Scegliere la configurazione corretta del runtime di integrazione per lo scenario
Il runtime di integrazione è una parte importante dell'infrastruttura per la soluzione di integrazione dei dati fornita da Azure Data Factory. Ciò richiede di considerare pienamente come adattarsi alla struttura di rete e all'origine dati esistente all'inizio della progettazione della soluzione, nonché considerare le prestazioni, la sicurezza e i costi.
Confronto tra diversi tipi di runtime di integrazione
In Azure Data Factory sono disponibili tre tipi di runtime di integrazione: il runtime di integrazione di Azure, il runtime di integrazione self-hosted e il runtime di integrazione SSIS di Azure. Per il runtime di integrazione di Azure, è anche possibile abilitare una rete virtuale gestita, che ne rende l'architettura diversa rispetto al runtime di integrazione di Azure globale.
Questa tabella elenca le differenze in alcuni aspetti di tutti i runtime di integrazione. È possibile scegliere quello appropriato in base alle esigenze effettive. Per il runtime di integrazione Azure-SSIS, è possibile ottenere altre informazioni nell'articolo Creare un runtime di integrazione SSIS di Azure.
| Funzionalità | Runtime di integrazione di Azure | Runtime di integrazione di Azure con rete virtuale gestita | Runtime di integrazione self-hosted |
|---|---|---|---|
| Calcolo gestito | S | Y | N |
| Autoscale | Y | Y* | N |
| Flusso di dati | S | Y | N |
| Accesso ai dati locali | N | Y** | Y |
| collegamento privato/endpoint privato | N | Y*** | Y |
| Componente/driver personalizzato | N | N | Y |
* Quando la durata (TTL) è abilitata, le dimensioni di calcolo del runtime di integrazione sono riservate in base alla configurazione e non possono essere ridimensionate automaticamente.
** Gli ambienti locali devono essere connessi ad Azure tramite ExpressRoute o VPN. I componenti e i driver personalizzati non sono supportati.
Gli endpoint privati vengono gestiti dal servizio Azure Data Factory.
È importante scegliere un tipo appropriato di runtime di integrazione. Non solo deve essere adatto per l'architettura e i requisiti esistenti per l'integrazione dei dati, ma è anche necessario considerare come soddisfare ulteriormente le esigenze aziendali crescenti e qualsiasi aumento futuro del carico di lavoro. Ma non c'è un approccio adatto a tutte le dimensioni. La considerazione seguente consente di esplorare la decisione:
Quali sono i percorsi del runtime di integrazione e dell'archivio dati?
Il percorso del runtime di integrazione definisce la posizione del calcolo back-end e la posizione in cui vengono eseguiti lo spostamento dei dati, l'invio di attività e la trasformazione dei dati. Per ottenere prestazioni e efficienza di trasmissione migliori, il runtime di integrazione deve essere più vicino all'origine dati o al sink.- Il runtime di integrazione di Azure rileva automaticamente la posizione più adatta in base ad alcune regole (nota anche come autoresolve). Vedere i dettagli qui: Località del runtime di integrazione di Azure.
- Il runtime di integrazione di Azure con una rete virtuale gestita ha la stessa area della data factory. Non può essere risolto automaticamente come il runtime di integrazione di Azure.
- Il runtime di integrazione self-hosted si trova nell'area delle macchine virtuali locali o di Azure.
L'archivio dati è accessibile pubblicamente?
Se l'archivio dati è accessibile pubblicamente, la differenza tra i diversi tipi di runtime di integrazione non è di grandi dimensioni. Se l'archivio si trova dietro un firewall o in una rete privata, ad esempio una rete locale o virtuale, le scelte migliori sono il runtime di integrazione di Azure con una rete virtuale gestita o il runtime di integrazione self-hosted.- È necessaria una configurazione aggiuntiva, ad esempio collegamento privato Servizio e Load Balancer quando si usa il runtime di integrazione di Azure con una rete virtuale gestita per accedere a un archivio dati protetto da un firewall o in una rete privata. È possibile fare riferimento a questa esercitazione Accedere a SQL Server locale dalla rete virtuale gestita di Data Factory usando un endpoint privato come esempio. Se l'archivio dati si trova in un ambiente locale, l'ambiente locale deve essere connesso ad Azure tramite ExpressRoute o una VPN da sito a sito.
