Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Dopo aver collegato un notebook a un cluster ed eseguito una o più celle, il notebook ha lo stato e visualizza gli output. Questa sezione descrive come gestire lo stato e gli output del notebook.
Cancellare lo stato e gli output dei notebook
Per cancellare lo stato e gli output del notebook, selezionare una delle opzioni Cancella nella parte inferiore del menu Esegui.
| Opzione di menu | Descrizione |
|---|---|
| Cancellare tutti gli output delle celle | Cancella gli output delle celle. Ciò è utile se si condivide il notebook e si desidera evitare di includere risultati. |
| Cancellare lo stato | Cancella lo stato del notebook, comprese definizioni di funzioni e variabili, dati e librerie importate. |
| Azzerare stato e output | Cancella gli output delle celle e lo stato del notebook. |
| Cancellare lo stato ed eseguire tutto | Cancella lo stato del notebook e avvia una nuova esecuzione. |
Tabella Risultati
Quando viene eseguita una cella, i risultati vengono visualizzati in una tabella dei risultati. Con la tabella dei risultati, è possibile eseguire le operazioni seguenti:
- Copiare una colonna o un altro subset di dati dei risultati tabulari nella clipboard.
- Eseguire una ricerca di testo sulla tabella dei risultati.
- Ordinare e filtrare i dati.
- Spostarsi tra le celle della tabella usando i tasti di direzione della tastiera.
- Selezionare parte di un nome di colonna o un valore di cella facendo doppio clic e trascinando per selezionare il testo desiderato.
- Usare l'esploratore colonne per cercare, visualizzare o nascondere, fissare e ridisporre le colonne.

Per visualizzare i limiti nella tabella dei risultati del notebook, vedere limiti della tabella dei risultati del notebook.
Selezionare i dati
Per selezionare i dati nella tabella dei risultati, eseguire una delle operazioni seguenti.
- Copiare i dati o un sottoinsieme dei dati negli appunti.
- Cliccare su un'intestazione di colonna o di riga.
- Fare clic nella cella superiore sinistra della tabella per selezionare l'intera tabella.
- Trascinare il cursore su qualsiasi set di celle per selezionarle.
Per aprire un pannello laterale che visualizza le informazioni di selezione, fare clic sull'icona del pannello ![]() nell'angolo in alto a destra accanto alla casella Ricerca .
nell'angolo in alto a destra accanto alla casella Ricerca .
![]()
Copiare i dati negli appunti
Per copiare la tabella dei risultati in formato CSV negli Appunti, fare clic sulla freccia verso il basso accanto alla scheda del titolo della tabella, quindi fare clic su Copia risultati negli Appunti.
In alternativa, fare clic sulla casella in alto a sinistra della tabella per selezionare la tabella completa, quindi fare clic con il pulsante destro del mouse e scegliere Copia dal menu a discesa.
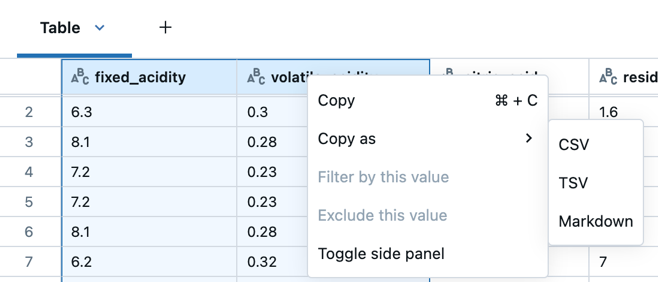
Esistono diversi modi per copiare i dati selezionati:
- Premere
Cmd + Cin MacOS oCtrl + Cin Windows per copiare i risultati negli Appunti in formato CSV. - Fare clic con il pulsante destro del mouse e selezionare Copia per copiare i risultati negli appunti in formato CSV.
- Fare clic con il pulsante destro del mouse e selezionare Copia come per copiare i dati selezionati in formato CSV, TSV o Markdown.
Ordinare i risultati
Per ordinare la tabella dei risultati in base ai valori di una colonna, posizionare il cursore sul nome della colonna. A destra della cella viene visualizzata un'icona contenente il nome della colonna. Fare clic sulla freccia per ordinare la colonna.

