Sviluppare codice nei notebook di Databricks
Questa pagina descrive come sviluppare codice nei notebook di Databricks, inclusi completamento automatico, formattazione automatica per Python e SQL, combinazione di Python e SQL in un notebook e rilevamento della cronologia versioni del notebook.
Per altre informazioni sulle funzionalità avanzate disponibili con l'editor, come il completamento automatico, la selezione di variabili, il supporto di più cursori e i confronti affiancati, consultare Esplorare il notebook e l'editor di file di Databricks.
Quando si usa il notebook o l'editor di file, Databricks Assistant è disponibile per facilitare la generazione, la spiegazione e il debug del codice. Per altre informazioni, vedere Utilizzo di Databricks Assistant.
I notebook di Databricks includono anche un debugger interattivo predefinito per i notebook Python. Vedere Notebook per le demo.
Modularizzare il codice
Importante
Questa funzionalità è disponibile in anteprima pubblica.
Con Databricks Runtime 11.3 LTS e versioni successive, è possibile creare e gestire file di codice sorgente nell'area di lavoro di Azure Databricks e quindi importarli nei notebook in base alle esigenze.
Per altre informazioni sull'uso dei file di codice sorgente, vedere Condividere codice tra notebook di Databricks e Lavorare con i moduli Python e R.
Formattare le celle del codice
Azure Databricks offre degli strumenti che consentono di formattare codice Python e SQL nelle celle del notebook in modo rapido e semplice. Questi strumenti riducono lo sforzo necessario per mantenere formattato il codice e consentono di applicare gli stessi standard di codifica nei notebook.
Libreria del formattatore Black di Python
Importante
Questa funzionalità è disponibile in anteprima pubblica.
Azure Databricks supporta la formattazione del codice Python usando black all'interno del notebook. Il notebook deve essere collegato a un cluster con i pacchetti Python black e tokenize-rt installati.
In Databricks Runtime 11.3 LTS e versioni successive, Azure Databricks peinstalla black e tokenize-rt. È possibile usare il formattatore direttamente senza dover installare queste librerie.
In Databricks Runtime 10.4 LTS e versioni precedenti, è necessario installare black==22.3.0 e tokenize-rt==4.2.1 da PyPI nel notebook o nel cluster per usare il formattatore Python. Eseguire il comando seguente nel notebook:
%pip install black==22.3.0 tokenize-rt==4.2.1
oppure installare la libreria nel cluster.
Per altre informazioni sull'installazione delle librerie, vedere Gestione degli ambienti Python.
Per i file e i notebook nelle cartelle Git di Databricks, è possibile configurare il formattatore Python in base al file pyproject.toml. Per usare questa funzionalità, creare un file pyproject.toml nella directory radice della cartella Git e configurarlo in base al formato di configurazione Black. Modificare la sezione [tool.black] nel file. La configurazione viene applicata quando si formattano file e notebook in tale cartella Git.
Come formattare le celle Python e SQL
È necessario disporre dell'autorizzazione CAN EDIT nel notebook per formattare il codice.
Azure Databricks usa la libreria Gethue/sql-formatter per formattare SQL e il formattatore di codice black per Python.
È possibile avviare un formattatore nei seguenti modi:
Formattare una singola cella
- Tasto di scelta rapida: premere CMD+MAIUSC+F.
- Menu contestuale dei comandi:
- Formato cella SQL: Seleziona Formato SQL nel menu a tendina del contesto dei comandi di una cella SQL. Questa voce di menu è visibile solo nelle celle del notebook SQL o in quelle con un
%sqlmagic del linguaggio. - Formatta cella Python: selezionare Formato Python nel menu a discesa del comando di una cella Python. Questa voce di menu è visibile solo nelle celle del notebook Python o in quelle con un
%pythonmagic del linguaggio.
- Formato cella SQL: Seleziona Formato SQL nel menu a tendina del contesto dei comandi di una cella SQL. Questa voce di menu è visibile solo nelle celle del notebook SQL o in quelle con un
- Notebook menu Modifica: selezionare una cella Python o SQL e quindi selezionare Modifica celle > formato.
Formattare più celle
Selezionare più celle e quindi selezionare Modifica celle > formato. Se si selezionano celle di più linguaggio, vengono formattate solo le celle SQL e Python. Sono inclusi quelli che usano
%sqle%python.Formattare tutte le celle Python e SQL nel notebook
selezionare modifica > formato Notebook. Se il notebook contiene più di un linguaggio, vengono formattate solo le celle SQL e Python. Sono inclusi quelli che usano
%sqle%python.
Limitazioni della formattazione del codice
- Black applica gli standard PEP 8 per il rientro a 4 spazi. Il rientro non è configurabile.
- La formattazione di stringhe Python incorporate all'interno di una UDF SQL non è supportata. Analogamente, la formattazione di stringhe SQL all'interno di una funzione definita dall'utente Python non è supportata.
Linguaggi di codice nei notebook
Impostare la lingua predefinita
La lingua predefinita del notebook viene visualizzata accanto al nome del notebook.

Per modificare la lingua predefinita, fare clic sul pulsante lingua e selezionare la nuova lingua dal menu a discesa. Per assicurarsi che i comandi esistenti continuino a funzionare, i comandi della lingua predefinita precedente vengono automaticamente preceduti da un comando magic del linguaggio.
Combinazioni di lingue
Per impostazione predefinita, le celle usano la lingua predefinita del notebook. È possibile eseguire la sostituzione della lingua predefinita in una cella cliccando sul pulsante lingua e selezionando una lingua dal menu a discesa.
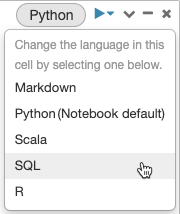
In alternativa, è possibile usare il comando magic del linguaggio %<language> all'inizio di una cella. I comandi magic supportati sono: %python, %r, %scala e %sql.
Nota
Quando si richiama un comando magic del linguaggio, il comando viene inviato a REPL nel contesto di esecuzione del notebook. Le variabili definite in un linguaggio (e quindi nel REPL di tale lingua) non sono disponibili nel REPL di un altro linguaggio. I REPL possono condividere lo stato solo tramite risorse esterne, come file in DBFS od oggetti nell'archiviazione oggetti.
I notebook supportano anche alcuni comandi magic ausiliari:
-
%sh: consente di eseguire il codice della shell nel notebook. Per interrompere la cella se il comando shell ha uno stato di uscita diverso da zero, aggiungere l'opzione-e. Questo comando viene eseguito solo sul driver Apache Spark e non sui ruoli di lavoro. Per eseguire un comando shell in tutti i nodi, usare uno script init. -
%fs: consente di usare i comandi del file systemdbutils. Ad esempio, per eseguire il comandodbutils.fs.lsper elencare i file, è possibile specificare%fs ls. Per altre informazioni, vedere Usare i file in Azure Databricks. -
%md: consente di includere vari tipi di documentazione, tra cui testo, immagini, formule matematiche ed equazioni. Vedi la sezione successiva.
Evidenziazione della sintassi SQL e completamento automatico nei comandi Python
L'evidenziazione della sintassi e il completamento automatico di SQL sono disponibili quando si usa SQL all'interno di un comando Python, ad esempio in un comando spark.sql.
Esplorare i risultati delle celle SQL
In un notebook di Databricks i risultati di una cella del linguaggio SQL vengono resi automaticamente disponibili come dataframe impliciti assegnati alla variabile _sqldf. È quindi possibile usare questa variabile in qualsiasi cella Python e SQL eseguita in un secondo momento, indipendentemente dalla posizione nel notebook.
Nota
Questa funzionalità presenta le limitazioni seguenti:
- La
_sqldfvariabile non è disponibile nei notebook che usano un'istanza di SQL Warehouse per il calcolo. - L'uso
_sqldfnelle celle Python successive è supportato in Databricks Runtime 13.3 e versioni successive. - L'uso
_sqldfnelle celle SQL successive è supportato solo in Databricks Runtime 14.3 e versioni successive. - Se la query usa le parole chiave
CACHE TABLEoUNCACHE TABLE, la_sqldfvariabile non è disponibile.
Lo screenshot seguente mostra come _sqldf usare nelle celle Python e SQL successive:
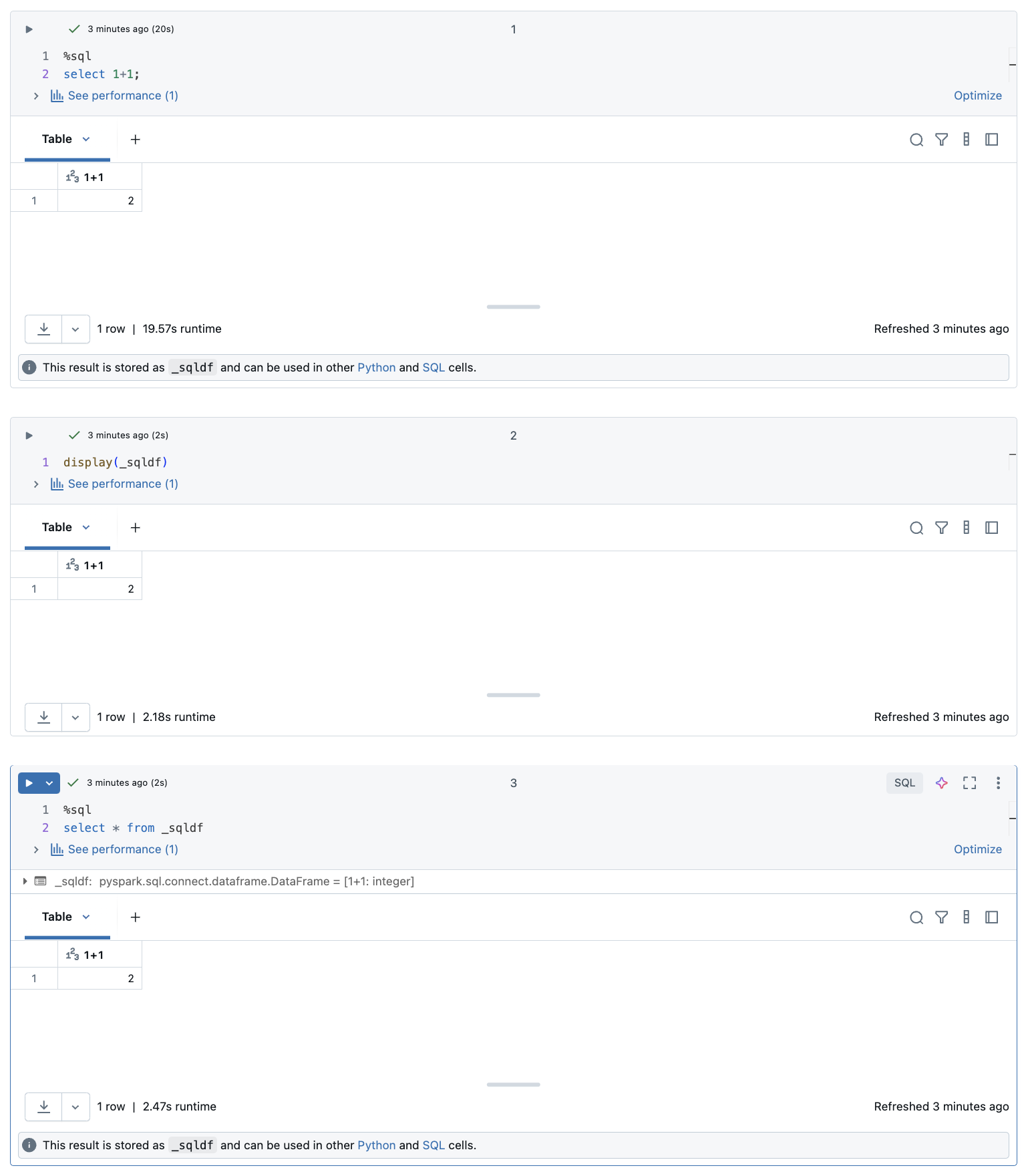
Importante
La variabile _sqldf viene riassegnata ogni volta che viene eseguita una cella SQL. Per evitare di perdere il riferimento a un risultato specifico del dataframe, assegnarlo a un nuovo nome di variabile prima di eseguire la cella SQL successiva:
Python
new_dataframe_name = _sqldf
SQL
ALTER VIEW _sqldf RENAME TO new_dataframe_name
Eseguire celle SQL in parallelo
Mentre un comando è in esecuzione e il notebook è collegato a un cluster interattivo, è possibile eseguire una cella SQL contemporaneamente con il comando corrente. La cella SQL viene eseguita in una nuova sessione parallela.
Per eseguire una cella in parallelo:
Cliccare Run now (Esegui adesso). La cella viene eseguita immediatamente.
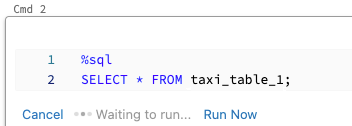
Poiché la cella viene eseguita in una nuova sessione, le viste temporanee, le funzioni definite dall'utente (UDF) e il DataFrame Python implicito (_sqldf) non sono supportati per le celle eseguite in parallelo. Inoltre, i nomi predefiniti del catalogo e del database vengono usati durante l'esecuzione parallela. Se il codice fa riferimento a una tabella in un catalogo o un database diverso, è necessario specificare il nome della tabella usando lo spazio dei nomi a tre livelli (catalog.schema.table).
Eseguire celle SQL in un'istanza di SQL Warehouse
È possibile eseguire comandi SQL in un notebook di Databricks in un SQL Warehouse, un tipo di calcolo ottimizzato per l'analisi SQL. Vedere Usare un notebook con un warehouse SQL.