Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questa esercitazione illustra come creare ed eseguire una pipeline di Azure Data Factory che esegue un carico di lavoro di Azure Batch. Uno script Python viene eseguito sui nodi Batch per ottenere un input di valori separati da virgole (CSV) da un contenitore di Archiviazione BLOB di Azure, modificare i dati e scrivere l'output in un contenitore di archiviazione diverso. Si utilizza Batch Explorer per creare un pool e nodi di Batch e Azure Storage Explorer per lavorare con i contenitori e i file di archiviazione.
In questa esercitazione apprenderai a:
- Utilizzare Batch Explorer per creare un pool di Batch e i relativi nodi.
- Usare Storage Explorer per creare contenitori di archiviazione e caricare file di input.
- Sviluppare uno script Python per modificare i dati di input e produrre output.
- Creare una pipeline di Data Factory che esegue il carico di lavoro di Batch.
- Usare Batch Explorer per esaminare i file di log di output.
Prerequisiti
- Un account Azure con una sottoscrizione attiva. Se non se ne ha una, creare un account gratuito.
- Un account di Batch con un account di Archiviazione di Azure collegato. È possibile creare gli account usando uno dei metodi seguenti: portale di Azure | Azure CLI | Bicep | modello ARM | Terraform.
- Un'istanza di Data Factory. Per creare la data factory, seguire le istruzioni riportate in Creare una data factory.
- Batch Explorer scaricato e installato.
- Storage Explorer scaricato e installato.
-
Python 3.8 o versione successiva, con il pacchetto azure-storage-blob installato usando
pip. - Set di dati di input iris.csv scaricato da GitHub.
Usare Batch Explorer per creare un pool e nodi di Batch
Usare Batch Explorer per creare un pool di nodi di calcolo per eseguire il carico di lavoro.
Accedere a Batch Explorer con le credenziali di Azure.
Seleziona il tuo account Batch.
Selezionare Pool sulla barra laterale sinistra e quindi selezionare l'icona + per aggiungere un pool.
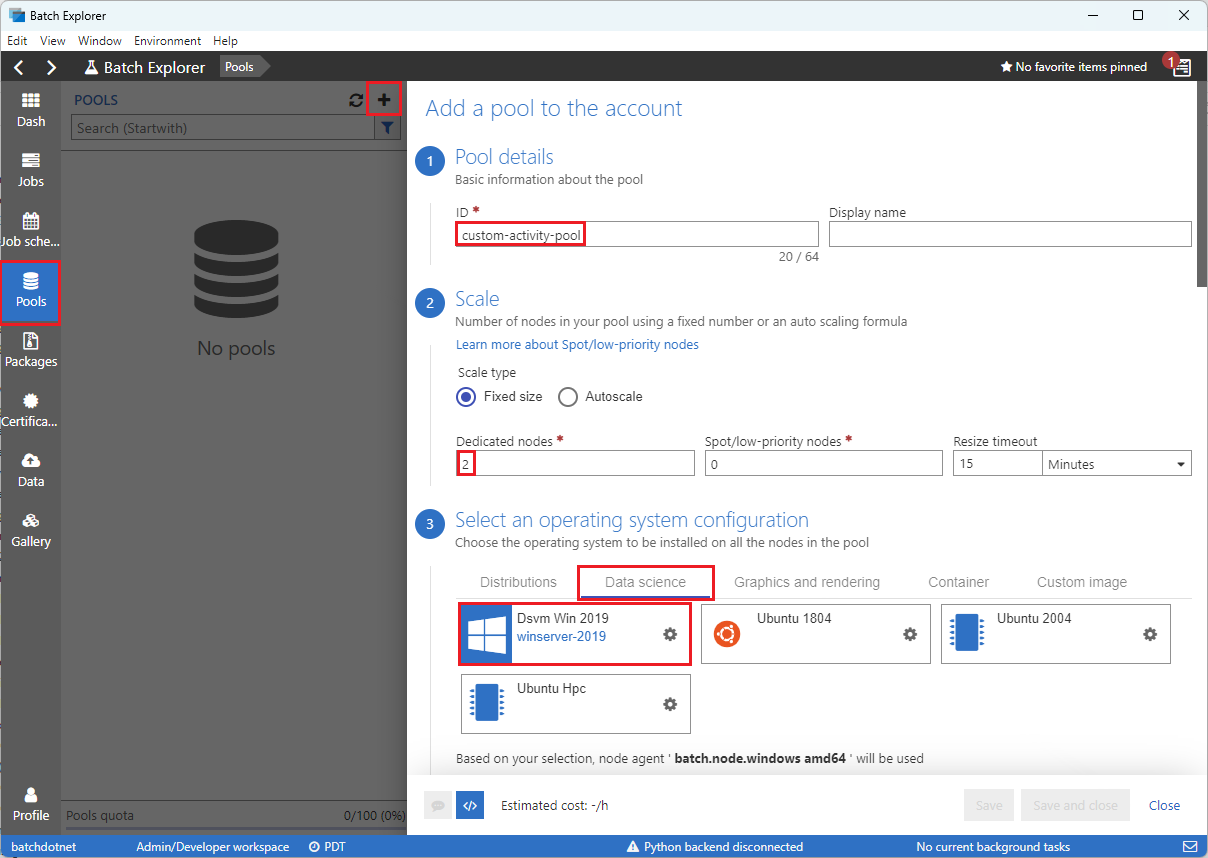
Completare il modulo Aggiungi un pool all'account come indicato di seguito:
- In ID immettere custom-activity-pool.
- Sotto Nodi dedicati, immettere 2.
- Per Selezionare una configurazione del sistema operativo, selezionare la scheda Analisi scientifica dei dati e quindi selezionare Dsvm Win 2019.
- In Scegliere una dimensione di macchina virtuale, selezionare Standard_F2s_v2.
- Per Avvia attività selezionare Aggiungi un'attività di avvio.
Nella schermata attività di avvio, in Riga di comando immettere
cmd /c "pip install azure-storage-blob pandas"e quindi selezionare Seleziona. Questo comando installa ilazure-storage-blobpacchetto in ogni nodo all'avvio.
Seleziona Salva e chiudi.

Usare Storage Explorer per creare contenitori BLOB
Usare Storage Explorer per creare contenitori BLOB per archiviare i file di input e di output e quindi caricare i file di input.
- Accedere a Storage Explorer con le credenziali di Azure.
- Nella barra laterale sinistra individuare ed espandere l'account di archiviazione collegato all'account Batch.
- Fare clic con il pulsante destro del mouse su Contenitori BLOB e scegliere Crea contenitore BLOB oppure selezionare Crea contenitore BLOB da Azioni nella parte inferiore della barra laterale.
- Immettere l'input nel campo di inserimento.
- Creare un altro contenitore BLOB denominato output.
- Selezionare il contenitore di input e quindi selezionare Carica>Carica file nel riquadro destro.
- Nella schermata Carica file, sotto File selezionati, selezionare i puntini di sospensione ... accanto al campo di inserimento.
- Passare al percorso del file iris.csv scaricato, selezionare Apri e quindi selezionare Carica.

Sviluppare un modulo Python
Lo script Python seguente carica il file del set di dati iris.csv dal contenitore di input di Storage Explorer, modifica i dati e salva i risultati nel contenitore di output.
Lo script deve usare la stringa di connessione per l'account di archiviazione di Azure collegato all'account Batch. Per ottenere la stringa di connessione:
- Nella portale di Azure cercare e selezionare il nome dell'account di archiviazione collegato all'account Batch.
- Nella pagina dell'account di archiviazione selezionare Chiavi di accesso nel riquadro di spostamento a sinistra in Sicurezza e rete.
- In key1 selezionare Mostra accanto a Stringa di connessione e quindi selezionare l'icona Copia per copiare il stringa di connessione.
Incolla la stringa di connessione nello script seguente, sostituendo il segnaposto <storage-account-connection-string>. Salvare lo script come file denominato main.py.
Importante
Non è consigliabile esporre le chiavi dell'account nel codice sorgente dell'app per l'uso in ambiente di produzione. È consigliabile limitare l'accesso alle credenziali e farvi riferimento nel codice usando variabili o un file di configurazione. È consigliabile archiviare le chiavi dell'account Batch e dell'account di Archiviazione in Azure Key Vault.
