Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
In questa guida introduttiva si userà la procedura guidata Importa e vettorializza i dati nel portale di Azure per iniziare con la ricerca multimodale. La procedura guidata semplifica il processo di estrazione, suddivisione in blocchi, vettorizzazione e caricamento di testo e immagini in un indice ricercabile.
A differenza di Avvio rapido: La ricerca vettoriale nel portale di Azure, che elabora immagini semplici contenenti testo, questo avvio rapido supporta l'elaborazione avanzata delle immagini per scenari RAG multimodali.
Questo avvio rapido usa un PDF multimodale dal repository azure-search-sample-data. Tuttavia, è possibile usare file diversi e completare comunque questa guida introduttiva.
Prerequisiti
Un account Azure con una sottoscrizione attiva. Creare un account gratuito.
Un servizio ricerca di intelligenza artificiale di Azure. È consigliabile usare il livello Basic o superiore.
Un account di archiviazione di Azure. Usare Archiviazione BLOB di Azure o Azure Data Lake Storage Gen2 (account di archiviazione con uno spazio dei nomi gerarchico) in un account con prestazioni standard (utilizzo generico v2). I livelli di accesso possono essere frequenti, rari o freddi.
Metodo di estrazione supportato.
Metodo di incorporamento supportato.
Familiarità con la procedura guidata. Consulta le procedure guidate per l'importazione dati nel portale di Azure.
Metodi di estrazione supportati
Per l'estrazione di contenuto, è possibile scegliere l'estrazione predefinita tramite Ricerca di intelligenza artificiale di Azure o l'estrazione avanzata tramite Intelligence per i documenti di Intelligenza artificiale di Azure. Nella tabella seguente vengono descritti entrambi i metodi di estrazione.
| Metodo | Descrizione |
|---|---|
| Estrazione predefinita | Estrae solo i metadati della posizione dalle immagini PDF. Non richiede un'altra risorsa di Intelligenza artificiale di Azure. |
| Estrazione avanzata | Estrae i metadati della posizione dal testo e dalle immagini per più tipi di documento. Richiede una risorsa multiservizio dei Servizi di Intelligenza Artificiale di Azure1 in un'area supportata. |
1 Ai fini della fatturazione, è necessario collegare la risorsa multiservizio di Intelligenza artificiale di Azure al set di competenze nel servizio Ricerca intelligenza artificiale di Azure. A meno che non si usi una connessione senza chiave per creare il set di competenze, entrambe le risorse devono trovarsi nella stessa area.
Metodi di incorporamento supportati
Per l'incorporamento del contenuto, è possibile scegliere la descrizione verbale dell'immagine (seguita da vettorizzazione del testo) o incorporamenti multimodali. Le istruzioni di distribuzione per i modelli vengono fornite in una sezione successiva. Nella tabella seguente vengono descritti entrambi i metodi di incorporamento.
| Metodo | Descrizione | Modelli supportati |
|---|---|---|
| Verbalizzazione delle immagini | Usa un LLM per generare descrizioni in linguaggio naturale delle immagini e quindi usa un modello di incorporamento per vettorizzare testo normale e immagini verbalizzate. Richiede una risorsa OpenAI di Azure1, 2 o un progetto Azure AI Foundry. Per la vettorizzazione del testo, è anche possibile usare una risorsa multiservizio di Servizi di intelligenza artificiale di Azure3 in un'area supportata. |
LLMs: GPT-4o GPT-4o-mini phi-4 4 Incorporamento di modelli: text-embedding-ada-002 text-embedding-3-small text-embedding-3-large |
| Incorporamenti multimodali | Usa un modello di incorporamento per vettorizzare direttamente sia testo che immagini. Richiede un progetto di Azure AI Foundry o una risorsa multiservizio di servizi Azure AI3 in un'area supportata. |
Cohere-embed-v3-english Cohere-embed-v3-multilingual |
1 L'endpoint della risorsa OpenAI di Azure deve avere un sottodominio personalizzato, ad esempio https://my-unique-name.openai.azure.com. Se la risorsa è stata creata nel portale di Azure, questo sottodominio viene generato automaticamente durante l'installazione delle risorse.
2 Le risorse OpenAI di Azure (con accesso ai modelli di incorporamento) create nel portale di Azure AI Foundry non sono supportate. È necessario creare una risorsa OpenAI di Azure nel portale di Azure.
3 Ai fini della fatturazione, è necessario collegare la risorsa multiservizio di Intelligenza artificiale di Azure al set di competenze nel servizio Ricerca intelligenza artificiale di Azure. A meno che non si usi una connessione senza chiave (anteprima) per creare il set di competenze, entrambe le risorse devono trovarsi nella stessa area.
4phi-4 è disponibile solo per i progetti Azure AI Foundry.
Requisiti dell'endpoint pubblico
Tutte le risorse precedenti devono avere l'accesso pubblico abilitato in modo che i nodi portale di Azure possano accedervi. In caso contrario, la procedura guidata ha esito negativo. Dopo l'esecuzione della procedura guidata, è possibile abilitare i firewall e gli endpoint privati nei componenti di integrazione per la sicurezza. Per altre informazioni, vedere Proteggere le connessioni nelle procedure guidate di importazione.
Se gli endpoint privati sono già presenti e non è possibile disabilitarli, l'alternativa consiste nell'eseguire il rispettivo flusso end-to-end da uno script o programma in una macchina virtuale. La macchina virtuale deve appartenere alla stessa rete virtuale dell’endpoint privato. Di seguito è riportato un esempio di codice Python per la vettorizzazione integrata. Nello stesso Archivio GitHub sono disponibili esempi in altri linguaggi di programmazione.
Verificare lo spazio
Se si inizia con il servizio gratuito, sono limitati a tre indici, tre origini dati, tre set di competenze e tre indicizzatori. Assicurarsi di avere spazio per gli elementi aggiuntivi prima di iniziare, Questo avvio rapido crea uno di ogni oggetto.
Configurare l'accesso
Prima di iniziare, assicurarsi di disporre delle autorizzazioni per accedere al contenuto e alle operazioni. Per l'autorizzazione, è consigliabile usare l'autenticazione e l'accesso basato sui ruoli di Microsoft Entra ID. Per assegnare i ruoli, è necessario essere proprietario o amministratore accesso utenti . Se i ruoli non sono fattibili, è possibile usare invece l'autenticazione basata su chiave .
Configurare i ruoli obbligatori e i ruoli condizionali identificati in questa sezione.
Ruoli richiesti
Ricerca di intelligenza artificiale di Azure e Archiviazione di Azure sono necessari per tutti gli scenari di ricerca multifunzionali.
Ricerca AI di Azure fornisce la pipeline multimodale. Configurare l'accesso per se stessi e il servizio di ricerca per leggere i dati, eseguire la pipeline e interagire con altre risorse di Azure.
Nel servizio Ricerca intelligenza artificiale di Azure:
Assegnare i ruoli seguenti a se stessi:
Collaboratore servizi di ricerca
Collaboratore ai dati dell'indice di ricerca
Lettore di dati dell'indice di ricerca
Ruoli condizionali
Le schede seguenti illustrano tutte le risorse compatibili con la procedura guidata per la ricerca bidirezionale. Selezionare solo le schede che si applicano al metodo di estrazione scelto e al metodo di incorporamento.
Azure OpenAI fornisce moduli LLM per la verbalizzazione delle immagini e i modelli di incorporamento per la vettorializzazione di testo e immagine. Il servizio di ricerca richiede l'accesso per chiamare la competenza GenAI Prompt e la competenza di incorporamento di Azure OpenAI.
Nella risorsa OpenAI di Azure:
- Assegna l'utente di Servizi cognitivi OpenAI all'identità del servizio di ricerca.
Preparare i dati di esempio
In questa guida rapida viene utilizzato un file PDF di esempio, ma è anche possibile utilizzare i propri file. Se si usa un servizio di ricerca gratuito, usare meno di 20 file per rimanere entro la quota gratuita per l'elaborazione dell'arricchimento dei dati.
Per preparare i dati di esempio per questa guida introduttiva:
Accedere al portale di Azure e selezionare l'account di archiviazione di Azure.
Nel riquadro sinistro selezionareContenitori>.
Creare un contenitore e quindi caricare il PDF di esempio nel contenitore.
Creare un altro contenitore per archiviare le immagini estratte dal PDF.
Distribuire modelli
La procedura guidata offre diverse opzioni per l'integrazione dei contenuti. La verbalizzazione delle immagini richiede un LLM per descrivere le immagini e un modello di incorporamento per vettorizzare il contenuto di testo e immagine, mentre gli incorporamenti multimodali diretti richiedono solo un modello di incorporamento. Questi modelli sono disponibili tramite Azure OpenAI e Azure AI Foundry.
Annotazioni
Se si usa Visione artificiale di Azure, ignorare questo passaggio. Gli incorporamenti multimodali sono integrati nella tua risorsa multiservizio di Intelligenza Artificiale di Azure e non richiedono la distribuzione del modello.
Per distribuire i modelli per questa guida introduttiva:
Accedere al portale di Azure AI Foundry.
Selezionare la risorsa OpenAI di Azure o il progetto Azure AI Foundry.
Nel riquadro sinistro selezionare Catalogo modelli.
Distribuire i modelli necessari per il metodo di incorporamento scelto.
Avviare la procedura guidata
Per avviare la procedura guidata per la ricerca multimodale:
Accedere al portale di Azure e selezionare il servizio Ricerca intelligenza artificiale di Azure.
Nella pagina Panoramica selezionare Importa e vettorizza dati.

Seleziona la tua origine dati: Azure Blob Storage o Azure Data Lake Storage Gen2.

Selezionare RAG multimodale.



Connettersi ai dati
Ricerca di intelligenza artificiale di Azure richiede una connessione a un'origine dati per l'inserimento e l'indicizzazione del contenuto. In questo caso, l'origine dati è l'account di archiviazione di Azure.
Per connettersi ai dati:
Nella pagina Connetti ai dati specificare la sottoscrizione di Azure.
Selezionare l'account di archiviazione e il contenitore in cui sono stati caricati i dati di esempio.
Selezionare la casella di controllo Autentica con identità gestita . Lasciare il tipo di identità assegnato dal sistema.
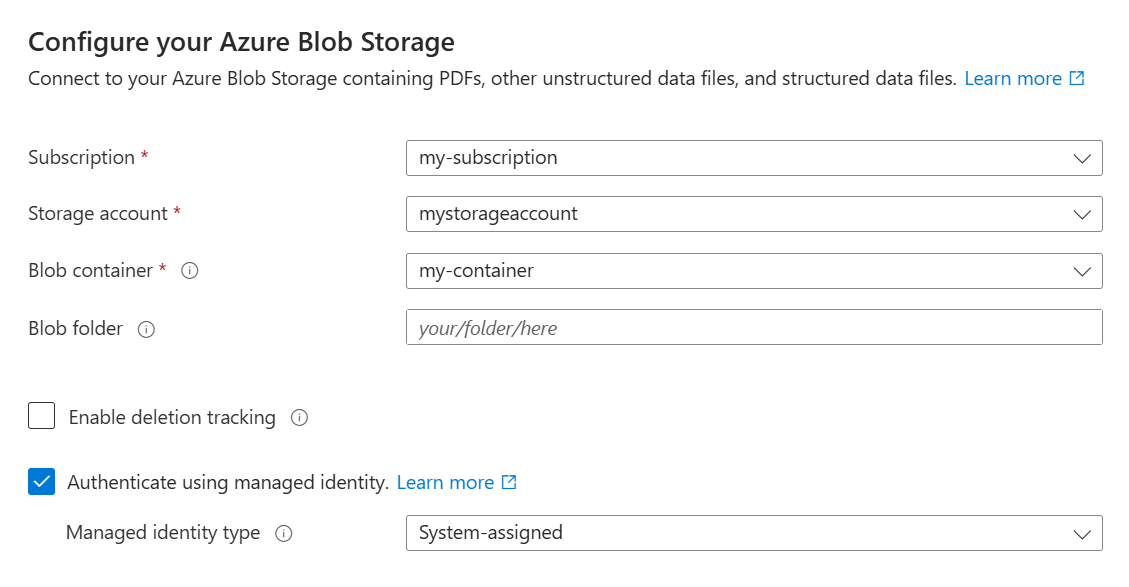
Selezionare Avanti.

Estrai il tuo contenuto
A seconda del metodo di estrazione scelto, la procedura guidata fornisce opzioni di configurazione per la creazione di documenti e la suddivisione in blocchi.
Il metodo predefinito chiama la competenza Estrazione documenti per estrarre il contenuto di testo e generare immagini normalizzate dai documenti. Viene quindi chiamata l'abilità Text Split per suddividere il contenuto di testo estratto in pagine.
Per usare la competenza Estrazione documenti:
Nella pagina Estrazione contenuto selezionare Predefinito.
