Data wrangling con pool di Apache Spark (deprecato)
SI APPLICA A: Python SDK azureml v1
Python SDK azureml v1
Avviso
L'integrazione di Azure Synapse Analytics con Azure Machine Learning, disponibile Python SDK v1, è deprecata. Gli utenti possono comunque usare l'area di lavoro di Synapse, registrata con Azure Machine Learning, come servizio collegato. Tuttavia, non è più possibile registrare una nuova area di lavoro di Synapse con Azure Machine Learning come servizio collegato. È consigliabile usare l'ambiente di calcolo Spark serverless e i pool di Spark per Synapse collegati, disponibili nell'interfaccia della riga di comando v2 e in Python SDK v2. Per altre informazioni, vedere https://aka.ms/aml-spark.
Questo articolo illustra come eseguire in modo interattivo attività di data wrangling in una sessione di Synapse dedicata, basata su Azure Synapse Analytics, in un notebook Jupyter. Per queste attività si usa Azure Machine Learning Python SDK. Per altre informazioni sulle pipeline di Azure Machine Learning, vedere Come usare Apache Spark (basato su Azure Synapse Analytics) nella pipeline di Machine Learning (anteprima). Per altre informazioni su come usare Azure Synapse Analytics con un'area di lavoro di Synapse, vedere la serie introduttiva su Azure Synapse Analytics.
Integrazione di Azure Machine Learning e Azure Synapse Analytics
Con l'integrazione di Azure Synapse Analytics con Azure Machine Learning (anteprima) è possibile collegare un pool Apache Spark, supportato da Azure Synapse, per attività interattive di esplorazione e preparazione dei dati. Con questa integrazione, è possibile avere una risorsa di calcolo dedicato per il data wrangling su larga scala, il tutto all'interno dello stesso notebook Python usato per il training dei modelli di Machine Learning.
Prerequisiti
Configurare l'ambiente di sviluppo per installare Azure Machine Learning SDK oppure usare un'istanza di ambiente di calcolo di Azure Machine Learning con l'SDK già installato
Installare Azure Machine Learning Python SDK
Creare un pool di Apache Spark con il portale di Azure, strumenti Web o Synapse Studio
Installare il pacchetto
azureml-synapse(anteprima) con il codice seguente:pip install azureml-synapseCollegare l'area di lavoro di Azure Machine Learning e l'area di lavoro di Azure Synapse Analytics con Azure Machine Learning Python SDK o con lo studio di Azure Machine Learning
Collegare un pool di Spark per Synapse come destinazione di calcolo
Avviare il pool di Spark per Synapse per le attività di data wrangling
Per iniziare la preparazione dei dati con il pool di Apache Spark, specificare il nome dell'ambiente di calcolo Spark per Synapse collegato. È possibile trovare questo nome con lo studio di Azure Machine Learning nella scheda Ambienti di calcolo collegati.
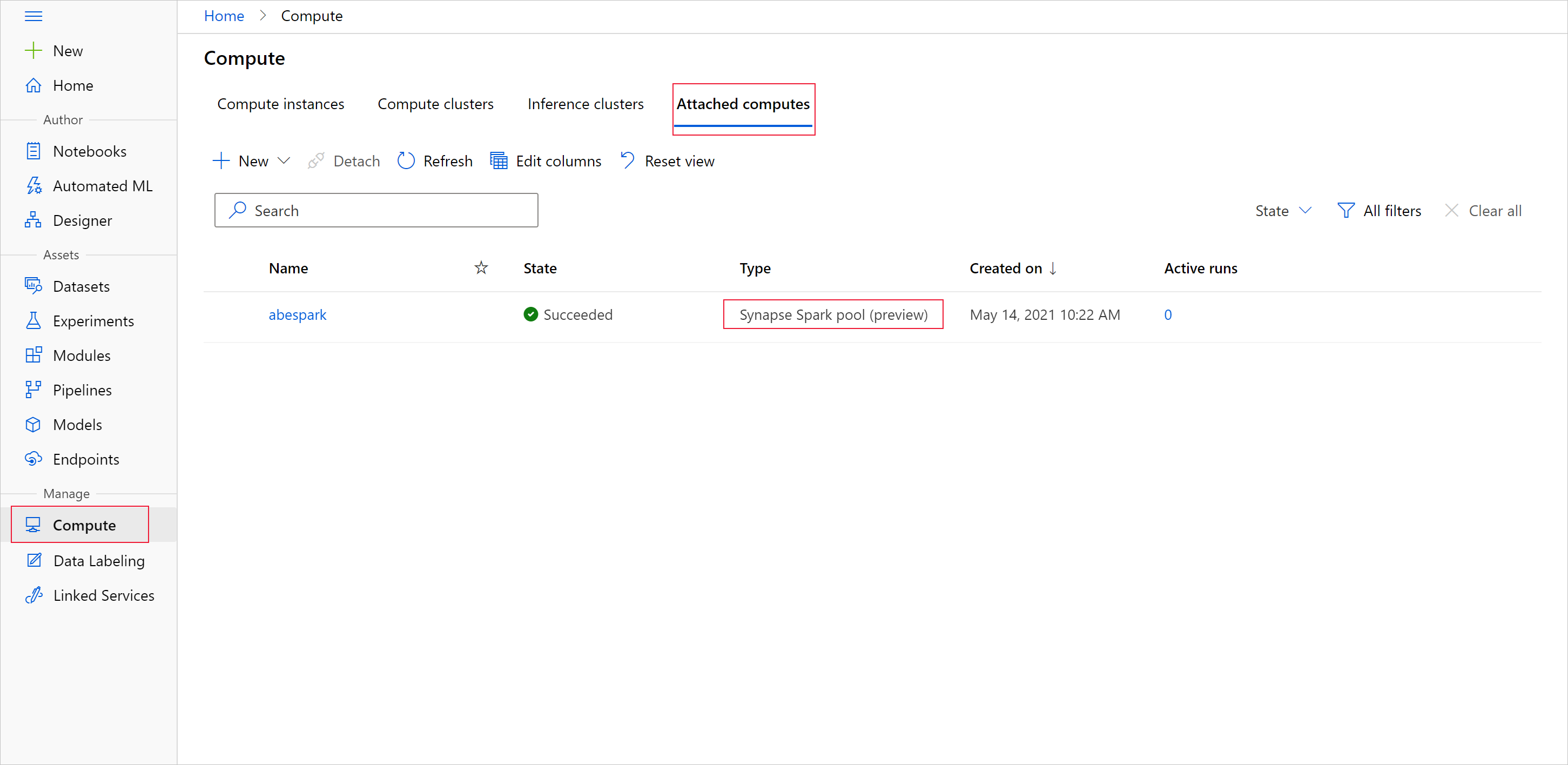
Importante
Per continuare a usare il pool di Apache Spark, è necessario indicare quale risorsa di calcolo usare in tutte le attività di data wrangling. Usare %synapse per singole righe di codice e %%synapse per più righe:
%synapse start -c SynapseSparkPoolAlias
Dopo l'avvio della sessione, è possibile controllare i relativi metadati:
%synapse meta
È possibile specificare un ambiente di Azure Machine Learning da usare durante la sessione di Apache Spark. Verranno applicate solo le dipendenze Conda specificate nell'ambiente. Le immagini Docker non sono supportate.
Avviso
Le dipendenze Python specificate nelle dipendenze Conda dell'ambiente non sono supportate nei pool di Apache Spark. Attualmente sono supportate solo le versioni stabili di Python. Includere sys.version_info nello script per controllare la versione di Python in uso.
Il codice seguente consente di creare la variabile di ambiente myenv, per installare azureml-core versione 1.20.0 e numpy versione 1.17.0 prima dell'avvio della sessione. È quindi possibile includere questo ambiente nell'istruzione start della sessione di Apache Spark.
from azureml.core import Workspace, Environment
# creates environment with numpy and azureml-core dependencies
ws = Workspace.from_config()
env = Environment(name="myenv")
env.python.conda_dependencies.add_pip_package("azureml-core==1.20.0")
env.python.conda_dependencies.add_conda_package("numpy==1.17.0")
env.register(workspace=ws)
Per avviare la preparazione dei dati con il pool di Apache Spark nell'ambiente personalizzato, specificare il nome del pool di Apache Spark e l'ambiente da usare durante la sessione di Apache Spark. È possibile specificare l'ID sottoscrizione, nonché il gruppo di risorse e il nome dell'area di lavoro di Machine Learning.
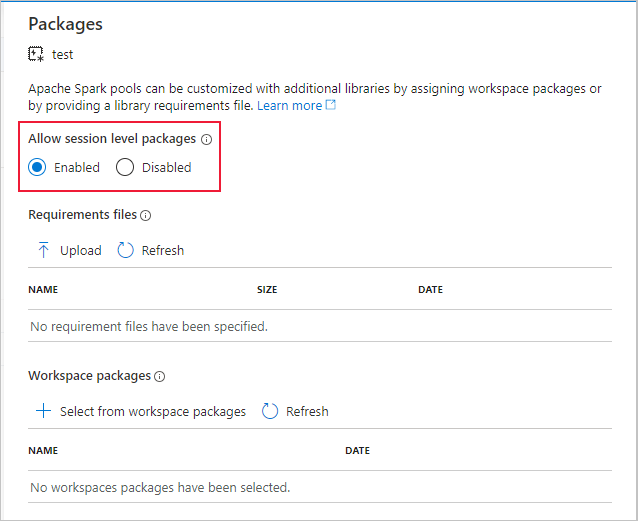
Importante
Assicurarsi di abilitare l'opzione Consenti pacchetti a livello di sessione nell'area di lavoro di Synapse collegata.
%synapse start -c SynapseSparkPoolAlias -e myenv -s AzureMLworkspaceSubscriptionID -r AzureMLworkspaceResourceGroupName -w AzureMLworkspaceName
Caricare dati dall'archiviazione
Dopo l'avvio della sessione di Apache Spark, trasferire i dati da preparare. Il caricamento dei dati è supportato per Archiviazione BLOB di Azure e Azure Data Lake Storage Gen1 e Gen2.
Sono disponibili due opzioni per caricare dati da questi servizi di archiviazione:
Caricare direttamente i dati dall'archiviazione con il relativo percorso HDFS (Hadoop Distributed Files System).
Trasferire i dati da un set di dati di Azure Machine Learning esistente
Per accedere a questi servizi di archiviazione, è necessario avere le autorizzazioni di Ruolo con autorizzazioni di lettura per i dati dei BLOB di archiviazione. Per eseguire il writeback dei dati in questi servizi di archiviazione, è necessario avere le autorizzazioni di Collaboratore ai dati dei BLOB di archiviazione. Altre informazioni su autorizzazioni e ruoli di archiviazione.
Caricare i dati con il percorso HDFS (Hadoop Distributed Files System)
Per caricare e trasferire i dati dall'archiviazione con il percorso HDFS corrispondente, è necessario che siano disponibili le credenziali di autenticazione per l'accesso ai dati. Queste credenziali variano a seconda del tipo di archiviazione. Nell'esempio di codice seguente viene illustrato come trasferire i dati da un'istanza di Archiviazione BLOB di Azure in un dataframe Spark con il token di firma di accesso condiviso o la chiave di accesso:
%%synapse
# setup access key or SAS token
sc._jsc.hadoopConfiguration().set("fs.azure.account.key.<storage account name>.blob.core.windows.net", "<access key>")
sc._jsc.hadoopConfiguration().set("fs.azure.sas.<container name>.<storage account name>.blob.core.windows.net", "<sas token>")
# read from blob
df = spark.read.option("header", "true").csv("wasbs://demo@dprepdata.blob.core.windows.net/Titanic.csv")
Nell'esempio di codice seguente viene illustrato come trasferire i dati da Azure Data Lake Storage Gen1 (ADLS Gen1) con le credenziali dell'entità servizio:
%%synapse
# setup service principal which has access of the data
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.access.token.provider.type","ClientCredential")
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.client.id", "<client id>")
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.credential", "<client secret>")
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.refresh.url",
"https://login.microsoftonline.com/<tenant id>/oauth2/token")
df = spark.read.csv("adl://<storage account name>.azuredatalakestore.net/<path>")
Nell'esempio di codice seguente viene illustrato come trasferire i dati da Azure Data Lake Storage Gen2 (ADLS Gen2) con le credenziali dell'entità servizio:
%%synapse
# setup service principal which has access of the data
sc._jsc.hadoopConfiguration().set("fs.azure.account.auth.type.<storage account name>.dfs.core.windows.net","OAuth")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth.provider.type.<storage account name>.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.id.<storage account name>.dfs.core.windows.net", "<client id>")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.secret.<storage account name>.dfs.core.windows.net", "<client secret>")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.endpoint.<storage account name>.dfs.core.windows.net",
"https://login.microsoftonline.com/<tenant id>/oauth2/token")
df = spark.read.csv("abfss://<container name>@<storage account>.dfs.core.windows.net/<path>")
Trasferire i dati da set di dati registrati
È anche possibile inserire un set di dati registrato esistente nell'area di lavoro e convertirlo in un dataframe Spark per eseguire la preparazione dei dati. In questo esempio viene eseguita l'autenticazione nell'area di lavoro, viene ottenuto un oggetto TabularDataset registrato blob_dset che fa riferimento ai file nell'archiviazione BLOB e viene eseguita la conversione di TabularDataset in un dataframe Spark. Quando i set di dati vengono convertiti in dataframe Spark, è possibile usare le librerie di pyspark per l'esplorazione e la preparazione dei dati.
%%synapse
from azureml.core import Workspace, Dataset
subscription_id = "<enter your subscription ID>"
resource_group = "<enter your resource group>"
workspace_name = "<enter your workspace name>"
ws = Workspace(workspace_name = workspace_name,
subscription_id = subscription_id,
resource_group = resource_group)
dset = Dataset.get_by_name(ws, "blob_dset")
spark_df = dset.to_spark_dataframe()
Eseguire attività di data wrangling
Dopo aver recuperato ed esaminato i dati, è possibile eseguire attività di data wrangling. Questo esempio di codice amplia l'esempio relativo ad HDFS della sezione precedente. Partendo dalla colonna Survived filtra i dati nel dataframe Spark df e raggruppa tale elenco in base ad Age:
%%synapse
from pyspark.sql.functions import col, desc
df.filter(col('Survived') == 1).groupBy('Age').count().orderBy(desc('count')).show(10)
df.show()
Salvare i dati nell'archiviazione e arrestare la sessione di Spark
Una volta completate le attività di esplorazione e preparazione dei dati, archiviare i dati preparati nell'account di archiviazione in Azure per usarli in un secondo momento. In questo esempio di codice viene eseguito il writeback dei dati preparati in Archiviazione BLOB di Azure, sovrascrivendo il file Titanic.csv originale nella directory training_data. Per eseguire il writeback nell'archiviazione, è necessario avere le autorizzazioni di Collaboratore ai dati dei BLOB di archiviazione. Per altre informazioni, vedere Assegnare un ruolo di Azure per l'accesso ai dati BLOB.
%% synapse
df.write.format("csv").mode("overwrite").save("wasbs://demo@dprepdata.blob.core.windows.net/training_data/Titanic.csv")
Dopo aver completato la preparazione dei dati e salvato i dati preparati nell'archiviazione, usare il comando seguente per terminare l'uso del pool di Apache Spark:
%synapse stop
Creare un set di dati per rappresentare i dati preparati
Quando si è pronti a utilizzare i dati preparati per il training del modello, connettersi all'archiviazione con un archivio dati di Azure Machine Learning e specificare uno o più file da usare con un set di dati di Azure Machine Learning.
Questo esempio di codice:
- Presuppone che sia già stato creato un archivio dati che si connette al servizio di archiviazione in cui sono stati salvati i dati preparati.
- Recupera l'archivio dati esistente
mydatastoredall'area di lavorowscon il metodo get(). - Crea un oggetto FileDataset
train_dsper fare riferimento ai file di dati preparati presenti nella directorymydatastoreditraining_data. - Crea la variabile
input1, che può essere usata in un secondo momento per rendere disponibili i file di dati del set di datitrain_dsin una destinazione di calcolo per le attività di training.
from azureml.core import Datastore, Dataset
datastore = Datastore.get(ws, datastore_name='mydatastore')
datastore_paths = [(datastore, '/training_data/')]
train_ds = Dataset.File.from_files(path=datastore_paths, validate=True)
input1 = train_ds.as_mount()
Usare un oggetto ScriptRunConfig per inviare un'esecuzione dell'esperimento a un pool di Spark per Synapse
Se si è pronti ad automatizzare e preparare per la produzione le attività di data wrangling, è possibile usare l'oggetto ScriptRunConfig per inviare un'esecuzione dell'esperimento a un pool di Spark per Synapse collegato. Analogamente, se si ha una pipeline di Azure Machine Learning, è possibile usare SynapseSparkStep per specificare il pool di Spark per Synapse come destinazione di calcolo per il passaggio di preparazione dei dati nella pipeline. La disponibilità dei dati nel pool di Spark per Synapse dipende dal tipo di set di dati.
- Per un oggetto FileDataset è possibile usare il metodo
as_hdfs(). Quando si invia l'esecuzione, il set di dati viene reso disponibile per il pool di Spark per Synapse come HFDS (Hadoop Distributed File System) - Per un oggetto TabularDataset è possibile usare il metodo
as_named_input()
L'esempio di codice seguente:
- Crea la variabile
input2dall'oggetto FileDatasettrain_dscreato nell'esempio di codice precedente - Crea la variabile
outputcon la classeHDFSOutputDatasetConfiguration. Al termine dell'esecuzione, questa classe consente di salvarne l'output come set di datitestnell'archivio datimydatastore. Nell'area di lavoro di Azure Machine Learning il set di datitestviene registrato con il nomeregistered_dataset - Configura le impostazioni da usare per l'esecuzione nel pool di Spark per Synapse
- Definisce i parametri di ScriptRunConfig per:
- Usare lo script
dataprep.pyper l'esecuzione - Specificare i dati da usare come input e come renderli disponibili per il pool di Spark per Synapse
- Specificare dove archiviare i dati di output di
output
- Usare lo script
from azureml.core import Dataset, HDFSOutputDatasetConfig
from azureml.core.environment import CondaDependencies
from azureml.core import RunConfiguration
from azureml.core import ScriptRunConfig
from azureml.core import Experiment
input2 = train_ds.as_hdfs()
output = HDFSOutputDatasetConfig(destination=(datastore, "test").register_on_complete(name="registered_dataset")
run_config = RunConfiguration(framework="pyspark")
run_config.target = synapse_compute_name
run_config.spark.configuration["spark.driver.memory"] = "1g"
run_config.spark.configuration["spark.driver.cores"] = 2
run_config.spark.configuration["spark.executor.memory"] = "1g"
run_config.spark.configuration["spark.executor.cores"] = 1
run_config.spark.configuration["spark.executor.instances"] = 1
conda_dep = CondaDependencies()
conda_dep.add_pip_package("azureml-core==1.20.0")
run_config.environment.python.conda_dependencies = conda_dep
script_run_config = ScriptRunConfig(source_directory = './code',
script= 'dataprep.py',
arguments = ["--file_input", input2,
"--output_dir", output],
run_config = run_config)
Per altre informazioni su run_config.spark.configuration e sulla configurazione di Spark in generale, vedere l'articolo sulla classe SparkConfiguration e la documentazione sulla configurazione di Apache Spark.
Dopo aver configurato l'oggetto ScriptRunConfig, è possibile inviare l'esecuzione.
from azureml.core import Experiment
exp = Experiment(workspace=ws, name="synapse-spark")
run = exp.submit(config=script_run_config)
run
Per altre informazioni, tra cui quelle relative allo script dataprep.py usato in questo esempio, vedere il notebook di esempio.
Dopo aver preparato i dati, è possibile usarli come input per i processi di training. Nell'esempio di codice precedente si specifica registered_dataset come dati di input per i processi di training.
Notebook di esempio
Vedere questi notebook di esempio per altri concetti e dimostrazioni delle funzionalità di integrazione di Azure Synapse Analytics e Azure Machine Learning.
- Eseguire una sessione di Spark interattiva da un notebook nell'area di lavoro di Azure Machine Learning.
- Inviare l'esecuzione di un esperimento di Azure Machine Learning con un pool di Spark per Synapse come destinazione di calcolo.
Passaggi successivi
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per