- Il runtime di integrazione self-hosted è più flessibile e non richiede impostazioni aggiuntive, ExpressRoute o VPN. Ma è necessario fornire e gestire il computer manualmente.
- È anche possibile aggiungere gli indirizzi IP pubblici del runtime di integrazione di Azure all'elenco di indirizzi consentiti del firewall e consentire l'accesso all'archivio dati, ma non è una soluzione auspicabile in ambienti di produzione altamente sicuri.
Quale livello di sicurezza è necessario durante la trasmissione dei dati?
Se è necessario elaborare dati estremamente riservati, è necessario difendersi, ad esempio, attacchi man-in-the-middle durante la trasmissione dei dati. È quindi possibile scegliere di usare un endpoint privato e collegamento privato per garantire la sicurezza dei dati.- È possibile creare endpoint privati gestiti negli archivi dati quando si usa il runtime di integrazione di Azure con una rete virtuale gestita. Gli endpoint privati vengono gestiti dal servizio Azure Data Factory all'interno della rete virtuale gestita.
- È anche possibile creare endpoint privati nella rete virtuale e il runtime di integrazione self-hosted può usarli per accedere agli archivi dati.
- Il runtime di integrazione di Azure non supporta endpoint privato e collegamento privato.
Quale livello di manutenzione è possibile fornire?
La gestione dell'infrastruttura, dei server e delle apparecchiature è una delle attività importanti del reparto IT di un'azienda. In genere richiede molto tempo e fatica.- Non è necessario preoccuparsi della manutenzione, ad esempio aggiornamento, patch e versione del runtime di integrazione di Azure e del runtime di integrazione di Azure con una rete virtuale gestita. Il servizio Azure Data Factory si occupa di tutte le attività di manutenzione.
- Poiché il runtime di integrazione self-hosted è installato nei computer dei clienti, la manutenzione deve essere gestita dagli utenti finali. È tuttavia possibile abilitare l'aggiornamento automatico per ottenere automaticamente la versione più recente del runtime di integrazione self-hosted ogni volta che è presente un aggiornamento. Per informazioni su come abilitare l'aggiornamento automatico e gestire il controllo della versione del runtime di integrazione self-hosted, è possibile fare riferimento all'articolo Aggiornamento automatico e scadenza del runtime di integrazione self-hosted. Viene inoltre fornito uno strumento di diagnostica per il runtime di integrazione self-hosted per verificare l'integrità di alcuni problemi comuni. Per altre informazioni sullo strumento di diagnostica, vedere l'articolo Strumento di diagnostica del runtime di integrazione self-hosted. È anche consigliabile usare Monitoraggio di Azure e Azure Log Analytics specificamente per raccogliere tali dati e abilitare un singolo riquadro di monitoraggio per i runtime di integrazione self-hosted. Per altre informazioni sulla configurazione, vedere l'articolo Configurare il runtime di integrazione self-hosted per la raccolta di Log Analytics per istruzioni.
Quali requisiti di concorrenza sono disponibili?
Quando si elaborano dati su larga scala, ad esempio la migrazione dei dati su larga scala, si spera di migliorare l'efficienza e la velocità di elaborazione il più possibile. La concorrenza è spesso un requisito importante per l'integrazione dei dati.- Il runtime di integrazione di Azure ha il supporto di concorrenza più elevato tra tutti i tipi di runtime di integrazione. L'unità di integrazione dei dati (DIU) è l'unità di funzionalità da eseguire in Azure Data Factory. È possibile selezionare il numero desiderato di unità di distribuzione, ad esempio, attività Copy. Nell'ambito di DIU è possibile eseguire più attività contemporaneamente. Per gruppi di aree diverse, si avranno limitazioni superiori diverse. Informazioni sui dettagli di questi limiti nell'articolo Limiti di Data Factory.
- Il runtime di integrazione di Azure con una rete virtuale gestita ha un meccanismo simile al runtime di integrazione di Azure, ma a causa di alcuni vincoli architetturali, la concorrenza che può supportare è inferiore al runtime di integrazione di Azure.
- Le attività simultanee che il runtime di integrazione self-hosted può eseguire dipendono dalle dimensioni del computer e dal cluster. È possibile scegliere un computer di dimensioni maggiori o usare più nodi di integrazione self-hosted nel cluster se è necessaria una maggiore concorrenza.
Sono necessarie funzionalità specifiche?
Esistono alcune differenze funzionali tra i tipi di runtime di integrazione.- Il flusso di dati è supportato dal runtime di integrazione di Azure e dal runtime di integrazione di Azure con una rete virtuale gestita. Tuttavia, non è possibile eseguire flussi di dati usando il runtime di integrazione self-hosted.
- Se è necessario installare componenti personalizzati, ad esempio driver ODBC, JVM o un certificato di SQL Server, il runtime di integrazione self-hosted è l'unica opzione. I componenti personalizzati non sono supportati dal runtime di integrazione di Azure o dal runtime di integrazione di Azure con una rete virtuale gestita.
Architettura per il runtime di integrazione
In base alle caratteristiche di ogni runtime di integrazione, sono necessarie architetture diverse per soddisfare le esigenze aziendali di integrazione dei dati. Di seguito sono riportate alcune architetture tipiche che possono essere usate come riferimento.
Runtime di integrazione di Azure
Il runtime di integrazione di Azure è un ambiente di calcolo con scalabilità automatica completamente gestito che è possibile usare per spostare dati da Azure o da origini dati non Di Azure.
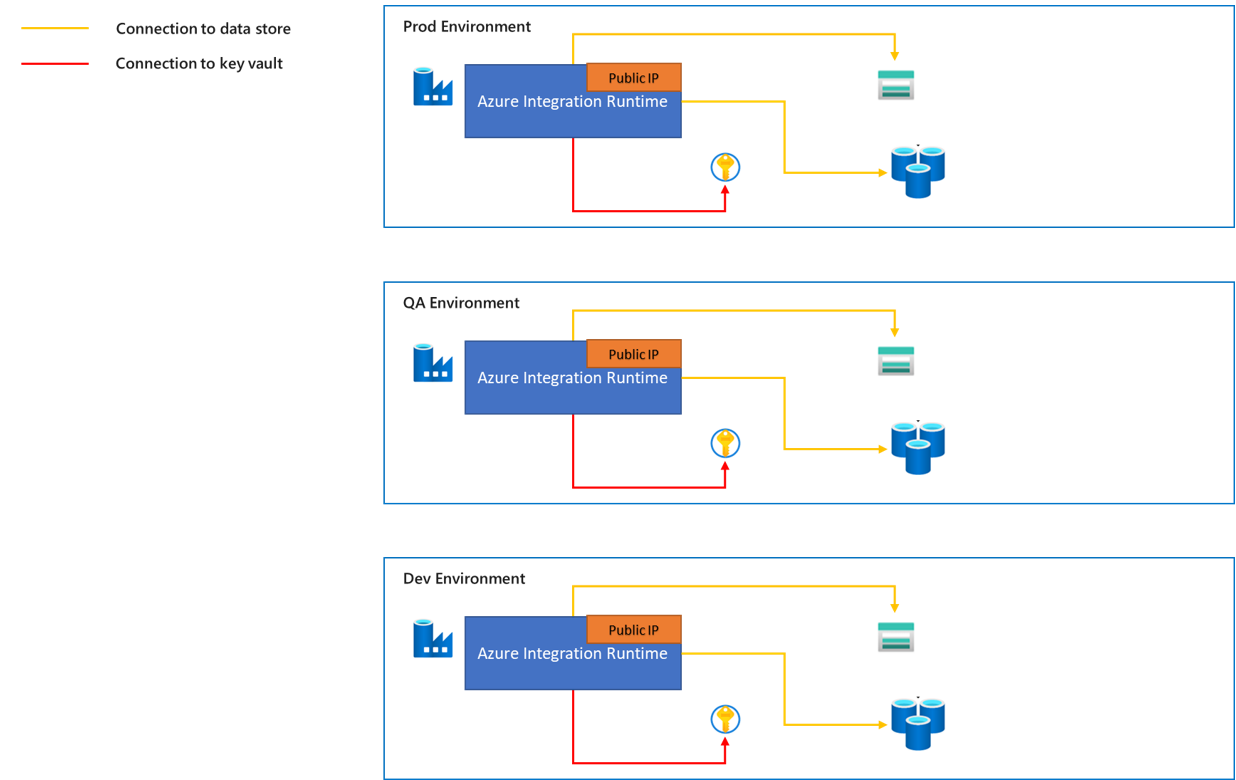
- Il traffico dal runtime di integrazione di Azure agli archivi dati è attraverso la rete pubblica.
- È disponibile un intervallo di indirizzi IP pubblici statici per il runtime di integrazione di Azure e questi indirizzi IP possono essere aggiunti all'elenco consenti del firewall dell'archivio dati di destinazione. Per altre informazioni su come ottenere indirizzi IP pubblici del runtime di integrazione di Azure, vedere l'articolo Indirizzi IP di Azure Integration Runtime.
- Il runtime di integrazione di Azure può essere risolto in modo automatico in base all'area dell'origine dati e del sink di dati. In alternativa, è possibile scegliere un'area specifica. È consigliabile scegliere l'area più vicina all'origine dati o al sink, che può offrire prestazioni di esecuzione migliori. Altre informazioni sulle considerazioni sulle prestazioni sono disponibili nell'articolo Risolvere i problemi relativi all'attività di copia in Azure IR.
Runtime di integrazione di Azure con rete virtuale gestita
Quando si usa il runtime di integrazione di Azure con una rete virtuale gestita, è consigliabile usare endpoint privati gestiti per connettere le origini dati per garantire la sicurezza dei dati durante la trasmissione. Con alcune impostazioni aggiuntive, ad esempio collegamento privato Servizio e Load Balancer, gli endpoint privati gestiti possono essere usati anche per accedere alle origini dati locali.

- Un endpoint privato gestito non può essere riutilizzato in ambienti diversi. È necessario creare un set di endpoint privati gestiti per ogni ambiente. Per tutte le origini dati supportate dagli endpoint privati gestiti, vedere l'articolo Origini dati e servizi supportati.
- È anche possibile usare endpoint privati gestiti per le connessioni a risorse di calcolo esterne da orchestrare, ad esempio Azure Databricks e Funzioni di Azure. Per visualizzare l'elenco completo delle risorse di calcolo esterne supportate, vedere l'articolo Origini dati e servizi supportati.
- La rete virtuale gestita viene gestita dal servizio Azure Data Factory. Il peering reti virtuali non è supportato tra una rete virtuale gestita e una rete virtuale del cliente.
- I clienti non possono modificare direttamente le configurazioni, ad esempio la regola del gruppo di sicurezza di rete in una rete virtuale gestita.
- Se una proprietà di un endpoint privato gestito è diversa tra gli ambienti, è possibile eseguirne l'override tramite parametrizzazione di tale proprietà e specificando il rispettivo valore durante la distribuzione. Vedere i dettagli nell'articolo Procedure consigliate per CI/CD.
Runtime di integrazione self-hosted
Per impedire che i dati di ambienti diversi interferiscano tra loro e garantiscano la sicurezza dell'ambiente di produzione, è necessario creare un runtime di integrazione self-hosted corrispondente per ogni ambiente. In questo modo si garantisce un isolamento sufficiente tra ambienti diversi.
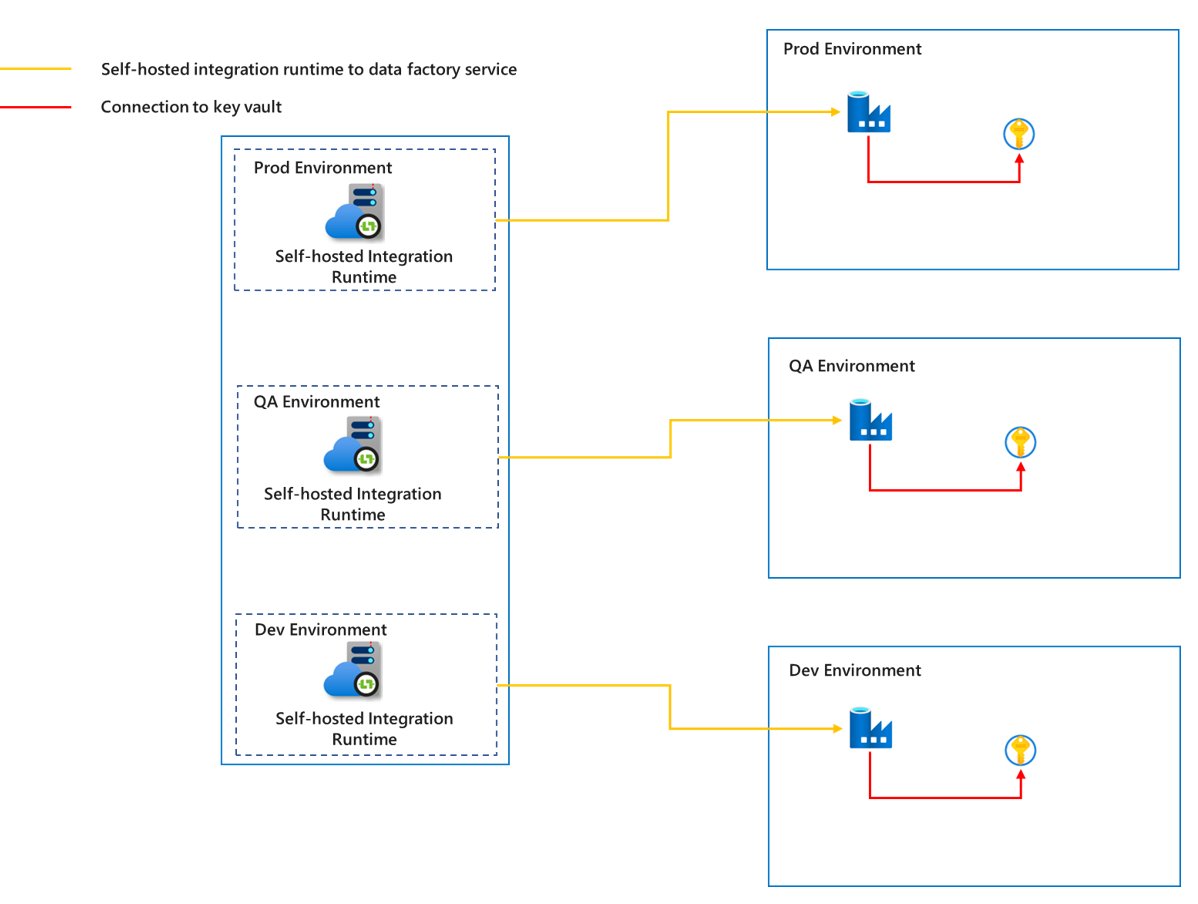
Poiché il runtime di integrazione self-hosted viene eseguito in un computer gestito dal cliente, per ridurre il più possibile i costi, la manutenzione e le attività di aggiornamento, è possibile usare le funzioni condivise del runtime di integrazione self-hosted per progetti diversi nello stesso ambiente. Per informazioni dettagliate sulla condivisione del runtime di integrazione self-hosted, vedere l'articolo Creare un runtime di integrazione self-hosted condiviso in Azure Data Factory. Allo stesso tempo, per rendere i dati più sicuri durante la trasmissione, è possibile scegliere di usare un collegamento privato per connettere le origini dati e l'insieme di credenziali delle chiavi e connettere la comunicazione tra il runtime di integrazione self-hosted e il servizio Azure Data Factory.
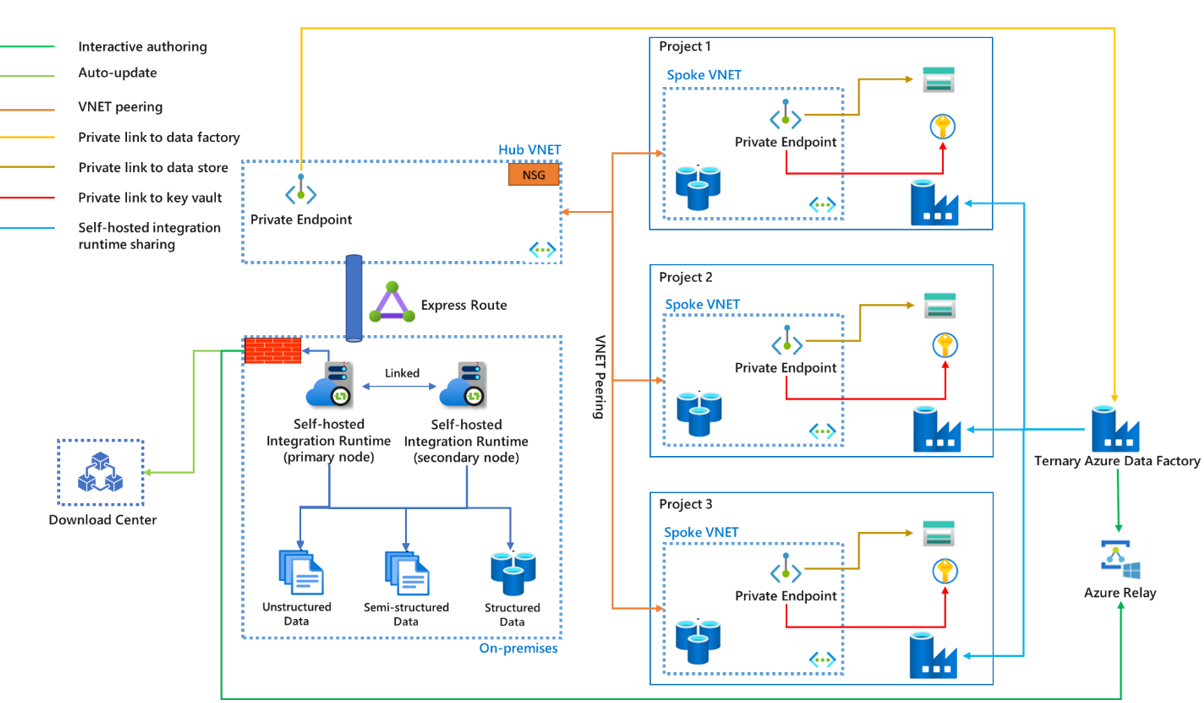
- ExpressRoute non è obbligatorio. Senza ExpressRoute, i dati non raggiungeranno il sink tramite reti private, ad esempio una rete virtuale o un collegamento privato, ma attraverso la rete pubblica.
- Se la rete locale è connessa alla rete virtuale di Azure tramite ExpressRoute o VPN, il runtime di integrazione self-hosted può essere installato nelle macchine virtuali in una rete virtuale hub.
- L'architettura di rete virtuale hub-spoke può essere usata non solo per progetti diversi, ma anche per ambienti diversi (Prod, QA e Dev).
- Il runtime di integrazione self-hosted può essere condiviso con più data factory. La data factory primaria vi fa riferimento come runtime di integrazione self-hosted condiviso e altri fanno riferimento a esso come runtime di integrazione self-hosted collegato. Un runtime di integrazione self-hosted fisico può avere più nodi in un cluster. La comunicazione avviene solo tra il runtime di integrazione self-hosted primario e il nodo primario, con il lavoro distribuito ai nodi secondari dal nodo primario.
- Le credenziali degli archivi dati locali possono essere archiviate nel computer locale o in un insieme di credenziali delle chiavi di Azure. Azure Key Vault è altamente consigliato.
- La comunicazione tra il runtime di integrazione self-hosted e la data factory può passare attraverso un collegamento privato. Attualmente, tuttavia, la creazione interattiva tramite Inoltro di Azure e l'aggiornamento automatico alla versione più recente dall'area download non supportano il collegamento privato. Il traffico passa attraverso il firewall dell'ambiente locale. Per altre informazioni, vedere l'articolo collegamento privato di Azure per Azure Data Factory.
- Il collegamento privato è necessario solo per la data factory primaria. Tutto il traffico passa attraverso la data factory primaria, quindi verso altre data factory.
- È previsto lo stesso nome del runtime di integrazione self-hosted in tutte le fasi di CI/CD. È possibile prendere in considerazione l'uso di una factory ternaria solo per contenere i runtime di integrazione self-hosted condivisi e usare il runtime di integrazione self-hosted collegato nelle varie fasi di produzione. Per altre informazioni, vedere l'articolo Integrazione e recapito continui.
- È possibile controllare il modo in cui il traffico passa all'area download e all'inoltro di Azure usando le configurazioni della rete locale ed ExpressRoute, tramite un proxy locale o una rete virtuale hub. Assicurarsi che il traffico sia consentito dalle regole del proxy o del gruppo di sicurezza di rete.
- Se si vuole proteggere la comunicazione tra nodi del runtime di integrazione self-hosted, è possibile abilitare l'accesso remoto dalla intranet con un certificato TLS/SSL. Per altre informazioni, vedere l'articolo Abilitare l'accesso remoto dalla Intranet con il certificato TLS/SSL (Avanzato).