Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Note
La funzionalità Feed di dati delle modifiche di Lakebase è disponibile in anteprima pubblica.
Configura il feed delle modifiche ai dati di Lakebase (CDF) su una tabella Postgres, quindi osserva le modifiche a livello di riga apparire nella tabella Delta di destinazione.
Passaggi: (1) Abilitare l'acquisizione delle modifiche → (2) Avviare il feed → (3) Seguire una riga nella → lakehouse (4) Modificare la riga, vedere che scorre attraverso
Note
Questa è una guida introduttiva. Per la documentazione completa, consulta Lakebase Change Data Feed.
Prima di iniziare
- Assicurarsi di aver completato Ottenere un database Postgres. È necessario un progetto Lakebase con la
playing_with_lakebasetabella di esempio. - Un catalogo e uno schema di Unity Catalog per i quali si dispone dell'autorizzazione
CREATE TABLE.
Passaggio 1: Attivare l'acquisizione delle modifiche
Postgres necessita di dati di riga completi nel log write-ahead per il funzionamento di CDF. Impostare l'identità di replica su full fa sì che Postgres registri, per ogni modifica, sia lo stato precedente sia quello nuovo della riga.
Nell'editor SQL di Lakebase eseguire:
ALTER TABLE playing_with_lakebase REPLICA IDENTITY FULL;
Altre informazioni: Impostare l'identità di replica in tutte le tabelle in uno schema e applicarla automaticamente alle nuove tabelle
Passaggio 2: Avviare il feed
Lakebase CDF è configurato a livello di schema. Ogni tabella corrente e futura nello schema di origine viene inclusa automaticamente, quindi non si selezionano singole tabelle.
Nel ramo di produzione aprire la scheda Feed di dati delle modifiche e fare clic su Avvia. Scegli public come schema di origine, quindi seleziona un catalogo e uno schema di destinazione in Unity Catalog. Lo snapshot iniziale inizia immediatamente e lb_playing_with_lakebase_history viene visualizzato come tabella Delta nella destinazione.
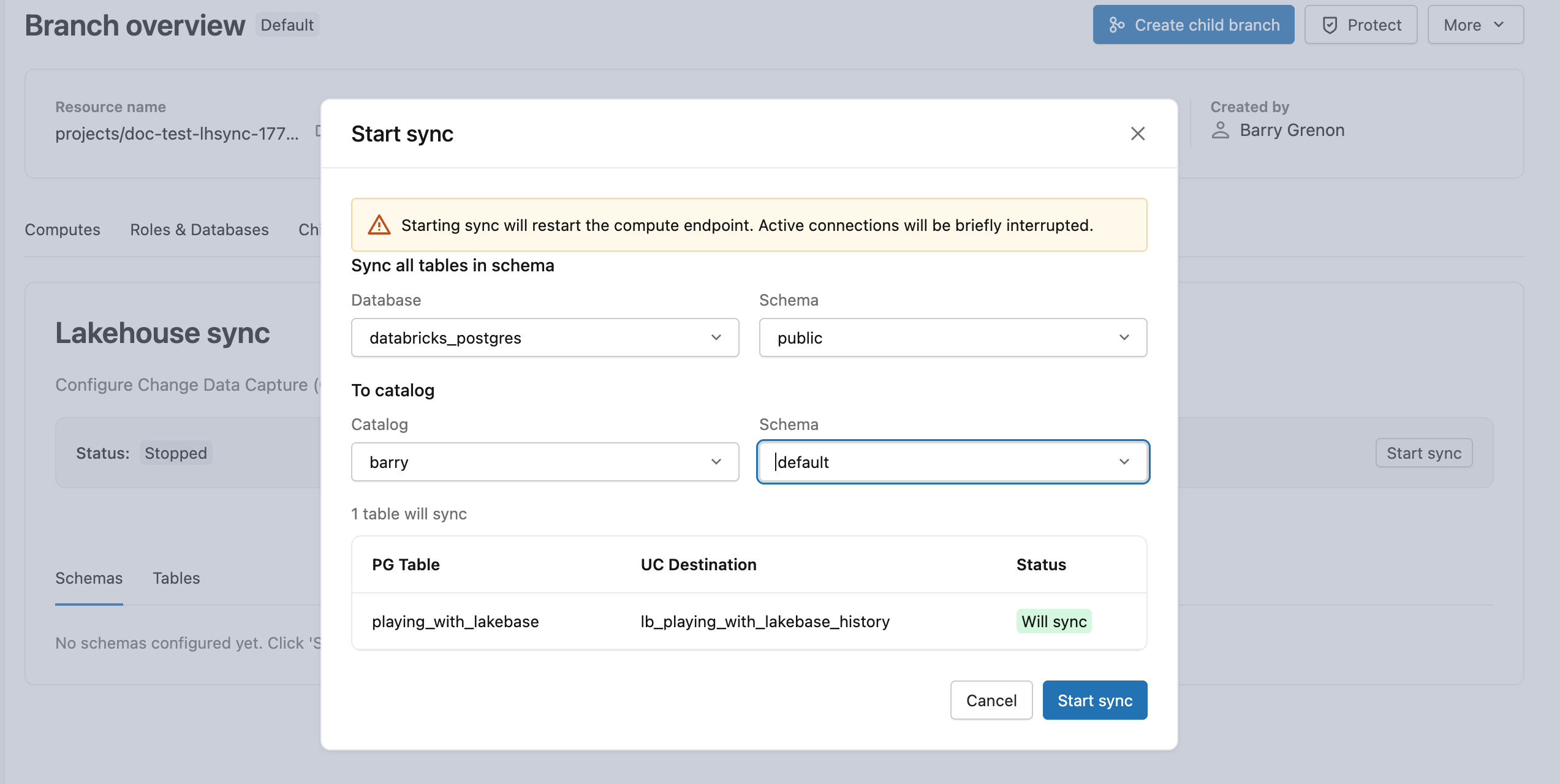
Altre informazioni: Avviare il feed di dati delle modifiche
Passo 3: Seguire una riga nel lago
Seleziona una riga da Lakebase. Esaminare la riga id=2:
SELECT * FROM playing_with_lakebase WHERE id = 2;
Ora trova la stessa riga nella tabella della cronologia di Delta. Passare a un databricks SQL warehouse o a un notebook ed eseguire:
SELECT * FROM <catalog>.<schema>.lb_playing_with_lakebase_history
WHERE id = 2;
Sostituire <catalog> e <schema> con la destinazione scelta nel passaggio 2. Verrà visualizzata la riga id=2 con la stessa name e value come in Lakebase, oltre a colonne aggiuntive. Lo snapshot iniziale ha scritto ogni riga esistente in Delta come insert evento, ovvero ciò che rappresenta tale riga.
Queste colonne aggiuntive descrivono il tipo di evento rappresentato da ogni riga (_pg_change_type), quando si è verificato (_timestamp) e le informazioni sull'ordinamento di Postgres (_pg_lsn, _pg_xid).
Ulteriori informazioni: Schema della tabella di destinazione | Mapping dei tipi di dati
Passaggio 4: Modifica la riga e osservala propagarsi
Tornare all'editor SQL di Lakebase, aggiornare la riga id=2:
UPDATE playing_with_lakebase SET value = 55.5 WHERE id = 2;
Attendere alcuni secondi per visualizzare la modifica nel feed, quindi eseguire nuovamente una query sulla tabella di cronologia:
SELECT id, value, _pg_change_type, _timestamp
FROM <catalog>.<schema>.lb_playing_with_lakebase_history
WHERE id = 2
ORDER BY _pg_lsn DESC;

La riga id=2 viene ora visualizzata tre volte: l'originale insert, un update_preimage oggetto con il valore precedente e un update_postimage con il nuovo valore. Ogni modifica alla riga diventa una nuova riga di cronologia, quindi è sempre disponibile un audit trail completo. Le eliminazioni funzionano allo stesso modo, aggiungendo una riga con _pg_change_type = 'delete'.
Scopri di più: Schemi di modifica comuni | Creare pipeline downstream
Passaggi successivi
- Creare una pipeline downstream: Trasformare la tabella di cronologia in un'aggregazione live con una vista materializzata, SDP o Structured Streaming.
- Eseguire analisi: Eseguire query sulle tabelle di cronologia Delta con Databricks SQL.
- Usa il livello bronzo: Integra la tabella della cronologia in un'architettura medallionica.
- Esaminare i limiti di produzione: Vedere limitazioni e risoluzione dei problemi e gestione delle modifiche dello schema.
- Esplora Lakebase:Concetti fondamentali | Lakebase