Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Azure Databricks include diverse utilità e API per interagire con i file nei percorsi seguenti:
- Volumi del catalogo Unity
- File dell'area di lavoro
- Archiviazione di oggetti cloud
- Punti di montaggio DBFS e radice DBFS
- Archiviazione temporanea collegata al nodo driver del cluster
Questo articolo include esempi per interagire con i file in queste posizioni per gli strumenti seguenti:
- Apache Spark
- SPARK SQL e Databricks SQL
- Utilità del sistema di file di Databricks (
dbutils.fso%fs) - Interfaccia a riga di comando di Databricks
- Databricks REST API
- Comandi della shell Bash (
%sh) - L'installazione delle librerie con ambito notebook viene effettuata usando
%pip - Panda
- Utilità per la gestione ed elaborazione di file Python nel contesto di software open source
Importante
Alcune operazioni in Databricks, in particolare quelle che usano librerie Java o Scala, vengono eseguite come processi JVM, ad esempio:
- Specificare una dipendenza di un file JAR usando
--jarsnelle configurazioni di Spark - Chiamare
catojava.io.Filenei notebook Scala - Origini dati personalizzate, ad esempio
spark.read.format("com.mycompany.datasource") - Librerie che caricano file usando Java
FileInputStreamoPaths.get()
Queste operazioni non supportano la lettura o la scrittura su volumi Unity Catalog o file dell'area di lavoro utilizzando percorsi di file standard, come /Volumes/my-catalog/my-schema/my-volume/my-file.csv. Se è necessario accedere ai file del volume o ai file dell'area di lavoro dalle dipendenze JAR o dalle librerie basate su JVM, copiare prima i file nell'archiviazione locale di calcolo usando i comandi Python o %sh, ad esempio %sh mv.. Non usare %fs e dbutils.fs che usano la JVM. Per accedere ai file già copiati in locale, usare comandi specifici del linguaggio, ad esempio Python shutil o usare %sh comandi. Se un file deve essere presente durante l'avvio del cluster, usare uno script init per spostare prima il file. Consulta Che cosa sono gli script init?.
È necessario fornire uno schema URI per accedere ai dati?
I percorsi di accesso ai dati in Azure Databricks seguono uno degli standard seguenti:
percorsi in stile URI includono uno schema URI. Per le soluzioni di accesso ai dati native di Databricks, gli schemi URI sono facoltativi per la maggior parte dei casi d'uso. Quando si accede direttamente ai dati nell'archiviazione di oggetti cloud, è necessario specificare lo schema URI corretto per il tipo di archiviazione.
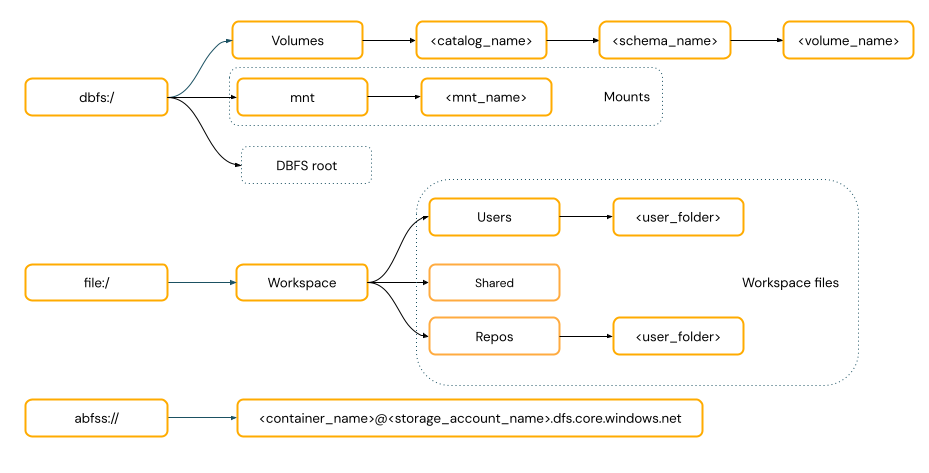
I percorsi in stile POSIX forniscono l'accesso ai dati in modo relativo alla radice del driver (
/). I percorsi in stile POSIX non richiedono mai uno schema. È possibile usare volumi del catalogo Unity o montaggi DBFS per fornire l'accesso in stile POSIX ai dati nell'archiviazione di oggetti cloud. Molti framework ML e altri moduli Python OSS richiedono FUSE e possono usare solo percorsi in stile POSIX.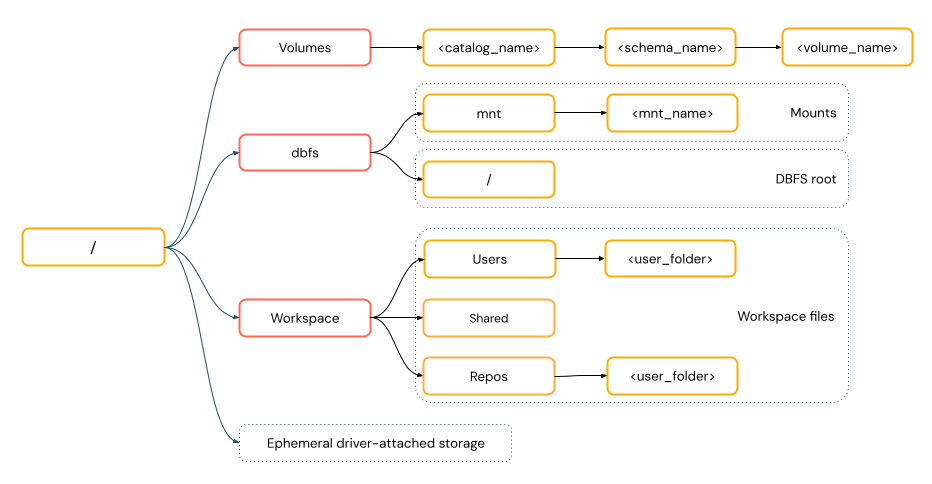
Nota
Le operazioni di file che richiedono l'accesso ai dati FUSE non possono accedere direttamente all'archiviazione di oggetti cloud usando gli URI. Databricks consiglia di usare i volumi di Unity Catalog per configurare l'accesso a queste posizioni per FUSE.
Nel calcolo configurato con la modalità di accesso dedicato (in precedenza modalità di accesso utente singolo) e Databricks Runtime 14.3 e versioni successive, Scala supporta FUSE per i volumi del catalogo Unity e i file dell'area di lavoro, ad eccezione dei sottoprocessi provenienti da Scala, ad esempio il comando Scala "cat /Volumes/path/to/file".!!.
Lavorare con i file nei volumi di Unity Catalog
Databricks consiglia di usare i volumi di Unity Catalog per configurare l'accesso ai file di dati non tabulari archiviati nell'archiviazione di oggetti cloud. Per la documentazione completa sulla gestione dei file nei volumi, incluse istruzioni dettagliate e procedure consigliate, vedere Usare i file nei volumi del catalogo Unity.
Gli esempi seguenti illustrano le operazioni comuni che usano diversi strumenti e interfacce:
| Strumento | Esempio |
|---|---|
| Apache Spark | spark.read.format("json").load("/Volumes/my_catalog/my_schema/my_volume/data.json").show() |
| SPARK SQL e Databricks SQL | SELECT * FROM csv.`/Volumes/my_catalog/my_schema/my_volume/data.csv`;LIST '/Volumes/my_catalog/my_schema/my_volume/'; |
| Utilità del file system di Databricks | dbutils.fs.ls("/Volumes/my_catalog/my_schema/my_volume/")%fs ls /Volumes/my_catalog/my_schema/my_volume/ |
| Interfaccia a riga di comando di Databricks | databricks fs cp /path/to/local/file dbfs:/Volumes/my_catalog/my_schema/my_volume/ |
| Databricks REST API | POST https://<databricks-instance>/api/2.1/jobs/create{"name": "A multitask job", "tasks": [{..."libraries": [{"jar": "/Volumes/dev/environment/libraries/logging/Logging.jar"}],},...]} |
| Comandi della shell Bash | %sh curl http://<address>/text.zip -o /Volumes/my_catalog/my_schema/my_volume/tmp/text.zip |
| Installazioni della libreria | %pip install /Volumes/my_catalog/my_schema/my_volume/my_library.whl |
| Panda | df = pd.read_csv('/Volumes/my_catalog/my_schema/my_volume/data.csv') |
| Software Open Source Python | os.listdir('/Volumes/my_catalog/my_schema/my_volume/path/to/directory') |
Per informazioni sulle limitazioni dei volumi e sulle soluzioni alternative, vedere Limitazioni dell'uso dei file nei volumi.
Lavorare con i file dell'area di lavoro
I file dell'area di lavoro di Databricks sono i file in un'area di lavoro, archiviati nell'account di archiviazione dell'area di lavoro . È possibile usare i file dell'area di lavoro per archiviare e accedere a file come notebook, file di codice sorgente, file di dati e altri asset dell'area di lavoro.
Importante
Poiché i file dell'area di lavoro hanno restrizioni sulle dimensioni, Databricks consiglia di archiviare solo file di dati di piccole dimensioni principalmente per lo sviluppo e il test. Per consigli su dove archiviare altri tipi di file, vedere Tipi di file.
| Strumento | Esempio |
|---|---|
| Apache Spark | spark.read.format("json").load("file:/Workspace/Users/<user-folder>/data.json").show() |
| SPARK SQL e Databricks SQL | SELECT * FROM json.`file:/Workspace/Users/<user-folder>/file.json`; |
| Utilità del file system di Databricks | dbutils.fs.ls("file:/Workspace/Users/<user-folder>/")%fs ls file:/Workspace/Users/<user-folder>/ |
| Interfaccia a riga di comando di Databricks | databricks workspace list |
| Databricks REST API | POST https://<databricks-instance>/api/2.0/workspace/delete{"path": "/Workspace/Shared/code.py", "recursive": "false"} |
| Comandi della shell Bash | %sh curl http://<address>/text.zip -o /Workspace/Users/<user-folder>/text.zip |
| Installazioni della libreria | %pip install /Workspace/Users/<user-folder>/my_library.whl |
| Panda | df = pd.read_csv('/Workspace/Users/<user-folder>/data.csv') |
| Software Open Source Python | os.listdir('/Workspace/Users/<user-folder>/path/to/directory') |
Nota
Lo schema file:/ è necessario quando si lavora con le utilità di Databricks, Apache Spark o SQL.
Nelle aree di lavoro in cui la radice DBFS e i punti di montaggio sono disabilitati, è possibile utilizzare anche dbfs:/Workspace per accedere ai file dell'area di lavoro tramite le utilità Databricks. Ciò richiede Databricks Runtime 13.3 LTS o versione successiva. Vedere Disabilitare l'accesso alla radice e ai montaggi DBFS nell'area di lavoro di Azure Databricks esistente.
Per le limitazioni relative all'uso dei file dell'area di lavoro, vedere Limitazioni.
Dove vanno i file dell'area di lavoro eliminati?
L'eliminazione di un file dell'area di lavoro lo invia al cestino. È possibile recuperare o eliminare definitivamente i file dal cestino usando l'interfaccia utente.
Vedi Eliminare un oggetto.
Lavorare con i file nell'archiviazione oggetti nel cloud
Databricks consiglia di usare i volumi di Unity Catalog per configurare l'accesso sicuro ai file nell'archiviazione di oggetti cloud. È necessario configurare le autorizzazioni se si sceglie di accedere ai dati direttamente nell'archivio oggetti cloud usando gli URI. Vedere Volumi gestiti ed esterni.
Gli esempi seguenti usano gli URI per accedere ai dati nell'archiviazione di oggetti cloud:
| Strumento | Esempio |
|---|---|
| Apache Spark | spark.read.format("json").load("abfss://container-name@storage-account-name.dfs.core.windows.net/path/file.json").show() |
| SPARK SQL e Databricks SQL |
SELECT * FROM csv.`abfss://container-name@storage-account-name.dfs.core.windows.net/path/file.json`;
LIST 'abfss://container-name@storage-account-name.dfs.core.windows.net/path';
|
| Utilità del file system di Databricks |
dbutils.fs.ls("abfss://container-name@storage-account-name.dfs.core.windows.net/path/")
%fs ls abfss://container-name@storage-account-name.dfs.core.windows.net/path/
|
| Interfaccia a riga di comando di Databricks | Non supportato |
| Databricks REST API | Non supportato |
| Comandi della shell Bash | Non supportato |
| Installazioni della libreria | %pip install abfss://container-name@storage-account-name.dfs.core.windows.net/path/to/library.whl |
| Panda | Non supportato |
| Software Open Source Python | Non supportato |
Lavorare con i file nei punti di montaggio DBFS e nella radice DBFS
Importante
I montaggi dbfs radice e DBFS sono deprecati e non consigliati da Databricks. Viene effettuato il provisioning di nuovi account senza accedere a queste funzionalità. Databricks consiglia di utilizzare invece volumi di Unity Catalog, percorsi esterni o file dell'area di lavoro.
| Strumento | Esempio |
|---|---|
| Apache Spark | spark.read.format("json").load("/mnt/path/to/data.json").show() |
| SPARK SQL e Databricks SQL | SELECT * FROM json.`/mnt/path/to/data.json`; |
| Utilità del file system di Databricks | dbutils.fs.ls("/mnt/path")%fs ls /mnt/path |
| Interfaccia a riga di comando di Databricks | databricks fs cp dbfs:/mnt/path/to/remote/file /path/to/local/file |
| Databricks REST API | POST https://<host>/api/2.0/dbfs/delete --data '{ "path": "/tmp/HelloWorld.txt" }' |
| Comandi della shell Bash | %sh curl http://<address>/text.zip > /dbfs/mnt/tmp/text.zip |
| Installazioni della libreria | %pip install /dbfs/mnt/path/to/my_library.whl |
| Panda | df = pd.read_csv('/dbfs/mnt/path/to/data.csv') |
| Software Open Source Python | os.listdir('/dbfs/mnt/path/to/directory') |
Nota
Lo schema dbfs:/ è necessario quando si usa l'interfaccia della riga di comando di Databricks.
Lavorare con i file nell'archiviazione temporanea collegata al nodo driver
L'archiviazione effimera collegata al nodo driver è un'archiviazione a blocchi con accesso integrato al percorso basato su POSIX. Tutti i dati archiviati in questa posizione scompaiono quando un cluster termina o riavvia.
| Strumento | Esempio |
|---|---|
| Apache Spark | Non supportato |
| SPARK SQL e Databricks SQL | Non supportato |
| Utilità del file system di Databricks | dbutils.fs.ls("file:/path")%fs ls file:/path |
| Interfaccia a riga di comando di Databricks | Non supportato |
| Databricks REST API | Non supportato |
| Comandi della shell Bash | %sh curl http://<address>/text.zip > /tmp/text.zip |
| Installazioni della libreria | Non supportato |
| Panda | df = pd.read_csv('/path/to/data.csv') |
| Software Open Source Python | os.listdir('/path/to/directory') |
Nota
Lo schema file:/ è necessario quando si utilizzano le utilità di Databricks.
Spostare i dati dall'archiviazione temporanea ai volumi
È possibile accedere ai dati scaricati o salvati in un archivio temporaneo usando Apache Spark. Poiché l'archiviazione temporanea è collegata al driver e Spark è un motore di elaborazione distribuito, non tutte le operazioni possono accedere direttamente ai dati qui. Si supponga di dover spostare i dati dal file system del driver ai volumi del catalogo Unity. In tal caso, è possibile copiare i file usando i comandi magic o le utilità Databricks, come negli esempi seguenti:
dbutils.fs.cp ("file:/<path>", "/Volumes/<catalog>/<schema>/<volume>/<path>")
%sh cp /<path> /Volumes/<catalog>/<schema>/<volume>/<path>
%fs cp file:/<path> /Volumes/<catalog>/<schema>/<volume>/<path>