# Load libraries
# from azure.storage.blob import BlobClient
from azure.storage.blob import BlobServiceClient
import pandas as pd
import io
# Define parameters
connectionString = "<storage-account-connection-string>"
containerName = "output"
outputBlobName = "iris_setosa.csv"
# Establish connection with the blob storage account
blob = BlobClient.from_connection_string(conn_str=connectionString, container_name=containerName, blob_name=outputBlobName)
# Initialize the BlobServiceClient (This initializes a connection to the Azure Blob Storage, downloads the content of the 'iris.csv' file, and then loads it into a Pandas DataFrame for further processing.)
blob_service_client = BlobServiceClient.from_connection_string(conn_str=connectionString)
blob_client = blob_service_client.get_blob_client(container_name=containerName, blob_name=outputBlobName)
# Download the blob content
blob_data = blob_client.download_blob().readall()
# Load iris dataset from the task node
# df = pd.read_csv("iris.csv")
df = pd.read_csv(io.BytesIO(blob_data))
# Take a subset of the records
df = df[df['Species'] == "setosa"]
# Save the subset of the iris dataframe locally in the task node
df.to_csv(outputBlobName, index = False)
with open(outputBlobName, "rb") as data:
blob.upload_blob(data, overwrite=True)
Per ulteriori informazioni sull'uso di Blob Storage di Azure, consultare la documentazione di Blob Storage di Azure.
Eseguire lo script in locale per testare e convalidare la funzionalità.
python main.py
Lo script deve produrre un file di output denominato iris_setosa.csv che contiene solo i record di dati con Species = setosa. Dopo aver verificato che funzioni correttamente, caricare il file di script main.py nel contenitore di input di Storage Explorer.
Configurare una pipeline di Data Factory
Creare e convalidare una pipeline di Data Factory che usa lo script Python.
Ottenere le informazioni sull'account
La pipeline Azure Data Factory deve usare i nomi degli account Batch e di archiviazione, i valori delle chiavi degli account e l'endpoint dell'account Batch. Per ottenere queste informazioni dal portale di Azure:
Nella barra di Ricerca di Azure cercare e selezionare il nome dell'account Batch.
Nella pagina Account Batch, selezionare Chiavi dal pannello di navigazione a sinistra.
Nella pagina Chiavi copiare i valori seguenti:
- Account batch
- Endpoint dell'account
- Chiave di accesso primaria
- Nome dell'account di archiviazione
- Key1
Creare ed eseguire la pipeline
Se Azure Data Factory Studio non è già in esecuzione, selezionare Avvia studio nella pagina Data Factory nel portale di Azure.
In Data Factory Studio, selezionare l'icona a forma di matita Author nella barra di navigazione a sinistra.
Sotto Risorse della fabbrica, selezionare l'icona +, e quindi selezionare Pipeline.
Nel riquadro Proprietà a destra modificare il nome della pipeline in Esegui Python.
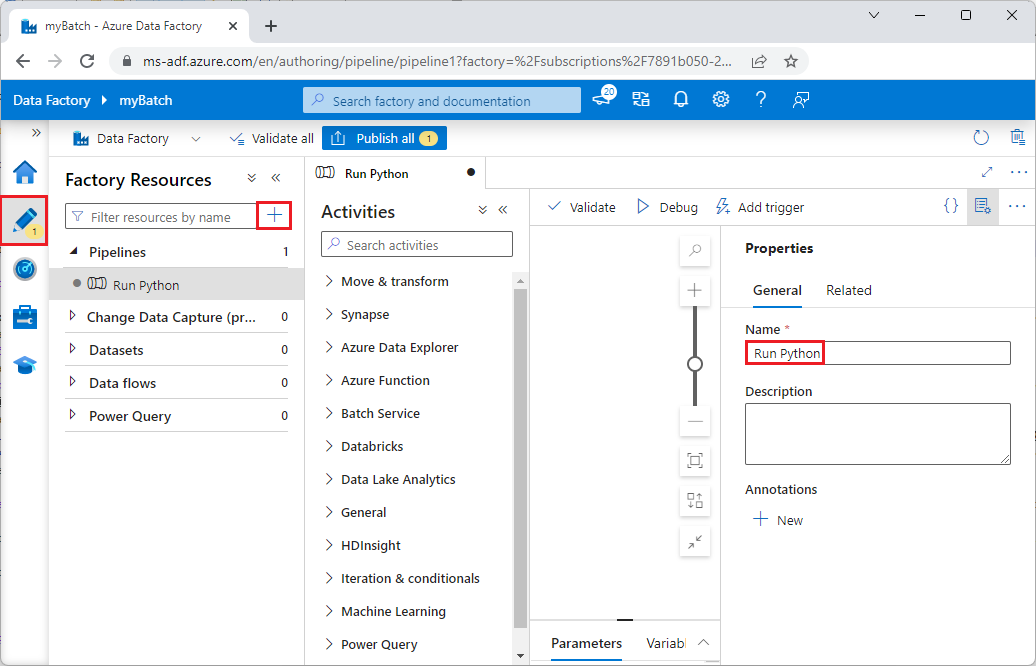
Nel riquadro Attività espandere Servizio batch e trascinare l'attività Personalizzato nell'area di progettazione pipeline.
