Continuità aziendale e ripristino di emergenza per App per la logica di Azure
Per ridurre l'impatto e gli effetti che gli eventi imprevedibili hanno per le aziende e i clienti, assicurarsi di avere una soluzione di ripristino di emergenza (RIPRISTINO di emergenza) in modo che sia possibile proteggere i dati, ripristinare rapidamente le risorse che supportano le funzioni aziendali critiche e mantenere le operazioni in esecuzione per mantenere la continuità aziendale (BC). Ad esempio, le interruzioni possono includere interruzioni, perdite nell'infrastruttura o nei componenti sottostanti, ad esempio archiviazione, rete o risorse di calcolo, errori delle applicazioni non recuperabili o anche una perdita completa del data center. Avendo una soluzione di continuità aziendale e ripristino di emergenza pronta, l'organizzazione o l'organizzazione possono rispondere più rapidamente alle interruzioni, pianificate o non pianificate e ridurre i tempi di inattività per i clienti.
Questo articolo fornisce indicazioni e strategie BCDR che è possibile applicare quando si creano flussi di lavoro automatizzati usando App per la logica di Azure. I flussi di lavoro delle app per la logica consentono di integrare e orchestrare più facilmente i dati tra app, servizi cloud e sistemi locali riducendo la quantità di codice da scrivere. Quando si pianifica BCDR, assicurarsi di considerare non solo le app per la logica, ma anche queste risorse di Azure usate con le app per la logica:
Connessioni create dai flussi di lavoro dell'app per la logica ad altre app, servizi e sistemi. Per altre informazioni, vedere Connessioni alle risorse più avanti in questo argomento.
Gateway dati locali che sono risorse di Azure create e usate nelle app per la logica per accedere ai dati nei sistemi locali. Ogni risorsa gateway rappresenta un'installazione separata del gateway dati in un computer locale. Per altre informazioni, vedere Gateway dati locali più avanti in questo argomento.
Account di integrazione in cui si definiscono e archiviano gli artefatti usati dalle app per la logica per gli scenari di integrazione aziendale (B2B). Ad esempio, è possibile configurare il ripristino di emergenza tra aree per gli account di integrazione.
Ambienti del servizio di integrazione (ISE) in cui si creano app per la logica eseguite in un'istanza di runtime di App per la logica isolata all'interno di una rete virtuale di Azure. Queste app per la logica possono quindi accedere alle risorse protette dietro un firewall in tale rete virtuale.
Posizioni primarie e secondarie
Ogni app per la logica deve specificare il percorso da usare per la distribuzione. Questa posizione è un'area pubblica in Azure multi-tenant globale, ad esempio "Stati Uniti occidentali" o un ambiente del servizio di integrazione (ISE) creato e distribuito in precedenza in una rete virtuale di Azure. L'esecuzione di app per la logica in un ISE è simile all'esecuzione di app per la logica in un'area di Azure globale, che significa che la strategia di ripristino di emergenza può essere applicata a entrambi gli scenari. Tuttavia, gli ISE hanno altre considerazioni, ad esempio la configurazione dell'accesso alle risorse disponibili solo per gli ISE.
Nota
Se l'app per la logica funziona anche con elementi B2B, ad esempio partner commerciali, contratti, schemi, mappe e certificati, archiviati in un account di integrazione, sia l'account di integrazione che le app per la logica devono specificare la stessa posizione.
Questa strategia di ripristino di emergenza è incentrata sulla configurazione dell'app per la logica primaria per eseguire il failover in un'app per la logica di standby o di backup in una posizione alternativa in cui è disponibile anche App per la logica di Azure. In questo modo, se il primario subisce perdite, interruzioni o errori, il secondario può assumere il lavoro. Questa strategia richiede che l'app per la logica secondaria e le risorse dipendenti siano già distribuite e pronte nella posizione alternativa.
Se si seguono procedure devOps valide, è già possibile usare modelli di Azure Resource Manager per definire e distribuire le app per la logica e le relative risorse dipendenti. Resource Manager modelli offrono la possibilità di usare una singola definizione di distribuzione e quindi usare i file di parametro per fornire i valori di configurazione da usare per ogni destinazione di distribuzione. Questa funzionalità significa che è possibile distribuire la stessa app per la logica in ambienti diversi, ad esempio sviluppo, test e produzione. È anche possibile distribuire la stessa app per la logica in aree o ISE diverse, che supportano strategie di ripristino di emergenza che usano aree associate.
Per la strategia di failover, le app e le posizioni per la logica devono soddisfare questi requisiti:
L'istanza dell'app per la logica secondaria ha accesso alle stesse app, servizi e sistemi dell'istanza dell'app per la logica primaria.
Entrambe le istanze dell'app per la logica hanno lo stesso tipo di host. Quindi, entrambe le istanze vengono distribuite nelle aree in Azure multi-tenant globale o entrambe le istanze vengono distribuite in ISE, che consentono alle app per la logica di accedere direttamente alle risorse in una rete virtuale di Azure. Per le procedure consigliate e altre informazioni sulle aree associate per BCDR, vedere Replica tra aree in Azure: continuità aziendale e ripristino di emergenza.
Ad esempio, sia le posizioni primarie che secondarie devono essere ISE quando l'app per la logica primaria viene eseguita in un ISE e usa connettori con versione ISE, azioni HTTP per chiamare le risorse nella rete virtuale di Azure o entrambe. In questo scenario, l'app per la logica secondaria deve avere anche una configurazione simile nella posizione secondaria come app per la logica primaria.
Nota
Per scenari più avanzati, è possibile combinare sia Azure multi-tenant che un ISE come posizioni. Assicurarsi tuttavia di considerare e comprendere le differenze tra il modo in cui le app per la logica vengono eseguite in un'istanza di ISE rispetto ad Azure multi-tenant.
Se si usano gli ISE, assicurarsi che vengano ridimensionati o abbiano una capacità sufficiente per gestire il carico.
Esempio: Azure multi-tenant
In questo esempio vengono illustrate le istanze dell'app per la logica primaria e secondaria, distribuite in aree separate in Azure multi-tenant globale per questo scenario. Un singolo modello di Resource Manager definisce sia le istanze dell'app per la logica che le risorse dipendenti richieste da tali app per la logica. I file di parametri separati specificano i valori di configurazione da usare per ogni percorso di distribuzione:
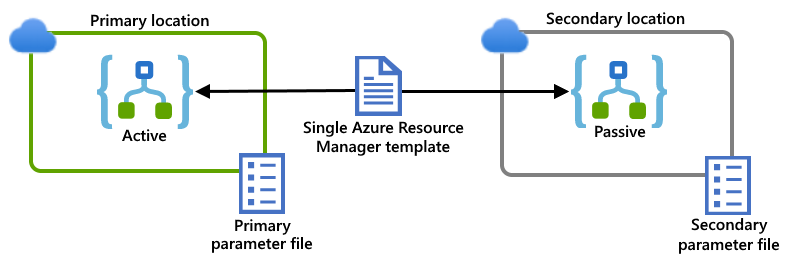
Esempio: Ambiente del servizio di integrazione
In questo esempio vengono illustrate le istanze precedenti dell'app per la logica primaria e secondaria, ma distribuite in ISE separati. Un singolo modello di Resource Manager definisce entrambe le istanze dell'app per la logica, le risorse dipendenti richieste da tali app per la logica e gli ISE come posizioni di distribuzione. I file di parametri separati definiscono i valori di configurazione da usare per la distribuzione in ogni percorso:
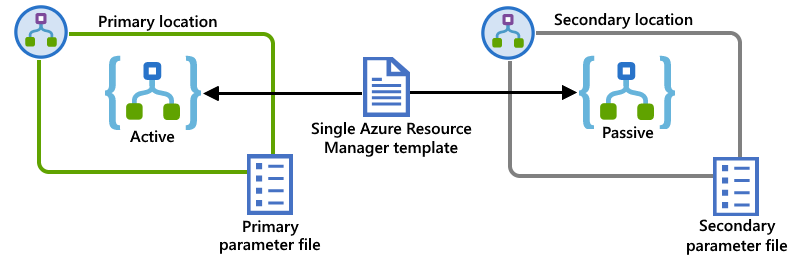
Connessioni alle risorse
App per la logica di Azure offre molte centinaia di operazioni del connettore che il flusso di lavoro dell'app per la logica può usare per usare altre app, servizi, sistemi e altre risorse, ad esempio account di archiviazione di Azure, SQL Server database, account di posta elettronica aziendale o dell'istituto di istruzione e così via. Se l'app per la logica deve accedere a queste risorse, creare connessioni che autenticano l'accesso a queste risorse. Ogni connessione è una risorsa di Azure separata che esiste in una posizione specifica e non può essere usata dalle risorse in altre posizioni.
Per la strategia di ripristino di emergenza, prendere in considerazione le posizioni in cui esistono risorse dipendenti rispetto alle istanze dell'app per la logica:
L'istanza primaria e le risorse dipendenti esistono in posizioni diverse. In questo caso, l'istanza secondaria può connettersi alle stesse risorse o endpoint dipendenti. Tuttavia, è necessario creare connessioni in modo specifico per l'istanza secondaria. In questo modo, se la posizione primaria non è disponibile, le connessioni secondarie non sono interessate.
Si supponga, ad esempio, che l'app per la logica primaria si connette a un servizio esterno, ad esempio Salesforce. In genere, la disponibilità e la posizione del servizio esterno sono indipendenti dalla disponibilità dell'app per la logica. In questo caso, l'istanza secondaria può connettersi allo stesso servizio ma deve avere la propria connessione.
Sia l'istanza primaria che le risorse dipendenti esistono nella stessa posizione. In questo caso, le risorse dipendenti devono avere backup o versioni replicate in una posizione diversa in modo che l'istanza secondaria possa comunque accedere a tali risorse.
Si supponga, ad esempio, che l'app per la logica primaria si connette a un servizio nella stessa posizione o area, ad esempio Azure SQL Database. Se l'intera area non è disponibile, è probabile che il servizio database Azure SQL in tale area non sia disponibile. In questo caso, si vuole che l'istanza secondaria usi un database replicato o di backup insieme a una connessione separata al database.
Gateway dati locali
Se l'app per la logica viene eseguita in Azure multi-tenant e deve accedere alle risorse locali, ad esempio i database SQL Server, è necessario installare il gateway dati locale in un computer locale. È quindi possibile creare una risorsa gateway dati nella portale di Azure in modo che l'app per la logica possa usare il gateway quando si crea una connessione alla risorsa.
La risorsa gateway dati è associata a una posizione o a un'area di Azure, proprio come la risorsa dell'app per la logica. Nella strategia di ripristino di emergenza assicurarsi che il gateway dati rimanga disponibile per l'uso dell'app per la logica. È possibile abilitare la disponibilità elevata per il gateway quando sono presenti più installazioni del gateway.
Nota
Se l'app per la logica viene eseguita in un ambiente del servizio di integrazione (ISE) e usa solo connettori ise-versioned per origini dati locali, non è necessario il gateway dati perché i connettori ISE forniscono l'accesso diretto alla risorsa locale.
Se non è disponibile alcun connettore con versione ISE per la risorsa locale desiderata, l'app per la logica può comunque creare la connessione usando un connettore non ISE, che viene eseguito in Azure multi-tenant globale, non l'ISE. Questa connessione richiede tuttavia il gateway dati locale.
Ruoli attivi e passivi attivi
È possibile configurare le posizioni primarie e secondarie in modo che le istanze dell'app per la logica in queste posizioni possano svolgere questi ruoli:
| Ruolo primario secondario | Descrizione |
|---|---|
| Attivo | Le istanze dell'app per la logica primaria e secondaria in entrambe le posizioni gestiscono attivamente le richieste seguendo uno di questi modelli: - Bilanciamento del carico: è possibile avere entrambe le istanze in ascolto di un endpoint e il traffico di bilanciamento del carico per ogni istanza in base alle esigenze. - Consumer concorrenti: è possibile avere entrambe le istanze come consumer concorrenti in modo che le istanze competono per i messaggi da una coda. Se un'istanza ha esito negativo, l'altra istanza accetta il carico di lavoro. |
| Attivo-passivo | L'istanza dell'app per la logica primaria gestisce attivamente l'intero carico di lavoro, mentre l'istanza secondaria è passiva (disabilitata o inattiva). Il secondario attende un segnale che il primario non è disponibile o non funziona a causa di interruzioni o errori e assume il carico di lavoro come istanza attiva. |
| Combinazione | Alcune app per la logica svolgono un ruolo attivo, mentre altre app per la logica svolgono un ruolo attivo-passivo. |
Esempi attivi
Questi esempi mostrano la configurazione attiva in cui entrambe le istanze dell'app per la logica gestiscono attivamente le richieste o i messaggi. Alcuni altri sistemi o servizi distribuiscono le richieste o i messaggi tra istanze, ad esempio una di queste opzioni:
Servizio di bilanciamento del carico "fisico", ad esempio un componente hardware che instrada il traffico
Servizio di bilanciamento del carico "soft", ad esempio Azure Load Balancer o Azure Gestione API. Con Gestione API è possibile specificare criteri che determinano come bilanciare il carico del traffico in ingresso. In alternativa, è possibile usare un servizio che supporta il rilevamento dello stato, ad esempio bus di servizio di Azure.
Anche se questo esempio mostra principalmente Azure Load Balancer, è possibile usare l'opzione più adatta alle esigenze dello scenario:
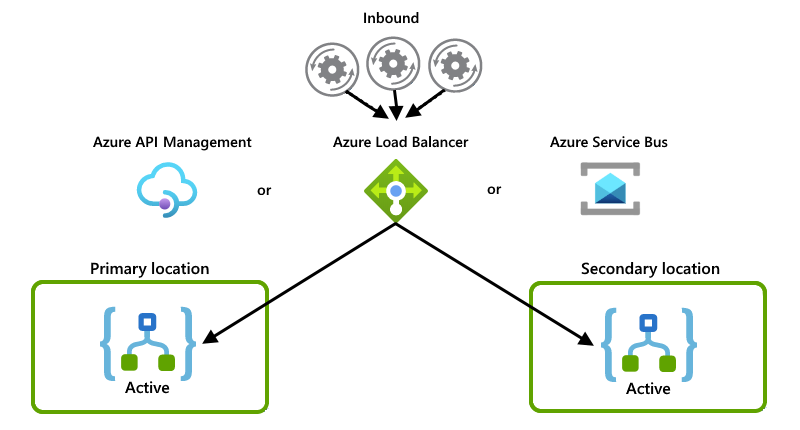
Ogni istanza dell'app per la logica funge da consumer e ha entrambe le istanze che competono per i messaggi da una coda:
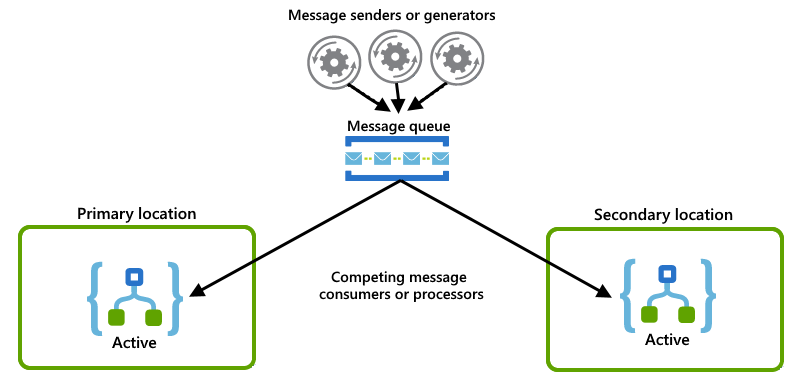
Esempi attivi-passivi
Questo esempio mostra la configurazione attiva-passiva in cui l'istanza dell'app per la logica primaria è attiva in una posizione, mentre l'istanza secondaria rimane inattiva in un'altra posizione. Se si verifica un'interruzione o un errore primario, è possibile eseguire uno script che attiva il carico di lavoro secondario.
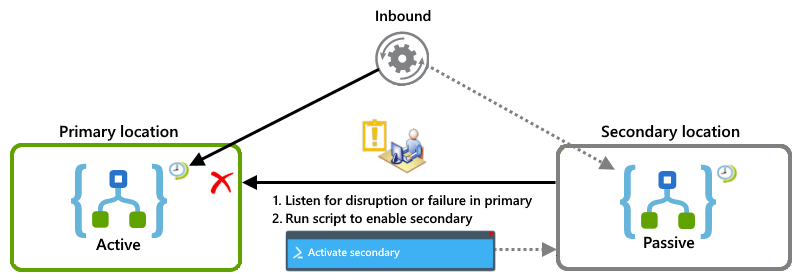
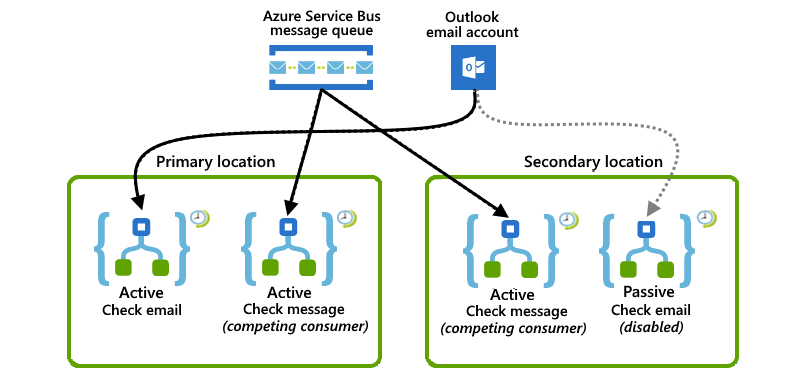
Combinazione con attivo e attivo-passivo
In questo esempio viene illustrata una configurazione combinata in cui la posizione primaria include entrambe le istanze dell'app per la logica attiva, mentre la posizione secondaria include istanze di app per la logica passiva attiva. Se la posizione primaria riscontra un'interruzione o un errore, l'app per la logica attiva nella posizione secondaria, che gestisce già un carico di lavoro parziale, può assumere l'intero carico di lavoro.
Nella posizione primaria un'app per la logica attiva è in ascolto di una coda di bus di servizio di Azure per i messaggi, mentre un'altra app per la logica attiva controlla i messaggi di posta elettronica usando un trigger di polling di Outlook Office 365.
Nella posizione secondaria un'app per la logica attiva funziona con l'app per la logica nella posizione primaria eseguendo l'ascolto e la concorrenza dei messaggi dalla stessa coda del bus di servizio. Nel frattempo, un'app per la logica passiva attende in standby per verificare la presenza di messaggi di posta elettronica quando la posizione primaria non è disponibile, ma è disabilitata per evitare la rilettura dei messaggi di posta elettronica.
Stato e cronologia dell'app per la logica
Quando l'app per la logica viene attivata e viene avviata l'esecuzione, lo stato dell'app viene archiviato nello stesso percorso in cui l'app è stata avviata e non è trasferiscibile in un'altra posizione. Se si verifica un errore o un'interruzione, le istanze del flusso di lavoro in corso vengono abbandonate. Quando si dispone di una posizione primaria e secondaria configurata, le nuove istanze del flusso di lavoro iniziano a essere eseguite nella posizione secondaria.
Ridurre le istanze in corso abbandonate
Per ridurre al minimo il numero di istanze del flusso di lavoro in corso abbandonate, è possibile scegliere tra vari modelli di messaggio che è possibile implementare, ad esempio:
Modello di scorrimento risolto
Questo modello di messaggio aziendale che suddivide un processo aziendale in fasi più piccole. Per ogni fase, si configura un'app per la logica che gestisce il carico di lavoro per tale fase. Per comunicare tra loro, le app per la logica usano un protocollo di messaggistica asincrona, ad esempio bus di servizio di Azure code o argomenti. Quando si divide un processo in fasi più piccole, si riduce il numero di processi aziendali che potrebbero essere bloccati in un'istanza dell'app per la logica non riuscita. Per altre informazioni generali su questo modello, vedere Modelli di integrazione aziendale - Scorrimento del routing.
In questo esempio viene illustrato un modello di scorrimento del routing in cui ogni app per la logica rappresenta una fase e usa una coda del bus di servizio per comunicare con l'app per la logica successiva nel processo.
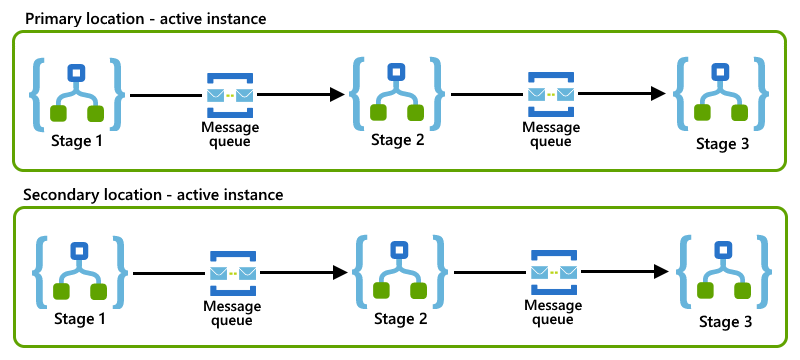
Se le istanze dell'app per la logica primaria e secondaria seguono lo stesso modello di scorrimento del routing nelle loro posizioni, è possibile implementare il modello di consumer concorrenti configurando ruoli attivi per tali istanze.
Accesso per attivare ed eseguire la cronologia delle esecuzioni
Per ottenere altre informazioni sulle esecuzioni precedenti dell'app per la logica, è possibile esaminare il trigger e la cronologia delle esecuzioni dell'app. La cronologia di esecuzione di un'app per la logica viene archiviata nella stessa posizione o area in cui è stata eseguita l'app per la logica, che significa che non è possibile eseguire la migrazione di questa cronologia a una posizione diversa. Se l'istanza primaria esegue il failover in un'istanza secondaria, è possibile accedere solo alla cronologia dei trigger e delle esecuzioni di ogni istanza nelle rispettive posizioni in cui sono state eseguite tali istanze. È tuttavia possibile ottenere informazioni sulla cronologia dell'app per la logica configurando le app per la logica per inviare eventi di diagnostica a un'area di lavoro di Azure Log Analytics. È quindi possibile esaminare l'integrità e la cronologia tra app per la logica eseguite in più posizioni.
Indicazioni sul tipo di trigger
Il tipo di trigger usato nelle app per la logica determina le opzioni per la configurazione di app per la logica tra posizioni nella strategia di ripristino di emergenza. Ecco i tipi di trigger disponibili che è possibile usare nelle app per la logica:
Trigger Recurrence
Il trigger Ricorrenza è indipendente da qualsiasi servizio o endpoint specifico e genera solo una pianificazione specificata e nessun altro criterio, ad esempio:
- Frequenza fissa e intervallo, ad esempio ogni 10 minuti
- Una pianificazione più avanzata, ad esempio l'ultimo lunedì di ogni mese alle 15:00
Quando l'app per la logica inizia con un trigger Ricorrenza, è necessario configurare le istanze dell'app per la logica primaria e secondaria con i ruoli passivi attivi. Per ridurre l'obiettivo del tempo di ripristino (RTO), che fa riferimento alla durata di destinazione per il ripristino di un processo aziendale dopo un'interruzione o un'emergenza, è possibile configurare le istanze dell'app per la logica con una combinazione di ruoli attivi-passivi e ruoli attivi passivi. In questa configurazione viene suddivisa la pianificazione tra posizioni.
Si supponga, ad esempio, di avere un'app per la logica che deve essere eseguita ogni 10 minuti. È possibile configurare le app e le posizioni per la logica in modo che se la posizione primaria non sia disponibile, la posizione secondaria può assumere il lavoro:
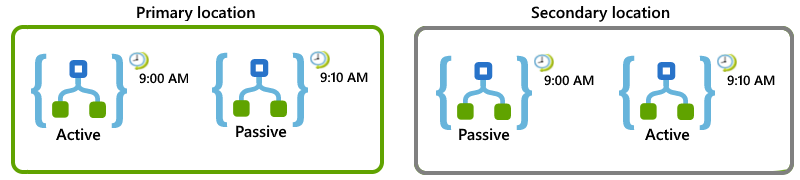
Nella posizione primaria configurare ruoli attivi-passivi per queste app per la logica:
Per l'app per la logica abilitata attiva , impostare il trigger Ricorrenza per iniziare all'inizio dell'ora e ripetere ogni 20 minuti, ad esempio 9:00, 9:20 e così via.
Per l'app per la logica disabilitata passiva , impostare il trigger Ricorrenza sulla stessa pianificazione, ma iniziare a 10 minuti dall'ora e ripetere ogni 20 minuti, ad esempio 9:10 AM, 9:30 AM e così via.
Nella posizione secondaria configurare l'attività passiva per queste app per la logica:
Per l'app per la logica disabilitata passiva , impostare il trigger Ricorrenza sulla stessa pianificazione dell'app per la logica attiva nella posizione primaria, che si trova nella parte superiore dell'ora e ripetere ogni 20 minuti, ad esempio 9:00, 9:10 AM e così via.
Per l'app per la logica abilitata attiva , impostare il trigger Ricorrenza sulla stessa pianificazione dell'app per la logica passiva nella posizione primaria, che consiste nell'iniziare a 10 minuti dall'ora e ripetere ogni 20 minuti, ad esempio 9:10, 9:20 AM e così via.
Ora, se si verifica un evento di interruzione nella posizione primaria, attivare l'app per la logica passiva nella posizione alternativa. In questo modo, se la ricerca dell'errore richiede tempo, questa configurazione limita il numero di ricorrenze perse durante tale ritardo.
Trigger di polling
Per verificare regolarmente se i nuovi dati per l'elaborazione sono disponibili da un servizio o un endpoint specifici, l'app per la logica può usare un trigger di polling che chiama ripetutamente il servizio o l'endpoint in base a una pianificazione di ricorrenza fissa. I dati forniti dal servizio o dall'endpoint possono avere uno di questi tipi:
- Dati statici, che descrivono i dati sempre disponibili per la lettura
- Dati volatili, che descrivono i dati che non sono più disponibili dopo la lettura
Per evitare ripetutamente di leggere gli stessi dati, l'app per la logica deve ricordare quali dati sono stati letti in precedenza mantenendo lo stato sul lato client o sul lato server, servizio o sistema.
Le app per la logica che funzionano con lo stato lato client usano trigger che possono mantenere lo stato.
Ad esempio, un trigger che legge un nuovo messaggio da una posta elettronica richiede che il trigger possa ricordare il messaggio di lettura più recente. In questo modo, il trigger avvia l'app per la logica solo quando arriva il messaggio non letto successivo.
Le app per la logica che funzionano con server, servizio o stato lato sistema usano valori di proprietà o impostazioni presenti sul lato server, servizio o sistema.
Ad esempio, un trigger basato su query che legge una riga da un database richiede che la riga abbia una
isReadcolonna impostata suFALSE. Ogni volta che il trigger legge una riga, l'app per la logica aggiorna la riga modificando laisReadcolonna daFALSEaTRUE.Questo approccio lato server funziona in modo analogo per le code o gli argomenti del bus di servizio con semantica di accodamento in cui un trigger può leggere e bloccare un messaggio mentre l'app per la logica elabora il messaggio. Al termine dell'elaborazione dell'app per la logica, il trigger elimina il messaggio dalla coda o dall'argomento.
Dal punto di vista del ripristino di emergenza, quando si configurano le istanze primarie e secondarie dell'app per la logica, assicurarsi di tenere conto di questi comportamenti in base al fatto che l'app per la logica tiene traccia dello stato sul lato client o sul lato server:
Per un'app per la logica che funziona con lo stato lato client, assicurarsi che l'app per la logica non legge lo stesso messaggio più di una volta. Una sola posizione può avere un'istanza di app per la logica attiva in qualsiasi momento specifico. Assicurarsi che l'istanza dell'app per la logica nel percorso alternativo sia inattiva o disabilitata fino al failover dell'istanza primaria nel percorso alternativo.
Ad esempio, il trigger Office 365 Outlook mantiene lo stato lato client e tiene traccia del timestamp per il messaggio di posta elettronica di lettura più recente per evitare la lettura di un duplicato.
Per un'app per la logica che funziona con lo stato lato server, è possibile configurare le istanze dell'app per la logica per svolgere ruoli attivi in cui funzionano come consumer concorrenti o ruoli passivi attivi in cui l'istanza alternativa attende fino al failover dell'istanza primaria alla posizione alternativa.
Ad esempio, la lettura da una coda di messaggi, ad esempio una coda bus di servizio di Azure, usa lo stato lato server perché il servizio di accodamento mantiene i blocchi sui messaggi per impedire ad altri client di leggere gli stessi messaggi.
Nota
Se l'app per la logica deve leggere i messaggi in un ordine specifico, ad esempio da una coda del bus di servizio, è possibile usare il modello consumer concorrente, ma solo se combinato con sessioni del bus di servizio, noto anche come modello di chiamata sequenziale. In caso contrario, è necessario configurare le istanze dell'app per la logica con i ruoli passivi attivi.
Trigger di richiesta
Il trigger Request rende l'app per la logica chiamabile da altre app, servizi e sistemi ed è in genere usata per fornire queste funzionalità:
API REST diretta per l'app per la logica che altri utenti possono chiamare
Ad esempio, usare il trigger Request per avviare l'app per la logica in modo che altre app per la logica possano chiamare il trigger usando l'azione Chiama flusso di lavoro - App per la logica.
Meccanismo di webhook o callback per l'app per la logica
Un modo per eseguire manualmente operazioni utente o routine per chiamare l'app per la logica, ad esempio usando uno script di PowerShell che esegue un'attività specifica
Dal punto di vista del ripristino di emergenza, il trigger Request è un ricevitore passivo perché l'app per la logica non esegue operazioni e attende fino a quando un altro servizio o sistema chiama in modo esplicito il trigger. Come endpoint passivo, è possibile configurare le istanze primarie e secondarie in questi modi:
Active-active: entrambe le istanze gestiscono attivamente le richieste o le chiamate. Il chiamante o il router bilancia o distribuisce il traffico tra queste istanze.
Attivo-passivo: solo l'istanza primaria è attiva e gestisce tutto il lavoro, mentre l'istanza secondaria attende fino all'interruzione o all'errore dell'esperienza primaria. Il chiamante o il router determina quando chiamare l'istanza secondaria.
Come architettura consigliata, è possibile usare Azure Gestione API come proxy per le app per la logica che usano trigger di richiesta. Gestione API offre resilienza tra aree predefinite e la possibilità di instradare il traffico tra più endpoint.
Trigger di webhook
Un trigger webhook consente all'app per la logica di sottoscrivere un servizio passando un URL di callback a tale servizio. L'app per la logica può quindi restare in ascolto e attendere che si verifichi un evento specifico in tale endpoint di servizio. Quando si verifica l'evento, il servizio chiama il trigger webhook usando l'URL di callback, che esegue quindi l'app per la logica. Se abilitato, il trigger webhook sottoscrive il servizio. Se disabilitato, il trigger annulla la sottoscrizione al servizio.
Dal punto di vista del ripristino di emergenza, configurare istanze primarie e secondarie che usano trigger webhook per giocare ruoli attivi-passivi perché solo un'istanza deve ricevere eventi o messaggi dall'endpoint sottoscritto.
Valutare l'integrità dell'istanza primaria
Per il corretto funzionamento della strategia di ripristino di emergenza, la soluzione richiede modi per eseguire queste attività:
- Controllare la disponibilità dell'istanza primaria
- Monitorare l'integrità dell'istanza primaria
- Attivare l'istanza secondaria
Questa sezione descrive una soluzione che è possibile usare in modo definitivo o come base per la propria progettazione. Ecco una panoramica generale dell'oggetto visivo per questa soluzione:
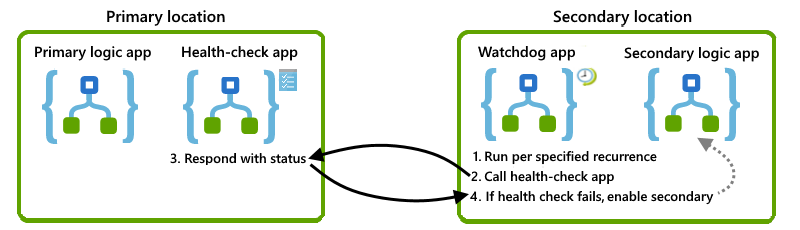
Controllare la disponibilità dell'istanza primaria
Per determinare se l'istanza primaria è disponibile, in esecuzione e in grado di funzionare, è possibile creare un'app per la logica "controllo integrità" che si trova nella stessa posizione dell'istanza primaria. È quindi possibile chiamare questa app per il controllo dell'integrità da una posizione alternativa. Se l'app di controllo integrità risponde correttamente, l'infrastruttura sottostante per il servizio App per la logica di Azure in tale area è disponibile e funzionante. Se l'app di controllo integrità non risponde, è possibile presupporre che la posizione non sia più integra.
Per questa attività, creare un'app per la logica di controllo integrità di base che esegue queste attività:
Riceve una chiamata dall'app watchdog usando il trigger Di richiesta.
Rispondere con uno stato che indica se l'app per la logica controllata funziona ancora usando l'azione Risposta.
Importante
L'app per la logica di controllo integrità deve usare un'azione Risposta in modo che l'app risponda in modo sincrono, non in modo asincrono.
Facoltativamente, per determinare ulteriormente se la posizione primaria è integra, è possibile determinare l'integrità di qualsiasi altro servizio che interagisce con l'app per la logica di destinazione in questa posizione. È sufficiente espandere l'app per la logica di controllo integrità per valutare anche l'integrità di questi altri servizi.
Creare un'app per la logica watchdog
Per monitorare l'integrità dell'istanza primaria e chiamare l'app per la logica health-check, creare un'app per la logica "watchdog" in una posizione alternativa. Ad esempio, è possibile configurare l'app per la logica watchdog in modo che, se la chiamata alla logica del controllo integrità ha esito negativo, il watchdog può inviare un avviso al team operativo in modo che possano analizzare l'errore e perché l'istanza primaria non risponde.
Importante
Assicurarsi che l'app per la logica watchdog si trova in una posizione diversa da quella primaria. Se App per la logica di Azure nella posizione primaria riscontra problemi, è possibile che il flusso di lavoro dell'app per la logica watchdog non venga eseguito.
Per questa attività, nella posizione secondaria creare un'app per la logica watchdog che esegue queste attività:
Eseguire in base a una ricorrenza fissa o pianificata usando il trigger Ricorrenza.
È possibile impostare la ricorrenza su un valore inferiore al livello di tolleranza per l'obiettivo del tempo di ripristino (RTO).
Chiamare il flusso di lavoro dell'app per la logica di controllo dell'integrità nella posizione primaria usando l'azione HTTP.
È anche possibile creare un'app per la logica watchdog più sofisticata, che dopo diversi errori chiama un'altra app per la logica che gestisce automaticamente il passaggio alla posizione secondaria quando il database primario ha esito negativo.
Attivare l'istanza secondaria
Per attivare automaticamente l'istanza secondaria, è possibile creare un'app per la logica che chiama l'API di gestione, ad esempio il connettore azure Resource Manager per attivare le app per la logica appropriate nella posizione secondaria. È possibile espandere l'app watchdog per chiamare questa app per la logica di attivazione dopo un determinato numero di errori.
Ridondanza della zona con zone di disponibilità
In ogni area di Azure le zone di disponibilità sono posizioni fisicamente separate a tolleranza agli errori locali. Tali errori possono variare da errori software e hardware a eventi quali terremoti, inondazioni e incendi. Queste zone raggiungono la tolleranza attraverso la ridondanza e l'isolamento logico dei servizi di Azure.
Per garantire resilienza e disponibilità distribuita, esistono almeno tre zone di disponibilità separate in qualsiasi area di Azure che supporta e abilita la ridondanza della zona. La piattaforma App per la logica di Azure distribuisce queste zone e i carichi di lavoro delle app per la logica in queste zone. Questa funzionalità è un requisito fondamentale per l'abilitazione di architetture resilienti e la disponibilità elevata in caso di errori del data center in un'area.
Questa funzionalità è attualmente disponibile in anteprima e disponibile per le nuove app per la logica a consumo in aree specifiche. Per altre informazioni, vedere la documentazione seguente:
- Proteggere le app per la logica a consumo da errori di area con ridondanza della zona e zone di disponibilità
- Aree e zone di disponibilità di Azure
Raccogliere dati di diagnostica
È possibile configurare la registrazione per le esecuzioni dell'app per la logica e inviare i dati di diagnostica risultanti a servizi quali Archiviazione di Azure, Hub eventi di Azure e Azure Log Analytics per un'ulteriore gestione e elaborazione.
Se si vogliono usare questi dati con Azure Log Analytics, è possibile rendere disponibili i dati per le posizioni primarie e secondarie configurando le impostazioni di diagnostica dell'app per la logica e inviando i dati a più aree di lavoro Log Analytics. Per altre informazioni, vedere Configurare i log di Monitoraggio di Azure e raccogliere dati di diagnostica per App per la logica di Azure.
Se si vogliono inviare i dati ad Archiviazione di Azure o Hub eventi di Azure, è possibile rendere disponibili i dati per le posizioni primarie e secondarie configurando la ridondanza geografica. Per altre informazioni, vedere questi articoli:
Passaggi successivi
- Progettare applicazioni Azure affidabili
- Elenco di controllo per la resilienza per servizi di Azure specifici
- Gestione dei dati per la resilienza in Azure
- Backup e ripristino di emergenza per le applicazioni Azure
- Eseguire il ripristino dopo un'interruzione di servizio a livello di area
- Contratti di servizio Microsoft per i servizi di Azure