Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
La deriva dello schema è il caso in cui le origini cambiano spesso i metadati. I campi, le colonne e i tipi possono essere aggiunti, rimossi o modificati in tempo reale. Senza gestire la deriva dello schema, il flusso di dati diventa vulnerabile alle modifiche dell'origine dati upstream. I modelli ETL tipici hanno esito negativo quando le colonne e i campi in ingresso cambiano perché tendono a essere associati a tali nomi di origine.
Per proteggersi dalla deriva dello schema, è importante disporre delle funzionalità in uno strumento flusso di dati per consentire, come Ingegnere dei dati, di:
- Definire origini con nomi di campo modificabili, tipi di dati, valori e dimensioni
- Definire i parametri di trasformazione che possono funzionare con i modelli di dati invece di valori e campi impostati come hardcoded
- Definire le espressioni in grado di riconoscere i criteri per la corrispondenza dei campi in ingresso, invece di usare campi denominati
Azure Data Factory supporta in modo nativo schemi flessibili che passano dall'esecuzione all'esecuzione, in modo da poter creare logica di trasformazione dei dati generica senza dover ricompilare i flussi di dati.
Nel flusso di dati è necessario prendere una decisione dal punto di vista dell'architettura riguardo a se accettare la deviazione dello schema in tutto il flusso. In questo modo, è possibile proteggersi da modifiche dello schema rispetto alle origini. Tuttavia, si perderà l'associazione anticipata delle colonne e dei tipi in tutto il flusso di dati. Azure Data Factory considera i flussi di deriva dello schema come flussi di associazione tardiva, quindi quando si compilano le trasformazioni, i nomi delle colonne deviate non saranno disponibili nelle visualizzazioni dello schema in tutto il flusso.
Questo video offre un'introduzione ad alcune delle soluzioni complesse che è possibile compilare facilmente nelle pipeline di Azure Data Factory o Synapse Analytics con la funzionalità di deriva dello schema del flusso di dati. In questo esempio vengono compilati modelli riutilizzabili basati su schemi di database flessibili:
Deriva dello schema nell'origine
Le colonne che arrivano nel flusso di dati dalla definizione di origine vengono definite come "deviate" quando non sono presenti nella proiezione di origine. È possibile visualizzare la proiezione di origine dalla scheda proiezione nella trasformazione di origine. Quando si seleziona un set di dati per l'origine, il servizio prende automaticamente lo schema dal set di dati e crea una proiezione dalla definizione dello schema del set di dati.
In una trasformazione di origine, la deriva dello schema viene definita come colonne di lettura non definite nello schema del set di dati. Per abilitare la deriva dello schema, selezionare Consenti deriva dello schema nella trasformazione di origine.
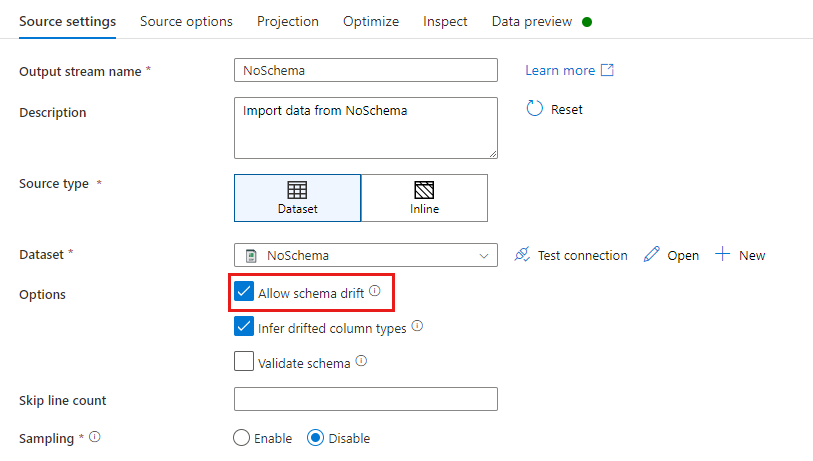
Quando la deriva dello schema è abilitata, tutti i campi in ingresso vengono letti dall'origine durante l'esecuzione e passati attraverso l'intero flusso al sink. Per impostazione predefinita, tutte le colonne appena rilevate, note come colonne deviate, arrivano come tipo di dati stringa. Se si desidera che il flusso di dati deduca automaticamente i tipi di dati delle colonne deviate, selezionare Infer drifted column types in your source settings (Infer drifted column types in your source settings).
Deriva dello schema nel sink
In una trasformazione sink, la deriva dello schema si verifica quando si scrivono colonne aggiuntive oltre a quanto definito nello schema dei dati sink. Per abilitare la deriva dello schema, selezionare Consenti deviazione dello schema nella trasformazione sink.
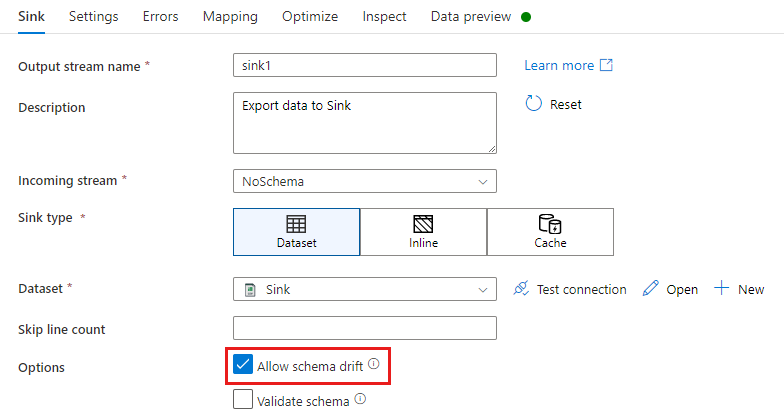
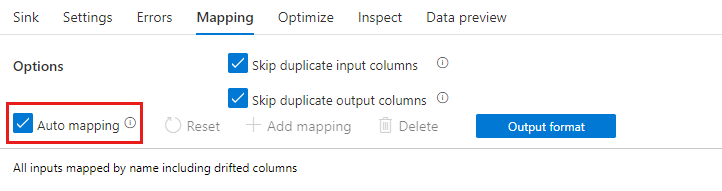
Se la deriva dello schema è abilitata, assicurarsi che il dispositivo di scorrimento Mapping automatico nella scheda Mapping sia attivato. Con questo dispositivo di scorrimento, tutte le colonne in ingresso vengono scritte nella destinazione. In caso contrario, è necessario utilizzare il mapping basato su regole per scrivere colonne deviate.
Trasformazione di colonne deviate
Quando il flusso di dati ha colonne deviate, è possibile accedervi nelle trasformazioni con i metodi seguenti:
- Usare le
byPositionespressioni ebyNameper fare riferimento in modo esplicito a una colonna in base al nome o al numero di posizione. - Aggiungere un criterio di colonna in una trasformazione Colonna derivata o Aggregazione in modo che corrisponda a qualsiasi combinazione di nome, flusso, posizione, origine o tipo
- Aggiungere un mapping basato su regole in una trasformazione Select o Sink per trovare una corrispondenza tra colonne con alias di colonne tramite un criterio
Per altre informazioni su come implementare modelli di colonna, vedere Modelli di colonna nel flusso di dati di mapping.
Eseguire il mapping rapido delle colonne deviate
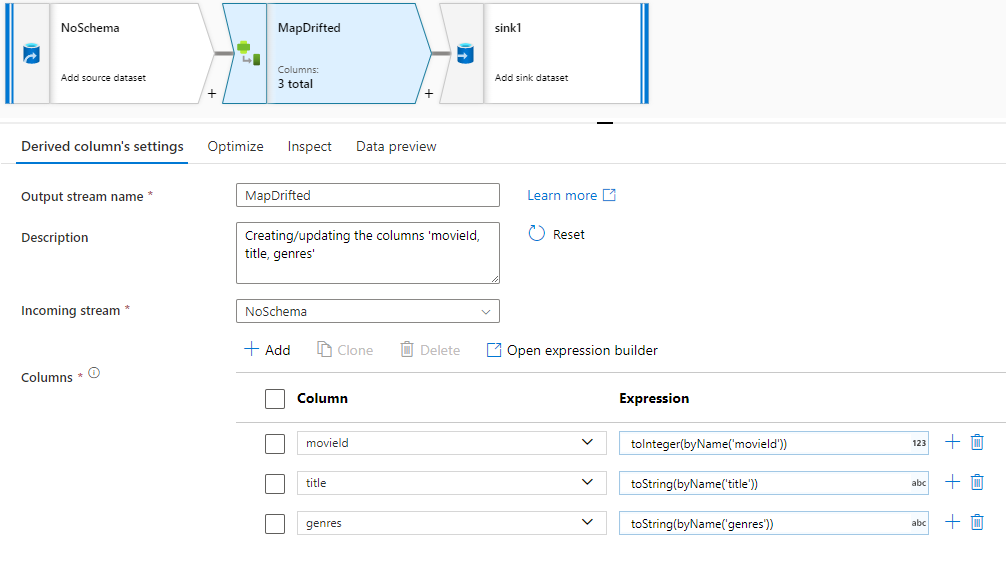
Per fare riferimento in modo esplicito alle colonne deviate, è possibile generare rapidamente mapping per queste colonne tramite un'azione rapida di anteprima dei dati. Dopo aver attivato la modalità di debug, passare alla scheda Anteprima dati e fare clic su Aggiorna per recuperare un'anteprima dei dati. Se data factory rileva che esistono colonne deviate, è possibile fare clic su Mappa derivata e generare una colonna derivata che consente di fare riferimento a tutte le colonne deviate nelle viste dello schema downstream.
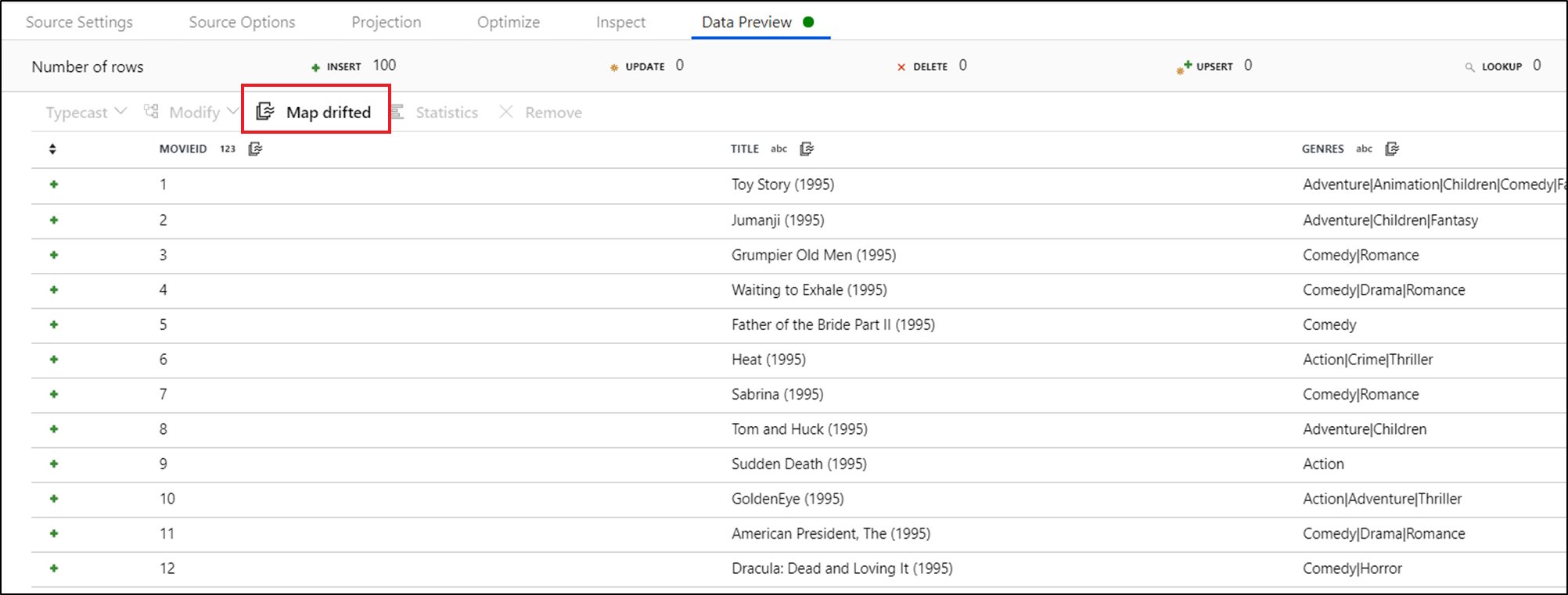
Nella trasformazione Colonna derivata generata, ogni colonna derivata viene mappata al nome e al tipo di dati rilevati. Nell'anteprima dei dati precedente la colonna 'movieId' viene rilevata come numero intero. Dopo aver fatto clic su Map Drifted , movieId viene definito nella colonna derivata come toInteger(byName('movieId')) e incluso nelle visualizzazioni dello schema nelle trasformazioni downstream.
Contenuto correlato
Nel linguaggio delle espressioni Flusso di dati sono disponibili funzionalità aggiuntive per i modelli di colonna e la deriva dello schema, tra cui "byName" e "byPosition".