Sotto l'area di disegno della finestra di progettazione, nella scheda Generale immettere testPipeline in Nome.
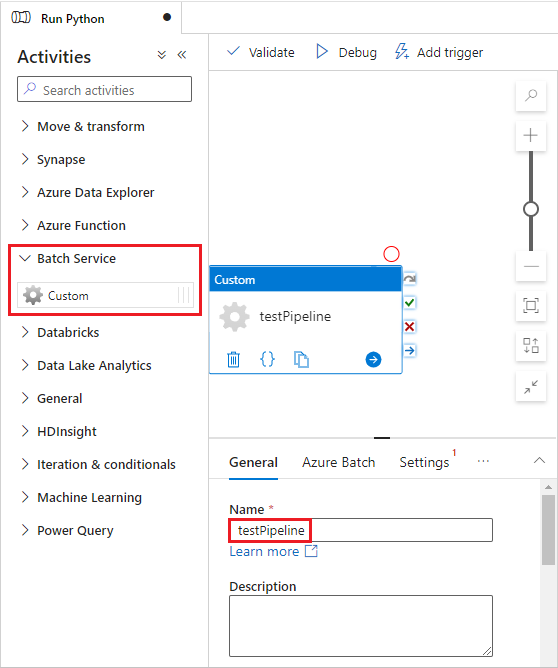
Selezionare la scheda Azure Batch e quindi selezionare Nuovo.
Completare il modulo Nuovo servizio collegato come indicato di seguito:
- Nome: immettere un nome per il servizio collegato, ad esempio AzureBatch1.
- Chiave di accesso: immettere la chiave di accesso primaria copiata dall'account Batch.
- Nome account: immettere il nome dell'account di Batch.
-
URL Batch: immettere l'endpoint dell'account copiato dall'account di Batch, ad esempio
https://batchdotnet.eastus.batch.azure.com. - Nome del pool: immettere custom-activity-pool, il pool che hai creato in Batch Explorer.
- Nome del servizio collegato dell'account di archiviazione: selezionare Nuovo. Nella schermata successiva immettere un nome per il servizio di archiviazione collegato, ad esempio AzureBlobStorage1, selezionare la sottoscrizione di Azure e l'account di archiviazione collegato e quindi selezionare Crea.
Nella parte inferiore della schermata Batch Nuovo servizio collegato, seleziona Test connessione. Al termine della connessione, selezionare Crea.
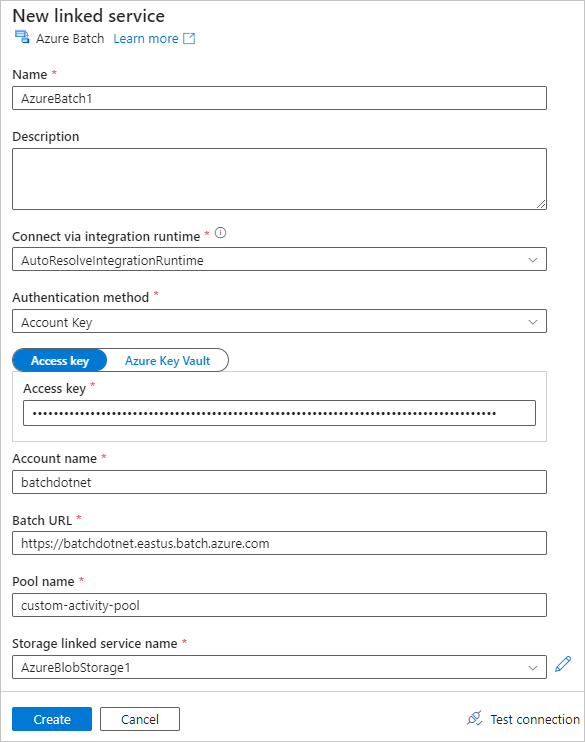
Selezionare la scheda Impostazioni e immettere o selezionare le impostazioni seguenti:
-
Comando: immettere
cmd /C python main.py. - Servizio collegato alle risorse: selezionare il servizio di archiviazione collegato creato, ad esempio AzureBlobStorage1, e testare la connessione per assicurarsi che abbia esito positivo.
- Percorso cartella: selezionare l'icona della cartella e quindi selezionare il contenitore di input e selezionare OK. I file di questa cartella vengono scaricati dal contenitore ai nodi del pool prima dell'esecuzione dello script Python.
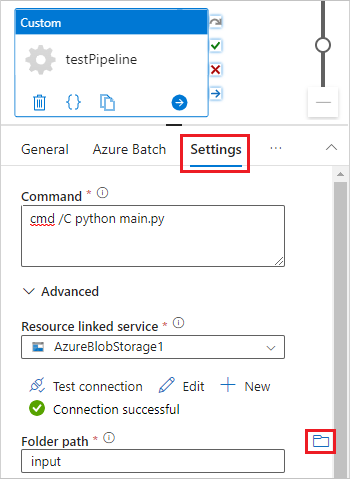
-
Comando: immettere
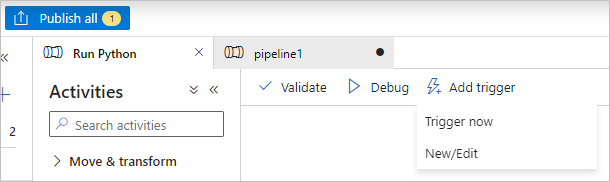
Selezionare Convalida sulla barra degli strumenti della pipeline per convalidare la pipeline.
Selezionare Debug per testare la pipeline e assicurarsi che funzioni correttamente.
Selezionare Pubblica tutto per pubblicare la pipeline.
Selezionare Aggiungi trigger e quindi Esegui ora per eseguire la pipeline oppure Nuovo/Modifica per pianificarla.

Usare Batch Explorer per visualizzare i file di log
Se l'esecuzione della pipeline genera avvisi o errori, è possibile usare Batch Explorer per esaminare i file di output stdout.txt e stderr.txt per altre informazioni.
- In Batch Explorer, selezionare Jobs dalla barra laterale a sinistra.
- Selezionare il processo adfv2-custom-activity-pool.
- Selezionare un'attività con codice di uscita dell'errore.
- Visualizzare i file stdout.txt e stderr.txt per analizzare e diagnosticare il problema.
Pulire le risorse
Gli account Batch, i processi e le attività sono gratuiti, ma i nodi di calcolo comportano addebiti anche quando non eseguono processi. È consigliabile allocare pool di nodi solo in base alle esigenze ed eliminare i pool al termine dell'operazione. La cancellazione dei pool elimina tutti i risultati delle attività presenti nei nodi, oltre ai nodi stessi.
I file di input e output rimangono nell'account di archiviazione e possono comportare addebiti. Quando i file non sono più necessari, è possibile eliminare i file o i contenitori. Quando non è più necessario l'account Batch o l'account di archiviazione collegato, è possibile eliminarli.
Passaggi successivi
In questa esercitazione si è appreso come usare uno script Python con Batch Explorer, Storage Explorer e Data Factory per eseguire un carico di lavoro Batch. Per altre informazioni su Data Factory, vedere Che cos'è Azure Data Factory?