Accedere ad Azure Data Lake Storage con il pass-through delle credenziali di Microsoft Enterprise ID (in precedenza noto come Azure Active Directory) (legacy)
Importante
Questa documentazione è stata ritirata e potrebbe non essere aggiornata.
Il pass-through delle credenziali è deprecato a partire da Databricks Runtime 15.0 e verrà rimosso nelle versioni future di Databricks Runtime. Databricks consiglia di eseguire l'aggiornamento a Unity Catalog. Unity Catalog semplifica la sicurezza e la governance dei dati fornendo una posizione centrale per amministrare e controllare l'accesso ai dati in più aree di lavoro nell'account. Vedere Cos'è Unity Catalog?.
Per il comportamento di sicurezza e governance più alto, contattare il team dell'account Azure Databricks per disabilitare il pass-through delle credenziali nell'account Azure Databricks.
Nota
Questo articolo contiene riferimenti al termine whitelist, un termine che Azure Databricks non usa. Quando il termine verrà rimosso dal software, verrà rimosso anche dall'articolo.
È possibile eseguire l'autenticazione automaticamente per accedere ad Azure Data Lake Storage Gen1 da Azure Databricks (ADLS Gen1) e ADLS Gen2 dai cluster Azure Databricks usando la stessa identità di Microsoft Entra ID (in precedenza Azure Active Directory) usata per accedere ad Azure Databricks. Quando si abilita il pass-through delle credenziali di Azure Data Lake Storage per il cluster, i comandi eseguiti in tale cluster possono leggere e scrivere dati in Azure Data Lake Storage senza che sia necessario configurare le credenziali dell'entità servizio per l'accesso all'archiviazione.
Il pass-through delle credenziali di Azure Data Lake Storage è supportato solo con Azure Data Lake Storage Gen1 e Gen2. Archiviazione BLOB di Azure non supporta il pass-through delle credenziali.
Questo articolo tratta:
- Abilitazione del pass-through delle credenziali per cluster standard e con concorrenza elevata.
- Configurazione del pass-through delle credenziali e inizializzazione delle risorse di archiviazione negli account ADLS.
- Accesso diretto alle risorse ADLS quando è abilitato il pass-through delle credenziali.
- Accesso alle risorse ADLS tramite un punto di montaggio quando è abilitato il pass-through delle credenziali.
- Funzionalità e limitazioni supportate quando si usa il pass-through delle credenziali.
I notebook sono inclusi per fornire esempi di uso del pass-through delle credenziali con gli account di archiviazione ADLS Gen1 e ADLS Gen2.
Fabbisogno
- Piano Premium. Per informazioni dettagliate sull'aggiornamento di un piano Standard a un piano Premium, vedere Effettuare l'aggiornamento o il downgrade di un'area di lavoro di Azure Databricks.
- Un account di archiviazione di Azure Data Lake Storage Gen1 o Gen2. Gli account di archiviazione di Azure Data Lake Storage Gen2 devono usare lo spazio dei nomi gerarchico per utilizzare il pass-through delle credenziali di Azure Data Lake Storage. Per istruzioni sulla creazione di un nuovo account ADLS Gen2 e sull'abilitazione dello spazio dei nomi gerarchico, vedere Creare un account di archiviazione.
- Autorizzazioni utente configurate correttamente per Azure Data Lake Storage. Un amministratore di Azure Databricks deve assicurarsi che gli utenti abbiano i ruoli corretti, ad esempio Collaboratore ai dati dei BLOB di archiviazione, per leggere e scrivere dati archiviati in Azure Data Lake Storage. Vedere Usare il portale di Azure per assegnare un ruolo di Azure per l'accesso ai dati BLOB e di accodamento.
- Comprendere i privilegi degli amministratori dell'area di lavoro nelle aree di lavoro abilitate per il pass-through ed esaminare le assegnazioni di amministratore dell'area di lavoro esistenti. Gli amministratori dell'area di lavoro possono gestire le operazioni per l'area di lavoro, tra cui l'aggiunta di utenti e entità servizio, la creazione di cluster e la delega di altri utenti come amministratori dell'area di lavoro. Le attività di gestione dell'area di lavoro, ad esempio la gestione della proprietà dei processi e la visualizzazione dei notebook, possono concedere l'accesso indiretto ai dati registrati in Azure Data Lake Storage. L'amministratore dell'area di lavoro è un ruolo con privilegi da distribuire con attenzione.
- Non è possibile usare un cluster configurato con le credenziali ADLS, ad esempio le credenziali dell'entità servizio, con pass-through delle credenziali.
Importante
Non è possibile eseguire l'autenticazione in Azure Data Lake Storage con le credenziali di Microsoft Entra ID se si è protetti da un firewall che non è stato configurato per consentire il traffico verso Microsoft Entra ID. Firewall di Azure blocca l'accesso ad Active Directory per impostazione predefinita. Per consentire l'accesso, configurare il tag del servizio AzureActiveDirectory. È possibile trovare informazioni equivalenti per le appliance virtuali di rete nel tag AzureActiveDirectory nel file JSON per gli intervalli IP e i tag del servizio di Azure. Per altre informazioni, vedere Tag del servizio Firewall di Azure.
Raccomandazioni per la registrazione
È possibile registrare le identità passate all'archiviazione ADLS nei log di diagnostica dell'archiviazione di Azure. La registrazione delle identità consente di collegare le richieste ADLS ai singoli utenti dai cluster Di Azure Databricks. Attivare la registrazione diagnostica nell'account di archiviazione per iniziare a ricevere questi log:
- Azure Data Lake Storage Gen1: seguire le istruzioni in Abilitare la registrazione diagnostica per l'account Data Lake Storage Gen1.
- Azure Data Lake Storage Gen2: configurare con PowerShell con il
Set-AzStorageServiceLoggingPropertycomando . Specificare 2.0 come versione, perché il formato della voce di log 2.0 include il nome dell'entità utente nella richiesta.
Abilitare il pass-through delle credenziali di Azure Data Lake Storage per un cluster a concorrenza elevata
I cluster a concorrenza elevata possono essere condivisi da più utenti. Supportano solo Python e SQL con il pass-through delle credenziali di Azure Data Lake Storage.
Importante
L'abilitazione del pass-through delle credenziali di Azure Data Lake Storage per un cluster a concorrenza elevata blocca tutte le porte nel cluster , ad eccezione delle porte 44, 53 e 80.
- Quando si crea un cluster, impostare Modalità cluster su Concorrenza elevata.
- In Opzioni avanzate selezionare Abilita pass-through delle credenziali per l'accesso ai dati a livello di utente e consentire solo i comandi Python e SQL.

Abilitare il pass-through delle credenziali di Azure Data Lake Storage per un cluster Standard
I cluster standard con pass-through delle credenziali sono limitati a un singolo utente. I cluster standard supportano Python, SQL, Scala e R. In Databricks Runtime 10.4 LTS e versioni successive è supportato sparklyr.
È necessario assegnare un utente alla creazione del cluster, ma il cluster può essere modificato da un utente con autorizzazioni CAN MANAGE in qualsiasi momento per sostituire l'utente originale.
Importante
L'utente assegnato al cluster deve disporre almeno dell'autorizzazione CAN ATTACH TO per il cluster per eseguire i comandi nel cluster. Gli amministratori dell'area di lavoro e l'autore del cluster dispongono delle autorizzazioni CAN MANAGE, ma non possono eseguire comandi nel cluster a meno che non siano l'utente del cluster designato.
- Quando si crea un cluster, impostare la modalità cluster su Standard.
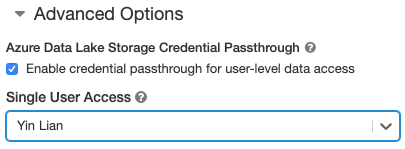
- In Opzioni avanzate selezionare Abilita pass-through delle credenziali per l'accesso ai dati a livello di utente e selezionare il nome utente dall'elenco a discesa Accesso utente singolo.
Creare un contenitore
I contenitori consentono di organizzare gli oggetti in un account di archiviazione di Azure.
Accedere direttamente ad Azure Data Lake Storage usando il pass-through delle credenziali
Dopo aver configurato il pass-through delle credenziali di Azure Data Lake Storage e aver creato contenitori di archiviazione, è possibile accedere ai dati direttamente in Azure Data Lake Storage Gen1 usando un adl:// percorso e Azure Data Lake Storage Gen2 usando un abfss:// percorso.
Azure Data Lake Storage Gen1
Python
spark.read.format("csv").load("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv").collect()
R
# SparkR
library(SparkR)
sparkR.session()
collect(read.df("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv", source = "csv"))
# sparklyr
library(sparklyr)
sc <- spark_connect(method = "databricks")
sc %>% spark_read_csv("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv") %>% sdf_collect()
- Sostituire
<storage-account-name>con il nome dell'account di archiviazione di ADLS Gen1.
Azure Data Lake Storage Gen2
Python
spark.read.format("csv").load("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv").collect()
R
# SparkR
library(SparkR)
sparkR.session()
collect(read.df("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv", source = "csv"))
# sparklyr
library(sparklyr)
sc <- spark_connect(method = "databricks")
sc %>% spark_read_csv("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv") %>% sdf_collect()
- Sostituire
<container-name>con il nome di un contenitore nell'account di archiviazione di ADLS Gen2. - Sostituire
<storage-account-name>con il nome dell'account di archiviazione di ADLS Gen2.
Montare Azure Data Lake Storage in DBFS usando il pass-through delle credenziali
È possibile montare un account di Azure Data Lake Storage o una cartella all'interno di essa in Che cos'è DBFS?. Il montaggio è un puntatore a Data Lake Store, quindi i dati non vengono mai sincronizzati in locale.
Quando si montano dati usando un cluster abilitato con il pass-through delle credenziali di Azure Data Lake Storage, qualsiasi lettura o scrittura nel punto di montaggio usa le credenziali dell'ID Microsoft Entra. Questo punto di montaggio sarà visibile ad altri utenti, ma gli unici utenti che avranno accesso in lettura e scrittura sono quelli che:
- Avere accesso all'account di archiviazione di Azure Data Lake Storage sottostante
- Usare un cluster abilitato per il pass-through delle credenziali di Azure Data Lake Storage
Azure Data Lake Storage Gen1
Per montare una risorsa di Azure Data Lake Storage Gen1 o una cartella al suo interno, usare i comandi seguenti:
Python
configs = {
"fs.adl.oauth2.access.token.provider.type": "CustomAccessTokenProvider",
"fs.adl.oauth2.access.token.custom.provider": spark.conf.get("spark.databricks.passthrough.adls.tokenProviderClassName")
}
# Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "adl://<storage-account-name>.azuredatalakestore.net/<directory-name>",
mount_point = "/mnt/<mount-name>",
extra_configs = configs)
Scala
val configs = Map(
"fs.adl.oauth2.access.token.provider.type" -> "CustomAccessTokenProvider",
"fs.adl.oauth2.access.token.custom.provider" -> spark.conf.get("spark.databricks.passthrough.adls.tokenProviderClassName")
)
// Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "adl://<storage-account-name>.azuredatalakestore.net/<directory-name>",
mountPoint = "/mnt/<mount-name>",
extraConfigs = configs)
- Sostituire
<storage-account-name>con il nome dell'account di archiviazione di ADLS Gen2. - Sostituire
<mount-name>con il nome del punto di montaggio previsto in DBFS.
Azure Data Lake Storage Gen2
Per montare un file system di Azure Data Lake Storage Gen2 o una cartella al suo interno, usare i comandi seguenti:
Python
configs = {
"fs.azure.account.auth.type": "CustomAccessToken",
"fs.azure.account.custom.token.provider.class": spark.conf.get("spark.databricks.passthrough.adls.gen2.tokenProviderClassName")
}
# Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/",
mount_point = "/mnt/<mount-name>",
extra_configs = configs)
Scala
val configs = Map(
"fs.azure.account.auth.type" -> "CustomAccessToken",
"fs.azure.account.custom.token.provider.class" -> spark.conf.get("spark.databricks.passthrough.adls.gen2.tokenProviderClassName")
)
// Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/",
mountPoint = "/mnt/<mount-name>",
extraConfigs = configs)
- Sostituire
<container-name>con il nome di un contenitore nell'account di archiviazione di ADLS Gen2. - Sostituire
<storage-account-name>con il nome dell'account di archiviazione di ADLS Gen2. - Sostituire
<mount-name>con il nome del punto di montaggio previsto in DBFS.
Avviso
Non fornire le chiavi di accesso dell'account di archiviazione o le credenziali dell'entità servizio per l'autenticazione al punto di montaggio. Ciò consentirebbe ad altri utenti di accedere al file system usando tali credenziali. Lo scopo del pass-through delle credenziali di Azure Data Lake Storage è impedire l'uso di tali credenziali e garantire che l'accesso al file system sia limitato agli utenti che hanno accesso all'account azure Data Lake Storage sottostante.
Sicurezza
È sicuro condividere cluster pass-through delle credenziali di Azure Data Lake Storage con altri utenti. Si sarà isolati l'uno dall'altro e non sarà in grado di leggere o usare le credenziali dell'altro.
Funzionalità supportate
| Funzionalità | Versione minima di Databricks Runtime | Note |
|---|---|---|
| Python e SQL | 5.5 | |
| Azure Data Lake Storage Gen1 | 5.5 | |
%run |
5.5 | |
| DBFS | 5.5 | Le credenziali vengono passate solo se il percorso DBFS viene risolto in una posizione in Azure Data Lake Storage Gen1 o Gen2. Per i percorsi DBFS che si risolvono in altri sistemi di archiviazione, usare un metodo diverso per specificare le credenziali. |
| Azure Data Lake Storage Gen2 | 5.5 | |
| memorizzazione nella cache del disco | 5.5 | |
| PySpark ML API | 5.5 | Le classi di Machine Learning seguenti non sono supportate: * org/apache/spark/ml/classification/RandomForestClassifier* org/apache/spark/ml/clustering/BisectingKMeans* org/apache/spark/ml/clustering/GaussianMixture* org/spark/ml/clustering/KMeans* org/spark/ml/clustering/LDA* org/spark/ml/evaluation/ClusteringEvaluator* org/spark/ml/feature/HashingTF* org/spark/ml/feature/OneHotEncoder* org/spark/ml/feature/StopWordsRemover* org/spark/ml/feature/VectorIndexer* org/spark/ml/feature/VectorSizeHint* org/spark/ml/regression/IsotonicRegression* org/spark/ml/regression/RandomForestRegressor* org/spark/ml/util/DatasetUtils |
| Variabili di trasmissione | 5.5 | All'interno di PySpark è previsto un limite per le dimensioni delle funzioni definite dall'utente Python che è possibile costruire, poiché le funzioni definite dall'utente di grandi dimensioni vengono inviate come variabili di trasmissione. |
| Librerie con ambito notebook | 5.5 | |
| Scala | 5.5 | |
| SparkR | 6.0 | |
| sparklyr | 10.1 | |
| Eseguire un notebook di Databricks da un altro notebook | 6.1 | |
| PySpark ML API | 6.1 | Tutte le classi di Ml PySpark supportate. |
| Metriche del cluster | 6.1 | |
| Databricks Connect | 7.3 | Il pass-through è supportato nei cluster Standard. |
Limitazioni
Le funzionalità seguenti non sono supportate con il pass-through delle credenziali di Azure Data Lake Storage:
%fsUsare invece il comando dbutils.fs equivalente.- Flussi di lavoro di Databricks.
- Informazioni di riferimento sull'API REST di Databricks.
- Catalogo Unity.
- Controllo di accesso a tabelle. Le autorizzazioni concesse dal pass-through delle credenziali di Azure Data Lake Storage possono essere usate per ignorare le autorizzazioni con granularità fine degli ACL di tabella, mentre le restrizioni aggiuntive degli ACL di tabella vincolano alcuni dei vantaggi offerti dal pass-through delle credenziali. Soprattutto:
- Se si dispone dell'autorizzazione Microsoft Entra ID per accedere ai file di dati sottostanti a una determinata tabella, si avranno le autorizzazioni complete per tale tabella tramite l'API RDD, indipendentemente dalle restrizioni applicate tramite ACL di tabella.
- Le autorizzazioni ACL della tabella verranno vincolate solo quando si usa l'API DataFrame. Se si tenta di leggere i file direttamente con l'API DataFrame, verranno visualizzati avvisi relativi alla mancata autorizzazione
SELECTper nessun file, anche se è possibile leggere tali file direttamente tramite l'API RDD. - Non sarà possibile leggere da tabelle supportate da file system diversi da Azure Data Lake Storage, anche se si dispone dell'autorizzazione ACL di tabella per leggere le tabelle.
- I metodi seguenti negli oggetti SparkContext (
sc) e SparkSession (spark):- Metodi deprecati.
- Metodi come
addFile()eaddJar()che consentono agli utenti non amministratori di chiamare il codice Scala. - Qualsiasi metodo che accede a un file system diverso da Azure Data Lake Storage Gen1 o Gen2 (per accedere ad altri file system in un cluster con il pass-through delle credenziali di Azure Data Lake Storage abilitato, usare un metodo diverso per specificare le credenziali e vedere la sezione relativa ai file system attendibili in Risoluzione dei problemi).
- Le API Hadoop precedenti (
hadoopFile()ehadoopRDD()). - Le API di streaming, poiché le credenziali passate scadono mentre il flusso era ancora in esecuzione.
- I montaggi DBFS (
/dbfs) sono disponibili solo in Databricks Runtime 7.3 LTS e versioni successive. I punti di montaggio con pass-through delle credenziali configurati non sono supportati tramite questo percorso. - Azure Data Factory.
- MLflow nei cluster a concorrenza elevata.
- pacchetto Python azureml-sdk in cluster a concorrenza elevata.
- Non è possibile estendere la durata dei token pass-through di Microsoft Entra ID usando i criteri di durata del token ID di Microsoft Entra. Di conseguenza, se si invia un comando al cluster che richiede più di un'ora, l'operazione avrà esito negativo se si accede a una risorsa di Azure Data Lake Storage dopo l'intervallo di 1 ora.
- Quando si usa Hive 2.3 e versioni successive, non è possibile aggiungere una partizione in un cluster con pass-through delle credenziali abilitato. Per altre informazioni, vedere la sezione relativa alla risoluzione dei problemi.
Notebook di esempio
I notebook seguenti illustrano il pass-through delle credenziali di Azure Data Lake Storage per Azure Data Lake Storage Gen1 e Gen2.
Notebook pass-through di Azure Data Lake Storage Gen1
Notebook pass-through di Azure Data Lake Storage Gen2
Risoluzione dei problemi
py4j.security.Py4JSecurityException: ... non è incluso nell'elenco elementi consentiti
Questa eccezione viene generata quando si accede a un metodo che Azure Databricks non ha contrassegnato esplicitamente come sicuro per i cluster con pass-through delle credenziali di Azure Data Lake Storage. Nella maggior parte dei casi, significa che il metodo potrebbe consentire a un utente in un cluster con passthrough delle credenziali di Azure Data Lake Storage di accedere alle credenziali di un altro utente.
org.apache.spark.api.python.PythonSecurityException: Path ... usa un file system non attendibile
Questa eccezione viene generata quando si è tentato di accedere a un file system che il cluster con pass-through delle credenziali di Azure Data Lake Storage non riconosce come sicuro. L'uso di un file system non attendibile potrebbe consentire a un utente in un cluster pass-through delle credenziali di Azure Data Lake Storage di accedere alle credenziali di un altro utente, pertanto non è possibile usare tutti i file system che non sono sicuri di essere usati in modo sicuro.
Per configurare il set di file system attendibili in un cluster con pass-through delle credenziali di Azure Data Lake Storage, impostare la chiave di configurazione di Spark spark.databricks.pyspark.trustedFilesystems nel cluster sotto forma di elenco delimitato da virgole dei nomi di classe che sono implementazioni attendibili di org.apache.hadoop.fs.FileSystem.
L'aggiunta di una partizione ha esito negativo con AzureCredentialNotFoundException quando il pass-through delle credenziali è abilitato
Quando si usa Hive 2.3-3.1, se si tenta di aggiungere una partizione in un cluster con pass-through delle credenziali abilitato, si verifica l'eccezione seguente:
org.apache.spark.sql.AnalysisException: org.apache.hadoop.hive.ql.metadata.HiveException: MetaException(message:com.databricks.backend.daemon.data.client.adl.AzureCredentialNotFoundException: Could not find ADLS Gen2 Token
Per risolvere questo problema, aggiungere partizioni in un cluster senza il pass-through delle credenziali abilitato.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per