Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
In questo articolo viene illustrata la procedura per definire uno schema per un indice di ricerca ed eseguirne il push in un servizio di ricerca. La creazione di un indice stabilisce le strutture dei dati fisici nel servizio di ricerca. Una volta creato l’indice, caricare l'indice come attività separata.
Prerequisiti
Autorizzazioni di scrittura come collaboratore del servizio di ricerca o amministratore chiave API per l'autenticazione basata su chiave.
Conoscere i dati che si vogliono indicizzare. Un indice di ricerca si basa su contenuto esterno che si desidera rendere ricercabile. Il contenuto ricercabile in un indice viene archiviato come campi. È necessario avere un'idea chiara dei campi di origine che si vogliono rendere ricercabili, recuperabili, filtrabili, facetable e ordinabili in Ricerca di intelligenza artificiale di Azure. Per indicazioni, vedere l'elenco di controllo dello schema.
È inoltre necessario disporre di un campo univoco nei dati di origine che può essere usato come chiave del documento (o ID) nell'indice.
Posizione stabile dell'indice. Lo spostamento di un indice esistente in un servizio di ricerca diverso non è supportato per impostazione predefinita. Rivedere i requisiti dell'applicazione e assicurarsi che il servizio di ricerca esistente (capacità e area) sia sufficiente per le proprie esigenze. Se si usa una dipendenza dai servizi di intelligenza artificiale di Azure o da Azure OpenAI, scegliere un'area che fornisca tutte le risorse necessarie.
Infine, tutti i livelli di servizio hanno limiti di indice sul numero di oggetti che è possibile creare. Ad esempio, se si sta sperimentando il livello Gratuito, è possibile avere solo tre indici in un determinato momento. All'interno dell'indice stesso, esistono limiti sui vettori e limiti di indice sul numero di campi semplici e complessi.
Chiavi documento
La creazione dell'indice di ricerca ha due requisiti: un indice deve avere un nome univoco nel servizio di ricerca e deve avere una chiave del documento. L'attributo booleano key in un campo può essere impostato su true per indicare quale campo fornisce la chiave del documento.
Una chiave del documento è l'identificatore univoco di un documento di ricerca, e un documento di ricerca è una raccolta di campi che descrive esaustivamente un determinato elemento. Ad esempio, se si indicizza un set di dati relativi a un film, un documento di ricerca contiene il titolo, il genere e la durata di un singolo film. I nomi dei film sono univoci in questo set di dati, quindi è possibile usare il nome del film come chiave del documento.
In Ricerca di intelligenza artificiale di Azure, una chiave del documento è una stringa e deve provenire da valori univoci nell'origine dati che fornisce il contenuto da indicizzare. Come regola generale, un servizio di ricerca non genera valori chiave, ma in alcuni scenari, ad esempio l'indicizzatore di tabelle di Azure, sintetizza i valori esistenti per creare una chiave univoca per i documenti indicizzati. Un altro scenario è l'indicizzazione uno-a-molti per i dati in blocchi o partizionati, nel qual caso vengono generate chiavi del documento per ogni blocco.
Durante l'indicizzazione incrementale, in cui viene indicizzato il contenuto nuovo e quello aggiornato, vengono aggiunti documenti in ingresso con nuove chiavi, mentre i documenti in ingresso con chiavi esistenti vengono uniti o sovrascritti, a seconda che i campi di indice siano null o popolati.
I punti importanti sulle chiavi del documento includono:
- La lunghezza massima dei valori in un campo chiave è di 1.024 caratteri.
- È necessario scegliere esattamente un campo di primo livello in ogni indice come campo chiave e deve essere di tipo
Edm.String. - Il valore predefinito dell'attributo
keyè false per i campi semplici e null per i campi complessi.
I campi chiave possono essere usati per cercare i documenti direttamente e aggiornare o eliminare documenti specifici. I valori dei campi chiave vengono gestiti in modo con distinzione tra maiuscole e minuscole durante la ricerca o l'indicizzazione dei documenti. Per informazioni dettagliate, vedere GET Document (REST) e Index Documents (REST).
Elenco di controllo dello schema
Usare questo elenco di controllo per facilitare le decisioni di progettazione per l'indice di ricerca.
Esaminare convenzioni di denominazione in modo che i nomi degli indici e dei campi siano conformi alle regole di denominazione.
Vedere i tipi di dati supportati. Il tipo di dati influisce sulla modalità di utilizzo del campo. Ad esempio, i contenuti numerici sono filtrabile ma non ricercabili come full-text. Il tipo di dati più comune per il testo ricercabile è
Edm.String, che viene tokenizzato e sottoposto a query usando il motore di ricerca full-text. Il tipo di dati più comune per un campo vettoriale èEdm.Singlema è possibile usare anche altri tipi.Specificare una descrizione dell'indice (anteprima), massimo 4.000 caratteri. Questo testo leggibile è prezioso quando un sistema deve accedere a diversi indici e prendere una decisione in base alla descrizione. Si consideri un server MCP (Model Context Protocol) che deve selezionare l'indice corretto in fase di esecuzione. La decisione può essere basata sulla descrizione anziché solo sul nome dell'indice. Un campo di descrizione dell'indice è disponibile nell'API REST 2025-05-01-preview, nel portale di Azure o in un pacchetto non definitivo di Azure SDK che offre tale funzionalità. Per altre informazioni, vedere Aggiungere una descrizione dell'indice.
Identificare una chiave del documento. La chiave di un documento è un requisito di indice. Si tratta di un singolo campo stringa popolato da un campo dati di origine che contiene valori univoci. Ad esempio, se si esegue l'indicizzazione da Archiviazione BLOB, il percorso di archiviazione dei metadati viene spesso usato come chiave del documento perché identifica in modo univoco ogni BLOB del contenitore.
Identificare i campi nell'origine dati che contribuiscono al contenuto ricercabile nell'indice.
Il contenuto nonvettoriale ricercabile include stringhe brevi o lunghe su cui viene eseguita una query tramite il motore di ricerca full-text. Se il contenuto è dettagliato (frasi brevi o blocchi più grandi), provare a usare analizzatori diversi per vedere come viene tokenizzato il testo.
Il contenuto vettoriale ricercabile possono essere immagini o testo (in qualsiasi lingua) che esiste come rappresentazione matematica. È possibile usare tipi di dati ristretti o la compressione vettoriale per ridurre i campi vettoriali.
Gli attributi impostati su campi, ad esempio
retrievableofilterable, determinano sia i comportamenti di ricerca che la rappresentazione fisica dell'indice nel servizio di ricerca. Determinare come attribuire i campi è un processo iterativo per molti sviluppatori. Per velocizzare le iterazioni, iniziare con i dati di esempio in modo da poterli eliminare e ricompilare facilmente.Identificare quali campi di origine possono essere usati come filtri. Il contenuto numerico e i campi di testo breve, in particolare quelli con valori ripetuti, sono scelte valide. Quando si lavora con i filtri, tenere presente quanto illustrato di seguito:
I filtri possono essere usati nelle query vettoriali e non di filtro, ma il filtro stesso viene applicato ai campi leggibili (nonvector) nell'indice.
I campi filtrabili possono essere usati facoltativamente nel riquadro di esplorazione in base a facet.
I campi filtrabili vengono restituiti in ordine arbitrario e non subiscono l'assegnazione dei punteggi di pertinenza, quindi è consigliabile renderli ordinabili anche.
Per i campi vettoriali, specificare una configurazione di ricerca vettoriale e gli algoritmi usati per creare i percorsi di spostamento e riempire lo spazio di incorporamento. Per altre informazioni, vedere Aggiungere campi vettoriali.
I campi vettoriali hanno proprietà aggiuntive che i campi non vettoriali non hanno, ad esempio gli algoritmi da usare e la compressione vettoriale.
I campi vettoriali omettono attributi che non sono utili per i dati vettoriali, ad esempio l'ordinamento, il filtro e il faceting.
Per i campi non vettoriali, determinare se usare l'analizzatore predefinito (
"analyzer": null) o un analizzatore diverso. Gli analizzatori vengono usati per tokenizzare i campi di testo durante l'indicizzazione e l'esecuzione di query.Per le stringhe multilingue, prendere in considerazione un analizzatore della lingua.
Per le stringhe sillabate o per caratteri speciali, prendere in considerazione analizzatori specializzati. Ne è un esempio la parola chiave che gestisce l'intero contenuto di un campo come un token singolo. Questo comportamento è utile per i dati come i codici postali, gli ID e alcuni nomi di prodotto. Per altre informazioni, vedere Ricerca e modelli di termini parziali con caratteri speciali.
Nota
La ricerca full-text viene eseguita su termini che vengono tokenizzati durante l'indicizzazione. Se le query non restituiscono i risultati previsti, verificare la presenza di tokenizzazione per verificare che la stringa che si sta cercando esista effettivamente. È possibile provare diversi analizzatori sulle stringhe per vedere come vengono prodotti i token dei vari analizzatori.
Configurare le definizioni dei campi
L'insieme fields definisce la struttura di un documento di ricerca. Tutti i campi hanno un nome, un tipo di dati e attributi.
L'impostazione di un campo come ricercabile, filtrabile, ordinabile o facetable ha un effetto sulle dimensioni dell'indice e sulle prestazioni delle query. Non impostare gli attributi nei campi a cui non si intende fare riferimento nelle espressioni di query.
Se un campo non è impostato per essere ricercabile, filtrabile, ordinabile o facetable, non è possibile fare riferimento al campo in alcuna espressione di query. Ciò è utile per i campi che non vengono usati nelle query, ma sono necessari nei risultati della ricerca.
Le API REST hanno l'attribuzione predefinita in base ai tipi di dati, che vengono usati anche dalle procedure guidate di importazione nel portale di Azure. Gli SDK di Azure non hanno impostazioni predefinite, ma hanno sottoclassi di campo che incorporano proprietà e comportamenti, ad esempio SearchableField per stringhe e SimpleField per le primitive.
Le attribuzioni di campi predefinite per le API REST sono riepilogate nella tabella seguente.
| Tipo di dati | Ricercabile | Recuperabile | Filtrabile | Con facet | Ordinabile | Archiviato |
|---|---|---|---|---|---|---|
Edm.String |
✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
Collection(Edm.String) |
✅ | ✅ | ✅ | ✅ | ❌ | ✅ |
Edm.Boolean |
❌ | ✅ | ✅ | ✅ | ✅ | ✅ |
Edm.Int32, Edm.Int64, Edm.Double |
❌ | ✅ | ✅ | ✅ | ✅ | ✅ |
Edm.DateTimeOffset |
❌ | ✅ | ✅ | ✅ | ✅ | ✅ |
Edm.GeographyPoint |
✅ | ✅ | ✅ | ❌ | ✅ | ✅ |
Edm.ComplexType |
✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
Collection(Edm.Single) e tutti gli altri tipi di campo vettoriale |
✅ | ✅ oppure ❌ | ❌ | ❌ | ❌ | ✅ |
I campi stringa possono anche essere associati facoltativamente agli analizzatori e alle mappe sinonimiche. I campi di tipo Edm.String filtrabili, ordinabili o facetable possono essere al massimo di 32 kilobyte. Ciò è dovuto al fatto che i valori di tali campi vengono considerati come un singolo termine di ricerca e la lunghezza massima di un termine in Ricerca di intelligenza artificiale di Azure è di 32 kilobyte. Se è necessario archiviare più testo di questo in un singolo campo stringa, è necessario impostare in modo esplicito la proprietà filtrabile, ordinabile e facetable su false nella definizione dell'indice.
I campi vettoriali devono essere associati a dimensioni e profili vettoriali. Di default, il recupero è vero se si aggiunge il campo vettoriale usando la procedura guidata Importa e vettorizza dati nel portale di Azure. Se si usa l'API REST, è falso.
Gli attributi di campo sono descritti nella tabella seguente.
| Attributo | Descrizione |
|---|---|
| nome | Obbligatorio. Imposta il nome del campo, che deve essere univoco all'interno dell'insieme fields dell'indice o del campo padre. |
| tipo | Obbligatorio. Imposta il tipo di dati per il campo. I campi possono essere semplici o complessi. I campi semplici sono di tipi primitivi, ad esempio Edm.String per il testo o Edm.Int32 per i numeri interi.
I campi complessi possono avere campi secondari semplici o complessi. In questo modo è possibile modellare oggetti e matrici di oggetti, che a sua volta consentono di caricare la maggior parte delle strutture di oggetti JSON nell'indice. Per l'elenco completo dei tipi supportati, vedere Tipi di dati supportati. |
| chiave | Obbligatorio. Impostare questo attributo su true per indicare che i valori di un campo identificano in modo univoco i documenti nell'indice. Per informazioni dettagliate, vedere Chiavi del documento in questo articolo. |
| Recuperabile | Indica se il campo può essere restituito in un risultato della ricerca. Impostare questo attributo su false se si vuole usare un campo come filtro, ordinamento o meccanismo di assegnazione dei punteggi, ma non si vuole che il campo sia visibile all'utente finale. Questo attributo deve essere true per i campi chiave e deve essere null per i campi complessi. Questo attributo può essere modificato nei campi esistenti. L'impostazione di recuperabile su true non comporta alcun aumento dei requisiti di archiviazione degli indici. Il valore predefinito è true per i campi semplici e null per i campi complessi. |
| ricercabile | Indica se il campo è ricercabile full-text e può essere fatto riferimento nelle query di ricerca. Ciò significa che viene sottoposta a analisi lessicali, ad esempio word break durante l'indicizzazione. Se si imposta un campo ricercabile su un valore come "Sunny day", internamente viene normalizzato nei singoli token "sunny" e "day". È così possibile eseguire ricerche full-text di questi termini. I campi di tipo Edm.String o Collection(Edm.String) sono disponibili per la ricerca per impostazione predefinita. Questo attributo deve essere false per campi semplici di altri tipi di dati non di stringa e deve essere null per campi complessi.
Un campo ricercabile utilizza spazio aggiuntivo nell'indice perché Ricerca intelligenza artificiale di Azure elabora il contenuto di tali campi e li organizza in strutture di dati ausiliarie per una ricerca con prestazioni elevate. Se si desidera risparmiare spazio nell'indice e non è necessario includere un campo nelle ricerche, impostare searchable su false. Per informazioni dettagliate, vedere Funzionamento della ricerca full-text in Ricerca di intelligenza artificiale di Azure. |
| filtrabile | Indica se abilitare il campo a cui fare riferimento nelle $filter query. Filtrabile differisce dalla modalità di gestione delle stringhe. I campi di tipo Edm.String o Collection(Edm.String) che sono filtrabili non vengono sottoposti ad analisi lessicale, quindi i confronti sono solo per corrispondenze esatte. Ad esempio, se si imposta un campo f di questo tipo su "Sunny day", $filter=f eq 'sunny' non trova corrispondenze, ma $filter=f eq 'Sunny day' lo farà. Questo attributo deve essere null per campi complessi. Il valore predefinito è true per i campi semplici e null per i campi complessi. Per ridurre le dimensioni dell'indice, impostare questo attributo su false per i campi su cui non verrà applicato il filtro. |
| Ordinabile | Indica se abilitare il campo a cui fare riferimento nelle $orderby espressioni. Per impostazione predefinita, Ricerca intelligenza artificiale di Azure ordina i risultati in base al punteggio, ma in molte esperienze gli utenti vogliono ordinare in base ai campi nei documenti. Un campo semplice può essere ordinato solo se è a valore singolo (ha un singolo valore nell'ambito del documento padre).
I campi di raccolta semplici non possono essere ordinabili, perché sono multivalore. Anche i sottocampi semplici di raccolte complesse sono multivalore e pertanto non possono essere ordinati. Questo vale sia se si tratta di un campo padre immediato o di un campo predecessore, che è la raccolta complessa. I campi complessi non possono essere ordinabili e l'attributo ordinabile deve essere null per tali campi. L'impostazione predefinita per l'ordinamento è true per i campi semplici a valore singolo, false per i campi semplici multivalore e null per i campi complessi. |
| facetable | Indica se abilitare il campo a cui fare riferimento nelle query facet. In genere usato in una presentazione dei risultati della ricerca che include il conteggio dei riscontri per categoria (ad esempio, cercare fotocamere digitali e vedere i riscontri per marchio, per impostazione predefinita, per prezzo e così via). Questo attributo deve essere null per campi complessi. I campi di tipo Edm.GeographyPoint o Collection(Edm.GeographyPoint) non possono essere visualizzabili. Il valore predefinito è true per tutti gli altri campi semplici. Per ridurre le dimensioni dell'indice, impostare questo attributo su false nei campi su cui non verrà eseguito il faceting. |
| analizzatore | Imposta l'analizzatore lessicale per la tokenizzazione delle stringhe durante le operazioni di indicizzazione e query. I valori validi per questa proprietà includono analizzatori del linguaggio, analizzatori predefiniti e analizzatori personalizzati. Il valore predefinito è standard.lucene. Questo attributo può essere usato solo con i campi stringa ricercabili e non può essere impostato insieme a searchAnalyzer o indexAnalyzer. Dopo aver scelto l'analizzatore e aver creato il campo nell'indice, non può essere modificato per il campo. Deve essere null per campi complessi. |
| analizzatore di ricerca | Impostare questa proprietà insieme a indexAnalyzer per specificare analizzatori lessicali diversi per l'indicizzazione e le query. Se si usa questa proprietà, impostare analyzer su null e assicurarsi che indexAnalyzer sia impostato su un valore consentito. I valori validi per questa proprietà includono analizzatori predefiniti e analizzatori personalizzati. Questo attributo può essere usato solo con i campi ricercabili. L'analizzatore di ricerca può essere aggiornato in un campo esistente perché viene usato solo in fase di query. Deve essere null per i campi complessi]. |
| analizzatore di indici | Impostare questa proprietà insieme a searchAnalyzer per specificare analizzatori lessicali diversi per l'indicizzazione e le query. Se si usa questa proprietà, impostare analyzer su null e assicurarsi che searchAnalyzer sia impostato su un valore consentito. I valori validi per questa proprietà includono analizzatori predefiniti e analizzatori personalizzati. Questo attributo può essere usato solo con i campi ricercabili. Dopo aver scelto l'analizzatore dell'indice, non può essere modificato per il campo. Deve essere null per campi complessi. |
| mappe di sinonimi | Elenco dei nomi delle mappe sinonimie da associare a questo campo. Questo attributo può essere usato solo con i campi ricercabili. Attualmente è supportata una sola mappa sinonimia per campo. L'assegnazione di una mappa sinonimia a un campo garantisce che i termini di query destinati a tale campo vengano espansi in fase di query usando le regole nella mappa dei sinonimi. Questo attributo può essere modificato nei campi esistenti. Deve essere null o una raccolta vuota per campi complessi. |
| campi | Elenco di sottocampi se si tratta di un campo di tipo Edm.ComplexType o Collection(Edm.ComplexType). Deve essere null o vuoto per i campi semplici. Per altre informazioni su come e quando usare campi secondari, vedere Come modellare tipi di dati complessi in Ricerca di intelligenza artificiale di Azure. |
Creare un indice
Quando si è pronti per creare l'indice, usare un client di ricerca in grado di inviare la richiesta. È possibile usare il portale di Azure o le API REST per lo sviluppo iniziale e il test di verifica, altrimenti è comune usare gli SDK di Azure.
Durante lo sviluppo, pianificare le ricompilazioni frequenti. Poiché nel servizio vengono create strutture fisiche, è necessario eliminare e creare nuovamente gli indici nel caso di molte modifiche. È possibile prendere in considerazione l'uso di un subset di dati per velocizzare le ricompilazioni.
La progettazione dell'indice tramite il portale di Azure applica i requisiti e le regole dello schema per tipi di dati specifici, ad esempio non consentire le funzionalità di ricerca full-text nei campi numerici.
Accedere al portale di Azure.
Verificare lo spazio. I servizi di ricerca sono soggetti al numero massimo di indici, che variano in base al livello di servizio. Assicurarsi di disporre di spazio per un secondo indice.
Nella pagina Panoramica del servizio di ricerca scegliere una delle opzioni per la creazione di un indice di ricerca:
- Aggiungere un indice, un editor incorporato per specificare uno schema di indice
- Importazione guidata
La procedura guidata è un flusso di lavoro dettagliato che crea un indicizzatore, un'origine dati e un indice finito. Carica anche i dati. Se è più di quanto si vuole, usare invece Aggiungi indice.
Lo screenshot seguente evidenzia dove Aggiungi indice, Importa dati e Procedura guidata per importare e vettorizzare dati appaiono sulla barra dei comandi.
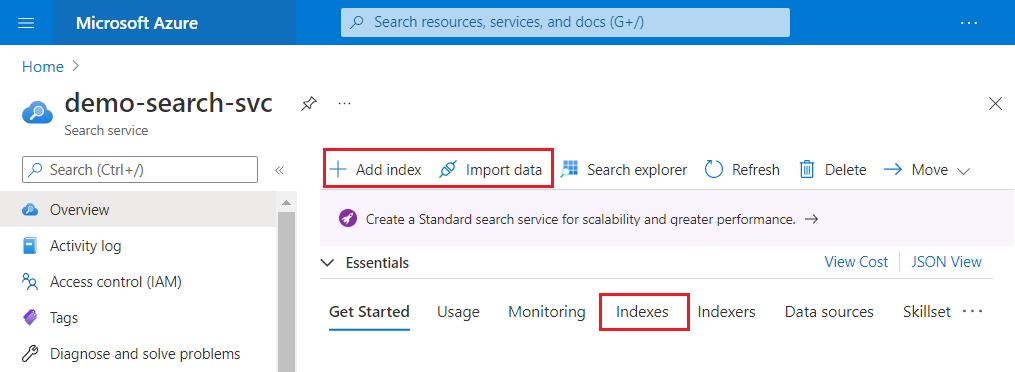
Dopo aver creato un indice, è possibile trovarlo di nuovo nella pagina Indici dal riquadro sinistro.
