Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
APPLICABILE A: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Suggerimento
Data Factory in Microsoft Fabric è la nuova generazione di Azure Data Factory, con un'architettura più semplice, un'intelligenza artificiale predefinita e nuove funzionalità. Se non si ha familiarità con l'integrazione dei dati, iniziare con Fabric Data Factory. I carichi di lavoro di Azure Data Factory esistenti possono eseguire l'aggiornamento a Fabric per accedere a nuove funzionalità tra data science, analisi in tempo reale e creazione di report.
In questa esercitazione si usa il portale di Azure per creare una pipeline Azure Data Factory. Questa pipeline trasforma i dati usando un'attività Spark e un servizio collegato Azure HDInsight su richiesta.
In questa esercitazione vengono completati i passaggi seguenti:
- Creare una fabbrica di dati.
- Crea una pipeline che utilizza un'attività Spark.
- Attivare un'esecuzione della pipeline.
- Monitorare l'esecuzione della pipeline.
Se non si ha una sottoscrizione Azure, creare un account free prima di iniziare.
Prerequisiti
Nota
È consigliabile usare il modulo Az PowerShell Azure per interagire con Azure. Per iniziare, vedere Installare Azure PowerShell. Per informazioni su come eseguire la migrazione al modulo Az PowerShell, vedere Migrate Azure PowerShell da AzureRM ad Az.
- un account di archiviazione di Azure. Creare uno script Python e un file di input e caricarli in Azure Storage. L'output del programma Spark viene archiviato in questo account di archiviazione. Il cluster Spark su richiesta usa lo stesso account di archiviazione come risorsa di archiviazione primaria.
Nota
HDInsight supporta solo gli account di archiviazione per utilizzo generico di livello Standard. Assicurarsi che l'account non sia un account di archiviazione Premium o solo BLOB.
- Azure PowerShell. Seguire le istruzioni in Come installare e configurare Azure PowerShell.
Caricare lo script Python nell'account di archiviazione BLOB
Creare un file di Python denominato WordCount_Spark.py con il contenuto seguente:
import sys from operator import add from pyspark.sql import SparkSession def main(): spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() lines = spark.read.text("wasbs://adftutorial@<storageaccountname>.blob.core.windows.net/spark/inputfiles/minecraftstory.txt").rdd.map(lambda r: r[0]) counts = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) counts.saveAsTextFile("wasbs://adftutorial@<storageaccountname>.blob.core.windows.net/spark/outputfiles/wordcount") spark.stop() if __name__ == "__main__": main()Sostituire <storageAccountName> con il nome dell'account di archiviazione Azure. Salvare quindi il file.
Nell'archiviazione BLOB di Azure, crea un contenitore denominato adftutorial se non esiste.
Creare una cartella denominata spark.
Creare una sottocartella denominata script nella cartella spark.
Caricare il file WordCount_Spark.py nella sottocartella script.
Caricare il file di input
- Creare un file denominato minecraftstory.txt con del testo. Il programma Spark conta il numero di parole in questo testo.
- Creare una sottocartella denominata inputfiles nella cartella spark.
- Caricare il file minecraftstory.txt nella sottocartella inputfiles.
Creare una data factory
Seguire la procedura descritta nell'articolo Quickstart: Creare una data factory usando il portale di Azure per creare una data factory se non ne hai già una con cui lavorare.
Creare servizi collegati
In questa sezione tu scrivi due servizi collegati:
- Un servizio collegato Azure Storage che collega un account Azure storage alla data factory. Questo archivio viene usato dal cluster HDInsight su richiesta. Contiene anche lo script Spark da eseguire.
- Un servizio HDInsight collegato su richiesta. Azure Data Factory crea automaticamente un cluster HDInsight ed esegue il programma Spark. Elimina quindi il cluster HDInsight dopo un tempo di inattività preconfigurato.
Creare un servizio collegato Azure Storage
Nella home page passare alla scheda Gestisci nel pannello sinistro.
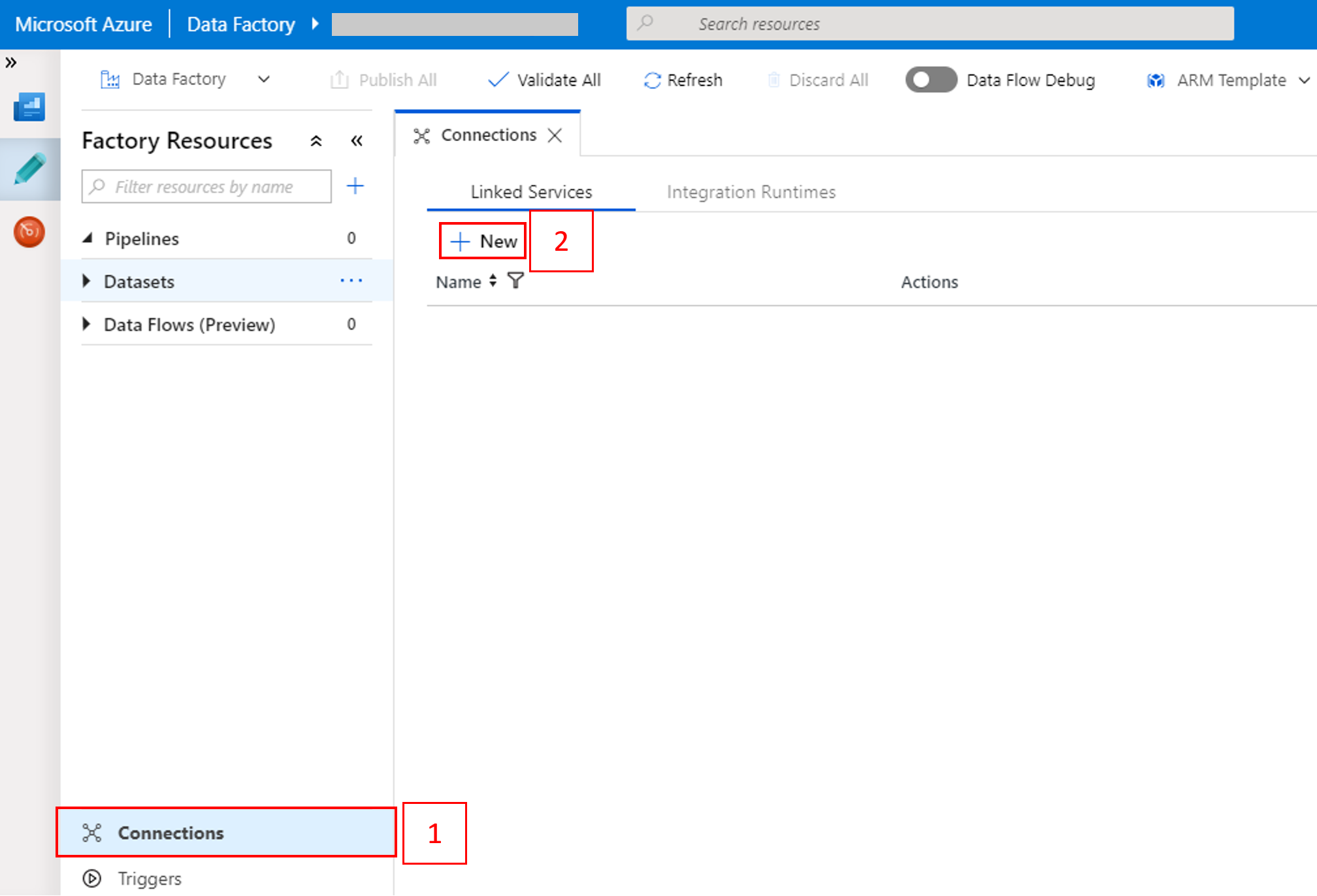
Selezionare Connessioni nella parte inferiore della finestra e quindi + Nuovo.
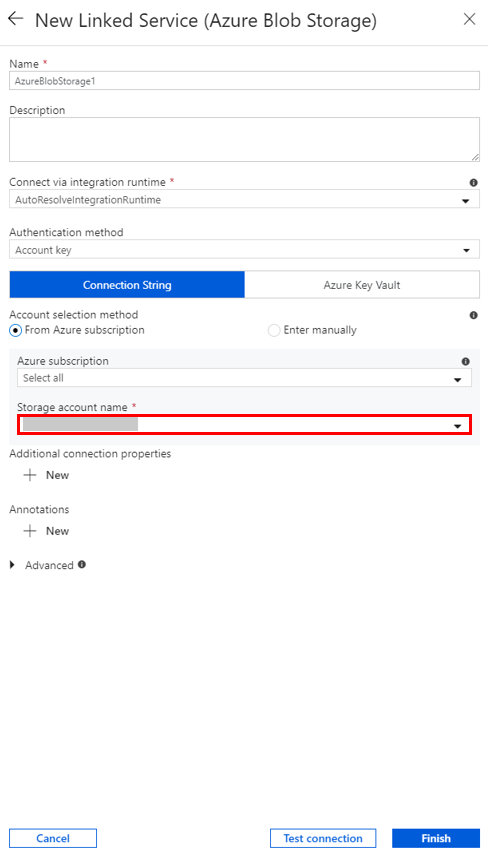
Nella finestra Nuovo servizio collegato selezionare Data Store>Azure Blob Storage e quindi selezionare Continue.

Per Nome account di archiviazione selezionare il nome dell'elenco e quindi selezionare Salva.
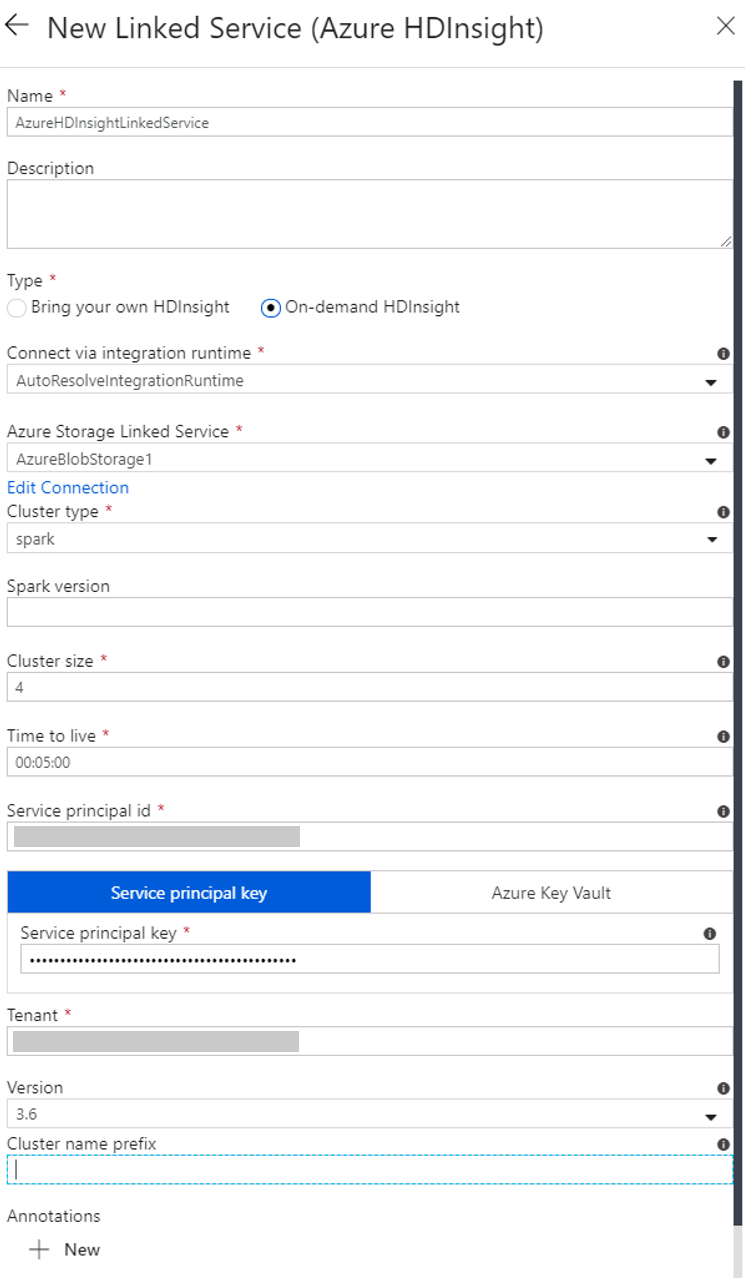
Creare un servizio collegato HDInsight su richiesta
Selezionare il pulsante + Nuovo per creare un altro servizio collegato.
Nella finestra Nuovo servizio collegato selezionare Compute>Azure HDInsight e quindi selezionare Continue.

Nella finestra New Linked Service (Nuovo servizio collegato) completare questa procedura:
a. Per Nome immettere AzureHDInsightLinkedService.
b. Per Tipo verificare che sia selezionata l'opzione On-demand HDInsight (HDInsight su richiesta).
c. Per Servizio collegato di Azure Storage, selezionare AzureBlobStorage1. Questo servizio collegato è stato creato in precedenza. Se è stato usato un nome diverso, specificare il nome corretto qui.
d. Per Tipo di cluster selezionare spark.
e. Per ID entità servizio immettere l'ID dell'entità servizio autorizzata a creare un cluster HDInsight.
Questa entità servizio deve essere un membro del ruolo Collaboratore della sottoscrizione o del gruppo di risorse in cui viene creato il cluster. Per altre informazioni, vedere Creare un'applicazione e un'entità servizio Microsoft Entra. L'ID entità servizio equivale all'ID applicazione e una chiave entità servizio equivale al valore di un segreto client.
f. Per Chiave principale del servizio, immettere la chiave.
g. Per Gruppo di risorse selezionare lo stesso gruppo di risorse usato durante la creazione della data factory. Il cluster Spark viene creato in questo gruppo di risorse.
h. Espandere Tipo di sistema operativo.
i. Immettere un nome in Nome dell'utente del cluster.
j. Immettere la password del cluster per l'utente.
k. Selezionare Fine.
Nota
Azure HDInsight limita il numero totale di core che è possibile usare in ogni area Azure supportata. Per il servizio collegato HDInsight su richiesta, il cluster HDInsight viene creato nella stessa posizione di Azure Storage utilizzata come archiviazione primaria. Assicurati di avere a disposizione quote di core sufficienti per creare con successo il cluster. Per altre informazioni, vedere Configurare i cluster di HDInsight con Hadoop, Spark, Kafka e altro ancora.
Creare una pipeline
Selezionare il pulsante + (segno più) e quindi selezionare Pipeline dal menu.
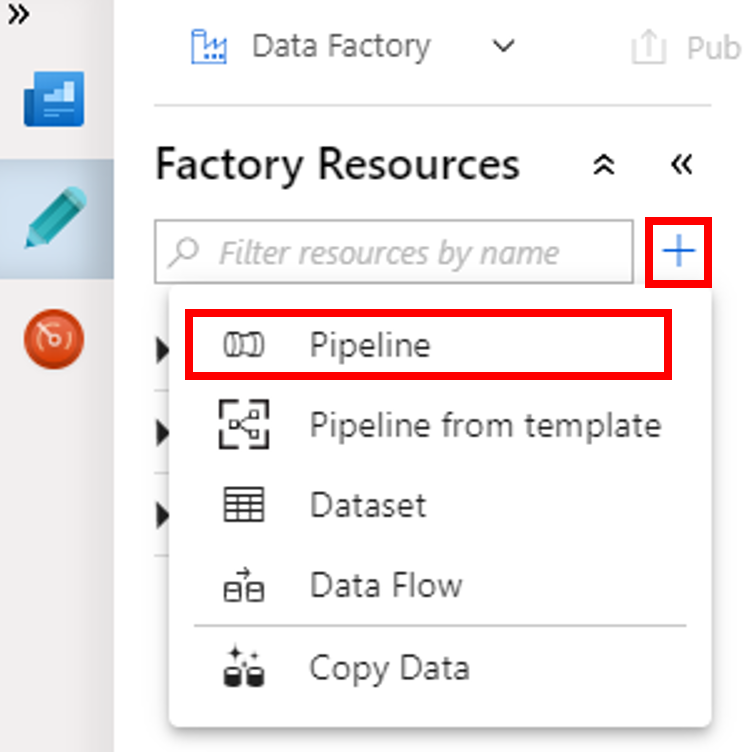
Nella casella degli strumenti Attività espandere HDInsight. Trascinare l'attività Spark dalla casella degli strumenti Attività all'area di progettazione della pipeline.
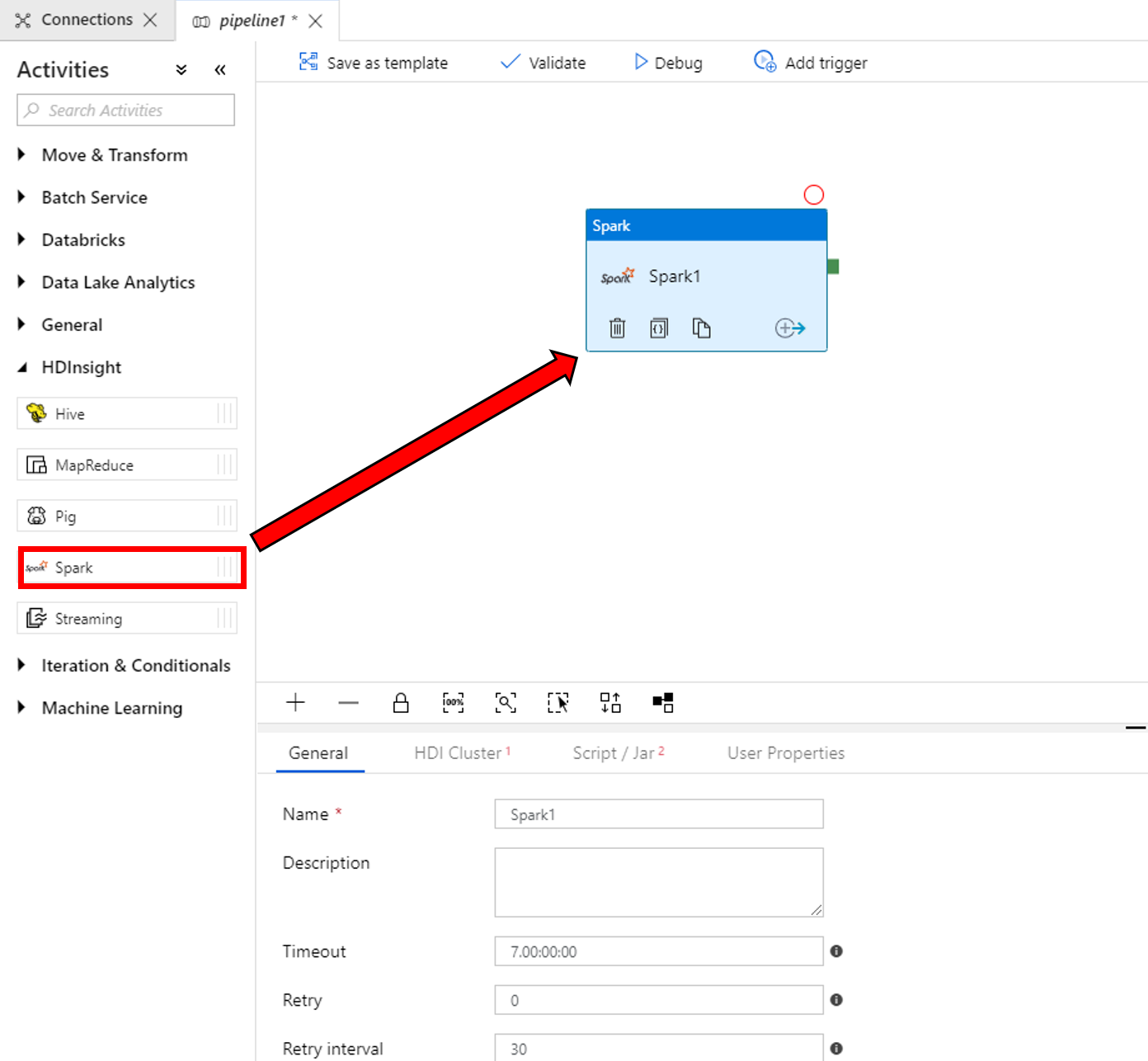
Nelle proprietà della finestra dell'attività Spark in basso completare questa procedura:
a. Passare alla scheda HDI Cluster.
b. Selezionare il servizio AzureHDInsightLinkedService creato nella procedura precedente.
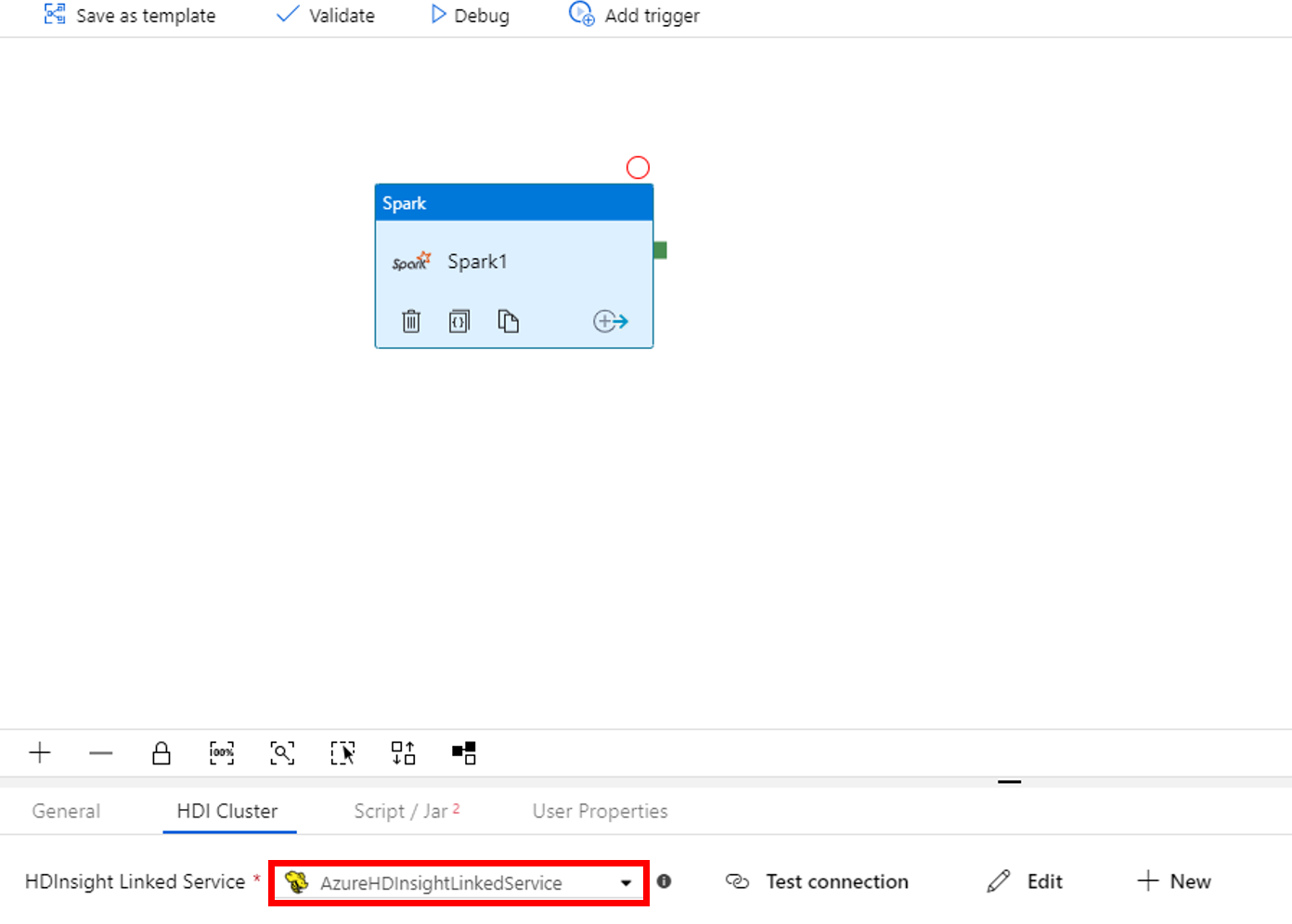
Passare alla scheda Script/Jar e completare questa procedura:
a. Per Job Linked Service, selezionare AzureBlobStorage1.
b. Selezionare Sfoglia archiviazione.
Specificare lo script Spark nella scheda "Script/Jar"
c. Passare alla cartella adftutorial/spark/script, selezionare WordCount_Spark.py e quindi Fine.
Per convalidare la pipeline, selezionare il pulsante Convalida sulla barra degli strumenti. Selezionare il pulsante >> (freccia destra) per chiudere la finestra di convalida.

Selezionare Pubblica tutti. L'interfaccia utente di Data Factory pubblica le entità (servizi collegati e pipeline) nel servizio Azure Data Factory.

Attivare un'esecuzione della pipeline
Selezionare Aggiungi trigger nella barra degli strumenti, quindi selezionare Attiva adesso.

Monitorare l'esecuzione della pipeline
Passare alla scheda Monitoraggio. Verificare che venga visualizzata un'esecuzione della pipeline. La creazione di un cluster Spark richiede circa 20 minuti.
Selezionare periodicamente Aggiorna per controllare lo stato dell'esecuzione della pipeline.
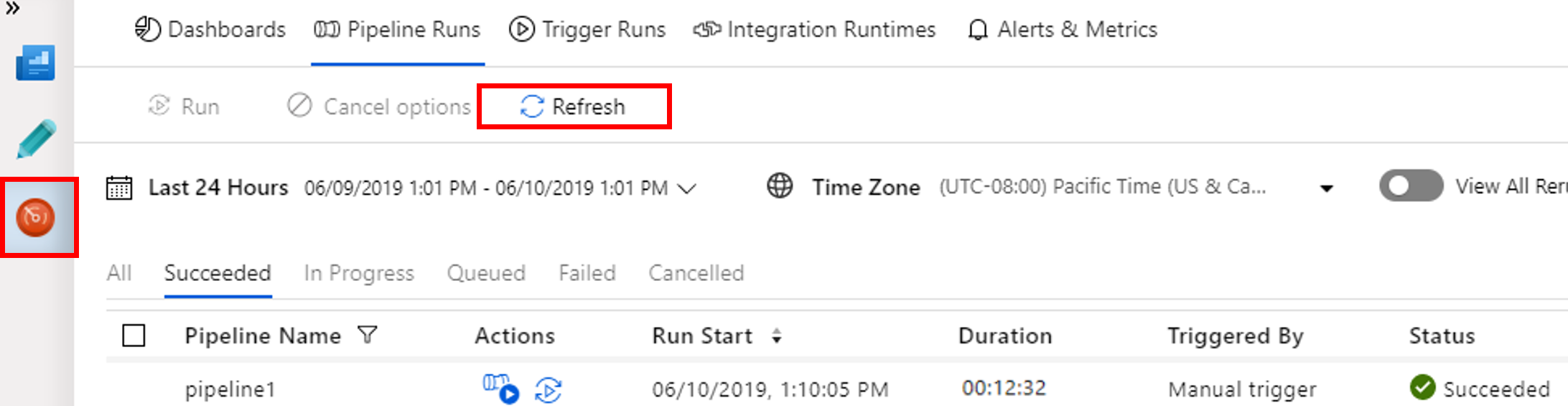
Per visualizzare le esecuzioni di attività associate all'esecuzione della pipeline, selezionare View Activity Runs (Visualizza le esecuzioni di attività) nella colonna Azioni.
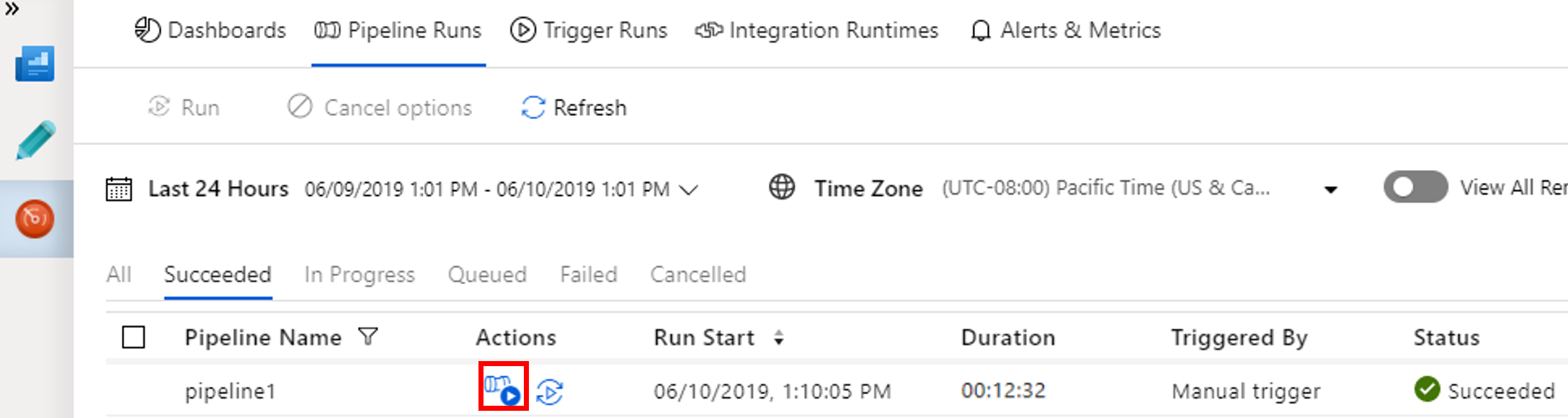
È possibile tornare alla visualizzazione delle sessioni della pipeline selezionando il collegamento Tutte le sessioni della pipeline nella parte superiore.

Verificare l'output
Verificare che il file di output sia stato creato nella cartella spark/otuputfiles/wordcount del contenitore adftutorial.
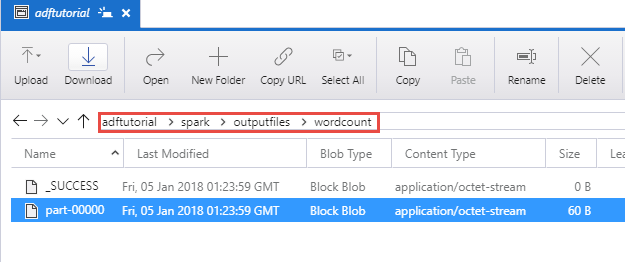
Il file dovrebbe contenere ogni parola del file di testo di input e il numero di occorrenze della parola nel file. Ad esempio:
(u'This', 1)
(u'a', 1)
(u'is', 1)
(u'test', 1)
(u'file', 1)
Contenuto correlato
La pipeline in questo esempio trasforma i dati usando un'attività Spark e un servizio HDInsight collegato su richiesta. Si è appreso come:
- Creare una fabbrica di dati.
- Crea una pipeline che utilizza un'attività Spark.
- Attivare un'esecuzione della pipeline.
- Monitorare l'esecuzione della pipeline.
Per informazioni su come trasformare i dati eseguendo uno script Hive in un cluster Azure HDInsight che si trova in una rete virtuale, passare all'esercitazione successiva: