Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
APPLICABILE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Data Factory in Microsoft Fabric è la nuova generazione di Azure Data Factory, con un'architettura più semplice, un'intelligenza artificiale predefinita e nuove funzionalità. Se non si ha familiarità con l'integrazione dei dati, iniziare con Fabric Data Factory. I carichi di lavoro di Azure Data Factory esistenti possono eseguire l'aggiornamento a Fabric per accedere a nuove funzionalità tra data science, analisi in tempo reale e creazione di report.
Diverse trasformazioni nei flussi di dati di mapping consentono di fare riferimento alle colonne modello in base ai modelli anziché ai nomi di colonna predefiniti. Questa corrispondenza è nota come schemi di colonna. È possibile definire modelli per abbinare le colonne in base al nome, al tipo di dati, al flusso, all'origine o alla posizione, anziché richiedere nomi di campo esatti. Esistono due scenari in cui i modelli di colonna sono utili:
- Se i campi di origine in ingresso cambiano spesso, ad esempio il caso di modifica delle colonne nei file di testo o nei database NoSQL. Questo scenario è noto come deriva dello schema.
- Se si vuole eseguire un'operazione comune su un gruppo di colonne di grandi dimensioni. Ad esempio, se si vuole eseguire il cast di ogni colonna che contiene "totale" nel nome in un tipo double.
Modelli di colonna nella colonna derivata e nell'aggregazione
Per aggiungere un modello di colonna in una colonna derivata, un'aggregazione o una trasformazione finestra, fare clic su Aggiungi sopra l'elenco di colonne o sull'icona del più accanto a una colonna derivata esistente. Scegliere Aggiungi modello di colonna.
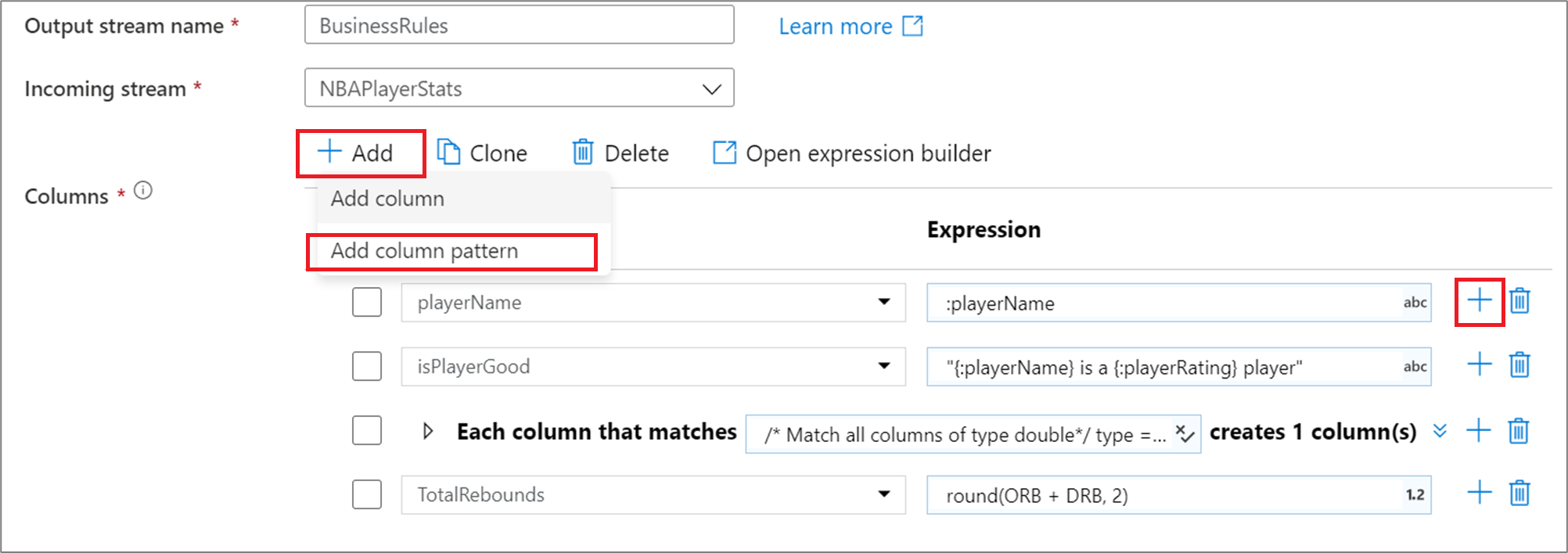
Usare il generatore di espressioni per immettere la condizione di corrispondenza. Creare un'espressione booleana che corrisponda alle colonne in base ai name, type, stream, origin e position della colonna. Il modello influenzerà qualsiasi colonna, derivata o definita, in cui la condizione restituisce vero.