Suggerimento
Dopo aver creato un indice nella portale di Azure, è possibile copiare la rappresentazione JSON e aggiungerla al codice dell'applicazione.
Impostare corsOptions per le query su più origini
Gli schemi di indice includono una sezione per l'impostazione di corsOptions. Per impostazione predefinita, JavaScript lato client non può chiamare alcuna API perché i browser impediscono tutte le richieste su più origini. Per consentire query con origini diverse nell'indice, abilitare CORS (Cross-Origin Resource Sharing) impostando l'attributo corsOptions. Per motivi di sicurezza, solo le API di query supportano CORS.
"corsOptions": {
"allowedOrigins": [
"*"
],
"maxAgeInSeconds": 300
Per CORS è possibile impostare le proprietà seguenti:
allowedOrigins (obbligatorio): si tratta di un elenco di origini possono accedere all'indice. Il codice JavaScript servito da queste origini è autorizzato a eseguire query sull'indice (presupponendo che il chiamante fornisca una chiave valida o disponga delle autorizzazioni). Ogni origine è in genere nel formato
protocol://<fully-qualified-domain-name>:<port>anche se<port>spesso viene omessa. Per altre informazioni, vedere Utilizzare la condivisione di risorse tra origini (Wikipedia).Per consentire l'accesso a tutte le origini, includere
*come unico elemento nella matriceallowedOrigins. Non si consiglia questa pratica per i servizi di ricerca della produzione ma spesso è utile per lo sviluppo e il debug.maxAgeInSeconds (facoltativo): i browser usano questo valore per determinare la durata (in secondi) di memorizzazione nella cache delle risposte preliminari CORS. Questo valore deve essere un intero non negativo. Un periodo di cache più lungo offre prestazioni migliori, ma estende la quantità di tempo necessaria per rendere effettivo un criterio CORS. Se questo valore non è impostato, viene usata una durata predefinita di cinque minuti.
Aggiornamenti consentiti per gli indici esistenti
Crea indice crea le strutture di dati fisiche (file e indici invertiti) nel servizio di ricerca. Dopo aver creato l'indice, la possibilità di apportare modifiche tramite Crea o Aggiorna indice dipende dal fatto che le modifiche invalidino tali strutture fisiche. La maggior parte degli attributi di campo non può essere modificata dopo la creazione del campo nell'indice.
Per ridurre al minimo la varianza nel codice dell'applicazione, è possibile creare un alias di indice che funge da riferimento stabile all'indice di ricerca. Anziché aggiornare il codice con i nomi degli indici, è possibile aggiornare un alias di indice in modo che punti alle versioni più recenti dell'indice.
Per ridurre al minimo l’abbandono del processo di progettazione, nella tabella seguente vengono descritti gli elementi fissi e quelli flessibili dello schema. La modifica di un elemento fisso richiede una ricompilazione dell'indice, mentre gli elementi flessibili possono essere modificati in qualsiasi momento senza influire sull'implementazione fisica. Per altre informazioni, vedere Aggiornare o ricompilare un indice.
| Elemento | È possibile aggiornare? |
|---|---|
| Nome | NO |
| Chiave | NO |
| Nomi e tipi di campo | NO |
| Attributi di campo (ricercabile, filtrabile, con facet, ordinabile) | NO |
| Attributo di campo (recuperabile) | Sì |
| Archiviato (si applica ai vettori) | NO |
| Analizzatore | È possibile aggiungere e modificare analizzatori personalizzati nell'indice. Per quanto riguarda le assegnazioni di analizzatori nei campi stringa, è possibile modificare solo searchAnalyzer. Tutte le altre assegnazioni e modifiche richiedono una ricompilazione. |
| Profili di punteggio | Sì |
| Componenti per il suggerimento | NO |
| condivisione di risorse tra le origini (CORS) | Sì |
| Crittografia | Sì |
| Mappe sinonimi | Sì |
| Configurazione semantica | Sì |
Passaggi successivi
Usare i collegamenti seguenti per informazioni sulle funzionalità specializzate che possono essere aggiunte a un indice:
- Aggiungere campi vettoriali e profili vettoriali
- Aggiungere profili di punteggio
- Aggiungere una classificazione semantica
- Aggiungere i suggerimenti
- Aggiungere mappe sinonimi
- Aggiungere analizzatori
- Aggiungere la crittografia
Usare questi collegamenti per caricare o aggiornare un indice: