Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
APPLICABILE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Data Factory in Microsoft Fabric è la nuova generazione di Azure Data Factory, con un'architettura più semplice, un'intelligenza artificiale predefinita e nuove funzionalità. Se non si ha familiarità con l'integrazione dei dati, iniziare con Fabric Data Factory. I carichi di lavoro di Azure Data Factory esistenti possono eseguire l'aggiornamento a Fabric per accedere a nuove funzionalità tra data science, analisi in tempo reale e creazione di report.
L'attività di ricerca può recuperare un set di dati da una qualsiasi delle origini dati supportate dalle pipeline di Data Factory e Synapse. È possibile usarlo per determinare in modo dinamico gli oggetti su cui operare in un'attività successiva, anziché impostare come hardcoded il nome dell'oggetto. Alcuni esempi di oggetti sono file e tabelle.
L'attività Lookup legge e restituisce il contenuto di un file di configurazione o una tabella. Restituisce anche il risultato dell'esecuzione di una query o di una stored procedure. L'output può essere un valore singolo o una matrice di attributi, che possono essere utilizzati in attività di copia, trasformazione o attività di flusso di controllo successive, come l'attività ForEach.
Creare un'attività di ricerca con l'interfaccia utente
Per usare un'attività di ricerca in una pipeline, completare la procedura seguente:
Cercare Ricerca nel riquadro Attività della pipeline, quindi trascinare un'attività Ricerca nel canvas della pipeline.
Selezionare la nuova attività Ricerca nell'area di disegno se non è già selezionata e la relativa scheda Impostazioni per modificarne i dettagli.
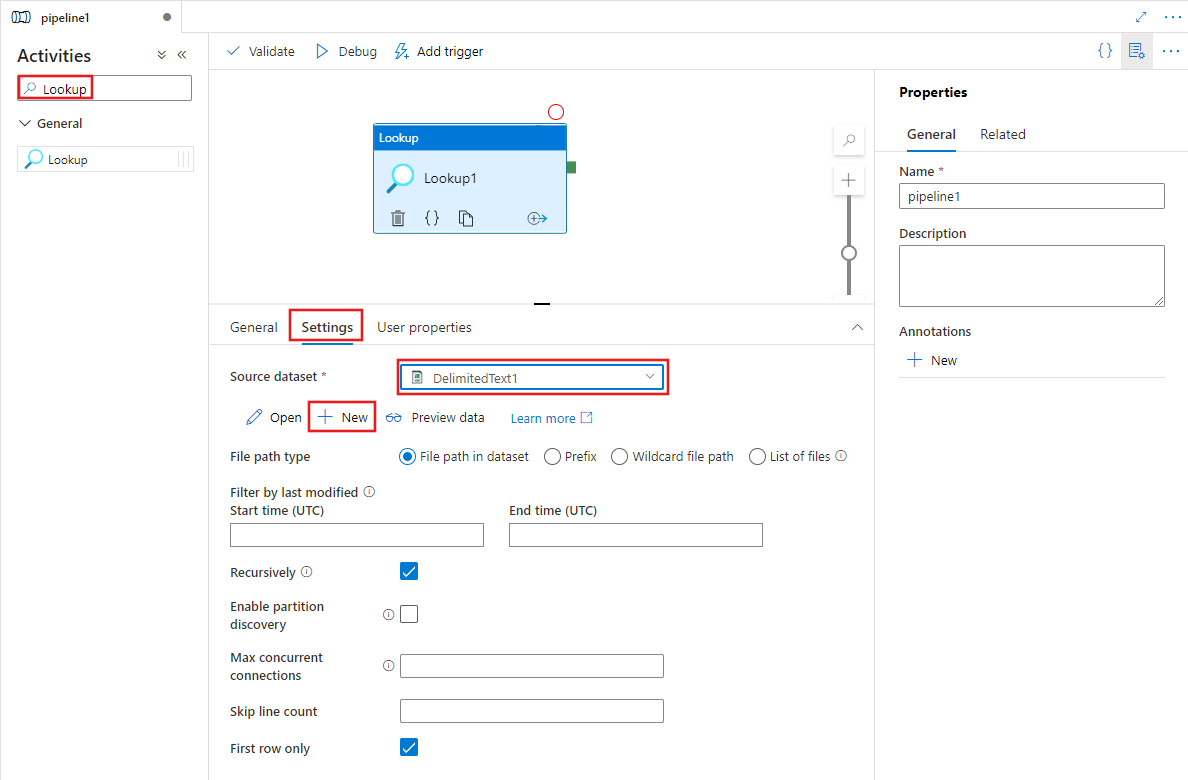
Scegliere un set di dati di origine esistente o selezionare il pulsante Nuovo per crearne uno nuovo.
Le opzioni per identificare le righe da includere nel set di dati di origine variano in base al tipo di set di dati. L'esempio precedente mostra le opzioni di configurazione per un set di dati di testo delimitato. Di seguito sono riportati esempi di opzioni di configurazione per un set di dati di tabella Azure SQL e un set di dati OData.
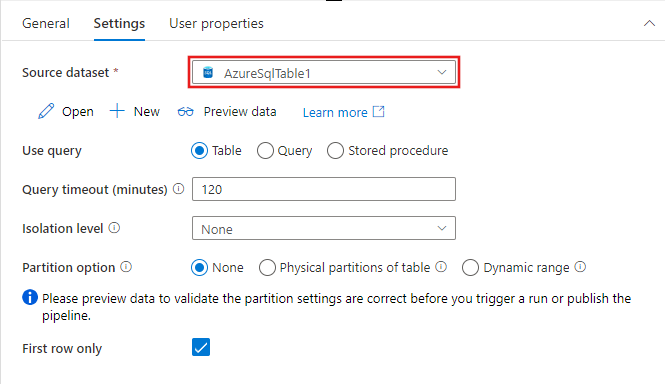
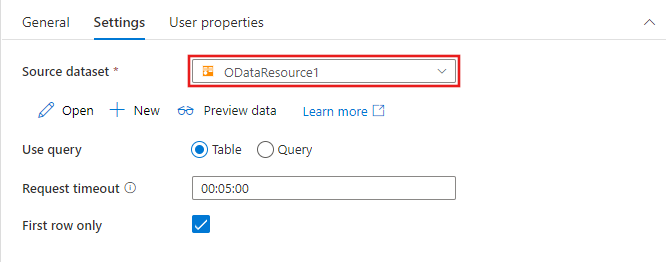
Funzionalità supportate
Notare quanto segue:
- L'attività di ricerca può restituire fino a 5000 righe; se il set di risultati contiene più record, verranno restituite le prime 5000 righe.
- L'output dell'attività Ricerca supporta fino a 4 MB; l'attività avrà esito negativo se le dimensioni superano questo limite.
- La durata più lunga per l'attività di ricerca prima del timeout è di 24 ore.
Nota
Quando si utilizza una query o una stored procedure per cercare i dati, assicurarsi di restituire esattamente un solo set di risultati. In caso contrario, l'attività di ricerca ha esito negativo.
Sono attualmente supportate le seguenti origini dati per l'attività Lookup.
Nota
Se un connettore è contrassegnato come Anteprima, è possibile provarlo e inviare commenti e suggerimenti. Se si vuole adottare una dipendenza dai connettori di anteprima nella soluzione, contattare Azure support.
Sintassi
{
"name":"LookupActivity",
"type":"Lookup",
"typeProperties":{
"source":{
"type":"<source type>"
},
"dataset":{
"referenceName":"<source dataset name>",
"type":"DatasetReference"
},
"firstRowOnly":<true or false>
}
}
Proprietà del tipo
| Nome | Descrizione | Tipo | Obbligatorio? |
|---|---|---|---|
| set di dati | Fornisce il riferimento al set di dati per la ricerca. Per i dettagli, vedere la sezione Proprietà del set di dati nell'articolo del connettore corrispondente. | Coppia chiave/valore | Sì |
| source | Contiene proprietà di origine specifiche del set di dati, come per l'origine dell'attività Copy. Ottieni i dettagli dalla sezione Proprietà dell'attività di copia in ogni articolo corrispondente del connettore. | Coppia chiave/valore | Sì |
| firstRowOnly | Indica se restituire solo la prima riga o tutte le righe. | Booleano | No. Il valore predefinito è true. |
Nota
- Le colonne Source con tipo ByteArray non sono supportate.
- Structure non è supportato nella definizione del set di dati. Per i file in formato testo, è possibile usare la riga di intestazione per specificare il nome della colonna.
- Se l'origine della ricerca è un file JSON, l'impostazione
jsonPathDefinitionper la modifica della forma dell'oggetto JSON non è supportata. Vengono recuperati gli interi oggetti.
Usare il risultato dell'attività Lookup
Il risultato della ricerca viene restituito nella sezione output del risultato dell'esecuzione dell'attività.
Se
firstRowOnlyè impostato sutrue(impostazione predefinita), il formato di output è mostrato nel codice seguente. Il risultato della ricerca è sotto una chiavefirstRowfissa. Per usare il risultato in un'attività successiva, usare il criterio di@{activity('LookupActivity').output.firstRow.table}.{ "firstRow": { "Id": "1", "schema":"dbo", "table":"Table1" } }Se
firstRowOnlyè impostato sufalse, il formato di output è mostrato nel codice seguente. Un campocountindica il numero di record restituiti. I valori dettagliati sono visualizzati sotto una matricevaluefissa. In questo caso l'attività Lookup è seguita da un'attività ForEach. Per passare l'arrayvalueal campoitemsdell'attività ForEach, usare il criterio di@activity('MyLookupActivity').output.value. Per accedere agli elementi nell'arrayvalue, usare la sintassi seguente:@{activity('lookupActivity').output.value[zero based index].propertyname}. Un esempio è@{activity('lookupActivity').output.value[0].schema}.{ "count": "2", "value": [ { "Id": "1", "schema":"dbo", "table":"Table1" }, { "Id": "2", "schema":"dbo", "table":"Table2" } ] }
Esempio
In questo esempio la pipeline contiene due attività: Ricerca e Copia. L'attività di copia trasferisce i dati da una tabella SQL nella tua istanza di Azure SQL Database all'archiviazione BLOB di Azure. Il nome della tabella SQL viene archiviato in un file JSON in Archiviazione BLOB. L'attività Lookup cerca il nome della tabella in fase di esecuzione. Il file JSON viene modificato in modo dinamico usando questo approccio. Non è necessario ridistribuire le pipeline o i set di dati.
In questo esempio viene illustrata la ricerca solo per la prima riga. Per la ricerca per tutte le righe e per concatenare i risultati con l'attività ForEach, vedere gli esempi in Copiare più tabelle in blocco.
Pipeline
- L'attività Lookup è configurata per l'uso di LookupDataset, che fa riferimento a una posizione nell'archivio BLOB Azure. L'attività Lookup legge il nome tabella SQL da un file JSON in questa posizione.
- L'attività Copy usa l'output dell'attività Lookup, ovvero il nome della tabella SQL. La proprietà tableName in SourceDataset è configurata in modo da usare l'output dell'attività Lookup. L'attività di copia trasferisce i dati dalla tabella SQL a un percorso nell'archiviazione BLOB di Azure. Il percorso è specificato dalla proprietà SinkDataset.
{
"name": "LookupPipelineDemo",
"properties": {
"activities": [
{
"name": "LookupActivity",
"type": "Lookup",
"dependsOn": [],
"policy": {
"timeout": "7.00:00:00",
"retry": 0,
"retryIntervalInSeconds": 30,
"secureOutput": false,
"secureInput": false
},
"userProperties": [],
"typeProperties": {
"source": {
"type": "JsonSource",
"storeSettings": {
"type": "AzureBlobStorageReadSettings",
"recursive": true
},
"formatSettings": {
"type": "JsonReadSettings"
}
},
"dataset": {
"referenceName": "LookupDataset",
"type": "DatasetReference"
},
"firstRowOnly": true
}
},
{
"name": "CopyActivity",
"type": "Copy",
"dependsOn": [
{
"activity": "LookupActivity",
"dependencyConditions": [
"Succeeded"
]
}
],
"policy": {
"timeout": "7.00:00:00",
"retry": 0,
"retryIntervalInSeconds": 30,
"secureOutput": false,
"secureInput": false
},
"userProperties": [],
"typeProperties": {
"source": {
"type": "AzureSqlSource",
"sqlReaderQuery": {
"value": "select * from [@{activity('LookupActivity').output.firstRow.schema}].[@{activity('LookupActivity').output.firstRow.table}]",
"type": "Expression"
},
"queryTimeout": "02:00:00",
"partitionOption": "None"
},
"sink": {
"type": "DelimitedTextSink",
"storeSettings": {
"type": "AzureBlobStorageWriteSettings"
},
"formatSettings": {
"type": "DelimitedTextWriteSettings",
"quoteAllText": true,
"fileExtension": ".txt"
}
},
"enableStaging": false,
"translator": {
"type": "TabularTranslator",
"typeConversion": true,
"typeConversionSettings": {
"allowDataTruncation": true,
"treatBooleanAsNumber": false
}
}
},
"inputs": [
{
"referenceName": "SourceDataset",
"type": "DatasetReference",
"parameters": {
"schemaName": {
"value": "@activity('LookupActivity').output.firstRow.schema",
"type": "Expression"
},
"tableName": {
"value": "@activity('LookupActivity').output.firstRow.table",
"type": "Expression"
}
}
}
],
"outputs": [
{
"referenceName": "SinkDataset",
"type": "DatasetReference",
"parameters": {
"schema": {
"value": "@activity('LookupActivity').output.firstRow.schema",
"type": "Expression"
},
"table": {
"value": "@activity('LookupActivity').output.firstRow.table",
"type": "Expression"
}
}
}
]
}
],
"annotations": [],
"lastPublishTime": "2020-08-17T10:48:25Z"
}
}
Set di dati di ricerca
Il set di dati lookup è il file sourcetable.json nella cartella di ricerca Azure Storage specificata dal tipo AzureBlobStorageLinkedService.
{
"name": "LookupDataset",
"properties": {
"linkedServiceName": {
"referenceName": "AzureBlobStorageLinkedService",
"type": "LinkedServiceReference"
},
"annotations": [],
"type": "Json",
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"fileName": "sourcetable.json",
"container": "lookup"
}
}
}
}
Set di dati di origine per l'attività Copy
Il set di dati di origine usa l'output dell'attività Lookup, ovvero il nome della tabella SQL. L'attività di copia trasferisce i dati da questa tabella SQL in un percorso nell'archivio BLOB di Azure. La posizione è specificata dal set di dati sink.
{
"name": "SourceDataset",
"properties": {
"linkedServiceName": {
"referenceName": "AzureSqlDatabase",
"type": "LinkedServiceReference"
},
"parameters": {
"schemaName": {
"type": "string"
},
"tableName": {
"type": "string"
}
},
"annotations": [],
"type": "AzureSqlTable",
"schema": [],
"typeProperties": {
"schema": {
"value": "@dataset().schemaName",
"type": "Expression"
},
"table": {
"value": "@dataset().tableName",
"type": "Expression"
}
}
}
}
Set di dati sink per l'attività Copy
L'attività di copia copia i dati dalla tabella SQL alla cartella filebylookup.csv nella cartella csv in Azure Storage. Il file è specificato dalla proprietà AzureBlobStorageLinkedService.
{
"name": "SinkDataset",
"properties": {
"linkedServiceName": {
"referenceName": "AzureBlobStorageLinkedService",
"type": "LinkedServiceReference"
},
"parameters": {
"schema": {
"type": "string"
},
"table": {
"type": "string"
}
},
"annotations": [],
"type": "DelimitedText",
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"fileName": {
"value": "@{dataset().schema}_@{dataset().table}.csv",
"type": "Expression"
},
"container": "csv"
},
"columnDelimiter": ",",
"escapeChar": "\\",
"quoteChar": "\""
},
"schema": []
}
}
sourcetable.json
È possibile usare i due tipi di formati seguenti per il file sourcetable.json.
Set di oggetti
{
"Id":"1",
"schema":"dbo",
"table":"Table1"
}
{
"Id":"2",
"schema":"dbo",
"table":"Table2"
}
Matrice di oggetti
[
{
"Id": "1",
"schema":"dbo",
"table":"Table1"
},
{
"Id": "2",
"schema":"dbo",
"table":"Table2"
}
]
Limitazioni e soluzioni alternative
Di seguito vengono descritte alcune limitazioni dell'attività Lookup con le soluzioni alternative suggerite.
| Limitazione | Soluzione alternativa |
|---|---|
| Per l'attività Lookup sono previsti un massimo di 5.000 righe e dimensioni massime di 4 MB. | Progettare una pipeline a due livelli in cui la pipeline esterna esegue l'iterazione su una pipeline interna, che recupera i dati che non superano il numero massimo di righe o le dimensioni massime. |
Contenuto correlato
Vedere altre attività del flusso di controllo supportate dalle pipeline di Azure Data Factory e Synapse: