Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
APPLICABILE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Data Factory in Microsoft Fabric è la nuova generazione di Azure Data Factory, con un'architettura più semplice, un'intelligenza artificiale predefinita e nuove funzionalità. Se non si ha familiarità con l'integrazione dei dati, iniziare con Fabric Data Factory. I carichi di lavoro di Azure Data Factory esistenti possono eseguire l'aggiornamento a Fabric per accedere a nuove funzionalità tra data science, analisi in tempo reale e creazione di report.
I flussi di dati sono disponibili sia nelle pipeline Azure Data Factory che nelle pipeline di Azure Synapse Analytics. Questo articolo si applica ai flussi di dati di mapping. Se non si ha familiarità con le trasformazioni, vedere l'articolo introduttivo Trasformare i dati usando flussi di dati di mapping.
Suggerimento
Per la conversione equivalente (Colonna pivot) in Dataflow Gen2, vedere Una guida a Dataflow Gen2 per gli utenti del flusso di dati per mapping.
Usare la trasformazione tramite Pivot per creare più colonne dai valori di riga univoci di una singola colonna. La trasformazione tramite Pivot si basa sull'aggregazione e consente di selezionare il raggruppamento per colonne per generare colonne pivot usando le funzioni di aggregazione.
Impostazione
La trasformazione tramite Pivot richiede tre diversi input: le colonne per il raggruppamento, la chiave pivot e la modalità di generazione per le colonne trasformate tramite Pivot.
Raggruppa per
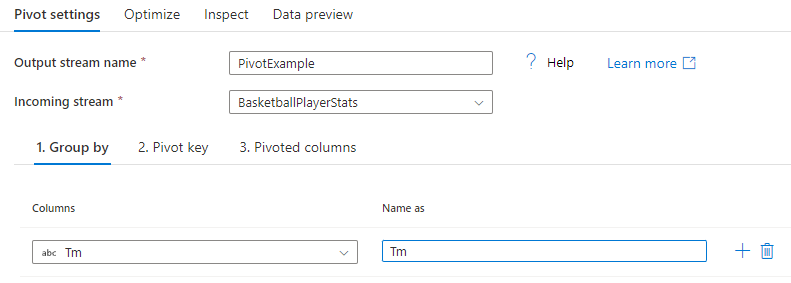
Selezionare le colonne su cui aggregare le colonne pivotate. I dati di output raggruppano tutte le righe con lo stesso gruppo per valori in una riga. L'aggregazione eseguita nella colonna trasformata tramite Pivot viene eseguita in ogni gruppo.
Questa sezione è facoltativa. Se non viene selezionato alcun gruppo per colonne, l'intero flusso di dati viene aggregato e viene restituita una sola riga.
Chiave pivot
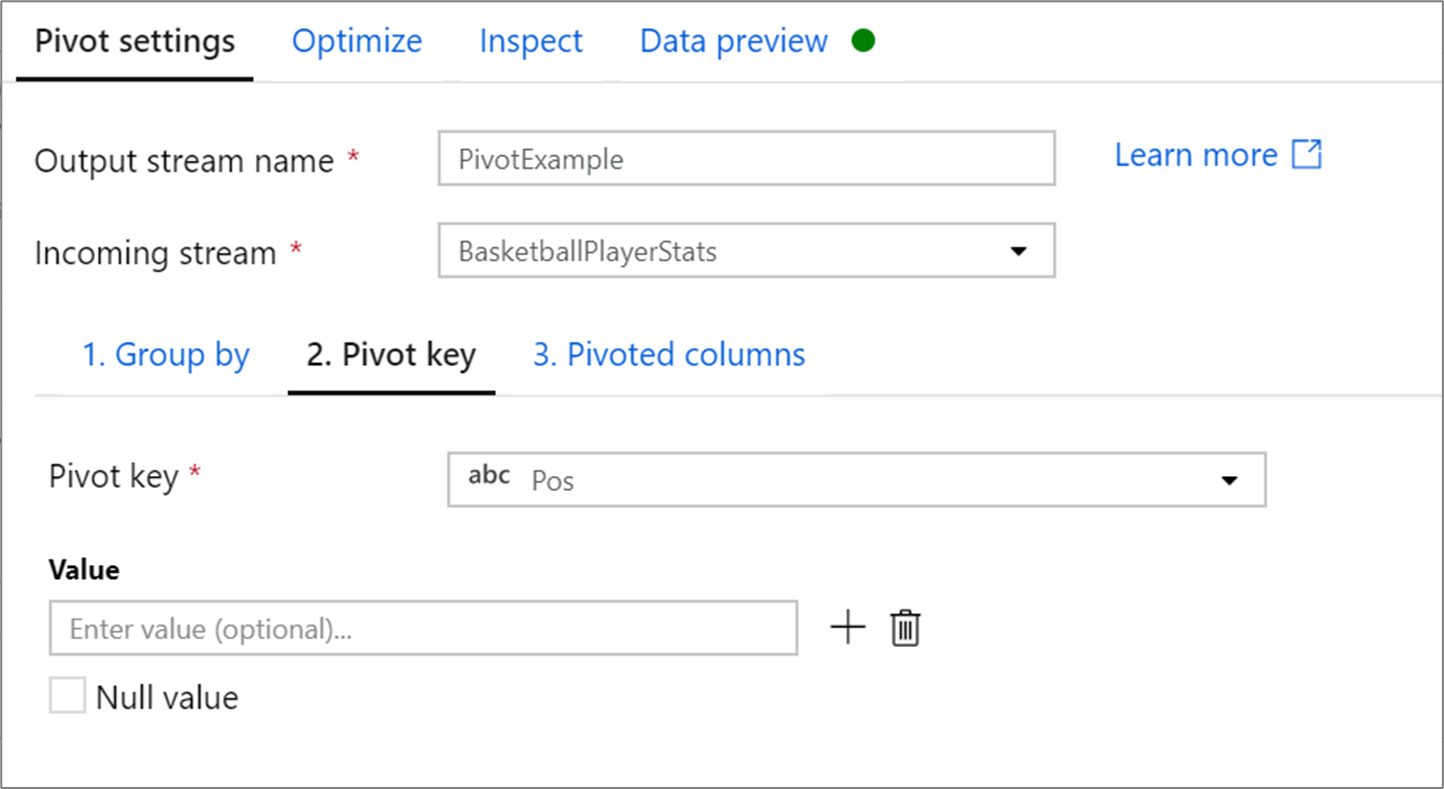
La chiave pivot corrisponde alla colonna i cui valori di riga vengono trasformati tramite Pivot in nuove colonne. Per impostazione predefinita, la trasformazione pivot crea una nuova colonna per ogni valore di riga univoco.
Nella sezione Valore è possibile immettere valori di riga specifici da trasformare tramite Pivot. Solo i valori di riga immessi in questa sezione vengono ruotati. L'abilitazione del valore Null crea una colonna trasformata tramite Pivot per i valori Null della colonna.
Colonne pivotate
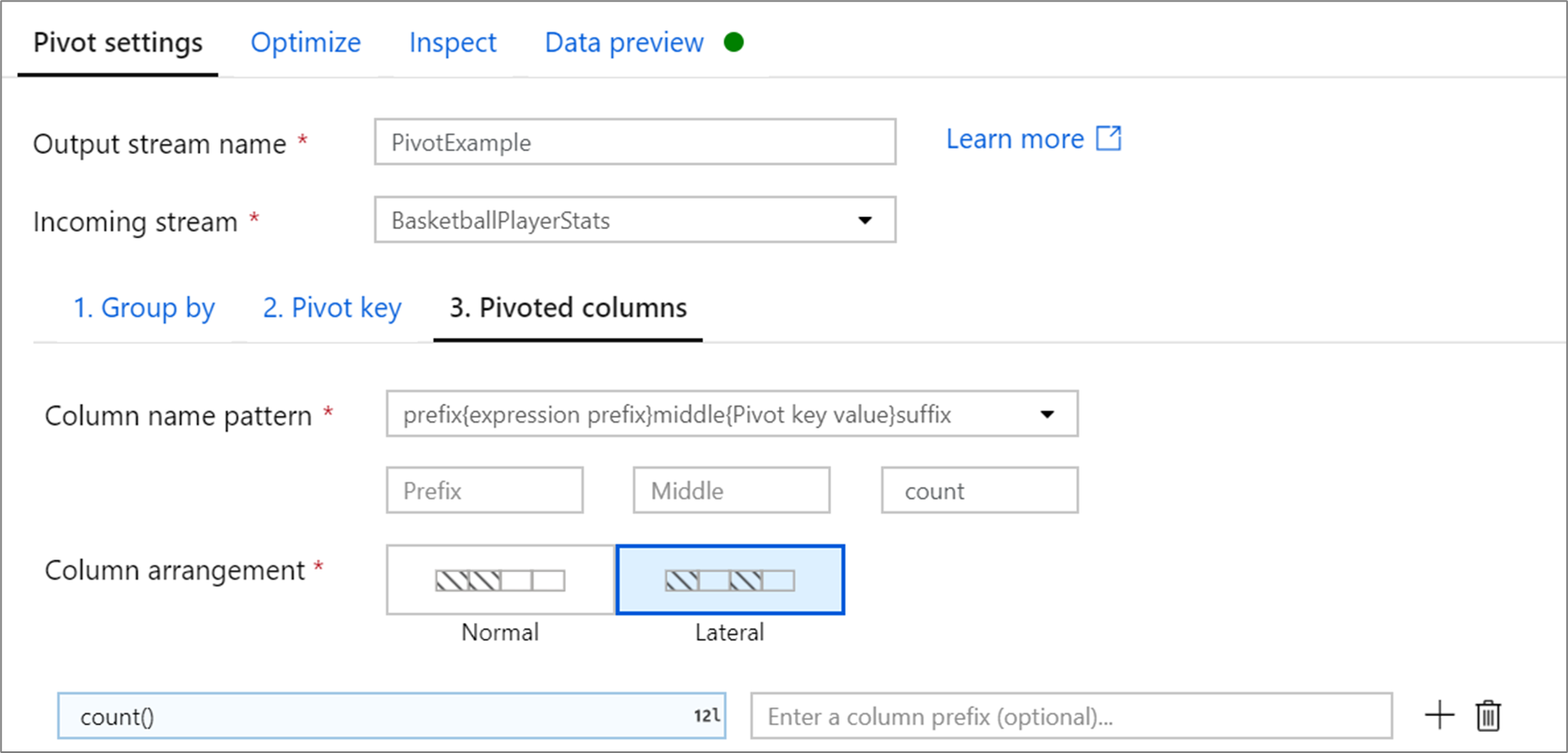
Per ogni valore di chiave pivot univoco che viene trasformato in una colonna, viene generato un valore di riga aggregato per ogni gruppo. È possibile creare più colonne per ogni chiave pivot. Ogni colonna pivot deve contenere almeno una funzione di aggregazione.
Modello nome colonna: selezionare come formattare il nome per ciascuna colonna pivot. Il nome della colonna restituita è una combinazione del valore della chiave pivot, del prefisso di colonna e del prefisso facoltativo, del suffisso, dei caratteri intermedi.
Disposizione colonne: se si generano più colonne pivot per ogni chiave pivot, scegliere la modalità di ordinamento delle colonne.
Prefisso colonna: se si generano più colonne pivot per ogni chiave pivot, immettere un prefisso di colonna per ogni colonna. Questa impostazione è facoltativa se si dispone di una sola colonna pivot.
Grafica di aiuto
L'immagine di aiuto mostra in che modo i diversi componenti pivot interagiscono tra loro
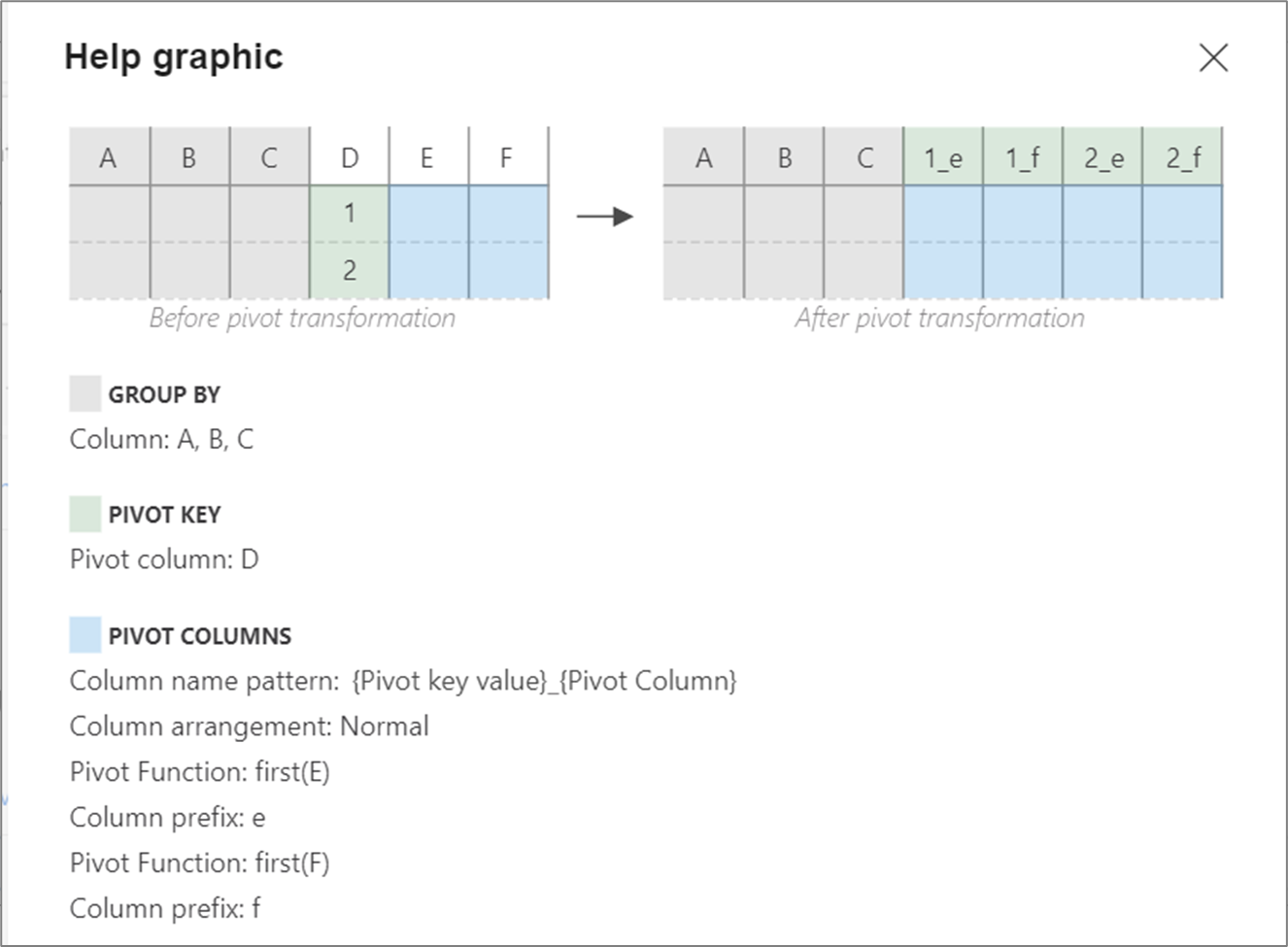
Metadati pivot
Se nella configurazione della chiave pivot non vengono specificati valori, le colonne con pivot vengono generate dinamicamente in fase di esecuzione. Il numero di colonne pivotate è uguale al numero di valori di chiave pivot univoci moltiplicato per il numero di colonne pivot. Poiché può trattarsi di un numero che cambia, l'esperienza utente non visualizza i metadati della colonna nella scheda Inspect e non esiste alcuna propagazione delle colonne. Per eseguire la trasformazione di queste colonne, usare le funzionalità del flusso di dati per mapping del modello di colonna.
Se vengono impostati valori di chiave pivot specifici, le colonne con pivot vengono visualizzate nei metadati. I nomi delle colonne sono disponibili nella scheda Ispeziona e nel mapping di sink e ispezione.
Generare i metadati dalle colonne deviate
Pivot genera in modo dinamico nuovi nomi di colonna basandosi sui valori delle righe. È possibile aggiungere le nuove colonne ai metadati a cui fare riferimento in un secondo momento nel flusso di dati. A tale scopo, usare l'azione veloce mappa alla deriva nell'anteprima dei dati.
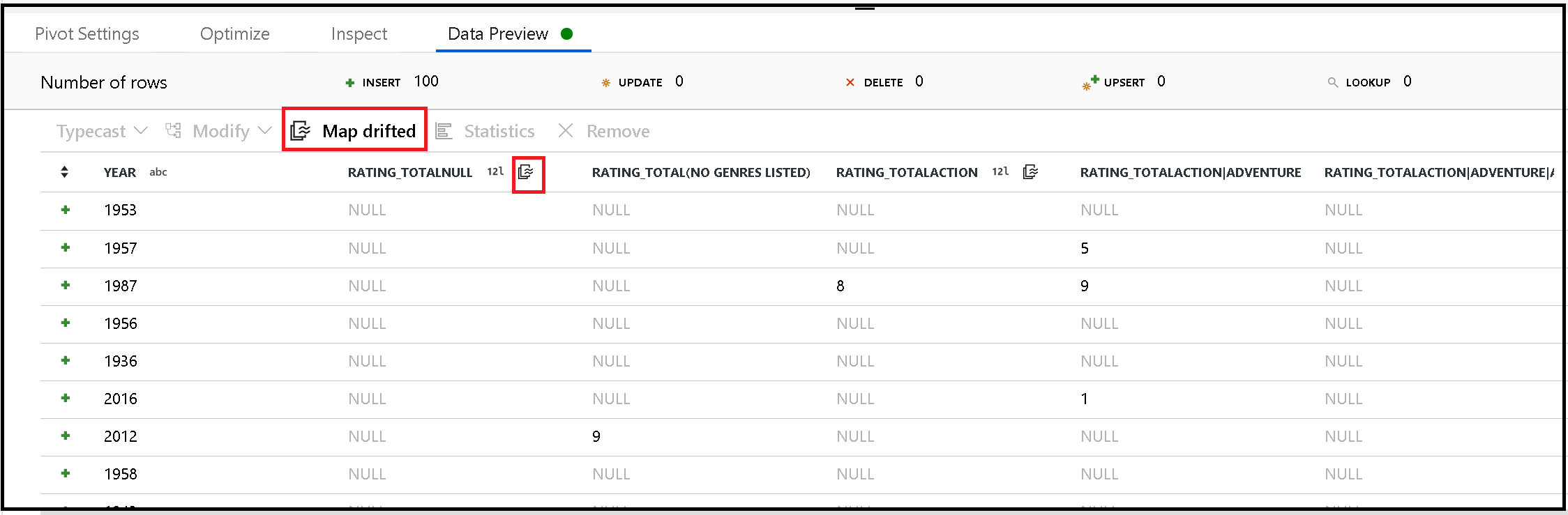
Colonne trasformate tramite Pivot con sink
Sebbene le colonne pivotate siano dinamiche, possono ancora essere inserite nell'archivio dati di destinazione. Abilitare Allow schema drift (Consenti deviazione schema) nelle impostazioni di sink. In questo modo è possibile scrivere colonne non incluse nei metadati. Non verranno visualizzati i nuovi nomi dinamici nei metadati delle colonne, ma l'opzione di "schema drift" consente di caricare i dati.
Riunire nuovamente i campi originali
La trasformazione tramite Pivot proietta solo le colonne Group by e trasformate tramite Pivot. Per includere altre colonne di input nei dati di output, usare un modello self join.
Script del flusso di dati
Sintassi
<incomingStreamName>
pivot(groupBy(Tm),
pivotBy(<pivotKeyColumn, [<specifiedColumnName1>,...,<specifiedColumnNameN>]),
<pivotColumnPrefix> = <pivotedColumnValue>,
columnNaming: '< prefix >< $N | $V ><middle >< $N | $V >< suffix >',
lateral: { 'true' | 'false'}
) ~> <pivotTransformationName
Esempio
Le schermate visualizzate nella sezione di configurazione includono lo script del flusso di dati seguente:
BasketballPlayerStats pivot(groupBy(Tm),
pivotBy(Pos),
{} = count(),
columnNaming: '$V$N count',
lateral: true) ~> PivotExample
Contenuto correlato
Utilizza la trasformazione unpivot per convertire i valori di colonna in valori di riga.