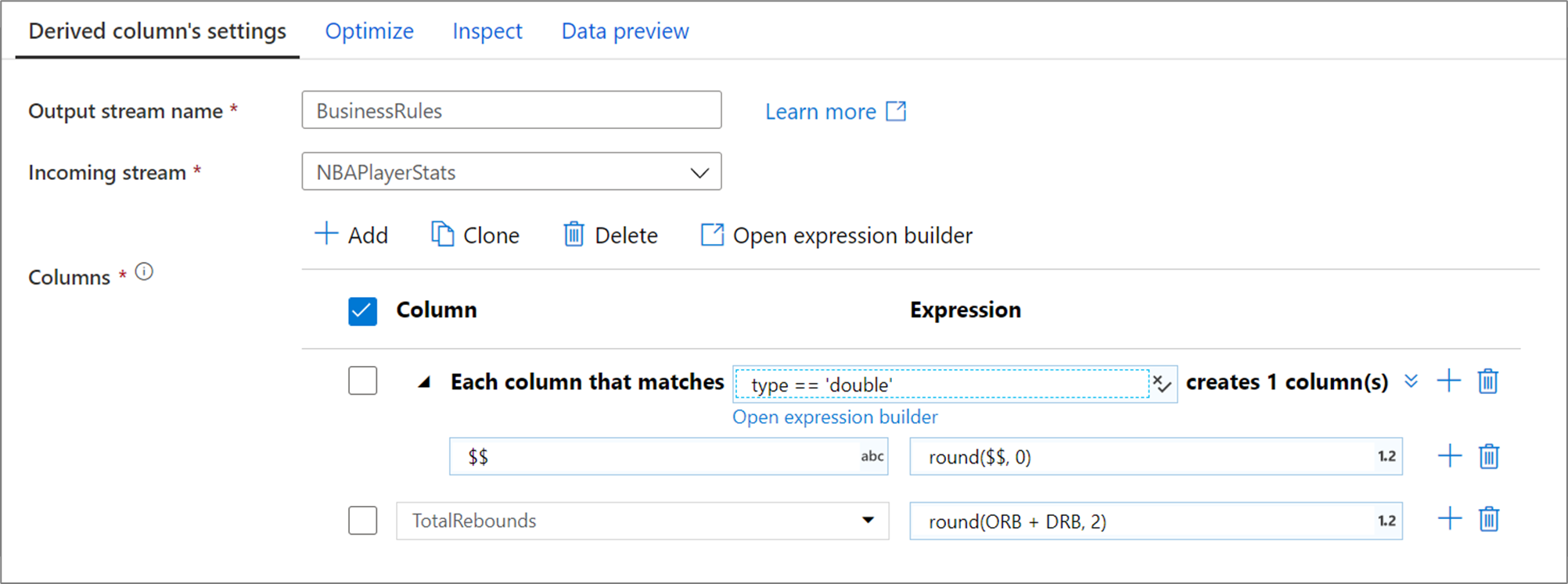
Lo schema di colonna sopra corrisponde a ogni colonna di tipo double e crea una colonna derivata per ogni corrispondenza. Specificando $$ come campo nome colonna, ogni colonna corrispondente viene aggiornata con lo stesso nome. Il valore di ogni colonna è il valore esistente arrotondato a due punti decimali.
Per verificare che la condizione di corrispondenza sia corretta, è possibile convalidare lo schema di output delle colonne definite nella scheda Inspect o ottenere uno snapshot dei dati nella scheda Anteprima dati.
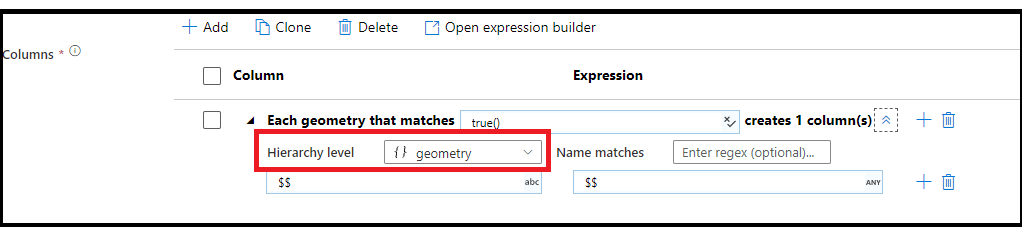
Corrispondenza di modelli gerarchica
È anche possibile creare corrispondenza di modelli all'interno di strutture gerarchiche complesse. Espandere la sezione Each MoviesStruct that matches in cui verrà richiesto di immettere ogni gerarchia nel flusso di dati. È quindi possibile creare modelli di corrispondenza per le proprietà all'interno della gerarchia scelta.
Appianamento delle strutture
Quando i dati hanno strutture complesse come matrici, strutture gerarchiche e mappe, è possibile usare la trasformazione Flatten per espandere le matrici e denormalizzare i dati. Per strutture e mappe, usare la trasformazione colonna derivata con modelli di colonna per formare la tabella relazionale appianata dalle gerarchie. È possibile usare i modelli di colonna come il seguente esempio, che appiana la gerarchia geografica in un formato di tabella relazionale.
Mapping basato su regole nella selezione e nella sink
Quando si esegue il mapping delle colonne nell'origine e si selezionano trasformazioni, è possibile aggiungere mapping fissi o mapping basati su regole. Corrispondenza basata su name, type, stream, origin e position delle colonne. È possibile avere qualsiasi combinazione di mapping fissi e basati su regole. Per impostazione predefinita, tutte le proiezioni con più di 50 colonne avranno come impostazione predefinita un mapping basato su regole che corrisponde a ogni colonna e restituisce il nome immesso.
Per aggiungere un mapping basato su regole, fare clic su Aggiungi mapping e selezionare Mapping basato su regole.

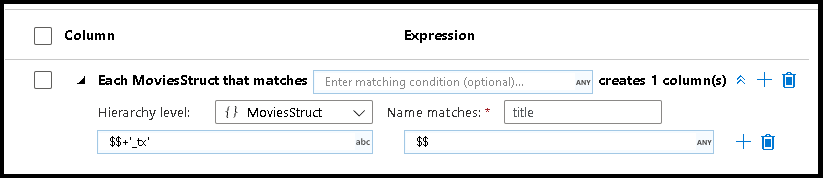
Ogni mapping basato su regole richiede due input: la condizione in base alla quale trovare la corrispondenza e il nome di ogni colonna mappata. Entrambi i valori vengono inseriti tramite il generatore di espressioni. Nella casella dell'espressione a sinistra immettere la condizione di corrispondenza booleana. Nella casella di espressione a destra, specificare a cosa verrà mappata la colonna corrispondente.

Usare la sintassi $$ per fare riferimento al nome di input di una colonna corrispondente. Usando l'immagine precedente come esempio, si supponga che un utente voglia trovare una corrispondenza in tutte le colonne stringa i cui nomi sono più brevi di sei caratteri. Se una colonna in ingresso è denominata test, l'espressione $$ + '_short' rinomina la colonna test_short. Se si tratta dell'unico mapping esistente, tutte le colonne che non soddisfano la condizione verranno eliminate dai dati restituiti.
Gli schemi corrispondono sia alle colonne deviate che alle colonne definite. Per visualizzare le colonne definite mappate da una regola, fare clic sull'icona degli occhiali accanto alla regola. Verificare l'output tramite l'anteprima dei dati.
Mappatura regex
Se si fa clic sull'icona della freccia verso il basso, è possibile specificare una condizione di mapping regex. Una condizione di mappatura regex corrisponde a tutti i nomi di colonna che corrispondono alla condizione regex specificata. Può essere usato in combinazione con i mapping standard basati su regole.

L'esempio precedente corrisponde al modello (r) regex o a qualsiasi nome di colonna contenente un valore r minuscolo. Analogamente alla mappatura standard basata su regole, tutte le colonne corrispondenti vengono modificate dalla condizione a destra usando la sintassi $$.
Gerarchie basate su regole
Se la proiezione definita ha una gerarchia, è possibile usare il mapping basato su regole per eseguire il mapping delle sottocolume delle gerarchie. Specificare una condizione di corrispondenza e la colonna complessa le cui sottocolonne si desidera mappare. Ogni sottocolonna corrispondente verrà restituita usando la regola "Name as" specificata a destra.
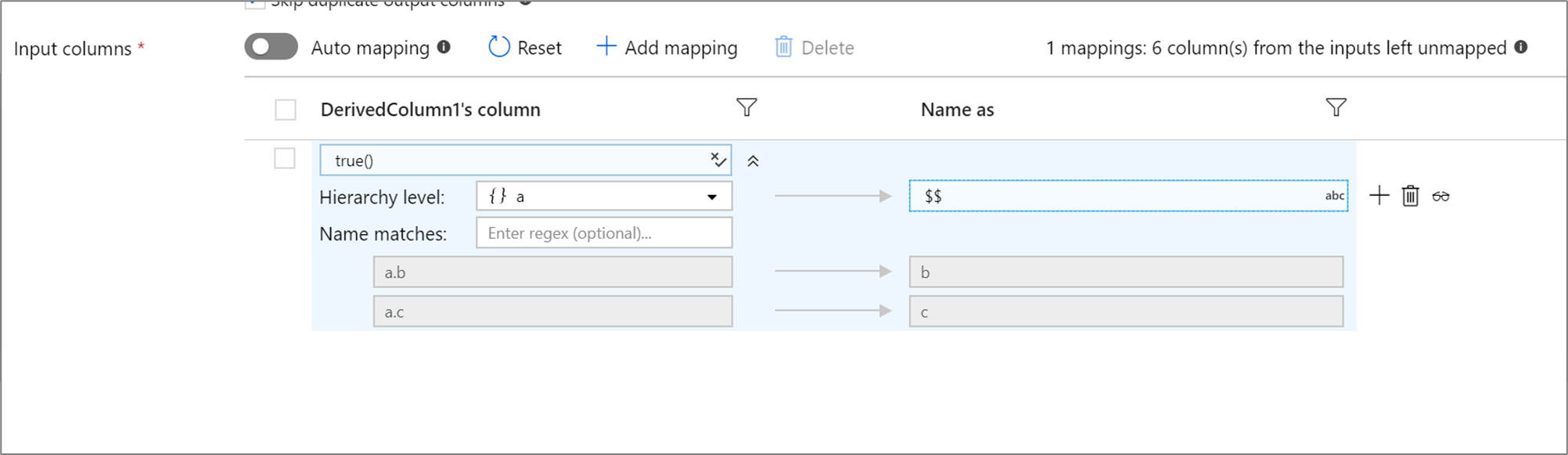
L'esempio precedente corrisponde a tutte le sottocolonne della colonna acomplessa .
a contiene due sottocolumni b e c. Lo schema di output includerà due colonne b e c come condizione 'Name as' è $$.
Valori delle espressioni di corrispondenza dei modelli
-
$$converte il nome o il valore di ogni corrispondenza in fase di esecuzione. Pensare a$$come equivalente dithis -
$0si traduce nel nome della colonna corrente che corrisponde in fase di esecuzione per i tipi scalari. Per i tipi gerarchici,$0rappresenta il percorso corrente della gerarchia di colonne corrispondenti. -
namerappresenta il nome di ogni colonna in ingresso -
typerappresenta il tipo di dati di ogni colonna in ingresso. L'elenco dei tipi di dati nel sistema dei tipi di flussi di dati è disponibile qui. -
streamrappresenta il nome associato a ogni flusso o trasformazione nel flusso -
positionè la posizione ordinale delle colonne nel flusso di dati -
originè la trasformazione in cui una colonna ha avuto origine o è stata aggiornata l'ultima volta.
Contenuto correlato
- Ulteriori informazioni sul linguaggio delle espressioni dei flussi di mappatura dati per le trasformazioni dei dati.
- Usare i modelli di colonna nella trasformazione sink e nella trasformazione selezione con mappatura basata su regole