Per ordinare in base a più colonne, tenere premuto il tasto maiusc mentre si fa clic sulla freccia di ordinamento delle colonne.
L'ordinamento segue l'ordine naturale per impostazione predefinita. Per applicare un ordinamento lessicografico, usare ORDER BY in SQL o le rispettive funzioni di SORT disponibili nell'ambiente.
Filtrare i risultati
Usare i filtri in una tabella dei risultati per esaminare più in dettaglio i dati. I filtri applicati alle tabelle dei risultati influiscono anche sulle visualizzazioni, abilitando l'esplorazione interattiva senza modificare la query o il set di dati sottostante. Vedi Filtrare una visualizzazione.
Esistono diversi modi per creare un filtro:
Assistente Databricks
Usare i prompt del linguaggio naturale con Assistente
Creare filtri usando i prompt del linguaggio naturale:
- Fare clic
 In alto a destra dei risultati della cella.
In alto a destra dei risultati della cella. - Nella finestra di dialogo visualizzata immettere il testo che descrive il filtro desiderato.
- Fare clic
 L'Assistente genererà e applicherà automaticamente il filtro.
L'Assistente genererà e applicherà automaticamente il filtro.
Per creare filtri aggiuntivi con Assistente, fare clic ![]() Accanto ai filtri per immettere un'altra richiesta.
Accanto ai filtri per immettere un'altra richiesta.
Consultare Filtrare i dati con prompt del linguaggio naturale.
Finestra di dialogo del filtro
Usare la finestra di dialogo di filtro predefinita
- Se Databricks Assistant non è abilitato, fare clic alto a destra dei risultati della cella per aprire la finestra di dialogo filtro. È anche possibile accedere a questa finestra di dialogo facendo clic sul
 .
. - Selezionare la colonna da filtrare.
- Selezionare la regola di filtro da applicare.
- Selezionare i valori da filtrare.

Per valore
Filtrare in base a un valore specifico
- Nella tabella dei risultati fare clic con il pulsante destro del mouse su una cella con tale valore.
- Selezionare Filtra in base a questo valore dal menu a discesa.

Per colonna
Filtrare in base a una colonna specifica
- Passare il puntatore del mouse sulla colonna in base alla quale si vuole applicare un filtro.
- Fare clic

- Fare clic su Filtro.
- Selezionare i valori da filtrare.

Per abilitare o disabilitare temporaneamente un filtro, attivare o disattivare il pulsante Abilita/Disabilita nella finestra di dialogo.
Per eliminare un filtro, fare clic ![]() Accanto al nome del
Accanto al nome del  .
.
Applicare filtri al set di dati completo
Per impostazione predefinita, i filtri vengono applicati solo ai risultati visualizzati nella tabella dei risultati. Se i dati restituiti vengono troncati (ad esempio, quando una query restituisce più di 10.000 righe o il set di dati è maggiore di 2 MB), il filtro viene applicato solo alle righe restituite. Una nota nella parte superiore destra della tabella indica che il filtro è stato applicato ai dati troncati.
È invece possibile scegliere di filtrare il set di dati completo. Fare clic su Dati troncati, quindi scegliere set di dati completo. A seconda delle dimensioni del set di dati, l'applicazione del filtro potrebbe richiedere molto tempo.

Creare una query dai risultati filtrati
Da una tabella o una visualizzazione dei risultati filtrati in un notebook con SQL come linguaggio predefinito, è possibile creare una nuova query con i filtri applicati. In alto a destra della tabella o della visualizzazione fare clic su Crea query. La query viene aggiunta come cella successiva nel notebook.
La query creata applica i tuoi filtri sopra la query originale. In questo modo è possibile usare un set di dati più piccolo e più pertinente, consentendo un'esplorazione e un'analisi dei dati più efficienti.

Esplorare le colonne
Per facilitare l'utilizzo di tabelle con molte colonne, è possibile usare Esplora colonne. Per aprire Esplora colonne, fare clic sull'icona della colonna (![]() ) in alto a destra di una tabella dei risultati.
) in alto a destra di una tabella dei risultati.
L'esploratore di colonne consente di:
- Cercare colonne: digitare nella barra di ricerca per filtrare l'elenco di colonne. Fare clic su una colonna nell'esploratore per navigare alla corrispondente nella tabella dei risultati.
- Mostra o nascondi colonne: usare le caselle di controllo per controllare la visibilità delle colonne. La casella di controllo nella parte superiore attiva o disattiva la visibilità di tutte le colonne contemporaneamente. È possibile visualizzare o nascondere singole colonne usando le caselle di controllo accanto ai relativi nomi.
- Aggiungi colonne: passare il puntatore del mouse su un nome di colonna per visualizzare un'icona a forma di puntina. Fare clic sull'icona a forma di puntina per fissare la colonna. Le colonne bloccate rimangono visibili mentre si scorre orizzontalmente la tabella dei risultati.
-
Ridisporre le colonne: fare clic e tenere premuta
 di trascinamento (icona di trascinamento) a destra del nome di una colonna, quindi trascinare la colonna nella nuova posizione desiderata. In questo modo le colonne nella tabella dei risultati vengono riordinate.
di trascinamento (icona di trascinamento) a destra del nome di una colonna, quindi trascinare la colonna nella nuova posizione desiderata. In questo modo le colonne nella tabella dei risultati vengono riordinate.

Formatta colonne
L'intestazione della colonna indica il tipo di dati della colonna. Ad esempio,  indica il tipo di dati integer. Passare il puntatore del mouse sull'indicatore per visualizzare il tipo di dati.
indica il tipo di dati integer. Passare il puntatore del mouse sull'indicatore per visualizzare il tipo di dati.
È possibile formattare le colonne nelle tabelle dei risultati come tipi come Valuta, Percentuale, URL e altro ancora, con il controllo sulle posizioni decimali per le tabelle più chiare.
Formattare le colonne dal menu kebab nel nome della colonna.
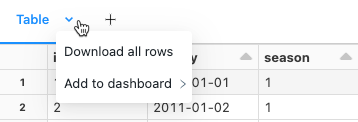
Scaricare i risultati
Per impostazione predefinita, il download dei risultati è abilitato. Per attivare o disattivare questa impostazione, si veda Gestire la possibilità di scaricare i risultati dai notebook.
È possibile scaricare un risultato di cella contenente l'output tabulare nel computer locale. Fare clic sulla freccia rivolta verso il basso accanto al titolo della scheda. Le opzioni di menu dipendono dal numero di righe nel risultato e dalla versione di Databricks Runtime. I risultati scaricati vengono salvati nel computer locale come file CSV con un nome corrispondente al nome del notebook.
Per i notebook connessi a SQL Warehouse o a risorse di calcolo serverless, è anche possibile scaricare i risultati come file di Excel.

Esplorare i risultati delle celle SQL
In un notebook di Databricks i risultati di una cella del linguaggio SQL sono automaticamente disponibili come dataframe assegnato alla variabile _sqldf. È possibile usare la _sqldf variabile per fare riferimento all'output SQL precedente nelle celle python e SQL successive. Per informazioni dettagliate, vedere Esplorare i risultati delle celle SQL.
Visualizzare più output per cella
I notebook Python e le celle %python nei notebook non Python supportano più output per cella. Ad esempio, l'output del codice seguente include sia il tracciato che la tabella:
import pandas as pd
from sklearn.datasets import load_iris
data = load_iris()
iris = pd.DataFrame(data=data.data, columns=data.feature_names)
ax = iris.plot()
print("plot")
display(ax)
print("data")
display(iris)
Ridimensionare gli output
Ridimensionare gli output delle celle trascinando l'angolo inferiore destro della tabella o della visualizzazione.

Effettuare il commit degli output dei notebook nelle cartelle Git di Databricks
Per informazioni sul commit degli output del notebook con estensione ipynb, si veda Consenti il commit dell'output del notebook con estensione ipynb.
- Il notebook deve essere un file con estensione ipynb
- Le impostazioni di amministrazione dell'area di lavoro devono consentire il commit degli output dei notebook