Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
APPLIES TO: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Data Factory in Microsoft Fabric è la nuova generazione di Azure Data Factory, con un'architettura più semplice, un'intelligenza artificiale predefinita e nuove funzionalità. Se non si ha familiarità con l'integrazione dei dati, iniziare con Fabric Data Factory. I carichi di lavoro di Azure Data Factory esistenti possono eseguire l'aggiornamento a Fabric per accedere a nuove funzionalità tra data science, analisi in tempo reale e creazione di report.
Questo articolo illustra come copiare dati da e verso un delta lake archiviato in Azure Data Lake Store Gen2 o Archiviazione BLOB di Azure usando il formato delta. Questo connettore è disponibile come set di dati inline nei flussi di dati di mapping sia come origine che come sink.
Proprietà del flusso di dati per mapping
Questo connettore è disponibile come set di dati inline nei flussi di dati di mapping sia come origine che come sink.
Proprietà di origine
Nella tabella seguente sono elencate le proprietà supportate da un'origine differenziale. È possibile modificare queste proprietà nella scheda Opzioni origine.
| Nome | Descrizione | Richiesto | Valori consentiti | Proprietà script del flusso di dati |
|---|---|---|---|---|
| Formato | Il formato deve essere delta |
yes | delta |
format |
| Sistema di file | Contenitore/file system del delta lake | yes | String | fileSystem |
| Percorso cartella | Directory del delta lake | yes | String | folderPath |
| Tipo di compressione | Tipo di compressione della tabella delta | no | bzip2gzipdeflateZipDeflatesnappylz4 |
compressionType |
| Livello di compressione | Scegliere se la compressione viene completata il più rapidamente possibile o se il file risultante deve essere compresso in modo ottimale. | obbligatorio se compressedType è specificato. |
Optimal oppure Fastest |
compressionLevel |
| Spostamento cronologico | Scegliere se eseguire una query su uno snapshot precedente di una tabella delta | no | Query per timestamp: Timestamp Query per versione: Integer |
timestampAsOf versionAsOf |
| Consenti nessun file trovato | Se true, non viene generato un errore se non vengono trovati file | no |
true oppure false |
ignoreNoFilesFound |
Importa schema
Delta è disponibile solo come set di dati inline e, per impostazione predefinita, non ha uno schema associato. Per ottenere i metadati della colonna, fare clic sul pulsante Importa schema nella scheda Proiezione . In questo modo è possibile fare riferimento ai nomi delle colonne e ai tipi di dati specificati dal corpus. Per importare lo schema, una sessione di debug del flusso di dati deve essere attiva ed è necessario disporre di un file di definizione di entità CDM esistente a cui puntare.
Esempio di script di origine Delta
source(output(movieId as integer,
title as string,
releaseDate as date,
rated as boolean,
screenedOn as timestamp,
ticketPrice as decimal(10,2)
),
store: 'local',
format: 'delta',
versionAsOf: 0,
allowSchemaDrift: false,
folderPath: $tempPath + '/delta'
) ~> movies
Proprietà sink
Nella tabella seguente sono elencate le proprietà supportate da un sink differenziale. È possibile modificare queste proprietà nella scheda Impostazioni.
| Nome | Descrizione | Richiesto | Valori consentiti | Proprietà script del flusso di dati |
|---|---|---|---|---|
| Formato | Il formato deve essere delta |
yes | delta |
format |
| Sistema di file | Contenitore/file system del delta lake | yes | String | fileSystem |
| Percorso cartella | Directory del delta lake | yes | String | folderPath |
| Tipo di compressione | Tipo di compressione della tabella delta | no | bzip2gzipdeflateZipDeflatesnappylz4TarGZiptar |
compressionType |
| Livello di compressione | Scegliere se la compressione viene completata il più rapidamente possibile o se il file risultante deve essere compresso in modo ottimale. | obbligatorio se compressedType è specificato. |
Optimal oppure Fastest |
compressionLevel |
| Vacuum | Elimina i file precedenti alla durata specificata che non è più rilevante per la versione corrente della tabella. Quando viene specificato un valore pari o inferiore a 0, l'operazione vacuum non viene eseguita. | yes | Intero | vuoto |
| Azione Tabella | Indica a Azure Data Factory cosa fare con la tabella Delta di destinazione nel sink. È possibile lasciarlo così come sono e accodare nuove righe, sovrascrivere la definizione e i dati della tabella esistenti con nuovi metadati e dati oppure mantenere la struttura di tabella esistente, ma prima troncare tutte le righe, quindi inserire le nuove righe. | no | Nessuno, Truncate, Overwrite | deltaTruncate, sovrascrittura |
| Metodo di aggiornamento | Quando si seleziona "Consenti inserimento" da solo o quando si scrive in una nuova tabella differenziale, la destinazione riceve tutte le righe in ingresso indipendentemente dal set di criteri riga. Se i dati contengono righe di altri criteri di riga, è necessario escluderli usando una trasformazione filtro precedente. Quando vengono selezionati tutti i metodi Update, viene eseguita un'operazione Merge, in cui le righe vengono inserite/eliminate/aggiornate in base ai criteri di riga impostati utilizzando una trasformazione Alter Row precedente. |
yes |
true oppure false |
insertable deletable upsertable aggiornabile |
| Scrittura ottimizzata | Ottenere una velocità effettiva più elevata per l'operazione di scrittura tramite l'ottimizzazione dello shuffle interno negli executor Spark. Di conseguenza, è possibile notare un minor numero di partizioni e file con dimensioni maggiori | no |
true oppure false |
ottimizzazioneScrittura: vero |
| Compattazione automatica | Al termine di un'operazione di scrittura, Spark eseguirà automaticamente il OPTIMIZE comando per riorganizionare i dati, ottenendo così più partizioni, se necessario, per migliorare le prestazioni di lettura in futuro |
no |
true oppure false |
autoCompact: vero |
Esempio di script sink delta
Lo script del flusso di dati associato è:
moviesAltered sink(
input(movieId as integer,
title as string
),
mapColumn(
movieId,
title
),
insertable: true,
updateable: true,
deletable: true,
upsertable: false,
keys: ['movieId'],
store: 'local',
format: 'delta',
vacuum: 180,
folderPath: $tempPath + '/delta'
) ~> movieDB
Sink differenziale con eliminazione delle partizioni
Con questa opzione in Update method above (ad esempio update/upsert/delete), è possibile limitare il numero di partizioni ispezionate. Solo le partizioni che soddisfano questa condizione vengono recuperate dall'archivio di destinazione. È possibile specificare un set fisso di valori che una colonna di partizione può richiedere.
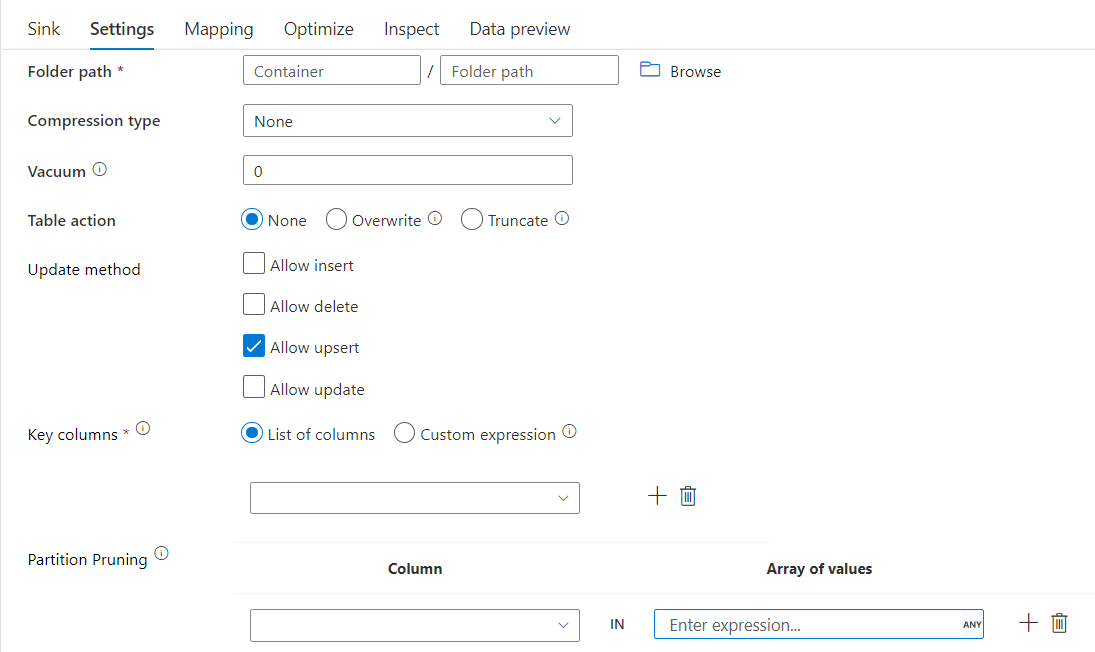
Esempio di script sink delta con eliminazione della partizione
Di seguito è riportato uno script di esempio.
DerivedColumn1 sink(
input(movieId as integer,
title as string
),
allowSchemaDrift: true,
validateSchema: false,
format: 'delta',
container: 'deltaContainer',
folderPath: 'deltaPath',
mergeSchema: false,
autoCompact: false,
optimizedWrite: false,
vacuum: 0,
deletable:false,
insertable:true,
updateable:true,
upsertable:false,
keys:['movieId'],
pruneCondition:['part_col' -> ([5, 8])],
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink2
Delta leggerà solo 2 partizioni in cui part_col == 5 e 8 dall'archivio delta di destinazione anziché da tutte le partizioni. part_col è una colonna in base alla quale i dati differenziali di destinazione sono partizionati. Non è necessario che sia presente nei dati di origine.
Opzioni di ottimizzazione sink delta
Nella scheda Impostazioni sono disponibili altre tre opzioni per ottimizzare la trasformazione sink differenziale.
Quando l'opzione Merge schema è abilitata, consente l'evoluzione dello schema, ovvero tutte le colonne presenti nel flusso in ingresso corrente ma non nella tabella Delta di destinazione vengono aggiunte automaticamente al relativo schema. Questa opzione è supportata in tutti i metodi di aggiornamento.
Quando la compattazione automatica è abilitata, dopo una singola scrittura, la trasformazione controlla se i file possono essere ulteriormente compattati ed esegue un processo OPTIMIZE rapido (con dimensioni di file da 128 MB invece di 1 GB) per compattare ulteriormente i file per le partizioni con il maggior numero di file di piccole dimensioni. La compattazione automatica consente di unire un numero elevato di file di piccole dimensioni in un numero minore di file di grandi dimensioni. La compattazione automatica viene avviata solo quando sono presenti almeno 50 file. Una volta eseguita un'operazione di compattazione, crea una nuova versione della tabella e scrive un nuovo file contenente i dati di diversi file precedenti in un formato compresso compatto.
Quando l'opzione Ottimizza scrittura è abilitata, la trasformazione sink ottimizza in modo dinamico le dimensioni delle partizioni in base ai dati effettivi tentando di scrivere file di 128 MB per ogni partizione di tabella. Si tratta di una dimensione approssimativa e può variare a seconda delle caratteristiche del set di dati. Le scritture ottimizzate migliorano l'efficienza complessiva delle scritture e delle letture successive. Organizza le partizioni in modo che le prestazioni delle letture successive migliorino.
Suggerimento
Il processo di scrittura ottimizzato rallenterà il processo ETL complessivo perché il sink eseguirà il comando Spark Delta Lake Optimize dopo l'elaborazione dei dati. È consigliabile usare temporaneamente la scrittura ottimizzata. Ad esempio, se si dispone di una pipeline di dati oraria, eseguire un flusso di dati con ottimizzazione scrittura giornaliera.
Limitazioni note
Quando si scrive in un sink differenziale, esiste una limitazione nota in cui il numero di righe scritte non verrà visualizzato nell'output di monitoraggio.
Contenuto correlato
- Creare una trasformazione di origine nel flusso di dati di mapping.
- Creare una trasformazione sink nel flusso di dati di mapping.
- Creare una trasformazione alter row per contrassegnare le righe come inserimento, aggiornamento, upsert o eliminazione.