Risolvere i problemi di un processo lento o in errore in un cluster HDInsight
Se un'applicazione elabora i dati in un cluster HDInsight viene eseguita lentamente o ha esito negativo con un codice di errore, sono disponibili diverse opzioni per la risoluzione dei problemi. Se l'esecuzione dei processi richiede più tempo del previsto o in generale si osservano tempi di risposta lenti, potrebbero essersi verificati errori upstream dal cluster, ad esempio dai servizi in cui il cluster è in esecuzione. La causa più comune di questi rallentamenti è tuttavia un ridimensionamento non sufficiente. Quando si crea un nuovo cluster HDInsight, selezionare le dimensioni appropriate delle macchine virtuali.
Per diagnosticare un cluster lento o in errore, raccogliere informazioni su tutti gli aspetti dell'ambiente, ad esempio informazioni sui servizi di Azure associati, sulla configurazione cluster e sull'esecuzione dei processi. Una tecnica diagnostica utile consiste nel provare a riprodurre lo stato di errore in un altro cluster.
- Passaggio 1: Raccogliere dati sul problema.
- Passaggio 2: Convalidare l'ambiente del cluster HDInsight.
- Passaggio 3: Visualizzare l'integrità del cluster.
- Passaggio 4: Esaminare lo stack e le versioni dell'ambiente.
- Passaggio 5: Esaminare i file di log del cluster.
- Passaggio 6: Controllare le impostazioni di configurazione.
- Passaggio 7: Riprodurre l'errore in un cluster diverso.
Passaggio 1: Raccogliere i dati sul problema
In HDInsight sono disponibili diversi strumenti che è possibile usare per identificare e risolvere i problemi relativi ai cluster. I passaggi seguenti illustrano questi strumenti e offrono suggerimenti per individuare il problema.
Identificare il problema
Per identificare il problema, porsi le domande seguenti:
- Che cosa era previsto? Che cosa è successo invece?
- Quanto è durata l'esecuzione del processo? Quanto doveva durare?
- Le attività sono state sempre eseguite lentamente in questo cluster? Sono state eseguite più velocemente in un altro cluster?
- Quando si è verificato il problema per la prima volta? Quanto spesso si è verificato da allora?
- È cambiato qualcosa nella configurazione cluster?
Dettagli del cluster
Le informazioni importanti sul cluster includono:
- Nome del cluster.
- Area del cluster: cercare le interruzioni nell'area.
- Tipo e versione del cluster HDInsight.
- Tipo e numero di istanze di HDInsight specificate per i nodi head e di lavoro.
Queste informazioni sono disponibili nel portale di Azure:

È anche possibile usare l'interfaccia della riga di comando di Azure:
az hdinsight list --resource-group <ResourceGroup>
az hdinsight show --resource-group <ResourceGroup> --name <ClusterName>
Un'altra opzione è usare PowerShell. Per altre informazioni, vedere Gestire cluster Apache Hadoop in HDInsight tramite Azure PowerShell.
Passaggio 2: Convalidare l'ambiente del cluster HDInsight
Ogni cluster HDInsight si basa su diversi servizi di Azure e su software open source, ad esempio Apache HBase e Apache Spark. I cluster HDInsight possono anche chiamare altri servizi di Azure, ad esempio Reti virtuali di Azure. Un errore del cluster può essere causato da uno dei servizi in esecuzione nel cluster o da un servizio esterno. L'esecuzione del cluster può non riuscire anche a causa di una modifica alla configurazione del servizio cluster.
Dettagli sul servizio
- Controllare le versioni della versione della libreria open source.
- Verificare la presenza di interruzioni del servizio di Azure.
- Controllare i limiti di utilizzo dei servizi di Azure.
- Controllare la configurazione della subnet Rete virtuale di Azure.
Visualizzare le impostazioni di configurazione cluster con l'interfaccia utente di Ambari
Apache Ambari consente di gestire e monitorare un cluster HDInsight con un'interfaccia utente Web e un'API REST. Ambari è incluso nei cluster HDInsight basati su Linux. Selezionare il riquadro Dashboard cluster nella pagina HDInsight del portale di Azure. Selezionare il riquadro Dashboard cluster HDInsight per aprire l'interfaccia utente di Ambari e immettere le credenziali di accesso del cluster.
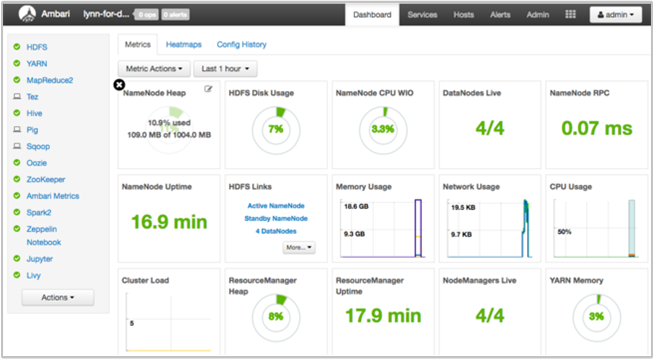
Per aprire un elenco di visualizzazioni di servizi, selezionare Visualizzazioni di Ambari nella pagina del portale di Azure. Questo elenco dipende dalle librerie installate. È ad esempio possibile visualizzare YARN Queue Manager, Hive View e Tez View. Selezionare un collegamento al servizio per visualizzare le informazioni sulla configurazione e sul servizio.
Controllare se si sono verificate interruzioni del servizio di Azure
HDInsight si basa su diversi servizi di Azure. Esegue i server virtuali in Azure HDInsight, archivia i dati e gli script nell'archivio BLOB di Azure o in Azure Data Lake Storage e indicizza i file di log nell'archivio tabelle di Azure. Le interruzioni di questi servizi, anche se rare, possono causare problemi in HDInsight. Se nel cluster si verificano rallentamenti imprevisti o errori, controllare il dashboard dello stato di Azure. Lo stato di ogni servizio è elencato per area. Controllare l'area del cluster e anche le aree per i servizi correlati.
Controllare i limiti di utilizzo del servizio Azure
Se si avvia un cluster di grandi dimensioni o sono stati avviati più cluster simultaneamente, possono verificarsi errori in un cluster se è stato superato un limite del servizio Azure. I limiti del servizio variano a seconda della sottoscrizione di Azure. Per altre informazioni, vedere Sottoscrizione di Azure e limiti, quote e vincoli dei servizi. È possibile chiedere a Microsoft di aumentare il numero di risorse di HDInsight disponibili (ad esempio, core delle VM e istanze delle VM) con una richiesta di aumento della quota di core per Resource Manager.
Controllare la versione di rilascio
Controllare la versione del cluster con la versione di HDInsight più recente. Ogni versione di HDInsight include miglioramenti, ad esempio nuove applicazioni, funzionalità, patch e correzioni di bug. Il problema che sta avendo effetti sul cluster potrebbe essere stato risolto nella versione di rilascio più recente. Se possibile, eseguire di nuovo il cluster usando la versione più recente di HDInsight e le librerie associate, ad esempio Apache HBase, Apache Spark e altre.
Riavviare i servizi del cluster
Se si verificano rallentamenti nel cluster, considerare la possibilità di riavviare i servizi tramite l'interfaccia utente di Ambari o l'interfaccia della riga di comando classica di Azure. È possibile che nel cluster si stiano verificando errori temporanei e il riavvio è il modo più veloce per stabilizzare l'ambiente e, probabilmente, per migliorare le prestazioni.
Passaggio 3: Visualizzare l'integrità del cluster
I cluster HDInsight sono costituiti da tipi diversi di nodi in esecuzione nelle istanze delle macchine virtuali. In ogni nodo è possibile monitorare l'esaurimento delle risorse, i problemi di connettività di rete e altri problemi che possono rallentare il cluster. Ogni cluster contiene due nodi head e la maggior parte dei tipi di cluster contiene una combinazione di nodi perimetrali e di lavoro.
Per una descrizione dei diversi nodi usati da ogni tipo di cluster, vedere Configurare i cluster HDInsight con Apache Hadoop, Apache Spark, Apache Kafka e altro ancora.
Le sezioni seguenti descrivono come controllare l'integrità di ogni nodo e del cluster nel suo complesso.
Ottenere uno snapshot dell'integrità del cluster usando il dashboard dell'interfaccia utente di Ambari
Il dashboard dell'interfaccia utente di Ambari (https://<clustername>.azurehdinsight.net) offre una panoramica dell'integrità del cluster, ad esempio tempo di attività, memoria, utilizzo di rete e CPU, utilizzo dei dischi HDFS e così via. Usare le sezioni degli host di Ambari per visualizzare le risorse a livello di host. È anche possibile arrestare e riavviare i servizi.
Controllare il servizio WebHCat
Uno scenario comune per i processi Apache Hive, Apache Pig o Apache Sqoop non riusciti è un errore del servizio WebHCat (o Templeton). WebHCat è un'interfaccia REST per l'esecuzione di processi remoti, ad esempio Hive, Pig, Scoop e MapReduce. WebHCat converte le richieste di invio dei processi nelle applicazioni YARN di Apache Hadoop e restituisce uno stato derivato dallo stato delle applicazioni YARN. Le sezioni seguenti descrivono i codici di stato HTTP WebHCat comuni.
BadGateway (codice di stato 502)
Questo codice è un messaggio generico dai nodi del gateway ed è il codice di stato di errore più comune. Una possibile causa è l'inattività del servizio WebHCat nel nodo head attivo. Per verificare questa possibilità, usare il comando CURL seguente:
curl -u admin:{HTTP PASSWD} https://{CLUSTERNAME}.azurehdinsight.net/templeton/v1/status?user.name=admin
Ambari visualizza un avviso che indica gli host in cui il servizio WebHCat è inattivo. È possibile provare a riattivare il servizio WebHCat riavviandolo nell'host.
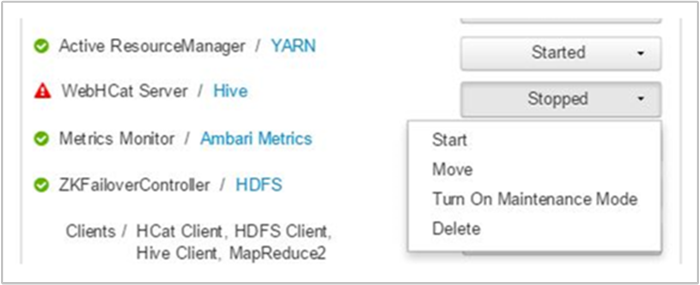
Se tuttavia un server WebHCat non viene attivato, verificare la presenza di messaggi di errore nel log delle operazioni. Per informazioni più dettagliate, vedere i file stderr e stdout a cui si fa riferimento nel nodo.
Timeout di WebHCat
Un gateway HDInsight esegue il timeout delle risposte che richiedono più di due minuti, restituendo 502 BadGateway. WebHCat cerca nei servizi YARN gli stati dei processi e, se YARN impiega più di due minuti a rispondere, tale richiesta può raggiungere il timeout.
In questo caso esaminare i log seguenti nella directory /var/log/webhcat:
- webhcat.log è il log log4j in cui il server scrive i log
- webhcat-console.log è l'elemento stdout del server quando viene avviato
- webhcat-console-error.log è l'elemento stderr del processo server
Nota
Il rollover di ogni webhcat.log viene eseguito giornalmente, generando file denominati webhcat.log.YYYY-MM-DD. Selezionare il file appropriato per l'intervallo di tempo da analizzare.
Le sezioni seguenti descrivono alcune possibili cause dei timeout di WebHCat.
Timeout a livello di WebHCat
Quando WebHCat è sotto carico, con più di 10 socket aperti, stabilire nuove connessioni socket richiede più tempo e può verificarsi un timeout. Per elencare le connessioni di rete da e verso WebHCat, usare netstat nel nodo head attivo corrente:
netstat | grep 30111
30111 è la porta su cui WebHCat è in ascolto. Il numero di socket aperti deve essere inferiore a 10.
Se non ci sono socket aperti, il comando precedente non genera risultati. Per controllare se Templeton è attivo e in ascolto sulla porta 30111, usare:
netstat -l | grep 30111
Timeout a livello di YARN
Templeton chiama YARN per eseguire i processi e la comunicazione tra Templeton e YARN può causare un timeout.
A livello di YARN si verificano due tipi di timeout:
L'invio di un processo YARN può durare tanto da causare un timeout.
Se si apre il
/var/log/webhcat/webhcat.logfile di log e si cerca "processo in coda", è possibile che vengano visualizzate più voci in cui il tempo di esecuzione è eccessivamente lungo (>2000 ms), con voci che mostrano tempi di attesa crescenti.Il tempo necessario per i processi in coda continua ad aumentare perché la velocità con cui i nuovi processi vengono inviati è maggiore della velocità con cui venivano completati i processi precedenti. Quando la memoria di YARN è usata al 100%, la coda joblauncher non può più prendere in prestito capacità dalla coda predefinita, quindi nessun altro nuovo processo può essere accettato nella coda joblauncher. Questo comportamento può prolungare sempre di più il tempo di attesa, causando un errore di timeout seguito in genere da molti altri.
L'immagine seguente illustra la coda joblauncher usata al 714,4%. Questo uso eccessivo è accettabile purché nella coda predefinita sia ancora disponibile capacità da prendere in prestito. Quando tuttavia il cluster è completamente utilizzato e la memoria di YARN è al 100% della capacità, i nuovi processi devono attendere e alla fine si verificano i timeout.

Esistono due modi per risolvere questo problema: ridurre la velocità dei nuovi processi da inviare o aumentare la velocità di consumo dei vecchi processi aumentando le prestazioni del cluster.
L'elaborazione di YARN può richiedere molto tempo e causare quindi i timeout.
Elencare tutti i processi: è una chiamata dispendiosa in termini di tempo. Questa chiamata enumera le applicazioni da YARN ResourceManager e, per ogni applicazione completata, ottiene lo stato da YARN JobHistoryServer. Con un numero di processi più elevato, questa chiamata può raggiungere il timeout.
Elencare i processi più vecchi di sette giorni: HDInsight YARN JobHistoryServer è configurato per conservare le informazioni sui processi completati per sette giorni (valore
mapreduce.jobhistory.max-age-ms). Il tentativo di enumerare i processi eliminati restituisce un timeout.
Per diagnosticare questi problemi:
- Determinare l'intervallo di tempo UTC per cui risolvere i problemi
- Selezionare i file
webhcat.logappropriati - Cercare i messaggi WARN ed ERROR compresi in tale intervallo
Altri errori di WebHCat
Codice di stato HTTP 500
Nella maggior parte dei casi in cui WebHCat restituisce 500, il messaggio contiene dettagli sull'errore. In caso contrario, cercare in
webhcat.logi messaggi WARN ed ERROR.Errori dei processi
In alcuni casi è possibile che le interazioni con WebHCat vengano eseguite correttamente, ma che i processi non riescano.
Templeton raccoglie l'output della console dei processi come
stderrinstatusdir, che è spesso utile per risolvere i problemi.stderrcontiene l'identificatore applicazione YARN della query effettiva.
Passaggio 4: Rivedere lo stack e le versioni dell'ambiente
La pagina Stack and Version (Stack e versione) dell'interfaccia utente di Ambari contiene informazioni sulla configurazione dei servizi cluster e la cronologia delle versioni dei servizi. Le versioni non corrette delle librerie dei servizi Hadoop possono essere causa di un errore del cluster. Nell'interfaccia utente di Ambari scegliere Stacks and Versions (Stack e versioni) dal menu Admin (Amministratore). Selezionare la scheda Versions (Versioni) nella pagina per visualizzare le informazioni sulle versioni dei servizi:
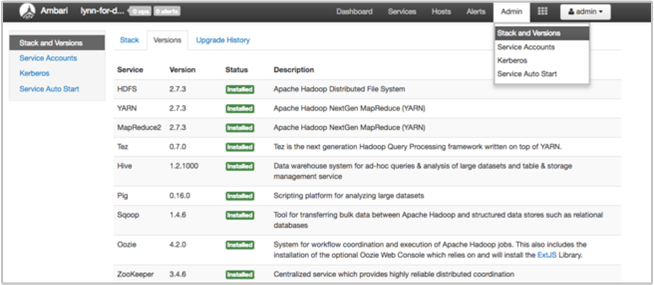
Passaggio 5: Esaminare i file di log
Sono molti i tipi di log generati dai diversi servizi e componenti che costituiscono un cluster HDInsight. I file di log di WebHCat sono stati descritti in precedenza. Esistono diversi altri file di log che è utile esaminare per limitare i problemi del cluster, come illustrato nelle sezioni seguenti.
I cluster HDInsight sono costituiti da diversi nodi, la maggior parte dei quali deve eseguire i processi inviati. I processi vengono eseguiti simultaneamente, ma i file di log possono visualizzare i risultati solo in modo lineare. HDInsight esegue le nuove attività, terminando le altre che non vengono completate prima. Tutta questa attività viene registrata nei file
stderresyslog.I file di log delle azioni script contengono gli errori o le modifiche alla configurazione non previste avvenute durante il processo di creazione del cluster.
I log dei passaggi di Hadoop identificano i processi di Hadoop avviati durante un passaggio contenente errori.
Controllare i log delle azioni script
Le azioni script di HDInsight eseguono gli script nel cluster manualmente o se specificato. Le azioni script, ad esempio, possono essere usate per installare software aggiuntivo nel cluster o modificare i valori predefiniti delle impostazioni di configurazione. I log delle azioni script possono fornire informazioni sugli errori che si sono verificati durante l'installazione e la configurazione del cluster. Per visualizzare lo stato di un'azione script, selezionare il pulsante ops (operazioni) nell'interfaccia utente di Ambari o accedere ai log dall'account di archiviazione predefinito.
I log delle azioni script si trovano nella directory \STORAGE_ACCOUNT_NAME\DEFAULT_CONTAINER_NAME\custom-scriptaction-logs\CLUSTER_NAME\DATE.
Visualizzare i log di HDInsight usando i collegamenti rapidi di Ambari
L'interfaccia utente di Ambari in HDInsight include diverse sezioni Quick Links (Collegamenti rapidi). Per accedere ai collegamento dei log di un determinato servizio nel cluster HDInsight, aprire l'interfaccia utente di Ambari per il cluster, quindi selezionare il collegamento del servizio dall'elenco a sinistra. Selezionare il menu a discesa Quick Links (Collegamenti rapidi), quindi il nodo HDInsight a cui si è interessati e infine selezionare il collegamento del log associato.
Ad esempio, per i log HDFS:
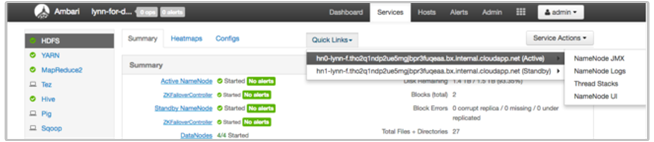
Visualizzare i file di log generati da Hadoop
Un cluster HDInsight genera log che vengono scritti nelle tabelle di Azure e nell'archivio BLOB di Azure. YARN crea i propri log di esecuzione. Per altre informazioni, vedere Gestire i log per un cluster HDInsight.
Esaminare i dump dell'heap
I dump dell'heap contengono uno snapshot della memoria dell'applicazione, inclusi i valori delle variabili in quel momento, utili per la diagnosi dei problemi che si verificano in fase di esecuzione. Per altre informazioni, vedere Abilitare i dump dell'heap per i servizi Apache Hadoop in HDInsight basato su Linux.
Passaggio 6: Controllare le impostazioni di configurazione
I cluster HDInsight sono preconfigurati con le impostazioni predefinite per i servizi correlati, ad esempio Hadoop, Hive, HBase e così via. A seconda del tipo di cluster, della configurazione hardware, del numero di nodi, dei tipi di processi in esecuzione e dei dati usati (e di come tali dati vengono elaborati), potrebbe essere necessario ottimizzare la configurazione.
Per istruzioni dettagliate sull'ottimizzazione delle prestazioni per la maggior parte degli scenari, vedere Ottimizzare la configurazione del cluster con Apache Ambari. Quando si usa Spark, vedere Ottimizzare i processi Apache Spark per le prestazioni.
Passaggio 7: Riprodurre l'errore in un cluster diverso
Per diagnosticare l'origine di un errore del cluster, avviare un nuovo cluster con la stessa configurazione e quindi inviare di nuovo i passaggi del processo non riuscito uno alla volta. Controllare i risultati di ogni passaggio prima di elaborare quello successivo. Questo metodo consente di correggere ed eseguire di nuovo un singolo passaggio non riuscito. Questo metodo presenta anche il vantaggio di caricare unicamente i dati di input una sola volta.
- Creare un nuovo cluster di test con la stessa configurazione del cluster con esito negativo.
- Inviare il primo passaggio del processo al cluster di test.
- Al termine dell'elaborazione del passaggio, cercare gli errori nei file di log del passaggio. Connettersi al nodo master del cluster di test e visualizzare i file di log presenti. I file di log del passaggio vengono visualizzati solo dopo che il passaggio viene eseguito alcune volte, termina o non riesce.
- Se il primo passaggio ha avuto esito positivo, eseguire il passaggio successivo. Se si sono verificati errori, esaminare l'errore nei file di log. Se si è verificato un errore nel codice, apportare la correzione ed eseguire di nuovo il passaggio.
- Continuare fino a quando tutti i passaggi vengono eseguiti senza errori.
- Al termine del debug del cluster di test, eliminarlo.
Passaggi successivi
- Gestire i cluster HDInsight usando l'interfaccia utente Web di Apache Ambari
- Analizzare i log di HDInsight
- Accedere all'applicazione APACHE Hadoop YARN per accedere a HDInsight basato su Linux
- Abilitare i dump dell'heap per i servizi Apache Hadoop in HDInsight basato su Linux
- Problemi noti del cluster Apache Spark in HDInsight