Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
APPLICABILE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Data Factory in Microsoft Fabric è la nuova generazione di Azure Data Factory, con un'architettura più semplice, un'intelligenza artificiale predefinita e nuove funzionalità. Se non si ha familiarità con l'integrazione dei dati, iniziare con Fabric Data Factory. I carichi di lavoro di Azure Data Factory esistenti possono eseguire l'aggiornamento a Fabric per accedere a nuove funzionalità tra data science, analisi in tempo reale e creazione di report.
I flussi di dati sono disponibili sia nelle pipeline Azure Data Factory che nelle pipeline di Azure Synapse Analytics. Questo articolo si applica alla mappatura dei flussi di dati. Se non si ha familiarità con le trasformazioni, vedere l'articolo introduttivo Trasformare i dati usando flussi di dati di mapping.
Suggerimento
Per la trasformazione equivalente (Aggiungi destinazione dati) in Dataflow Gen2, vedere Una guida a Dataflow Gen2 per gli utenti di data flow mapping.
Dopo aver completato la trasformazione dei dati, scriverli in un archivio di destinazione usando la trasformazione sink. Ogni flusso di dati richiede almeno una trasformazione sink, ma è possibile utilizzare tutti i sink necessari per completare il flusso di trasformazione. Per scrivere in sink aggiuntivi, creare nuovi flussi tramite nuovi rami e divisioni condizionali.
Ogni trasformazione sink è associata esattamente a un oggetto set di dati o a un servizio collegato. La trasformazione sink determina la forma e la posizione dei dati in cui scrivere.
Set di dati inline
Quando si crea una trasformazione sink, scegliere se le informazioni sul sink vengono definite all'interno di un oggetto set di dati o all'interno della trasformazione sink. La maggior parte dei formati è disponibile solo in uno o nell'altro. Per informazioni su come usare un connettore specifico, vedere il documento del connettore appropriato.
Quando un formato è supportato sia inline che in un oggetto set di dati, esistono vantaggi per entrambi. Gli oggetti set di dati sono entità riutilizzabili che possono essere usate in altri flussi di dati e attività, ad esempio Copy. Queste entità riutilizzabili sono particolarmente utili quando si usa uno schema con protezione avanzata. I set di dati non sono basati su Spark. In alcuni casi, potrebbe essere necessario eseguire l'override di determinate impostazioni o proiezione dello schema nella trasformazione sink.
I set di dati inline sono consigliati quando si usano schemi flessibili, istanze di sink uno-off o sink con parametri. Se il sink è fortemente parametrizzato, i set di dati inline consentono di non creare un oggetto "fittizio". I set di dati inline sono basati su Spark e le relative proprietà sono native del flusso di dati.
Per usare un set di dati inline, selezionare il formato desiderato nel selettore Tipo Sink. Anziché selezionare un set di dati sink, selezionare il servizio collegato a cui connettersi.
Database dell'area di lavoro (solo aree di lavoro di Synapse)
Quando si usano i flussi di dati nelle aree di lavoro di Azure Synapse, è possibile trasferire i dati direttamente in un tipo di database situato all'interno della tua area di lavoro Synapse. In questo modo sarà possibile ridurre la necessità di aggiungere servizi o set di dati collegati per tali database. I database creati tramite i modelli di database Azure Synapse sono accessibili anche quando si seleziona Database dell'area di lavoro.
Nota
Il connettore del database dell'area di lavoro Azure Synapse è attualmente disponibile in anteprima pubblica e può funzionare solo con i database Spark Lake in questo momento
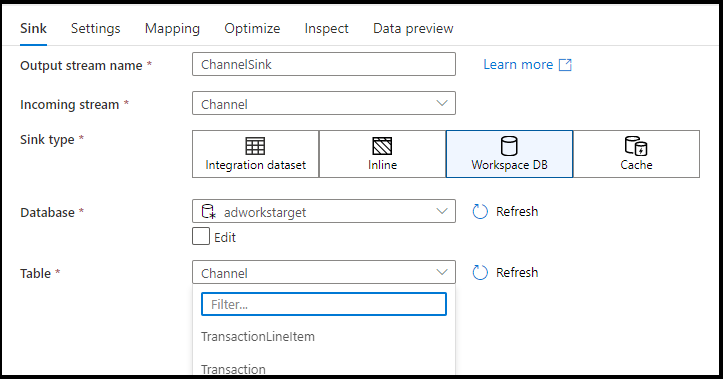
Tipi di Sink supportati
Il flusso di dati per mapping segue un approccio ELT (Extract, Load, Transform) e interagisce con set di dati di staging presenti in Azure. Attualmente, i set di dati seguenti possono essere usati in una trasformazione Sink.
Suggerimento
Il sink può avere un formato diverso da quello dell'origine. Questo è un passaggio di come è possibile passare da un formato all'altro. Ad esempio, da un CSV a un sink Parquet. Potrebbe essere necessario apportare alcune trasformazioni al flusso di dati tra l'origine e il sink per il corretto funzionamento. Ad esempio, Parquet ha requisiti di intestazioni più specifici rispetto a CSV.
| Connettore | Formato | Set di dati/inline |
|---|---|---|
| Archiviazione BLOB di Azure |
Avro Testo delimitato Delta JSON ORCO Parquet |
✓/✓ ✓/✓ -/✓ ✓/✓ ✓/✓ ✓/✓ |
| Azure Cosmos DB per NoSQL | ✓/- | |
| Azure Data Lake Storage Gen1 |
Avro Testo delimitato JSON ORCO Parquet |
✓/- ✓/- ✓/- ✓/✓ ✓/- |
| Azure Data Lake Storage Gen2 |
Avro Bookings Testo delimitato Delta JSON ORCO Parquet |
✓/✓ -/✓ ✓/✓ -/✓ ✓/✓ ✓/✓ ✓/✓ |
| Database di Azure per MySQL | ✓/✓ | |
| Database di Azure per PostgreSQL | ✓/✓ | |
| Esplora dati di Azure | ✓/✓ | |
| Database SQL di Azure | ✓/✓ | |
| Istanza gestita di database SQL di Azure | ✓/- | |
| Azure Synapse Analytics | ✓/- | |
| Dataverse | ✓/✓ | |
| Dynamics 365 | ✓/✓ | |
| Dynamics CRM | ✓/✓ | |
| Fabric Lakehouse | ✓/✓ | |
| SFTP |
Avro Testo delimitato JSON ORCO Parquet |
✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ |
| Fiocco | ✓/✓ | |
| SQL Server | ✓/✓ |
Le impostazioni specifiche di questi connettori si trovano nella scheda Impostazioni . Gli esempi di script del flusso di dati e informazioni su queste impostazioni si trovano nella documentazione del connettore.
Il servizio ha accesso a più di 90 connettori nativi. Per scrivere dati in tali altre origini dal flusso di dati, usare l'attività di copia per caricare tali dati da un Sink supportato.
Impostazioni sink
Dopo aver aggiunto un sink, configurarlo tramite la scheda Sink. Qui è possibile scegliere o creare il set di dati a cui il sink scrive. I valori di sviluppo per i parametri del set di dati possono essere configurati nelle impostazioni di debug. La modalità di debug deve essere attivata.
Il video seguente illustra diverse opzioni di sink per i tipi di file delimitati da testo.
Deriva dello schema: la deriva dello schema è la possibilità del servizio di gestire in modo nativo schemi flessibili nei flussi di dati senza dover definire in modo esplicito le modifiche alle colonne. Abilitare Consenti la deriva dello schema per consentire la scrittura di colonne aggiuntive oltre a quanto definito nello schema dei dati di destinazione.
Convalida schema: se è selezionato lo schema di convalida, il flusso di dati avrà esito negativo se una colonna nella proiezione sink non viene trovata nell'archivio sink o se i tipi di dati non corrispondono. Usare questa impostazione per imporre che lo schema sink soddisfi il contratto della proiezione definita. È utile negli scenari di sink del database per segnalare che i nomi o i tipi di colonna sono stati modificati.
Sink della cache
Un cache sink è un caso in cui un flusso di dati scrive i dati nella cache di Spark anziché in un archivio dati. Nei flussi di dati di mapping è possibile fare riferimento a questi dati all'interno dello stesso flusso più volte usando una ricerca nella cache. Ciò è utile quando si desidera fare riferimento ai dati come parte di un'espressione, ma non si vuole unire in modo esplicito le colonne. Esempi comuni in cui un sink della cache può essere utile per cercare un valore massimo in un archivio dati e trovare codici di errore corrispondenti a un database di messaggi di errore.
Per scrivere in un sink della cache, aggiungere una trasformazione sink e selezionare Cache come tipo di sink. A differenza di altri tipi di sink, non è necessario selezionare un set di dati o un servizio collegato perché non si sta scrivendo in un archivio esterno.
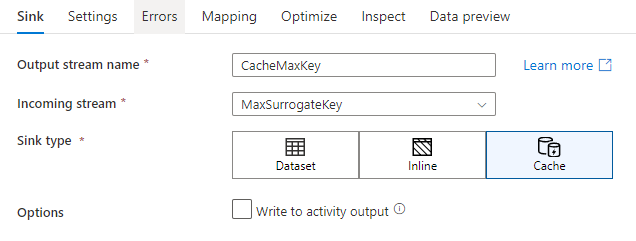
Nelle impostazioni del sink è possibile specificare facoltativamente le colonne chiave del sink della cache. Questi vengono usati come condizioni di corrispondenza quando si usa la lookup() funzione in una ricerca nella cache. Se si specificano colonne chiave, non è possibile usare la outputs() funzione in una ricerca nella cache. Per altre informazioni sulla sintassi di ricerca della cache, vedere Ricerche memorizzate nella cache.
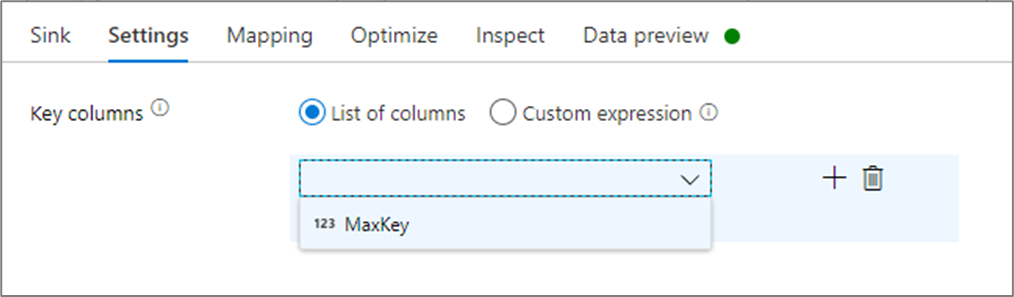
Ad esempio, se si specifica una singola colonna chiave di column1 in un sink della cache denominato cacheExample, la chiamata cacheExample#lookup() avrebbe un parametro che specifica quale riga nel sink della cache deve corrispondere. La funzione restituisce una singola colonna complessa con sottocolumni per ogni colonna mappata.
Nota
Un sink della cache deve trovarsi in un flusso di dati completamente indipendente da qualsiasi trasformazione che vi fa riferimento tramite una ricerca nella cache. Un sink della cache deve anche essere il primo sink scritto.
Scrivere nell’output dell’attività
In alternativa il sink cache può scrivere i dati nell'output dell'attività Flusso di dati che può quindi essere usata come input per un'altra attività nella pipeline. In questo modo è possibile passare rapidamente e facilmente i dati dall'attività del flusso di dati senza dover rendere persistenti i dati in un archivio dati.
Si noti che l'output di Flusso di dati inserito direttamente nella pipeline è limitato a 2 MB. Di conseguenza, Flusso di dati tenterà di aggiungere all'output il maggior numero di righe che può rimanere entro il limite di 2 MB, pertanto a volte potrebbe non essere possibile visualizzare tutte le righe nell'output dell'attività. L'impostazione di "Solo prima riga" a livello di attività Flusso di dati consente anche di limitare l'output dei dati da Flusso di dati, se necessario.
Metodo di aggiornamento
Per i tipi di sink di database, la scheda Impostazioni includerà una proprietà "Metodo di aggiornamento". Il valore predefinito è insert, ma include anche le opzioni della casella di controllo per l'aggiornamento, l'upsert e l'eliminazione. Per utilizzare queste opzioni aggiuntive, è necessario aggiungere una trasformazione Alter Row prima del sink. L'istruzione Alter Row consente di definire le condizioni per ciascuna delle azioni del database. Se l'origine è un'origine di abilitazione cdc nativa, è possibile impostare i metodi di aggiornamento senza alter row perché ADF è già a conoscenza dei marcatori di riga per inserimento, aggiornamento, upsert ed eliminazione.
Mapping dei campi
Analogamente a una trasformazione di selezione, nella scheda Mapping del sink è possibile decidere quali colonne in ingresso verranno scritte. Per impostazione predefinita, viene eseguito il mapping di tutte le colonne di input, incluse le colonne deviate. Questo comportamento è noto come automappatura.
Quando si disattiva il mapping automatico, è possibile aggiungere mapping fissi basati su colonne o mapping basati su regole. Con i mapping basati su regole, è possibile scrivere espressioni con criteri di ricerca. Il mapping corretto esegue il mapping dei nomi di colonne logiche e fisiche. Per ulteriori informazioni sul mapping basato su regole, vedere Modelli di colonna nel flusso di dati di mapping.
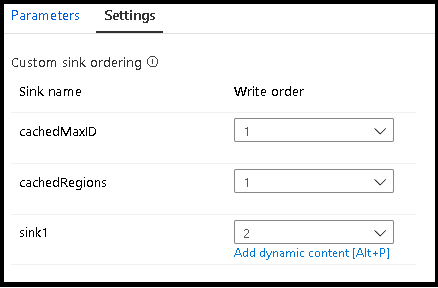
Ordinamento sink personalizzato
Per impostazione predefinita, i dati vengono scritti in più sink in un ordine non deterministico. Il motore di esecuzione scrive i dati in parallelo quando viene completata la logica di trasformazione e l'ordinamento del sink può variare a ogni esecuzione. Per specificare un ordine di sink esatto, abilitare Ordinamento sink personalizzato nella scheda Generale del flusso di dati. Se abilitata, i sink vengono scritti in sequenza in ordine crescente.
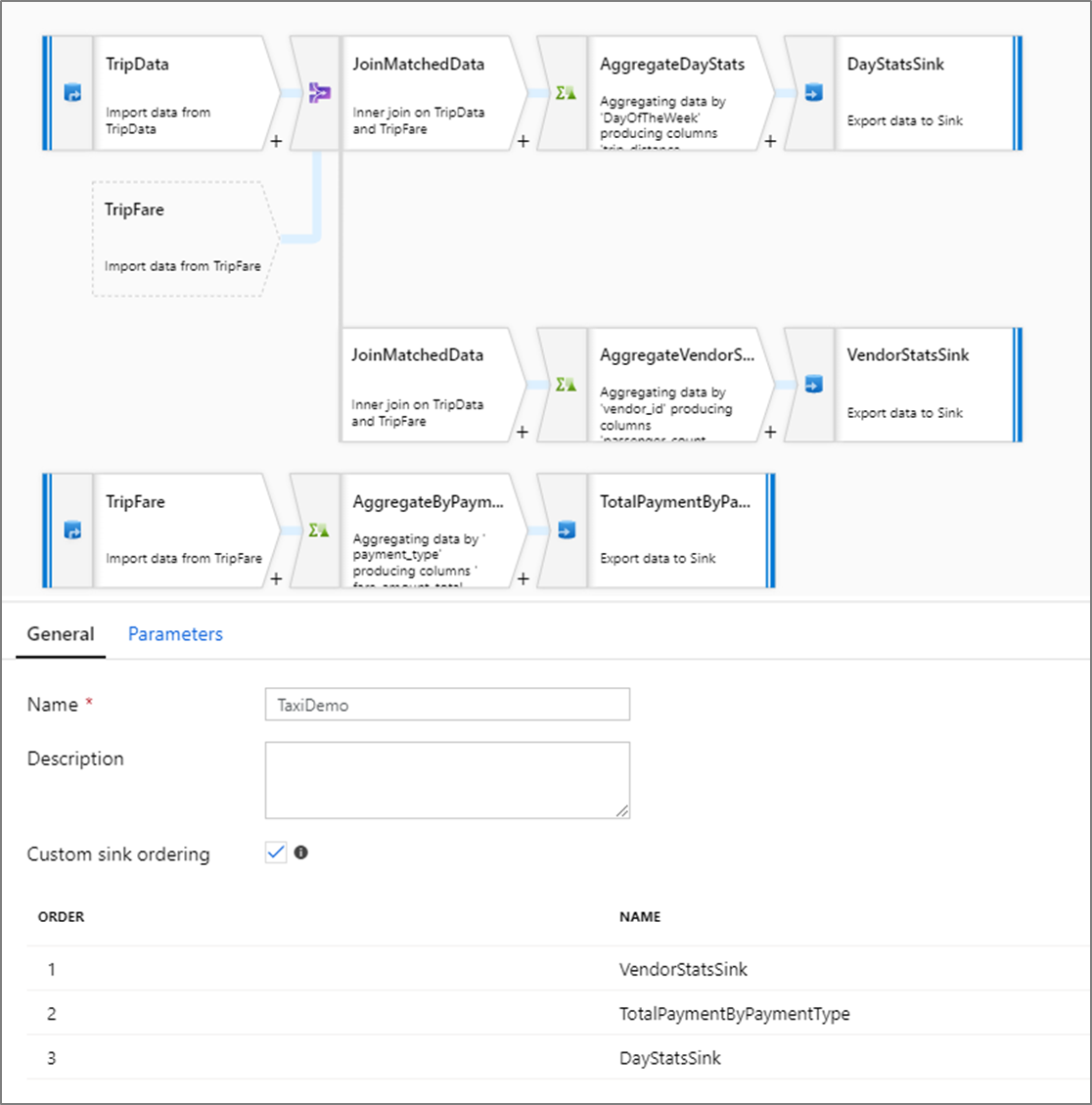
Nota
Quando si usano ricerche memorizzate nella cache, assicurarsi che l'ordinamento del sink abbia i sink memorizzati nella cache impostati su 1, il valore più basso (o primo) nell'ordinamento.
Gruppi di sink
È possibile raggruppare i sink applicando lo stesso numero di ordine per una serie di sink. Il servizio considererà tali sink come gruppi che possono essere eseguiti in parallelo. Le opzioni per l'esecuzione parallela verranno visualizzate nell'attività del flusso di dati della pipeline.
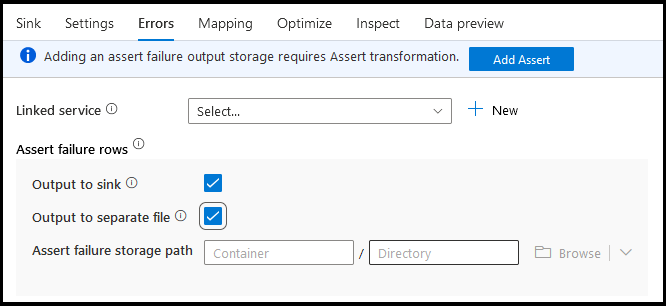
Errors
Nella scheda Errori sink è possibile configurare la gestione delle righe degli errori per acquisire e reindirizzare l'output per gli errori del driver di database e le asserzioni non riuscite.
Durante la scrittura nei database, alcune righe di dati potrebbero non riuscire a causa di vincoli impostati dalla destinazione. Per impostazione predefinita, un'esecuzione del flusso di dati avrà esito negativo al primo errore che riceve. In alcuni connettori è possibile scegliere Continua in caso di errore che consente il completamento del flusso di dati anche se sono presenti errori nelle singole righe. Attualmente, questa funzionalità è disponibile solo in database SQL di Azure e Azure Synapse. Per altre informazioni, vedere error row handling in Azure SQL DB.
Di seguito è riportata un'esercitazione video su come usare la gestione automatica delle righe degli errori del database nella trasformazione sink.
Per le righe di errore di asserzione, è possibile usare la trasformazione Assert upstream nel flusso di dati e quindi reindirizzare le asserzioni non riuscite a un file di output nella scheda Errori sink. È anche possibile ignorare le righe con errori di asserzione e non restituire tali righe nell'archivio dati di destinazione sink.
Anteprima dei dati nel sink
Quando si recupera un'anteprima dei dati in modalità di debug, nel sink non verranno scritti dati. Verrà restituito uno snapshot dell'aspetto dei dati, ma non verrà scritto nulla nella destinazione. Per testare la scrittura di dati nel sink, eseguire un debug della pipeline dall'area di disegno della pipeline.
Script del flusso di dati
Esempio
Di seguito è riportato un esempio di trasformazione sink e del relativo script del flusso di dati:
sink(input(
movie as integer,
title as string,
genres as string,
year as integer,
Rating as integer
),
allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:false,
updateable:true,
upsertable:false,
keys:['movie'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true,
saveOrder: 1,
errorHandlingOption: 'stopOnFirstError') ~> sink1
Contenuto correlato
Dopo aver creato il flusso di dati, aggiungere un'attività del flusso di dati alla pipeline.