Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Applicabile a: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Data Factory in Microsoft Fabric è la nuova generazione di Azure Data Factory, con un'architettura più semplice, un'intelligenza artificiale predefinita e nuove funzionalità. Se non si ha familiarità con l'integrazione dei dati, iniziare con Fabric Data Factory. I carichi di lavoro di Azure Data Factory esistenti possono eseguire l'aggiornamento a Fabric per accedere a nuove funzionalità tra data science, analisi in tempo reale e creazione di report.
Seguire questo articolo quando si vuole analizzare i file JSON o scrivere i dati in formato JSON.
Il formato JSON è supportato per i connettori seguenti:
- Amazon S3
- Archiviazione compatibile con Amazon S3,
- Azure BLOB
- Azure Data Lake Storage Gen1
- Azure Data Lake Storage Gen2
- File di Azure
- File system
- FTP
- Google Cloud Storage
- HDFS
- HTTP
- Archiviazione in Oracle Cloud
- SFTP
Proprietà del set di dati
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione dei set di dati, vedere l'articolo Set di dati. Questa sezione fornisce un elenco delle proprietà supportate dal set di dati JSON.
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type del set di dati deve essere impostata su Json. | Sì |
| location | Impostazioni di posizione dei file. Ogni connettore basato su file ha il proprio tipo di percorso e le proprietà supportate in location.
Vedere i dettagli nell'articolo del connettore -> sezione Proprietà del set di dati. |
Sì |
| encodingName | Tipo di codifica usato per leggere/scrivere file di test. I valori consentiti sono i seguenti: "UTF-8","UTF-8 senza BOM", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "US-ASCII", "UTF-7", "BIG5", "EUC-JP", "EUC-KR", "GB2312", "GB18030", "JOHAB", "SHIFT-JIS", "CP875", "CP866", "IBM00858", "IBM037", "IBM273", "IBM437", "IBM500", "IBM737", "IBM775", "IBM850", "IBM852", "IBM855", "IBM857", "IBM860", "IBM861", "IBM863", "IBM864", "IBM865", "IBM869", "IBM870", "IBM01140", "IBM01141", "IBM01142", "IBM01143", "IBM01144", "IBM01145", "IBM01146", "IBM01147", "IBM01148", "IBM01149", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-3", "ISO-8859-4", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "ISO-8859-13", "ISO-8859-15", "WINDOWS-874", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1252", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255", "WINDOWS-1256", "WINDOWS-1257", "WINDOWS-1258". |
No |
| compressione | Gruppo di proprietà per configurare la compressione dei file. Configurare questa sezione se si desidera eseguire la compressione/decompressione durante l'esecuzione dell'attività. | No |
| type (in compression) |
Codec di compressione usato per leggere/scrivere file JSON. I valori consentiti sono bzip2, gzip, deflate, ZipDeflate, TarGzip, Tar, snappyo lz4. Il valore predefinito non è compresso. Note attualmente attività Copy non supporta "snappy" e "lz4" e il flusso di dati di mapping non supporta "ZipDeflate"", "TarGzip" e "Tar". Nota quando si usa l'attività di copia per decomprimere i file ZipDeflate/TarGzip/Tar e scrivere nell'archivio dati sink basato su file, per impostazione predefinita i file vengono estratti nella cartella: <path specified in dataset>/<folder named as source compressed file>/, usare preserveZipFileNameAsFolder/preserveCompressionFileNameAsFolder su origine attività Copy per controllare se mantenere il nome dei file compressi come struttura di cartelle. |
No. |
| level (in compression) |
Rapporto di compressione. I valori consentiti sono ottimale o più veloce. - Fastest: l'operazione di compressione deve essere completata il più rapidamente possibile, anche se il file risultante non viene compresso in modo ottimale. - Optimal: l'operazione di compressione deve comprimere il file in modo ottimale, anche se il completamento richiede più tempo. Per maggiori informazioni, vedere l'argomento relativo al livello di compressione . |
No |
Di seguito è riportato un esempio di set di dati JSON in Archiviazione BLOB di Azure:
{
"name": "JSONDataset",
"properties": {
"type": "Json",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"compression": {
"type": "gzip"
}
}
}
}
proprietà attività Copy
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione delle attività, vedere l'articolo sulle pipeline. Questa sezione fornisce un elenco delle proprietà supportate dall'origine e dal sink JSON.
Informazioni su come estrarre i dati dai file JSON ed eseguire il mapping dell'archivio dati di sink/formato o viceversa dal mapping dello schema.
JSON come origine
Le proprietà seguenti sono supportate nella sezione attività Copy *origine*.
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type dell'origine dell'attività Copy deve essere impostata su JSONSource. | Sì |
| formatSettings | Gruppo di proprietà. Fare riferimento alla tabella delle impostazioni di lettura JSON seguente. | No |
| storeSettings | Gruppo di proprietà su come leggere i dati da un archivio dati. Ogni connettore basato su file dispone di impostazioni di lettura proprie supportate in storeSettings.
Visualizza i dettagli nell'articolo del connettore -> attività Copy proprietà. |
No |
Le impostazioni di lettura JSON supportate in formatSettings:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | Il tipo di formatSettings deve essere impostato su JsonReadSettings. | Sì |
| compressionProperties | Gruppo di proprietà su come decomprimere i dati per un determinato codec di compressione. | No |
| preserveZipFileNameAsFolder (in compressionProperties->type come ZipDeflateReadSettings) |
Si applica quando il set di dati di input è configurato con compressione ZipDeflate. Indica se mantenere il nome del file ZIP di origine come struttura di cartelle durante la copia. - Se impostato su true (impostazione predefinita), il servizio scrive i file decompressi in <path specified in dataset>/<folder named as source zip file>/.- Se impostato su false, il servizio scrive i file decompressi direttamente in <path specified in dataset>. Assicurarsi di non avere nomi di file duplicati in file ZIP di origine diversi per evitare corse o comportamenti imprevisti. |
No |
| preserveCompressionFileNameAsFolder (in compressionProperties->type come TarGZipReadSettings o TarReadSettings) |
Si applica quando il set di dati di input è configurato con compressione TarGzip/Tar. Indica se mantenere il nome del file compresso di origine come struttura delle cartelle durante la copia. - Se impostato su true (impostazione predefinita), il servizio scrive i file decompressi in <path specified in dataset>/<folder named as source compressed file>/. - Se impostato su false, il servizio scrive i file decompressi direttamente in <path specified in dataset>. Assicurarsi di non avere nomi di file duplicati in file di origine diversi per evitare corse o comportamenti imprevisti. |
No |
JSON come sink
Nella sezione *sink* dell'attività Copy sono supportate le proprietà seguenti.
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type dell'origine dell'attività Copy deve essere impostata su JSONSink. | Sì |
| formatSettings | Gruppo di proprietà. Fare riferimento alla tabella impostazioni di scrittura JSON seguente. | No |
| storeSettings | Gruppo di proprietà su come scrivere i dati in un archivio dati. Ogni connettore basato su file dispone di impostazioni di scrittura supportate in storeSettings.
Visualizza i dettagli nell'articolo del connettore -> attività Copy proprietà. |
No |
Le impostazioni di scrittura JSON supportate in formatSettings:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | Il tipo di formatSettings deve essere impostato su JsonWriteSettings. | Sì |
| filePattern | Indicare il modello dei dati archiviati in ogni file JSON. I valori consentiti sono: setOfObjects (linee JSON) e arrayOfObjects. Il valore predefinito è setOfObjects. Vedere la sezione Modelli di file JSON per i dettagli su questi modelli. | No |
Modelli di file JSON
Quando si copiano dati da file JSON, l'attività Copy può rilevare e analizzare automaticamente i modelli di file JSON seguenti. Quando si scrivono dati in file JSON, è possibile configurare il modello di file nel sink dell'attività Copy.
Tipo I: setOfObjects
Ogni file contiene un singolo oggetto, linee JSON o oggetti concatenati.
Esempio di JSON a oggetto singolo
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }Linee JSON (impostazione predefinita per sink)
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"} {"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"} {"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"345626404","switch1":"Germany","switch2":"UK"}Esempio di JSON concatenati
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" } { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" } { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" }
Tipo II: arrayOfObjects
Ogni file contiene una matrice di oggetti.
[ { "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }, { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" }, { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" } ]
Proprietà del flusso di dati per mapping
In mapping dei flussi di dati è possibile leggere e scrivere in formato JSON negli archivi dati seguenti: Archiviazione BLOB di Azure, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2 e SFTP ed è possibile leggere il formato JSON in Amazon S3.
Proprietà di origine
La tabella seguente elenca le proprietà supportate da un'origine JSON. È possibile modificare queste proprietà nella scheda Opzioni origine.
| Nome | Descrizione | Richiesto | Valori consentiti | Proprietà script del flusso di dati |
|---|---|---|---|---|
| Percorsi con caratteri jolly | Verranno elaborati tutti i file corrispondenti al percorso con caratteri jolly. Esegue l'override della cartella e del percorso del file impostato nel set di dati. | no | String[] | wildcardPaths |
| Partition Root Path (Percorso radice partizione) | Per i dati dei file partizionati, è possibile immettere un percorso radice della partizione per leggere le cartelle partizionate come colonne | no | String | partitionRootPath |
| Elenco di file | Indica se l'origine punta a un file di testo che elenca i file da elaborare | no |
true oppure false |
fileList |
| Colonna in cui archiviare il nome file | Creare una nuova colonna con il nome e il percorso del file di origine | no | String | rowUrlColumn |
| Dopo il completamento | Eliminare o spostare i file dopo l'elaborazione. Il percorso del file inizia dalla radice del contenitore | no | Eliminare: true o false Spostare: ['<from>', '<to>'] |
purgeFiles moveFiles |
| Filtra per data ultima modifica | Scegliere di filtrare i file in base all'ultima modifica | no | Timestamp: | modifiedAfter modifiedBefore |
| Documento singolo | I flussi di dati di mapping leggono un documento JSON da ogni file | no |
true oppure false |
singleDocument |
| Nomi di colonna non racchiusi tra virgolette | Se è selezionato Nomi di colonna senza virgolette, il flusso di dati per il mapping legge colonne JSON non racchiuse tra virgolette. | no |
true oppure false |
unquotedColumnNames |
| Contiene commenti | Selezionare Contiene commenti se i dati JSON contengono commenti in stile C o C++ | no |
true oppure false |
asComments |
| Virgolette singole | Legge colonne JSON che non sono racchiuse tra virgolette | no |
true oppure false |
singleQuoted |
| Carattere di escape barra rovesciata | Selezionare il carattere di escape barra rovesciata se le barre rovesciate vengono usate per eseguire l'escape dei caratteri nei dati JSON | no |
true oppure false |
backslashEscape |
| Consenti nessun file trovato | Se true, un errore non viene generato se non vengono trovati file | no |
true oppure false |
ignoreNoFilesFound |
Set di dati inline
I flussi di dati di mapping supportano "set di dati inline" come opzione per definire l'origine e il sink. Un set di dati JSON inline viene definito direttamente all'interno delle trasformazioni di origine e sink e non viene condiviso al di fuori del flusso di dati definito. È utile per la parametrizzazione delle proprietà del set di dati direttamente all'interno del flusso di dati e può trarre vantaggio da prestazioni migliorate rispetto ai set di dati di ADF condivisi.
Quando si legge un numero elevato di cartelle e file di origine, è possibile migliorare le prestazioni dell'individuazione dei file del flusso di dati impostando l'opzione "Schema proiettato dall'utente" all'interno della proiezione | Finestra di dialogo Opzioni schema. Questa opzione disattiva l'individuazione automatica dello schema predefinito di ADF e migliorerà notevolmente le prestazioni dell'individuazione dei file. Prima di impostare questa opzione, assicurarsi di importare la proiezione JSON in modo che ADF abbia uno schema esistente per la proiezione. Questa opzione non funziona con lo spostamento schema.
Opzioni formato di origine
L'uso di un set di dati JSON come origine nel flusso di dati consente di impostare cinque impostazioni aggiuntive. Queste impostazioni sono disponibili nell'accordion impostazioni JSON nella scheda Opzioni origine. Per l'impostazione del Modulo documento, è possibile selezionare uno dei tipi di Documento singolo, Documento per riga e Matrice di documenti.
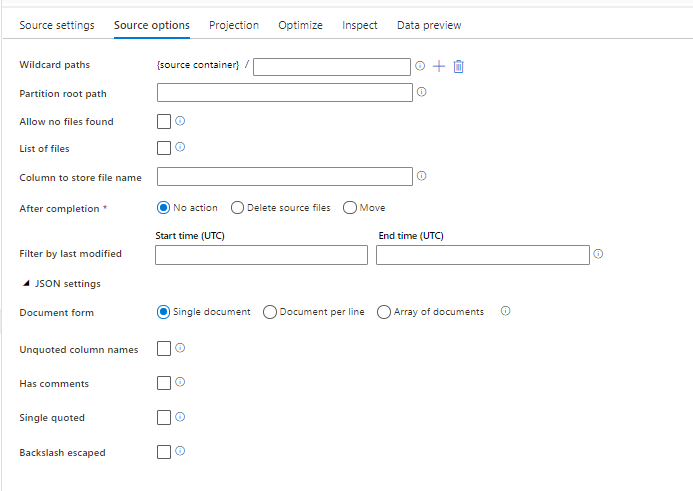
Default
Per impostazione predefinita, i dati JSON vengono letti nel formato seguente.
{ "json": "record 1" }
{ "json": "record 2" }
{ "json": "record 3" }
Documento singolo
Se è selezionato Documento singolo, i flussi di dati di mapping leggono un documento JSON da ogni file.
File1.json
{
"json": "record 1"
}
File2.json
{
"json": "record 2"
}
File3.json
{
"json": "record 3"
}
Se è selezionato Documento per riga, i flussi di dati di mapping leggono un documento JSON da ogni riga di un file.
File1.json
{"json": "record 1"}
File2.json
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"}
{"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"}
File3.json
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"}
{"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"}
{"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"345626404","switch1":"Germany","switch2":"UK"}
Se è selezionata Matrice di documenti, i flussi di dati di mapping leggono una matrice di documenti da un file.
File.json
[
{
"time": "2015-04-29T07:12:20.9100000Z",
"callingimsi": "466920403025604",
"callingnum1": "678948008",
"callingnum2": "567834760",
"switch1": "China",
"switch2": "Germany"
},
{
"time": "2015-04-29T07:13:21.0220000Z",
"callingimsi": "466922202613463",
"callingnum1": "123436380",
"callingnum2": "789037573",
"switch1": "US",
"switch2": "UK"
},
{
"time": "2015-04-29T07:13:21.4370000Z",
"callingimsi": "466923101048691",
"callingnum1": "678901578",
"callingnum2": "345626404",
"switch1": "Germany",
"switch2": "UK"
}
]
Nota
Se i flussi di dati generano un errore che indica "corrupt_record" durante l'anteprima dei dati JSON, è probabile che i dati contengano un singolo documento nel file JSON. L'impostazione "documento singolo" dovrebbe cancellare tale errore.
Nomi di colonna non racchiusi tra virgolette
Se è selezionato Nomi di colonna senza virgolette, il flusso di dati per il mapping legge colonne JSON non racchiuse tra virgolette.
{ json: "record 1" }
{ json: "record 2" }
{ json: "record 3" }
Contiene commenti
Selezionare Contiene commenti se i dati JSON hanno commenti in stile C o C++.
{ "json": /** comment **/ "record 1" }
{ "json": "record 2" }
{ /** comment **/ "json": "record 3" }
Virgolette singole
Selezionare Virgolette singole se i campi e i valori JSON usano virgolette singole anziché virgolette doppie.
{ 'json': 'record 1' }
{ 'json': 'record 2' }
{ 'json': 'record 3' }
Carattere di escape barra rovesciata
Selezionare il carattere di escape barra rovesciata se vengono usate barre rovesciate per eseguire l'escape dei caratteri nei dati JSON.
{ "json": "record 1" }
{ "json": "\} \" \' \\ \n \\n record 2" }
{ "json": "record 3" }
Proprietà sink
La tabella seguente elenca le proprietà supportate da un sink JSON. È possibile modificare queste proprietà nella scheda Impostazioni.
| Nome | Descrizione | Richiesto | Valori consentiti | Proprietà script del flusso di dati |
|---|---|---|---|---|
| Cancellare la cartella | Se la cartella di destinazione viene cancellata prima della scrittura | no |
true oppure false |
truncate |
| Opzione Nome file | Formato di denominazione dei dati scritti. Per impostazione predefinita, un file per partizione in formato part-#####-tid-<guid> |
no | Motivo: Stringa Per partizione: Stringa[] Come dati nella colonna: Stringa Output in un singolo file: ['<fileName>'] |
filePattern partitionFileNames rowUrlColumn partitionFileNames |
Creazione di strutture JSON in una colonna derivata
È possibile aggiungere una colonna complessa al flusso di dati tramite il generatore di espressioni di colonna derivata. Nella trasformazione colonna derivata aggiungere una nuova colonna e aprire il generatore di espressioni facendo clic sulla casella blu. Per rendere complessa una colonna, è possibile immettere manualmente la struttura JSON o usare l'esperienza utente per aggiungere sottocolonne in modo interattivo.
Uso dell'esperienza utente del generatore di espressioni
Nel riquadro laterale dello schema di output passare il puntatore del mouse su una colonna e fare clic sull'icona con il segno più. Selezionare Aggiungi sottocolonna per rendere la colonna un tipo complesso.
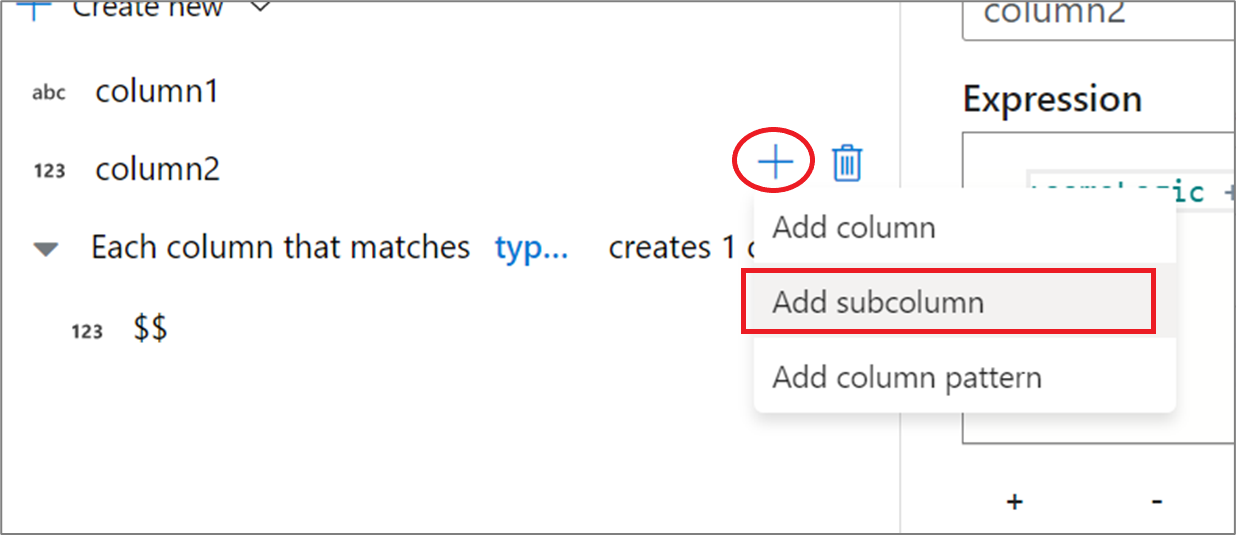
È possibile aggiungere altre colonne e sottocolonne nello stesso modo. Per ogni campo non complesso, è possibile aggiungere un'espressione nell'editor di espressioni a destra.
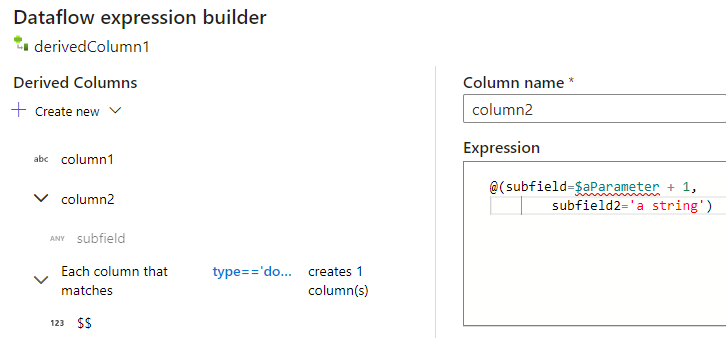
Immissione manuale della struttura JSON
Per aggiungere manualmente una struttura JSON, aggiungere una nuova colonna e immettere l'espressione nell'editor. L'espressione segue il formato generale seguente:
@(
field1=0,
field2=@(
field1=0
)
)
Se questa espressione fosse inserita per una colonna denominata "complexColumn", verrebbe scritta nel sink come il JSON seguente:
{
"complexColumn": {
"field1": 0,
"field2": {
"field1": 0
}
}
}
Script manuale di esempio per la definizione gerarchica completa
@(
title=Title,
firstName=FirstName,
middleName=MiddleName,
lastName=LastName,
suffix=Suffix,
contactDetails=@(
email=EmailAddress,
phone=Phone
),
address=@(
line1=AddressLine1,
line2=AddressLine2,
city=City,
state=StateProvince,
country=CountryRegion,
postCode=PostalCode
),
ids=[
toString(CustomerID), toString(AddressID), rowguid
]
)
Connettori e formati correlati
Ecco alcuni connettori e formati comuni correlati al formato JSON: