGroup | Rimuove uno o più database da un gruppo di failover |
| Remove-AzSqlDatabaseFailoverGroup | Rimuove un gruppo di failover dal server |
| Get-AzSqlDatabaseFailoverGroup | Recupera la configurazione di un gruppo di failover |
| Set-AzSqlDatabaseFailoverGroup | Modifica la configurazione di un gruppo di failover |
| Switch-AzSqlDatabaseFailoverGroup | Attiva il failover di un gruppo di failover per il server secondario |
Nota
È possibile distribuire il gruppo di failover tra sottoscrizioni usando il parametro -PartnerSubscriptionId in Azure PowerShell a partire da Az.SQL 3.11.0. Per saperne di più, vedere il seguente Esempio.