Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
SI APPLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Questo articolo descrive quali set di dati sono, come vengono definiti in formato JSON e come vengono usati nelle pipeline di Azure Data Factory e Synapse.
Se non si ha familiarità con Data Factory, vedere Introduzione ad Azure Data Factory per una panoramica. Per altre informazioni su Azure Synapse, vedere Informazioni su Azure Synapse
Panoramica
Un'area di lavoro di Azure Data Factory o Synapse può avere una o più pipeline. Una pipeline è un raggruppamento logico di attività che insieme eseguono un compito. Le attività in una pipeline definiscono le azioni da eseguire sui dati. Un set di dati è una visualizzazione dati denominata che punta o fa riferimento ai dati usati come input e output nelle attività. I set di dati identificano i dati all'interno dei diversi archivi dati, come tabelle, file, cartelle e documenti. Ad esempio, un set di dati BLOB di Azure specifica il contenitore BLOB e la cartella in Archiviazione BLOB da cui l'attività deve leggere i dati.
Prima di creare un set di dati, è necessario creare un servizio collegato per collegare l'archivio dati al servizio. I servizi collegati sono molto simili a stringhe di connessione e definiscono le informazioni necessarie per la connessione del servizio a risorse esterne. In altre parole, il set di dati rappresenta la struttura dei dati all'interno degli archivi dati collegati e il servizio collegato definisce la connessione all'origine dati. Ad esempio, un servizio collegato Archiviazione di Azure collega un account di archiviazione. Un set di dati BLOB di Azure rappresenta il contenitore BLOB e la cartella all'interno dell'account di Archiviazione di Azure che contiene i BLOB di input da elaborare.
Ecco uno scenario di esempio. Per copiare dati dall'archivio BLOB a un database SQL, creare due servizi collegati: Archiviazione BLOB di Azure e database SQL di Azure. Creare quindi due set di dati: set di dati Delimited Text (che fa riferimento al servizio collegato Archiviazione BLOB di Azure, presupponendo che siano presenti file di testo come origine) e set di dati di tabella SQL di Azure (che fa riferimento al servizio collegato database SQL di Azure). I servizi collegati Archiviazione BLOB di Azure e database SQL di Azure contengono stringa di connessione usati dal servizio in fase di esecuzione per connettersi al Archiviazione di Azure e all'database SQL di Azurerispettivamente. Il set di dati Delimited Text specifica il contenitore BLOB e la cartella BLOB che contiene i BLOB di input nell'archivio BLOB, insieme alle impostazioni relative al formato. Il set di dati della tabella SQL di Azure specifica la tabella SQL del database SQL in cui verranno copiati i dati.
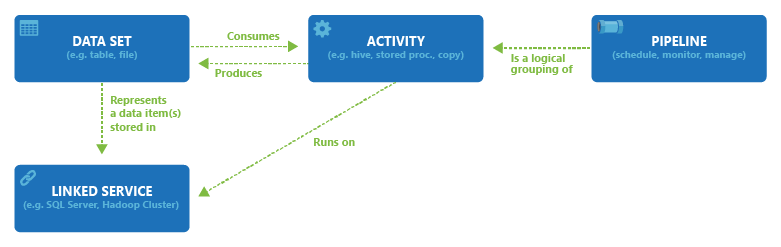
Il diagramma seguente illustra le relazioni tra pipeline, attività, set di dati e servizi collegati:
Creare un set di dati con l'interfaccia utente
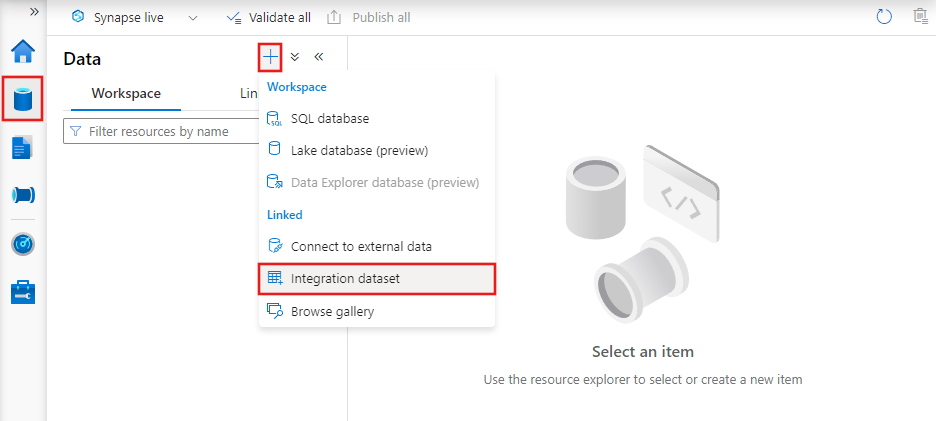
Per creare un set di dati con Azure Data Factory Studio, selezionare la scheda Autore (con l'icona a forma di matita) e quindi l'icona del segno più per scegliere Set di dati.
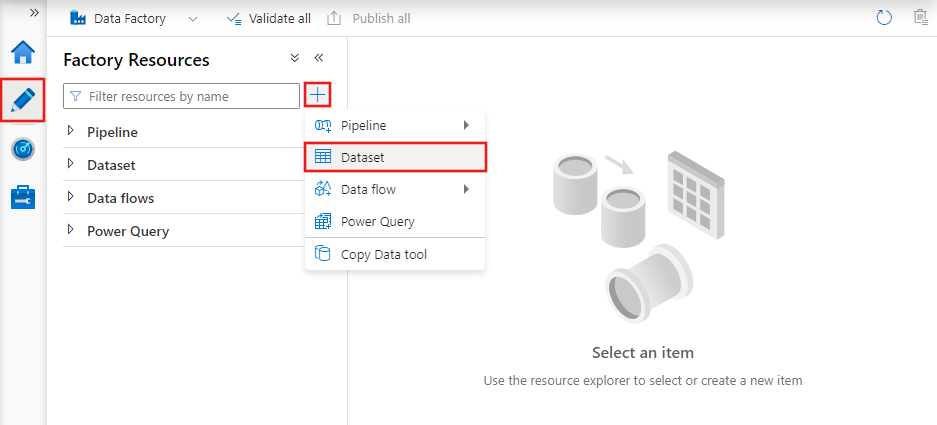
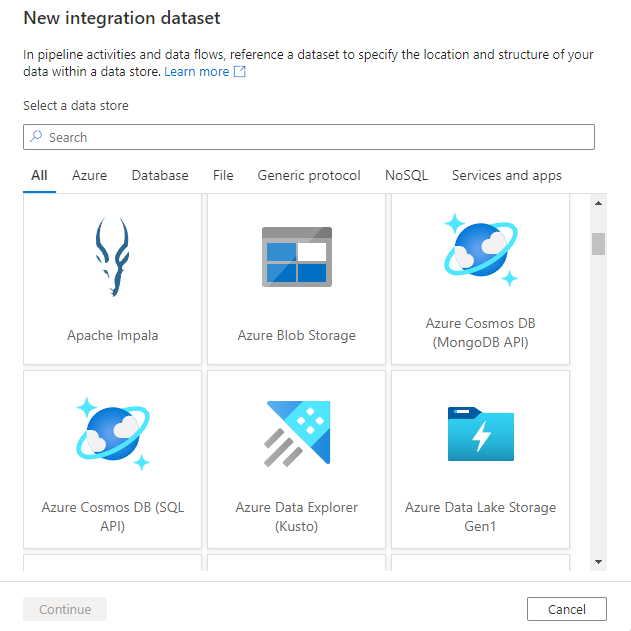
Verrà visualizzata la nuova finestra del set di dati per scegliere uno dei connettori disponibili in Azure Data Factory per configurare un servizio collegato esistente o nuovo.
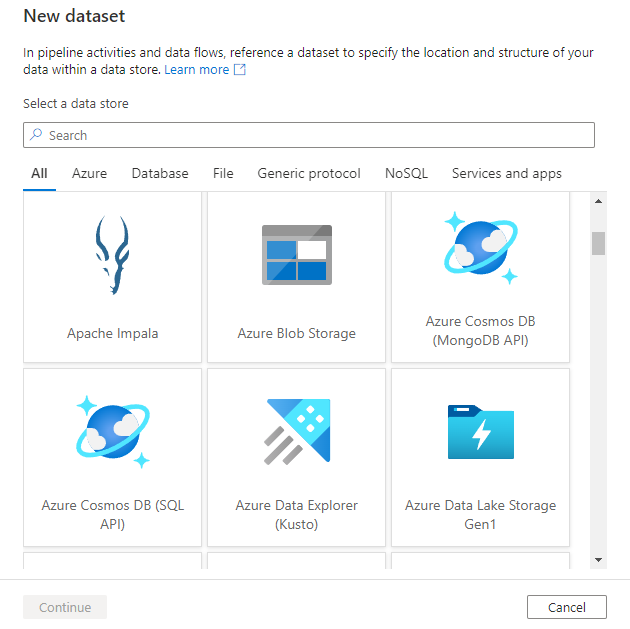
Verrà quindi richiesto di scegliere il formato del set di dati.

Infine, è possibile scegliere un servizio collegato esistente del tipo selezionato per il set di dati oppure crearne uno nuovo se non è già definito.
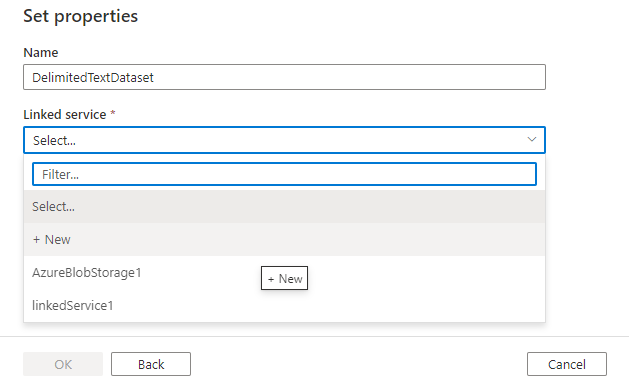
Dopo aver creato il set di dati, è possibile usarlo all'interno di qualsiasi pipeline in Azure Data Factory.
Set di dati JSON
Un set di dati è definito nel formato JSON seguente:
{
"name": "<name of dataset>",
"properties": {
"type": "<type of dataset: DelimitedText, AzureSqlTable etc...>",
"linkedServiceName": {
"referenceName": "<name of linked service>",
"type": "LinkedServiceReference",
},
"schema":[
],
"typeProperties": {
"<type specific property>": "<value>",
"<type specific property 2>": "<value 2>",
}
}
}
La tabella seguente descrive le proprietà nel codice JSON precedente:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| name | Nome del set di dati. Vedere Regole di denominazione delle code. | Sì |
| type | Tipo del set di dati. Specificare uno dei tipi supportati da Data Factory, ad esempio DelimitedText, AzureSqlTable. Per informazioni dettagliate, vedere Tipi di set di dati. |
Sì |
| schema | Lo schema del set di dati rappresenta il tipo di dati fisico e la forma. | No |
| typeProperties | Le proprietà del tipo sono diverse per ogni tipo. Per informazioni dettagliate sui tipi supportati e le relative proprietà, vedere la sezione Tipo di set di dati. | Sì |
Quando si importa lo schema del set di dati, selezionare il pulsante Importa schema e scegliere di importare dall'origine o da un file locale. Nella maggior parte dei casi, lo schema verrà importato direttamente dall'origine. Tuttavia, se si dispone già di un file di schema locale (un file Parquet o CSV con intestazioni), è possibile indirizzare il servizio a basare lo schema su tale file.
Nell'attività di copia i set di dati vengono usati nell'origine e nel sink. Lo schema definito nel set di dati è facoltativo come riferimento. Per applicare il mapping di colonne/campi tra origine e sink, fare riferimento a Schema e mapping dei tipi.
In Flusso di dati i set di dati vengono usati nelle trasformazioni di origine e sink. I set di dati definiscono gli schemi di base dei dati. Se i dati non hanno uno schema, è possibile usare la deviazione dello schema per l'origine e il sink. I metadati dei set di dati vengono visualizzati nella trasformazione di origine come proiezione di origine. La proiezione nella trasformazione origine rappresenta i dati di Flusso di dati con nomi e tipi definiti.
Tipo di set di dati
Il servizio supporta molti tipi diversi di set di dati, a seconda degli archivi dati usati. È possibile trovare l'elenco degli archivi dati supportati dall'articolo Panoramica del connettore. Selezionare un archivio dati per informazioni su come creare un servizio collegato e un set di dati.
Ad esempio, per un set di dati Delimited Text, il tipo di set di dati è impostato su DelimitedText , come illustrato nell'esempio JSON seguente:
{
"name": "DelimitedTextInput",
"properties": {
"linkedServiceName": {
"referenceName": "AzureBlobStorage",
"type": "LinkedServiceReference"
},
"annotations": [],
"type": "DelimitedText",
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"fileName": "input.log",
"folderPath": "inputdata",
"container": "adfgetstarted"
},
"columnDelimiter": ",",
"escapeChar": "\\",
"quoteChar": "\""
},
"schema": []
}
}
Nota
Il valore dello schema viene definito usando la sintassi JSON. Per informazioni più dettagliate sul mapping dello schema e sul mapping dei tipi di dati, vedere la documentazione relativa allo schema dell'attività di copia di Azure Data Factory e al mapping dei tipi .
Creare i set di dati
È possibile creare set di dati tramite uno di questi strumenti o SDK: API .NET, PowerShell, API REST, modello di Azure Resource Manager e portale di Azure
Set di dati della versione corrente e set di dati della versione 1
Ecco alcune differenze tra i set di dati nella versione corrente di Data Factory (e Azure Synapse) e la versione legacy di Data Factory versione 1:
- La proprietà esterna non è supportata nella versione corrente. e viene sostituita da un trigger.
- I criteri e le proprietà di disponibilità non sono supportati nella versione corrente. L'ora di inizio di una pipeline dipende da trigger.
- I set di dati con ambito (set di dati definiti in una pipeline) non sono supportati nella versione corrente.
Contenuto correlato
Avvi rapidi
Vedere le esercitazioni seguenti per istruzioni dettagliate sulla creazione di pipeline e set di dati tramite uno di questi strumenti o SDK.
- Quickstart: create a data factory using .NET (Avvio rapido: Creare una data factory tramite .NET)
- Quickstart: create a data factory using PowerShell (Avvio rapido: Creare una data factory tramite PowerShell)
- Quickstart: create a data factory using REST API (Avvio rapido: Creare una data factory tramite API REST)
- Avvio rapido: Creare una data factory con il portale di Azure