Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
APPLICABILE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Data Factory in Microsoft Fabric è la nuova generazione di Azure Data Factory, con un'architettura più semplice, un'intelligenza artificiale predefinita e nuove funzionalità. Se non si ha familiarità con l'integrazione dei dati, iniziare con Fabric Data Factory. I carichi di lavoro di Azure Data Factory esistenti possono eseguire l'aggiornamento a Fabric per accedere a nuove funzionalità tra data science, analisi in tempo reale e creazione di report.
Questo articolo illustra come risolvere i problemi di prestazioni dell'attività di copia in Azure Data Factory.
Dopo aver eseguito un'attività di copia, è possibile raccogliere i risultati dell'esecuzione e le statistiche sulle prestazioni nella visualizzazione di monitoraggio dell'attività di copia. Nell'immagine seguente è riportato un esempio.
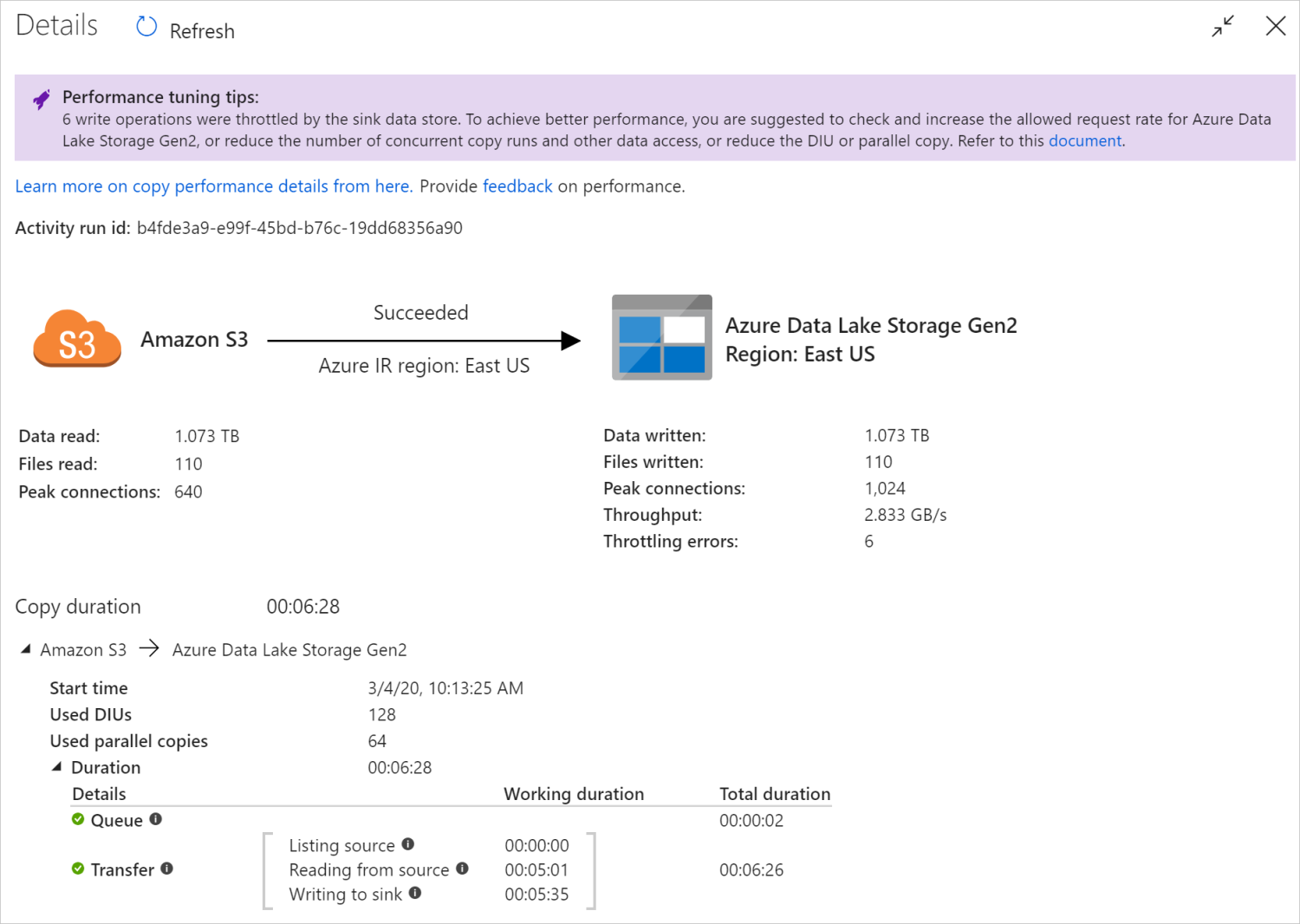
Suggerimenti per l'ottimizzazione delle prestazioni
In alcuni scenari, quando si esegue un'attività di copia, vengono visualizzati "Suggerimenti per l'ottimizzazione delle prestazioni" nella parte superiore, come illustrato nell'immagine precedente. I suggerimenti indicano il collo di bottiglia identificato dal servizio per questa particolare esecuzione della copia, insieme ai suggerimenti su come aumentare la velocità effettiva della copia. Provare a apportare la modifica consigliata, quindi eseguire di nuovo la copia.
Come riferimento, attualmente i suggerimenti per l'ottimizzazione delle prestazioni forniscono suggerimenti per i casi seguenti:
| Categoria | Suggerimenti per l'ottimizzazione delle prestazioni |
|---|---|
| Archivio dati specifico | Caricamento dei dati in Azure Synapse Analytics: si consiglia di usare l'istruzione PolyBase o COPY se non viene utilizzata. |
| Copia di dati da/a Azure SQL Database: quando il DTU è in alta utilizzazione, suggerire di effettuare l'aggiornamento a un livello superiore. | |
| Copia di dati da/a Azure Cosmos DB: quando le UR sono sotto utilizzo elevato, suggerire l'aggiornamento a UR più grandi. | |
| Copia dei dati dalla tabella SAP: quando si copia una grande quantità di dati, suggerire l'uso dell'opzione di partizione del connettore SAP per abilitare il caricamento parallelo e aumentare il numero di partizione massimo. | |
| Si consiglia di utilizzare UNLOAD per l'inserimento di dati da Amazon Redshift, se non è già in uso. | |
| Limitazione dell'archivio dati | Se molte operazioni di lettura/scrittura vengono limitate dall'archivio dati durante la copia, suggerire il controllo e aumentare la frequenza di richiesta consentita per l'archivio dati o ridurre il carico di lavoro simultaneo. |
| Runtime di integrazione | Se si utilizza un runtime di integrazione self-hosted e l'attività Copy rimane in coda per un lungo periodo fino a quando il runtime di integrazione non ha risorse disponibili per l'esecuzione, si consiglia di scalare orizzontalmente o verticalmente il runtime di integrazione. |
| Se si utilizza un Azure Integration Runtime in un'area non ottimale con conseguente rallentamento di lettura/scrittura, si consiglia di configurare l'uso di un IR in un'altra area. | |
| Tolleranza di errore | Se si configura la tolleranza di errore e ignorare le righe incompatibili porta a prestazioni lente, è consigliabile verificare che i dati di origine e destinazione siano compatibili. |
| copia di staging | Se la copia a fasi è configurata ma non è utile per la coppia sorgente-sink, suggerire di rimuoverla. |
| Riprendi | Quando l'attività di copia viene ripresa dall'ultimo punto di errore, ma si modifica l'impostazione DIU dopo l'esecuzione originale, si noti che la nuova impostazione DIU non ha effetto. |
Comprendere i dettagli dell'esecuzione dell'attività di copia
I dettagli e le durate dell'esecuzione nella parte inferiore della visualizzazione di monitoraggio dell'attività di copia descrivono le fasi principali che l'attività di copia passa attraverso (vedere l'esempio all'inizio di questo articolo), che è particolarmente utile per la risoluzione dei problemi relativi alle prestazioni della copia. Il collo di bottiglia del processo di copia è quello che richiede più tempo. Fare riferimento alla tabella seguente sulla definizione di ogni fase e apprendere come risolvere i problemi dell'attività di copia su Azure IR e risolvere i problemi dell'attività di copia su Self-hosted IR con tali informazioni.
| Fase | Descrizione |
|---|---|
| Coda | Tempo trascorso fino all'avvio effettivo dell'attività di copia nel runtime di integrazione. |
| Script di precopy | Tempo trascorso tra l'inizio dell'attività Copy sul runtime di integrazione e il termine dell'attività Copy che sta eseguendo lo script di precopy nell'archivio sink. Si applica quando si configura lo script di precopy per i sink di database; ad esempio, quando si scrivono dati in database SQL di Azure, è necessario eseguire la pulizia prima di copiare nuovi dati. |
| Trasferimento | Tempo trascorso tra la fine del passaggio precedente e il runtime di integrazione che trasferisce tutti i dati dall'origine al sink. Si noti che i passaggi secondari in fase di trasferimento vengono eseguiti in parallelo e alcune operazioni non vengono ora visualizzate, ad esempio, il formato di file di analisi/generazione. - Tempo al primo byte: il tempo trascorso tra la fine del passaggio precedente e il momento in cui l'IR riceve il primo byte dall'archivio dati di origine. Si applica alle origini non basate su file. - Elenco origine: quantità di tempo impiegato per enumerare file di origine o partizioni di dati. Quest'ultimo si applica quando si configurano le opzioni di partizione per le origini di database, ad esempio quando si copiano dati da database come Oracle/SAP HANA/Teradata/Netezza/etc. - Lettura dall'origine: quantità di tempo impiegato per il recupero dei dati dall'archivio dati di origine. - Scrittura nel sink: quantità di tempo impiegato per la scrittura di dati nell'archivio dati sink. Si noti che alcuni connettori non hanno questa metrica al momento, tra cui Azure AI Search, Azure Data Explorer, archiviazione tabelle Azure, Oracle, SQL Server, Common Data Service, Dynamics 365, Dynamics CRM, Salesforce/Salesforce Service Cloud. |
Risoluzione dei problemi relativi all'attività di copia su Azure IR
Seguire i passaggi di ottimizzazione delle prestazioni per pianificare ed eseguire test delle prestazioni per lo scenario.
Quando le prestazioni dell'attività di copia non soddisfano le aspettative, per risolvere i problemi relativi alle singole attività di copia in esecuzione su Azure Integration Runtime, se vengono visualizzati suggerimenti per l'ottimizzazione delle prestazioni visualizzati nella visualizzazione di monitoraggio della copia, applicare il suggerimento e riprovare. In caso contrario, comprendere i dettagli dell'esecuzione dell'attività di copia, controllare quale fase ha la durata più lunga e applicare le indicazioni seguenti per migliorare le prestazioni di copia:
Durata prolungata dello script di pre-copia: significa che lo script di pre-copia in esecuzione nel database del sink impiega molto tempo per finire. Affinare la logica dello script di precopy specificato per migliorare le prestazioni. Per ulteriori informazioni sul miglioramento dello script, contattare il team del database.
"Trasferimento - Tempo al primo byte" ha avuto una durata operativa prolungata: la query di origine impiega molto tempo per restituire qualsiasi dato. Ciò potrebbe significare che la query richiede molto tempo per l'elaborazione nell'origine perché l'origine è occupata con altre attività o la query non è ottimale oppure i dati vengono archiviati in modo da richiedere molto tempo per il recupero. Valutare se altre query vengono eseguite contemporaneamente su tale origine o se sono presenti aggiornamenti che è possibile apportare alla query in modo da poter recuperare i dati più rapidamente. Se è presente un team che gestisce l'origine dati, contattarli per modificare la query o controllare le prestazioni dell'origine.
"Trasferimento - Elenco dell'origine" ha riscontrato una lunga durata operativa: significa che l'enumerazione dei file di origine o delle partizioni di dati del database di origine è lenta.
Quando si copiano dati da un'origine basata su file, se si usa il filtro con caratteri jolly per il percorso della cartella o il nome file (
wildcardFolderPathowildcardFileName) oppure si usa il filtro ora dell'ultima modifica del file (modifiedDatetimeStartomodifiedDatetimeEnd), si noti che tale filtro fa sì che attività Copy elenchi tutti i file nella cartella specificata sul lato client, quindi applica il filtro. Tale enumerazione di file potrebbe diventare il collo di bottiglia soprattutto quando solo un piccolo set di file soddisfa la regola di filtro.Controllare se è possibile copiare i file in base al percorso o al nome del file partizionato datetime. In questo modo non grava sul lato sorgente dell'elenco.
Controllare se è possibile utilizzare i filtri nativi dell'archivio di dati, in particolare "prefisso" per Amazon S3/Archiviazione BLOB di Azure/File di Azure e "listAfter/listBefore" per ADLS Gen1. Questi filtri sono filtri lato server dell'archivio dei dati e offrono prestazioni migliori.
Prendere in considerazione la possibilità di suddividere un unico set di dati di grandi dimensioni in diversi set di dati più piccoli e consentire l'esecuzione simultanea dei processi di copia, ciascuno dei quali affronta una porzione di dati. È possibile eseguire questa operazione con Lookup/GetMetadata + ForEach + Copy. Vedere Copiare file da più contenitori o Eseguire la migrazione dei dati da Amazon S3 ai modelli di soluzione ADLS Gen2 come esempio generale.
Controllare se il servizio segnala eventuali errori di limitazione nell'origine o se l'archivio dati è in stato di utilizzo elevato. In tal caso, ridurre i carichi di lavoro nell'archivio dati o contattare l'amministratore dell'archivio dati per aumentare il limite di limitazione o la risorsa disponibile.
Usare il runtime di integrazione di Azure nella stessa area o in un'area vicina all'archivio dati di origine.
"Trasferimento - lettura dall'origine" ha avuto una lunga durata operativa:
Adottare le procedure consigliate per il caricamento dei dati specifiche del connettore, se applicabile. Ad esempio, quando si copiano dati da Amazon Redshift, configurare per l'uso di Redshift UNLOAD.
Controllare se il servizio segnala eventuali errori di limitazione nell'origine o se l'archivio dati è in stato di utilizzo elevato. In tal caso, ridurre i carichi di lavoro nell'archivio dati o contattare l'amministratore dell'archivio dati per aumentare il limite di limitazione o la risorsa disponibile.
Controllare il modello di origine e sink di copia:
Se il modello di copia supporta più di quattro Data Integration Units (DIUs), fare riferimento a questa sezione per i dettagli, in genere è possibile provare ad aumentare i DIU per ottenere prestazioni migliori.
In caso contrario, considerare di dividere un singolo set di dati di grandi dimensioni in diversi set di dati più piccoli e lasciare che questi lavori di copia vengano eseguiti contemporaneamente, ciascuno affrontando una porzione di dati. È possibile eseguire questa operazione con Lookup/GetMetadata + ForEach + Copy. Fare riferimento a Copiare file da più contenitori, Eseguire la migrazione dei dati da Amazon S3 ad ADLS Gen2 o Eseguire la copia bulk con modelli di soluzione di tabella dei controlli come esempio generale.
Usare il runtime di integrazione di Azure nella stessa area o in un'area vicina all'archivio dati di origine.
"Trasferimento - scrittura nel sink" ha riscontrato un lungo tempo di esecuzione
Adottare le procedure consigliate per il caricamento dei dati specifiche del connettore, se applicabile. Ad esempio, quando si copiano dati in Azure Synapse Analytics, usare l'istruzione PolyBase o COPY.
Controllare se il servizio segnala eventuali errori di limitazione nel sink o se l'archivio dati è in stato di utilizzo elevato. In tal caso, ridurre i carichi di lavoro nell'archivio dati o contattare l'amministratore dell'archivio dati per aumentare il limite di limitazione o la risorsa disponibile.
Controllare il modello di origine e sink di copia:
Se il modello di copia supporta più di quattro Data Integration Units (DIUs), fare riferimento a questa sezione per i dettagli, in genere è possibile provare ad aumentare i DIU per ottenere prestazioni migliori.
In caso contrario, regolare gradualmente le copie parallele. Troppi copie parallele potrebbero anche danneggiare le prestazioni.
Usare il runtime di integrazione di Azure nella stessa area o in un'area vicina all'archivio dati del sink.
Risolvere i problemi relativi all'attività Copy nel runtime di integrazione self-hosted
Seguire i passaggi di ottimizzazione delle prestazioni per pianificare ed eseguire test delle prestazioni per lo scenario.
Quando le prestazioni della copia non soddisfano le tue aspettative, per risolvere i problemi relativi ad un'attività di copia singola in esecuzione su Azure Integration Runtime, se nella visualizzazione di monitoraggio della copia compaiono suggerimenti per l'ottimizzazione delle prestazioni, applica il suggerimento e riprova. In caso contrario, comprendere i dettagli dell'esecuzione dell'attività di copia, controllare quale fase ha la durata più lunga e applicare le indicazioni seguenti per migliorare le prestazioni di copia:
"Coda" ha avuto una lunga durata: significa che l'attività Copy attende molto tempo nella coda fino a quando il runtime di integrazione self-hosted non dispone delle risorse necessarie per l'esecuzione. Controllare la capacità di integrazione e l'utilizzo del runtime di integrazione, e ridimensionare orizzontalmente o verticalmente in base al carico di lavoro.
"Trasferimento - Tempo al primo byte" ha avuto una durata operativa prolungata: significa che la query di origine impiega molto tempo per restituire qualsiasi dato. Controllare e ottimizzare l'interrogazione o il server. Per altre informazioni, contattare il team dell'archivio dati.
"Trasferimento - Elenco dell'origine" ha riscontrato una lunga durata operativa: significa che l'enumerazione dei file di origine o delle partizioni di dati del database di origine è lenta.
Controllare se il computer del runtime di integrazione self-hosted ha una bassa latenza a connettersi all'archivio dati di origine. Se l'origine è in Azure, è possibile usare questo strumento per controllare la latenza dal computer del runtime di integrazione self-hosted all'area di Azure, meno è meglio.
Quando si copiano dati da un'origine basata su file, se si usa il filtro con caratteri jolly per il percorso della cartella o il nome file (
wildcardFolderPathowildcardFileName) oppure si usa il filtro ora dell'ultima modifica del file (modifiedDatetimeStartomodifiedDatetimeEnd), si noti che tale filtro fa sì che attività Copy elenchi tutti i file nella cartella specificata sul lato client, quindi applica il filtro. Tale enumerazione di file potrebbe diventare il collo di bottiglia soprattutto quando solo un piccolo set di file soddisfa la regola di filtro.Controllare se è possibile copiare i file in base al percorso o al nome del file partizionato datetime. In questo modo non grava sul lato sorgente dell'elenco.
Controllare se è possibile utilizzare i filtri nativi dell'archivio di dati, in particolare "prefisso" per Amazon S3/Archiviazione BLOB di Azure/File di Azure e "listAfter/listBefore" per ADLS Gen1. Questi filtri sono filtri lato server dell'archivio dei dati e offrono prestazioni migliori.
Prendere in considerazione la possibilità di suddividere un unico set di dati di grandi dimensioni in diversi set di dati più piccoli e consentire l'esecuzione simultanea dei processi di copia, ciascuno dei quali affronta una porzione di dati. È possibile eseguire questa operazione con Lookup/GetMetadata + ForEach + Copy. Vedere Copiare file da più contenitori o Eseguire la migrazione dei dati da Amazon S3 ai modelli di soluzione ADLS Gen2 come esempio generale.
Controllare se il servizio segnala eventuali errori di limitazione nell'origine o se l'archivio dati è in stato di utilizzo elevato. In tal caso, ridurre i carichi di lavoro nell'archivio dati o contattare l'amministratore dell'archivio dati per aumentare il limite di limitazione o la risorsa disponibile.
"Trasferimento - lettura dall'origine" ha avuto una lunga durata operativa:
Controllare se il computer del runtime di integrazione self-hosted ha una bassa latenza a connettersi all'archivio dati di origine. Se l'origine è in Azure, è possibile usare questo strumento per controllare la latenza dal computer del runtime di integrazione self-hosted alla aree di Azure, meno è meglio.
Controllare se il computer del runtime di integrazione self-hosted dispone di una larghezza di banda in ingresso sufficiente per leggere e trasferire i dati in modo efficiente. Se l'archivio dati di origine si trova in Azure, è possibile usare questo strumento per controllare la velocità di download.
Controllare l'andamento dell'utilizzo della CPU e della memoria del runtime di integrazione self-hosted nel portale di Azure> nella pagina di panoramica del data factory o dell'area di lavoro di Synapse>. Considerare di aumentare/espandere IR se l'utilizzo della CPU è elevato o la memoria disponibile è insufficiente.
Se applicabile, adottare le migliori pratiche per il caricamento dei dati specifiche del connettore. Ad esempio:
Quando si copiano dati da Oracle, Netezza, Teradata, SAP HANA, SAP Table e SAP Open Hub, abilitare le opzioni di partizionamento dei dati per copiarli in parallelo.
Quando si copiano dati da HDFS, configurare per l'uso di DistCp.
Quando si copiano i dati da Amazon Redshift, configurare l'uso di UNLOAD di Redshift.
Controllare se il servizio segnala eventuali errori di limitazione nell'origine o se l'archivio dati è in stato di utilizzo elevato. In tal caso, ridurre i carichi di lavoro nell'archivio dati o contattare l'amministratore dell'archivio dati per aumentare il limite di limitazione o la risorsa disponibile.
Controllare il modello di origine e sink di copia:
Se si copiano dati da archivi dati abilitati per l'opzione di partizione, valutare la possibilità di ottimizzare gradualmente le copie parallele. Troppi copie parallele potrebbero anche danneggiare le prestazioni.
In caso contrario, considerare di dividere un singolo set di dati di grandi dimensioni in diversi set di dati più piccoli e lasciare che questi lavori di copia vengano eseguiti contemporaneamente, ciascuno affrontando una porzione di dati. È possibile eseguire questa operazione con Lookup/GetMetadata + ForEach + Copy. Fare riferimento a Copiare file da più contenitori, Eseguire la migrazione dei dati da Amazon S3 ad ADLS Gen2 o Eseguire la copia bulk con modelli di soluzione di tabella dei controlli come esempio generale.
"Trasferimento - scrittura nel sink" ha riscontrato un lungo tempo di esecuzione
Adottare le procedure consigliate per il caricamento dei dati specifiche del connettore, se applicabile. Ad esempio, quando si copiano dati in Azure Synapse Analytics, usare l'istruzione PolyBase o COPY.
Controllare se il computer del runtime di integrazione self-hosted ha una bassa latenza a connettersi all'archivio dati del sink. Se il sink è in Azure, è possibile usare questo strumento per controllare la latenza dal computer del runtime di integrazione self-hosted all'area di Azure, meno è meglio.
Controllare se il computer del runtime di integrazione self-hosted dispone di una larghezza di banda in uscita sufficiente per trasferire e scrivere i dati in modo efficiente. Se l'archivio dati sink si trova in Azure, è possibile usare questo strumento per controllare la velocità di caricamento.
Controllare l'andamento dell'utilizzo della CPU e della memoria del runtime di integrazione self-hosted nel portale di Azure> nella pagina di panoramica del data factory o dell'area di lavoro di Synapse>. Considerare di aumentare/espandere IR se l'utilizzo della CPU è elevato o la memoria disponibile è insufficiente.
Controllare se il servizio segnala eventuali errori di limitazione nel sink o se l'archivio dati è in stato di utilizzo elevato. In tal caso, ridurre i carichi di lavoro nell'archivio dati o contattare l'amministratore dell'archivio dati per aumentare il limite di limitazione o la risorsa disponibile.
Prendere in considerazione la possibilità di ottimizzare gradualmente le copie parallele. Troppi copie parallele potrebbero anche danneggiare le prestazioni.
Prestazioni del connettore e dell'IR
Questa sezione illustra alcune guide alla risoluzione dei problemi relativi alle prestazioni per un particolare tipo di connettore o runtime di integrazione.
Il tempo di esecuzione dell'attività varia utilizzando Azure IR rispetto ad Azure Virtual Network IR.
Il tempo di esecuzione dell'attività varia quando il set di dati si basa su Integration Runtime diversi.
Sintomi: basta alternare il menu a discesa del Servizio collegato nel set di dati per eseguire le stesse attività della pipeline, ma con tempi di esecuzione drasticamente diversi. Quando il set di dati si basa sul Virtual Network Integration Runtime gestito, richiede più tempo in media rispetto all'esecuzione quando si basa sul Integration Runtime predefinito.
Causa: controllando i dettagli delle esecuzioni della pipeline, è possibile notare che la pipeline lenta è in esecuzione nel runtime di integrazione della rete virtuale gestita, mentre quella normale è in esecuzione su Azure IR. Per impostazione predefinita, il runtime di integrazione della rete virtuale gestita richiede un tempo di attesa in coda più lungo rispetto ad Azure IR, perché non si riserva un nodo di calcolo per ogni istanza del servizio, quindi è presente un riscaldamento per ogni attività di copia da avviare, e si verifica principalmente nel join della rete virtuale anziché in Azure IR.
Prestazioni ridotte durante il caricamento dei dati in Azure SQL Database
Symptoms: la copia dei dati in Azure SQL Database diventa lenta.
Causa: la causa principale del problema è principalmente attivata dal collo di bottiglia del database SQL di Azure. Di seguito sono riportate alcune possibili cause:
Il livello del database Azure SQL non è abbastanza alto.
L'utilizzo di DTU di Azure SQL Database è vicino al 100%. È possibile monitorare le prestazioni e prendere in considerazione l'aggiornamento del livello di Azure SQL Database.
Gli indici non sono impostati correttamente. Rimuovere tutti gli indici prima del caricamento dei dati e ricrearli al termine del caricamento.
WriteBatchSize non è sufficientemente grande per adattarsi alle dimensioni delle righe dello schema. Tentare di ampliare la proprietà per risolvere il problema.
Anziché l'inserimento bulk, viene usata la stored procedure, che dovrebbe avere prestazioni peggiori.
Timeout o rallentamento delle prestazioni durante l'analisi di file di Excel di grandi dimensioni
Sintomi:
Quando si crea Excel set di dati e si importa lo schema da connessioni/archivi, dati di anteprima, elenco o fogli di lavoro di aggiornamento, è possibile riscontrare un errore di timeout se il file excel è di grandi dimensioni.
Quando si usa l'attività di copia per copiare dati da un file di Excel di grandi dimensioni (>= 100 MB) in un altro archivio dati, si potrebbe riscontrare un rallentamento delle prestazioni o un problema di OOM.
Causa:
Per operazioni come l'importazione dello schema, l'anteprima dei dati e l'elenco dei fogli di lavoro nel set di dati di Excel. Il timeout è 100 s e statico. Per file di Excel di grandi dimensioni, queste operazioni potrebbero non terminare entro il valore di timeout.
L'attività di copia legge l'intero file Excel in memoria, quindi individua il foglio di lavoro e le celle specificati per leggere i dati. Questo comportamento è dovuto all'SDK sottostante usato dal servizio.
Risoluzione:
Per l'importazione dello schema, è possibile generare un file di esempio più piccolo, ovvero un subset di file originale, e scegliere "Importa schema dal file di esempio" anziché "Importa schema da connessione/archivio".
Per elencare il foglio di lavoro, nell'elenco a discesa del foglio di lavoro è possibile selezionare "Modifica" e immettere invece il nome/indice del foglio.
Per copiare file di Excel di grandi dimensioni (>100 MB) in un altro archivio, è possibile usare l'origine Excel di Data Flow che supporta la lettura in streaming e offre prestazioni migliori.
Problema OOM di lettura di file JSON/Excel/XML di grandi dimensioni
Symptoms: quando si leggono file JSON/Excel/XML di grandi dimensioni si verifica il problema di esaurimento della memoria (OOM) durante l'esecuzione dell'attività.
Causa:
- Per i grandi file XML: Il problema OOM di lettura di grandi file XML è una caratteristica voluta. La causa è che l'intero file XML deve essere letto in memoria perché è un singolo oggetto, quindi viene dedotto lo schema e i dati vengono recuperati.
- Per i grandi file Excel: il problema OOM di lettura di grandi file Excel è intenzionale. La causa è che l'SDK (POI/NPOI) usato deve leggere l'intero file di Excel in memoria, quindi dedurre lo schema e ottenere i dati.
- Per i file JSON di grandi dimensioni: il problema OOM di lettura di file JSON di grandi dimensioni è previsto per design quando il file JSON è costituito da un singolo oggetto.
Raccomandazione: applicare una delle opzioni seguenti per risolvere il problema.
- Opzione-1: registrare un runtime di integrazione self-hosted online con macchine potenti (CPU/memoria elevata) per leggere i dati dal file di grandi dimensioni attraverso l'attività Copy.
- Opzione-2: usare una memoria ottimizzata e un cluster di grandi dimensioni (ad esempio, 48 core) per leggere i dati dal file di grandi dimensioni tramite l'attività del flusso di dati di mapping.
- Opzione-3: suddividere il file di grandi dimensioni in quelli di piccole dimensioni, quindi usare l'attività di copia o mapping del flusso di dati per leggere la cartella.
- Opzione-4: se si è bloccati o si verifica il problema OOM durante la copia della cartella XML/Excel/JSON, usare l'attività foreach + l'attività di copia/flusso di dati per mapping nella pipeline per gestire ogni file o sottocartella.
-
Opzione-5: Altri:
- Nel caso di XML, utilizzare l'attività del Notebook con un cluster ottimizzato per la memoria per leggere i dati dai file se ogni file ha lo stesso schema. Attualmente Spark include implementazioni diverse per gestire xml.
- Per JSON, usare moduli di documento diversi (ad esempio, documento singolo, documento per riga e array di documenti) nelle impostazioni JSON nell'origine del flusso di dati per il mapping. Se il contenuto del file JSON è Document per riga, usa poca memoria.
Altri riferimenti
Ecco i riferimenti al monitoraggio delle prestazioni e all'ottimizzazione per alcuni degli archivi dati supportati:
- Archiviazione Blob di Azure: Obiettivi di scalabilità e prestazioni per l'archiviazione Blob e Checklist di prestazioni e scalabilità per l'archiviazione Blob.
- archiviazione tabelle di Azure: Obiettivi di scalabilità e prestazioni per l'archiviazione tabelle e Lista di controllo per prestazioni e scalabilità per l'archiviazione tabelle.
- Azure SQL Database: è possibile monitoraggio delle prestazioni e controllare la percentuale DTU (Database Transaction Unit).
- Azure Synapse Analytics: la sua funzionalità viene misurata in unità di Data Warehouse (DWU). Vedere Gestire la potenza di calcolo in Azure Synapse Analytics (panoramica).
- Azure Cosmos DB: Livelli di prestazioni in Azure Cosmos DB.
- SQL Server: Monitor e ottimizzare le prestazioni.
- File server locale: Ottimizzazione delle prestazioni per i file server.
Contenuto correlato
Vedere gli altri articoli relativi all'attività di copia: