Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Informazioni su come connettere un cluster Apache Spark in Azure HDInsight con database SQL di Azure. Quindi leggere, scrivere e trasmettere i dati nel database SQL. Le istruzioni riportate in questo articolo usano Jupyter Notebook per eseguire i frammenti di codice Scala. Tuttavia, è possibile creare un'applicazione autonoma in Scala o Python ed eseguire le stesse attività.
Prerequisiti
Cluster Azure HDInsight Spark. Seguire le istruzioni riportate in Creare un cluster Apache Spark in HDInsight.
Database SQL di Azure. Seguire le istruzioni in Creare un database in database SQL di Azure. Assicurarsi di creare un database con lo schema e i dati dell'esempio AdventureWorksLT. Assicurarsi inoltre di creare una regola del firewall a livello di server per consentire all'indirizzo IP del client di accedere al database SQL. Le istruzioni per aggiungere la regola del firewall sono disponibili nello stesso articolo. Dopo aver creato il database SQL, assicurarsi di mantenere a portata di mano i valori seguenti. che saranno necessari per connettersi al database da un cluster Spark.
- Nome server.
- nome del database.
- database SQL di Azure nome utente amministratore/password.
SQL Server Management Studio (SSMS). Seguire le istruzioni riportate in Usare SQL Server Management Studio per connettersi ed eseguire query sui dati.
Creare un notebook di Jupyter Notebook
Iniziare creando un oggetto Jupyter Notebook associato al cluster Spark. Usare quindi il notebook per eseguire i frammenti di codice illustrati in questo articolo.
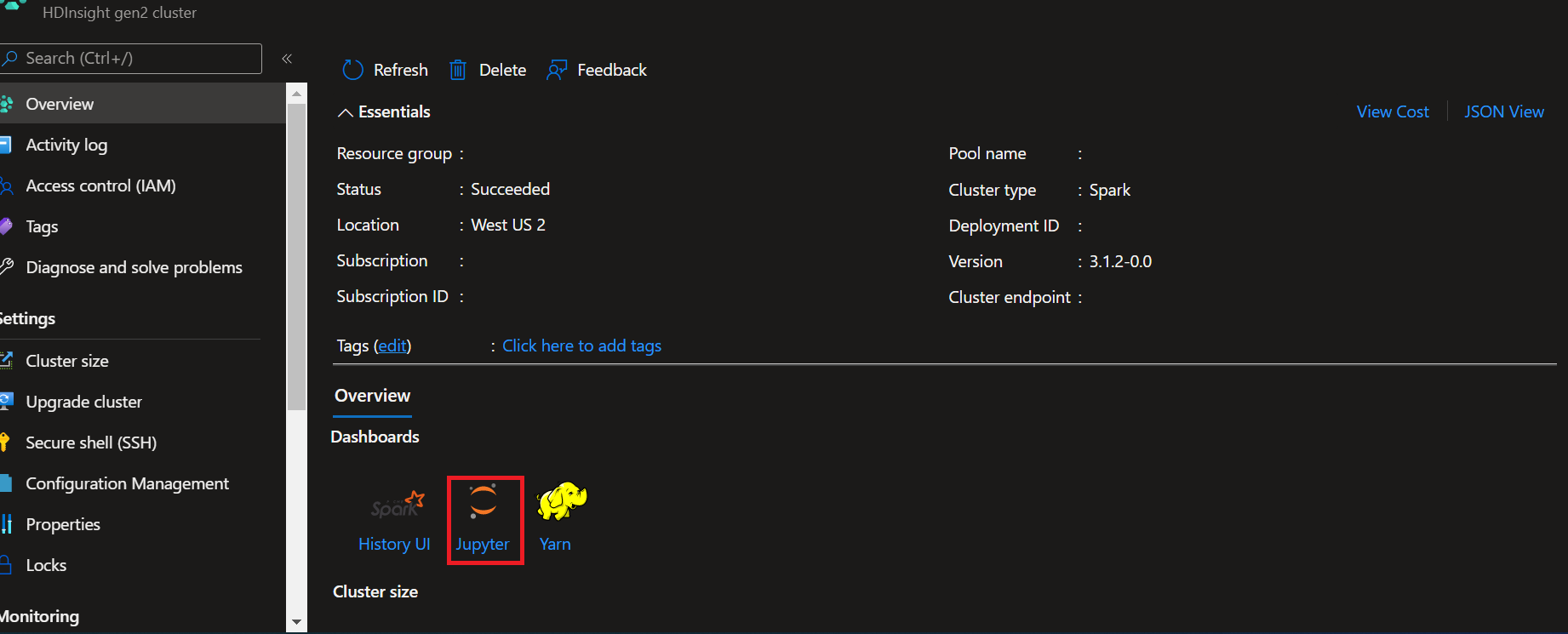
- Dal Portale di Azure, aprire il cluster.
- Selezionare Jupyter Notebook sotto Dashboard cluster sul lato destro. Se i dashboard del cluster non sono visualizzati, selezionare Panoramica dal menu a sinistra. Se richiesto, immettere le credenziali per il cluster.
Nota
È anche possibile accedere a Jupyter Notebook nel cluster Spark aprendo l'URL seguente nel browser. Sostituire CLUSTERNAME con il nome del cluster:
https://CLUSTERNAME.azurehdinsight.net/jupyter
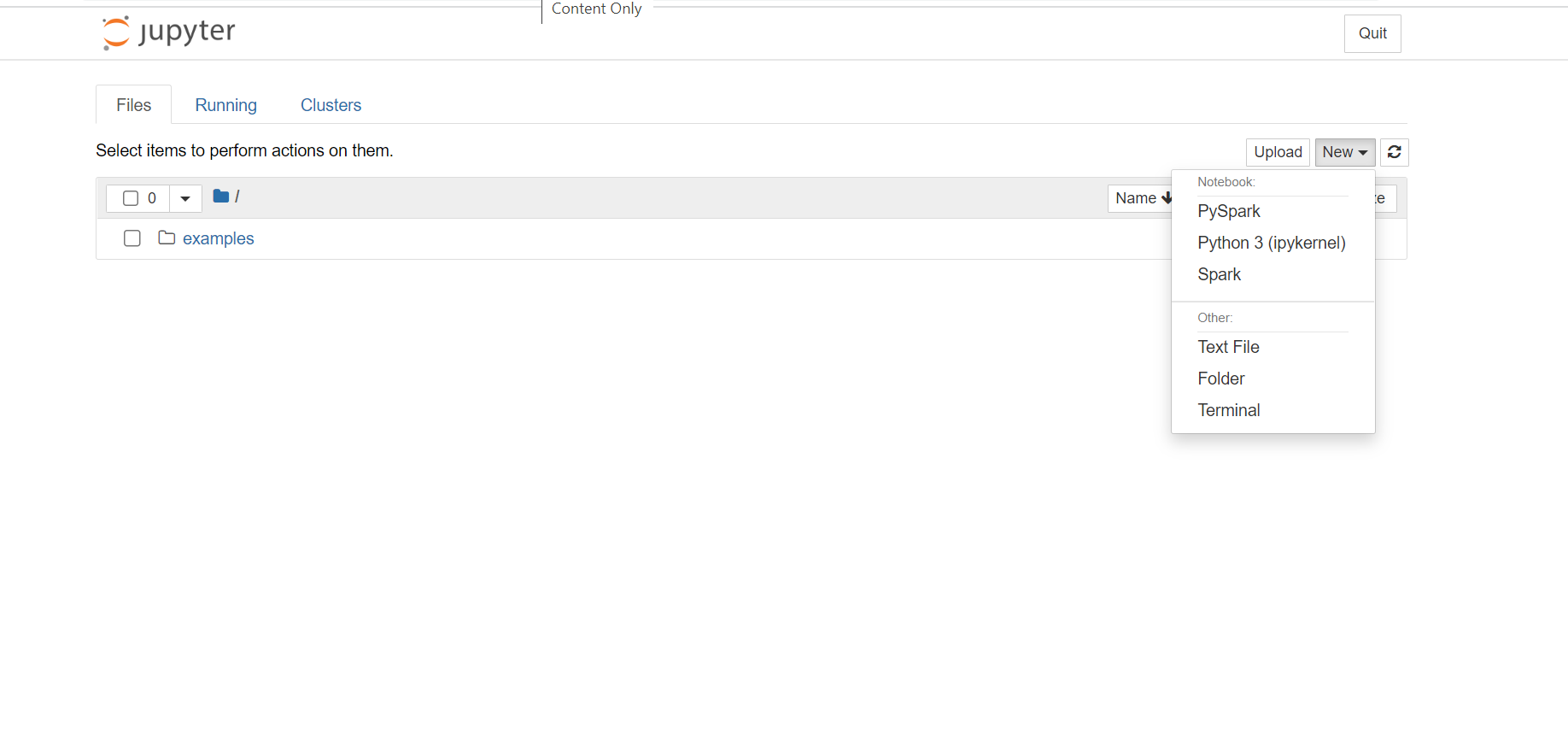
- Nell'angolo superiore destro del notebook di Jupyter fare clic su Nuovo e quindi su Spark per creare un notebook Scala. I notebook di Jupyter nel cluster HDInsight Spark forniscono anche il kernel PySpark per le applicazioni Python2 e il kernel PySpark3 per le applicazioni Python3 . In questo articolo si creerà un notebook di Scala.
Per altre informazioni sui kernel, vedere Usare i kernel di Jupyter Notebook con cluster Apache Spark in HDInsight.
Nota
In questo articolo viene usato un kernel Spark (Scala) perché lo streaming di dati da Spark in database SQL è attualmente supportato solo in Scala e Java. Anche se le operazioni di lettura e scrittura in SQL possono essere eseguite con Python, per coerenza a livello di articolo si userà Scala per tutte e tre le operazioni.
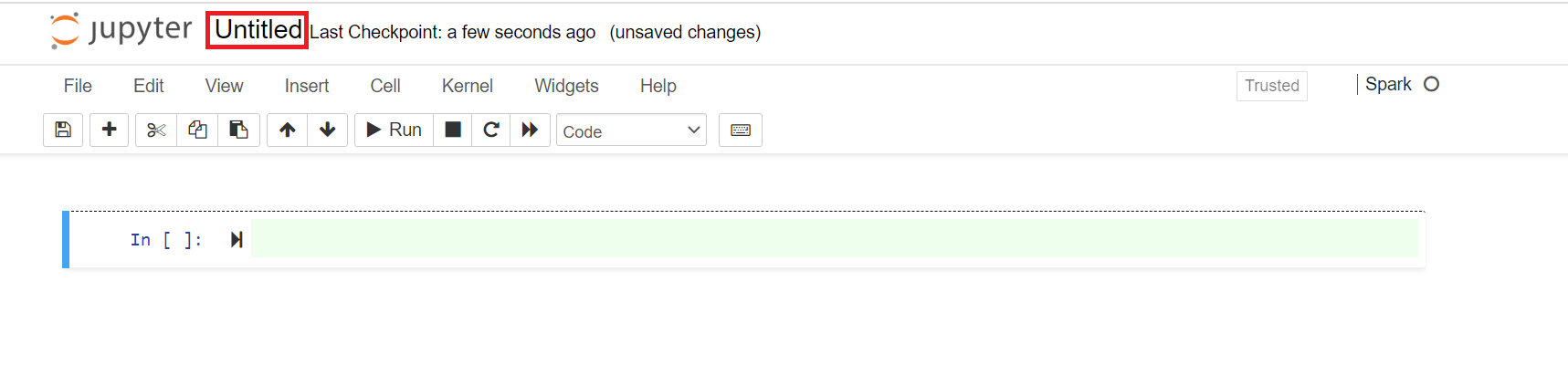
Verrà aperto un nuovo notebook con un nome predefinito Senza titolo. Fare clic sul nome del notebook e immettere un nome a scelta.
È ora possibile iniziare a creare l'applicazione.
Leggere i dati da database SQL di Azure
In questa sezione si leggeranno i dati di una tabella (ad esempio, SalesLT.Address) presente nel database AdventureWorks.
In un nuovo notebook di Jupyter, in una cella di codice, incollare il frammento di codice seguente e sostituire i valori segnaposto con i valori per il database.
// Declare the values for your database val jdbcUsername = "<SQL DB ADMIN USER>" val jdbcPassword = "<SQL DB ADMIN PWD>" val jdbcHostname = "<SQL SERVER NAME HOSTING SDL DB>" //typically, this is in the form or servername.database.windows.net val jdbcPort = 1433 val jdbcDatabase ="<AZURE SQL DB NAME>"Premere MAIUSC+INVIO per eseguire la cella di codice.
Usare il frammento di codice seguente per compilare un URL JDBC che è possibile passare alle API del dataframe Spark. Il codice crea un
Propertiesoggetto per contenere i parametri. Incollare il frammento di codice in una cella di codice e premere MAIUSC+INVIO per eseguirlo.import java.util.Properties val jdbc_url = s"jdbc:sqlserver://${jdbcHostname}:${jdbcPort};database=${jdbcDatabase};encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.windows.net;loginTimeout=60;" val connectionProperties = new Properties() connectionProperties.put("user", s"${jdbcUsername}") connectionProperties.put("password", s"${jdbcPassword}")Usare il frammento di codice seguente per creare un dataframe con i dati di una tabella nel database. In questo frammento di codice viene usata una
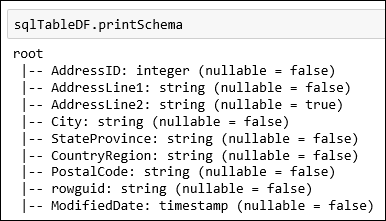
SalesLT.Addresstabella disponibile come parte del database AdventureWorksLT . Incollare il frammento di codice in una cella di codice e premere MAIUSC+INVIO per eseguirlo.val sqlTableDF = spark.read.jdbc(jdbc_url, "SalesLT.Address", connectionProperties)È ora possibile eseguire operazioni sul dataframe, ad esempio ottenere lo schema dei dati:
sqlTableDF.printSchemaViene visualizzato un output simile all'immagine seguente:
È anche possibile eseguire operazioni come recuperare le prime 10 righe.
sqlTableDF.show(10)o recuperare colonne specifiche dal set di dati.
sqlTableDF.select("AddressLine1", "City").show(10)
Scrivere dati in database SQL di Azure
In questa sezione viene usato un file CSV di esempio disponibile nel cluster per creare una tabella nel database e popolarla con i dati. Il file CSV di esempio (HVAC.csv) è disponibile in tutti i cluster HDInsight al percorso HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv.
In un nuovo notebook di Jupyter, in una cella di codice, incollare il frammento di codice seguente e sostituire i valori segnaposto con i valori per il database.
// Declare the values for your database val jdbcUsername = "<SQL DB ADMIN USER>" val jdbcPassword = "<SQL DB ADMIN PWD>" val jdbcHostname = "<SQL SERVER NAME HOSTING SDL DB>" //typically, this is in the form or servername.database.windows.net val jdbcPort = 1433 val jdbcDatabase ="<AZURE SQL DB NAME>"Premere MAIUSC+INVIO per eseguire la cella di codice.
Il frammento di codice seguente compila un URL JDBC che è possibile passare alle API del dataframe Spark. Il codice crea un
Propertiesoggetto per contenere i parametri. Incollare il frammento di codice in una cella di codice e premere MAIUSC+INVIO per eseguirlo.import java.util.Properties val jdbc_url = s"jdbc:sqlserver://${jdbcHostname}:${jdbcPort};database=${jdbcDatabase};encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.windows.net;loginTimeout=60;" val connectionProperties = new Properties() connectionProperties.put("user", s"${jdbcUsername}") connectionProperties.put("password", s"${jdbcPassword}")Usare il frammento di codice seguente per estrarre lo schema dei dati in HVAC.csv e usarlo per caricare i dati dal file CSV in un dataframe,
readDf. Incollare il frammento di codice in una cella di codice e premere MAIUSC+INVIO per eseguirlo.val userSchema = spark.read.option("header", "true").csv("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv").schema val readDf = spark.read.format("csv").schema(userSchema).load("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")Utilizzare il dataframe
readDfper creare una tabella temporanea,temphvactable. Usare quindi la tabella temporanea per creare una tabella hive,hvactable_hive.readDf.createOrReplaceTempView("temphvactable") spark.sql("create table hvactable_hive as select * from temphvactable")Usare infine la tabella hive per creare una tabella nel database. Il frammento di codice seguente viene creato
hvactablein database SQL di Azure.spark.table("hvactable_hive").write.jdbc(jdbc_url, "hvactable", connectionProperties)Connessione al database SQL di Azure usando SSMS e verificare che sia presente un
dbo.hvactableelemento.a. Avviare SSMS e connettersi al database SQL di Azure specificando i dettagli di connessione, come illustrato nello screenshot seguente.
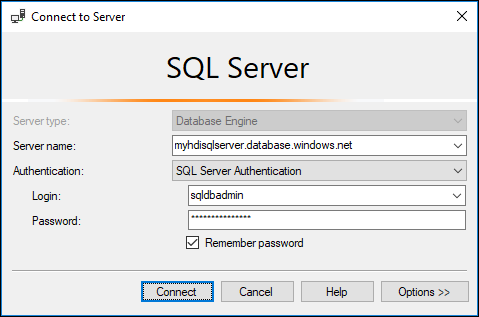
b. Da Esplora oggetti espandere il database e il nodo della tabella per visualizzare la tabella dbo.hvactable creata.
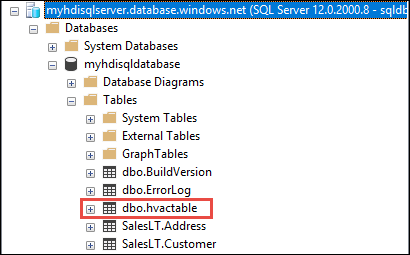
Eseguire una query in SSMS per visualizzare le colonne nella tabella.
SELECT * from hvactable
Trasmettere dati in database SQL di Azure
In questa sezione vengono trasmessi i dati nell'oggetto hvactable creato nella sezione precedente.
Come primo passaggio, assicurarsi che non siano presenti record nell'oggetto
hvactable. Eseguire la query seguente nella tabella tramite SQL Server Management Studio.TRUNCATE TABLE [dbo].[hvactable]Creare un nuovo notebook jupyter nel cluster HDInsight Spark. Incollare il frammento di codice seguente in una cella di codice e quindi premere MAIUSC+INVIO:
import org.apache.spark.sql._ import org.apache.spark.sql.types._ import org.apache.spark.sql.functions._ import org.apache.spark.sql.streaming._ import java.sql.{Connection,DriverManager,ResultSet}I dati vengono trasmessi dal HVAC.csv all'oggetto
hvactable. HVAC.csv file è disponibile nel cluster all'indirizzo/HdiSamples/HdiSamples/SensorSampleData/HVAC/. Nel frammento di codice seguente, prima si ottiene lo schema dei dati da trasmettere e quindi si usa lo schema per creare un dataframe di streaming. Incollare il frammento di codice in una cella di codice e premere MAIUSC+INVIO per eseguirlo.val userSchema = spark.read.option("header", "true").csv("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv").schema val readStreamDf = spark.readStream.schema(userSchema).csv("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/") readStreamDf.printSchemaL'output mostra lo schema di HVAC.csv, ha
hvactableanche lo stesso schema. Nell'output vengono elencate le colonne presenti nella tabella.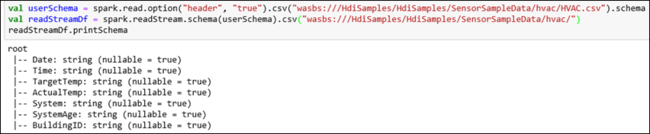
Usare infine il frammento di codice seguente per leggere i dati dal HVAC.csv e trasmetterli nel
hvactabledatabase. Incollare il frammento di codice in una cella di codice, sostituire i valori segnaposto con i valori per il database e quindi premere MAIUSC + INVIO per l'esecuzione.val WriteToSQLQuery = readStreamDf.writeStream.foreach(new ForeachWriter[Row] { var connection:java.sql.Connection = _ var statement:java.sql.Statement = _ val jdbcUsername = "<SQL DB ADMIN USER>" val jdbcPassword = "<SQL DB ADMIN PWD>" val jdbcHostname = "<SQL SERVER NAME HOSTING SDL DB>" //typically, this is in the form or servername.database.windows.net val jdbcPort = 1433 val jdbcDatabase ="<AZURE SQL DB NAME>" val driver = "com.microsoft.sqlserver.jdbc.SQLServerDriver" val jdbc_url = s"jdbc:sqlserver://${jdbcHostname}:${jdbcPort};database=${jdbcDatabase};encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.windows.net;loginTimeout=30;" def open(partitionId: Long, version: Long):Boolean = { Class.forName(driver) connection = DriverManager.getConnection(jdbc_url, jdbcUsername, jdbcPassword) statement = connection.createStatement true } def process(value: Row): Unit = { val Date = value(0) val Time = value(1) val TargetTemp = value(2) val ActualTemp = value(3) val System = value(4) val SystemAge = value(5) val BuildingID = value(6) val valueStr = "'" + Date + "'," + "'" + Time + "'," + "'" + TargetTemp + "'," + "'" + ActualTemp + "'," + "'" + System + "'," + "'" + SystemAge + "'," + "'" + BuildingID + "'" statement.execute("INSERT INTO " + "dbo.hvactable" + " VALUES (" + valueStr + ")") } def close(errorOrNull: Throwable): Unit = { connection.close } }) var streamingQuery = WriteToSQLQuery.start()Verificare che i dati vengano trasmessi a
hvactableeseguendo la query seguente in SQL Server Management Studio (SSMS). Ogni volta che si esegue la query, il numero di righe nella tabella aumenta.SELECT COUNT(*) FROM hvactable