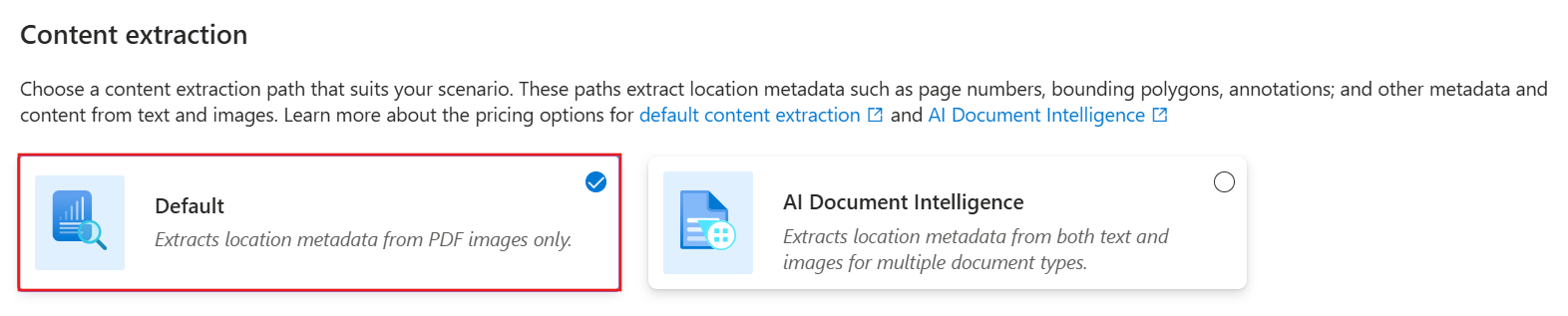
Selezionare Avanti.



Incorporare il contenuto
Durante questo passaggio, la procedura guidata usa il metodo di incorporamento scelto per generare rappresentazioni vettoriali di testo e immagini.
L'assistente chiama un'abilità per creare testo descrittivo per le immagini (verbalizzazione delle immagini) e un'altra abilità per creare rappresentazioni vettoriali per testo e immagini.
Per la verbalizzazione delle immagini, la funzionalità Prompt GenAI utilizza il tuo LLM distribuito per analizzare ogni immagine estratta e produrre una descrizione in linguaggio naturale.
Per gli embedding, la skill di embedding di Azure OpenAI, skill AML o la skill di embedding multimodale di Azure AI Vision usa il tuo modello di embedding distribuito per convertire blocchi di testo e descrizioni verbalizzate in vettori altamente dimensionali. Questi vettori consentono la somiglianza e il recupero ibrido.
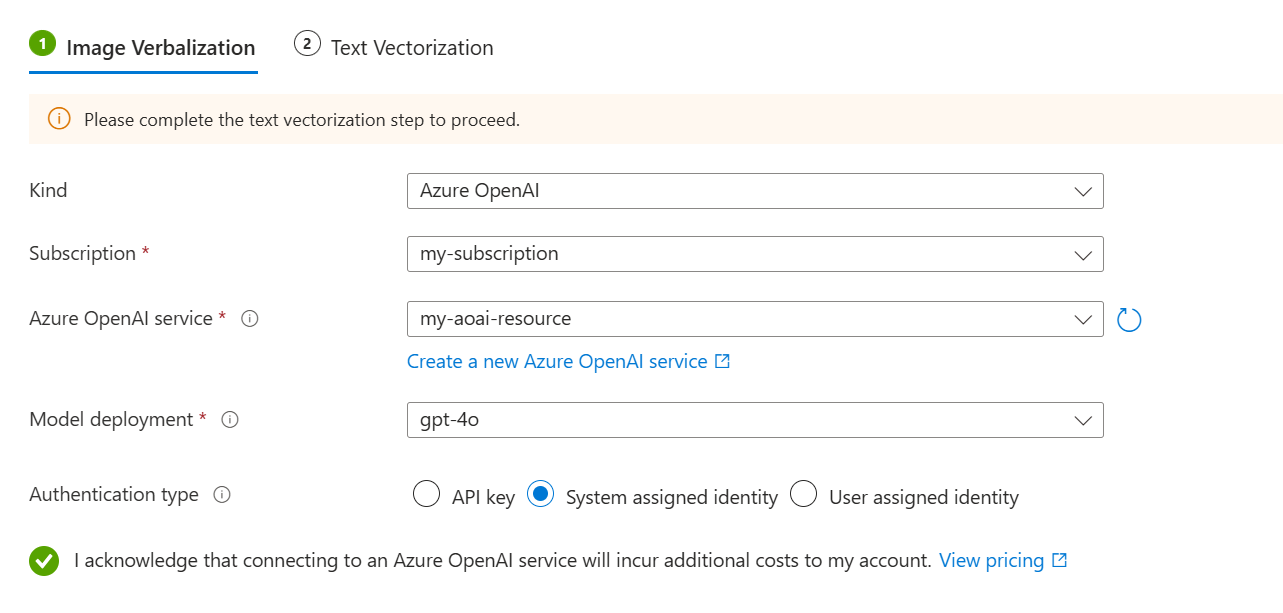
Per usare le competenze per la verbalizzazione delle immagini:
Nella pagina Incorporamento del contenuto, seleziona Verbalizzazione immagine.

Nella scheda Image Verbalization (Verbalizzazione immagine ):
Per selezionare il tipo, scegli il tuo fornitore di LLM: Azure OpenAI o i modelli del catalogo di AI Foundry Hub.
Specificare la sottoscrizione, la risorsa e la distribuzione LLM di Azure.
Per il tipo di autenticazione selezionare Identità assegnata dal sistema.
Selezionare la casella di controllo che riconosce gli effetti di fatturazione dell'uso di queste risorse.
Nella scheda Vettorializzazione testo :
Per il tipo, selezionare il provider di modelli: Azure OpenAI, i modelli di catalogo dell'hub di AI Foundry o la vettorizzazione di Visione artificiale.
Specificare l'abbonamento, la risorsa e la distribuzione del modello di embedding di Azure.
Per il tipo di autenticazione selezionare Identità assegnata dal sistema.
Selezionare la casella di controllo che riconosce gli effetti di fatturazione dell'uso di queste risorse.
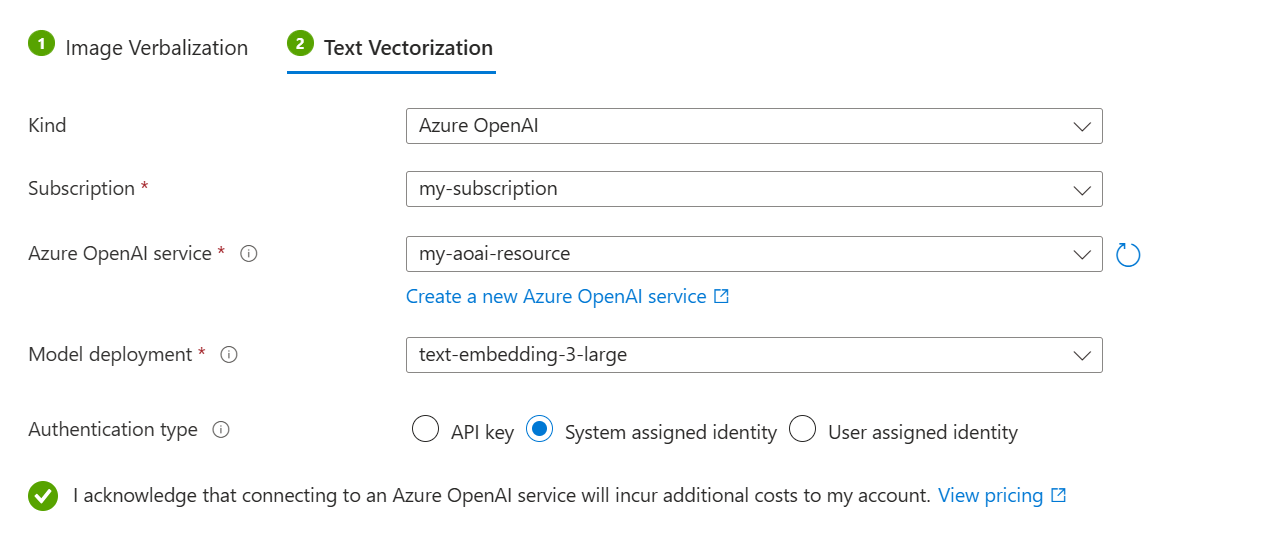
Selezionare Avanti.





Archiviare le immagini estratte
Il passaggio successivo consiste nell'inviare immagini estratte dai documenti ad Archiviazione di Azure. In Ricerca di intelligenza artificiale di Azure questa risorsa di archiviazione secondaria è nota come archivio conoscenze.
Per archiviare le immagini estratte:
Nella pagina Output immagine specificare la sottoscrizione di Azure.
Selezionare l'account di archiviazione e il contenitore blob creati per archiviare le immagini.
Selezionare la casella di controllo Autentica con identità gestita . Lasciare il tipo di identità assegnato dal sistema.
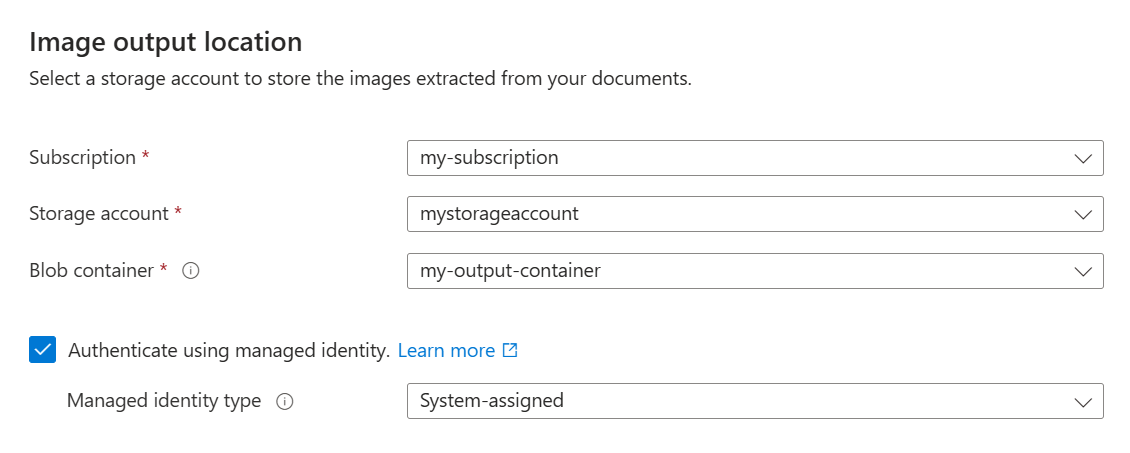
Selezionare Avanti.

Eseguire il mapping di nuovi campi
Nella pagina Impostazioni avanzate è possibile aggiungere facoltativamente campi allo schema dell'indice. Per impostazione predefinita, la procedura guidata genera i campi descritti nella tabella seguente.
| Campo | Si applica a | Descrizione | Attributi |
|---|---|---|---|
| ID contenuto | Vettori di testo e immagine | Campo stringa. Chiave del documento per l'indice. | Recuperabile, ordinabile e ricercabile. |
| titolo_del_documento | Vettori di testo e immagine | Campo stringa. Titolo di un documento leggibile all'uomo. | Recuperabile e ricercabile. |
| id_documento_testo | Vettori di testo | Campo stringa. Identifica il documento padre da cui ha origine il blocco di testo. | Recuperabile e filtrabile. |
| id_documento_immagine | Vettori di immagine | Campo stringa. Identifica il documento padre da cui ha origine l'immagine. | Recuperabile e filtrabile. |
| [Testo_contenuto] | Vettori di testo | Campo stringa. Versione leggibile del blocco di testo. | Recuperabile e ricercabile. |
| incorporazione del contenuto | Vettori di testo e immagine | Collection(Edm.Single). Rappresentazione vettoriale di testo e immagini. | Recuperabile e ricercabile. |
| percorso_contenuto | Vettori di testo e immagine | Campo stringa. Percorso del contenuto nel contenitore di archiviazione. | Recuperabile e ricercabile. |
| metadati sulla posizione | Vettori di immagine | Edm.ComplexType. Contiene i metadati relativi alla posizione dell'immagine nei documenti. | Varia in base al campo. |
Non è possibile modificare i campi generati o i relativi attributi, ma è possibile aggiungere campi se l'origine dati li fornisce. Ad esempio, Archiviazione BLOB di Azure fornisce una raccolta di campi di metadati.
Per aggiungere campi allo schema dell'indice:
In Campi indice selezionare Anteprima e modifica.
Seleziona Aggiungi campo.
Selezionare un campo di origine nei campi disponibili, immettere un nome di campo per l'indice e accettare (o eseguire l'override) del tipo di dati predefinito.
Se si vuole ripristinare lo schema nella versione originale, selezionare Reimposta.
Pianificare l'indicizzazione
Per le origini dati in cui i dati sottostanti sono volatili, è possibile pianificare l'indicizzazione per acquisire le modifiche a intervalli specifici o date e ore specifiche.
Per pianificare l'indicizzazione:
Nella pagina Impostazioni avanzate , in Pianificazione dell'indicizzazione, specificare una pianificazione di esecuzione per l'indicizzatore. Raccomandiamo Once per questa guida introduttiva.

Selezionare Avanti.

Completare la procedura guidata
Il passaggio finale consiste nell'esaminare la configurazione e creare gli oggetti necessari per la ricerca multimodale. Se necessario, tornare alle pagine precedenti della procedura guidata per modificare la configurazione.
Per completare la procedura guidata:
Nella pagina Rivedi e crea specificare un prefisso per gli oggetti creati dalla procedura guidata. Un prefisso comune consente di rimanere organizzati.

Seleziona Crea.

Al termine della configurazione, la procedura guidata crea gli oggetti seguenti:
Indicizzatore che guida la pipeline di indicizzazione.
Connessione all'origine dati a Archiviazione BLOB di Azure.
Indice con campi di testo, campi vettoriali, vettori, profili vettoriali e algoritmi vettoriali. Durante il flusso di lavoro della procedura guidata non è possibile modificare l'indice predefinito. Gli indici sono conformi all'API REST 01-05-2024- anteprima in moda da poter usare le funzionalità di anteprima.
Un set di competenze con le competenze seguenti:
La competenza Estrazione documenti o competenza Layout documento estrae testo e immagini dai documenti di origine. La funzionalità Suddivisione testo accompagna la funzionalità Estrazione documenti per la suddivisione in blocchi di dati, mentre la funzionalità Layout documento ha la suddivisione integrata in blocchi.
La competenza Prompt GenAI verbalizza le immagini in linguaggio naturale. Se stai usando incorporamenti multimodali diretti, questa competenza è assente.
La abilità di Embedding OpenAI di Azure, l'abilità AML o l'abilità di embedding multimodale di Azure AI Vision viene chiamata una volta per la vettorizzazione del testo e una volta per la vettorizzazione delle immagini.
La competenza Shaper arricchisce l'output con i metadati e crea nuove immagini con informazioni contestuali.
Suggerimento
Gli oggetti creati dalla procedura guidata hanno definizioni JSON configurabili. Per visualizzare o modificare queste definizioni, selezionare Gestione ricerche nel riquadro sinistro, in cui è possibile visualizzare gli indici, gli indicizzatori, le origini dati e i set di competenze.
Controllare i risultati
Questa guida introduttiva crea un indice multifunzionale che supporta la ricerca ibrida su testo e immagini. A meno che non si usino incorporamenti multimodali diretti, l'indice non accetta immagini come input di query, il che richiede la competenza AML o la competenza di incorporamenti multimodali di Azure AI Vision con un vettore equivalente. Per altre informazioni, vedere Configurare un vettore in un indice di ricerca.
La ricerca ibrida combina query full-text e query vettoriali. Quando si esegue una query ibrida, il motore di ricerca calcola la somiglianza semantica tra la query e i vettori indicizzati e classifica i risultati di conseguenza. Per l'indice creato in questa guida introduttiva, i risultati offrono contenuti dal campo content_text strettamente allineati alla tua query.
Per interrogare il tuo indice multimodale:
Accedere al portale di Azure e selezionare il servizio Ricerca intelligenza artificiale di Azure.
Nel riquadro sinistro, selezionare Gestione della ricerca>Indici.
Seleziona l'indice.
Selezionare Opzioni query e quindi selezionare Nascondi valori vettoriali nei risultati della ricerca. Questo passaggio rende i risultati più leggibili.
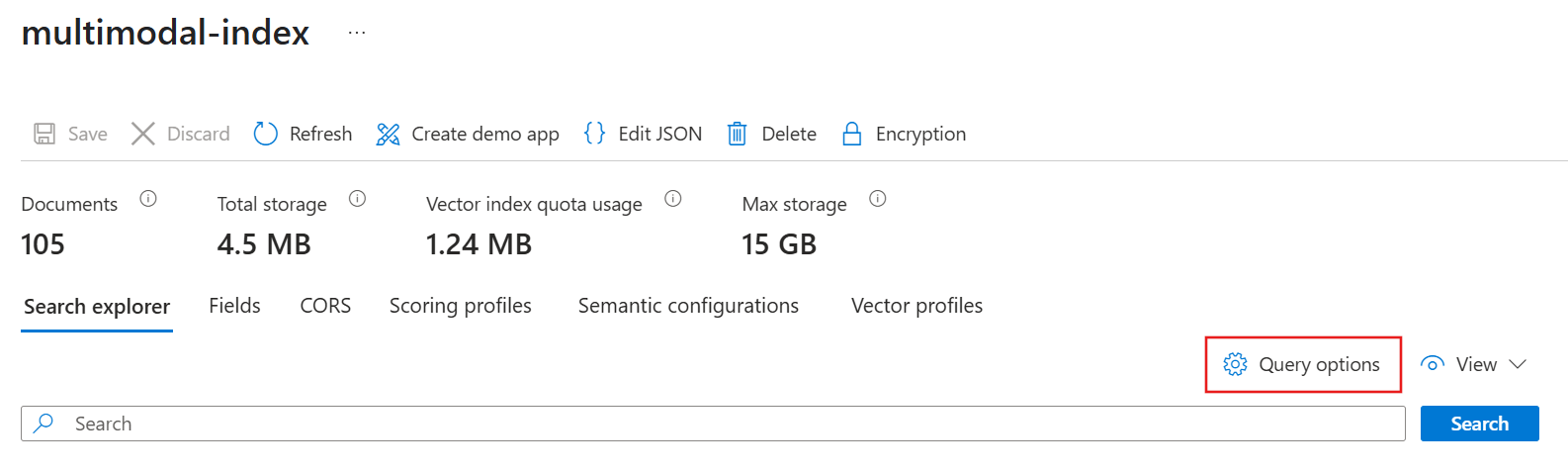
Immettere il testo per il quale si desidera eseguire la ricerca. Il nostro esempio utilizza
energy.Per eseguire la query, selezionare Cerca.

I risultati JSON devono includere il testo e il contenuto dell'immagine correlati all'indice
energy. Se è stato abilitato il ranker semantico, la@search.answersmatrice fornisce risposte semantiche concise e con attendibilità elevata per identificare rapidamente le corrispondenze pertinenti."@search.answers": [ { "key": "a71518188062_aHR0cHM6Ly9oYWlsZXlzdG9yYWdlLmJsb2IuY29yZS53aW5kb3dzLm5ldC9tdWx0aW1vZGFsLXNlYXJjaC9BY2NlbGVyYXRpbmctU3VzdGFpbmFiaWxpdHktd2l0aC1BSS0yMDI1LnBkZg2_normalized_images_7", "text": "A vertical infographic consisting of three sections describing the roles of AI in sustainability: 1. **Measure, predict, and optimize complex systems**: AI facilitates analysis, modeling, and optimization in areas like energy distribution, resource allocation, and environmental monitoring. **Accelerate the development of sustainability solution...", "highlights": "A vertical infographic consisting of three sections describing the roles of AI in sustainability: 1. **Measure, predict, and optimize complex systems**: AI facilitates analysis, modeling, and optimization in areas like<em> energy distribution, </em>resource<em> allocation, </em>and environmental monitoring. **Accelerate the development of sustainability solution...", "score": 0.9950000047683716 }, { "key": "1cb0754930b6_aHR0cHM6Ly9oYWlsZXlzdG9yYWdlLmJsb2IuY29yZS53aW5kb3dzLm5ldC9tdWx0aW1vZGFsLXNlYXJjaC9BY2NlbGVyYXRpbmctU3VzdGFpbmFiaWxpdHktd2l0aC1BSS0yMDI1LnBkZg2_text_sections_5", "text": "...cross-laminated timber.8 Through an agreement with Brookfield, we aim 10.5 gigawatts (GW) of renewable energy to the grid.910.5 GWof new renewable energy capacity to be developed across the United States and Europe.Play 4 Advance AI policy principles and governance for sustainabilityWe advocated for policies that accelerate grid decarbonization", "highlights": "...cross-laminated timber.8 Through an agreement with Brookfield, we aim <em> 10.5 gigawatts (GW) of renewable energy </em>to the<em> grid.910.5 </em>GWof new<em> renewable energy </em>capacity to be developed across the United States and Europe.Play 4 Advance AI policy principles and governance for sustainabilityWe advocated for policies that accelerate grid decarbonization", "score": 0.9890000224113464 }, { "key": "1cb0754930b6_aHR0cHM6Ly9oYWlsZXlzdG9yYWdlLmJsb2IuY29yZS53aW5kb3dzLm5ldC9tdWx0aW1vZGFsLXNlYXJjaC9BY2NlbGVyYXRpbmctU3VzdGFpbmFiaWxpdHktd2l0aC1BSS0yMDI1LnBkZg2_text_sections_50", "text": "ForewordAct... Similarly, we have restored degraded stream ecosystems near our datacenters from Racine, Wisconsin120 to Jakarta, Indonesia.117INNOVATION SPOTLIGHTAI-powered Community Solar MicrogridsDeveloping energy transition programsWe are co-innovating with communities to develop energy transition programs that align their goals with broader s.", "highlights": "ForewordAct... Similarly, we have restored degraded stream ecosystems near our datacenters from Racine, Wisconsin120 to Jakarta, Indonesia.117INNOVATION SPOTLIGHTAI-powered Community<em> Solar MicrogridsDeveloping energy transition programsWe </em>are co-innovating with communities to develop<em> energy transition programs </em>that align their goals with broader s.", "score": 0.9869999885559082 } ]


Pulire le risorse
Questa guida di avvio rapido utilizza risorse Azure fatturabili. Se le risorse non sono più necessarie, eliminarle dalla sottoscrizione per evitare addebiti.
Passaggi successivi
In questa guida introduttiva è stata presentata la procedura guidata Importa e vettorizza dati, che crea tutti gli oggetti necessari per la ricerca multimodale. Per esplorare in dettaglio ogni passaggio, vedere le esercitazioni seguenti:
- Esercitazione: Abilità per l'Estrazione di Documenti e la Verbalizzazione delle Immagini
- Tutorial: Descrizione delle immagini e abilità di gestione del layout del documento
- Esercitazione: embedding multimodali e abilità di estrazione documenti
- Esercitazione: Incorporamenti multimodali e abilità layout del documento