Panoramica della sicurezza per Ricerca di intelligenza artificiale di Azure
Questo articolo descrive le funzionalità di sicurezza di Ricerca intelligenza artificiale di Azure che proteggono i dati e le operazioni.
Flusso di dati (modelli di traffico di rete)
Un servizio di ricerca di intelligenza artificiale di Azure è ospitato in Azure ed è in genere accessibile dalle applicazioni client tramite connessioni di rete pubbliche. Anche se questo modello è predominante, non è l'unico modello di traffico di cui è necessario occuparsi. Comprendere tutti i punti di ingresso e il traffico in uscita è necessario per proteggere gli ambienti di sviluppo e produzione.
Ricerca di intelligenza artificiale di Azure ha tre modelli di traffico di rete di base:
- Richieste in ingresso effettuate da un client al servizio di ricerca (modello predominante)
- Richieste in uscita inviate dal servizio di ricerca ad altri servizi in Azure e altrove
- Richieste interne da servizio a servizio tramite la rete backbone Microsoft sicura
Traffico in ingresso
Le richieste in ingresso destinate a un endpoint del servizio di ricerca includono:
- Creare, leggere, aggiornare o eliminare indici e altri oggetti nel servizio di ricerca
- Caricare un indice con documenti di ricerca
- Eseguire una query su un indice
- Attivare l'esecuzione dell'indicizzatore o del set di competenze
Le API REST descrivono l'intera gamma di richieste in ingresso gestite da un servizio di ricerca.
Come minimo, tutte le richieste in ingresso devono essere autenticate usando una di queste opzioni:
- Autenticazione basata su chiave (impostazione predefinita). Le richieste in ingresso forniscono una chiave API valida.
- Controllo degli accessi in base al ruolo. L'autorizzazione viene eseguita tramite identità e assegnazioni di ruolo di Microsoft Entra nel servizio di ricerca.
Inoltre, è possibile aggiungere funzionalità di sicurezza di rete per limitare ulteriormente l'accesso all'endpoint. È possibile creare regole in ingresso in un firewall IP o creare endpoint privati che proteggono completamente il servizio di ricerca dalla rete Internet pubblica.
Traffico interno
Le richieste interne sono protette e gestite da Microsoft. Non è possibile configurare o controllare queste connessioni. Se si blocca l'accesso alla rete, non è necessaria alcuna azione da parte dell'utente perché il traffico interno non è configurabile dal cliente.
Il traffico interno è costituito da:
- Chiamate da servizio a servizio per attività come l'autenticazione e l'autorizzazione tramite Microsoft Entra ID, registrazione delle risorse inviata a Monitoraggio di Azure e connessioni endpoint private che usano collegamento privato di Azure.
- Richieste effettuate alle API dei servizi di intelligenza artificiale di Azure per competenze predefinite.
- Richieste effettuate ai modelli di Machine Learning che supportano la classificazione semantica.
Traffico in uscita
Le richieste in uscita possono essere protette e gestite dall'utente. Le richieste in uscita provengono da un servizio di ricerca ad altre applicazioni. Queste richieste vengono in genere effettuate dagli indicizzatori per l'indicizzazione basata su testo, l'arricchimento basato sulle competenze di intelligenza artificiale e le vettorizzazioni in fase di query. Le richieste in uscita includono operazioni di lettura e scrittura.
L'elenco seguente è un'enumerazione completa delle richieste in uscita per cui è possibile configurare connessioni sicure. Un servizio di ricerca effettua richieste per proprio conto e per conto di un indicizzatore o di una competenza personalizzata.
| Operazione | Scenario |
|---|---|
| Indicizzatori | Connettersi a origini dati esterne per recuperare i dati. Per altre informazioni, vedere Accesso dell'indicizzatore al contenuto protetto dalla sicurezza di rete di Azure. |
| Indicizzatori | Connettersi a Archiviazione di Azure per rendere persistenti gli archivi conoscenze, gli arricchimenti memorizzati nella cache, le sessioni di debug. |
| Competenze personalizzate | Connettersi alle funzioni di Azure, alle app Web di Azure o ad altre app che eseguono codice esterno ospitato fuori servizio. La richiesta di elaborazione esterna viene inviata durante l'esecuzione del set di competenze. |
| Indicizzatori e vettorizzazione integrata | Connettersi ad Azure OpenAI e a un modello di incorporamento distribuito oppure a una competenza personalizzata per connettersi a un modello di incorporamento fornito. Il servizio di ricerca invia testo ai modelli di incorporamento per la vettorizzazione durante l'indicizzazione. |
| Vettorizzatori | Connettersi ad Azure OpenAI o ad altri modelli di incorporamento in fase di query per convertire le stringhe di testo utente in vettori per la ricerca vettoriale. |
| Servizio di ricerca | Connettersi ad Azure Key Vault per le chiavi di crittografia gestite dal cliente usate per crittografare e decrittografare i dati sensibili. |
Le connessioni in uscita possono essere effettuate usando l'accesso completo di una risorsa stringa di connessione che include una chiave o un account di accesso al database o un'identità gestita se si usa Microsoft Entra ID e accesso basato sui ruoli.
Per raggiungere le risorse di Azure dietro un firewall, creare regole in ingresso in altre risorse di Azure che ammettono le richieste del servizio di ricerca.
Per raggiungere le risorse di Azure protette da collegamento privato di Azure, creare un collegamento privato condiviso usato da un indicizzatore per stabilire la connessione.
Eccezione per i servizi di ricerca e archiviazione nella stessa area
Se Archiviazione di Azure e Ricerca di intelligenza artificiale di Azure si trovano nella stessa area, il traffico di rete viene instradato tramite un indirizzo IP privato e si verifica sulla rete backbone Microsoft. Poiché vengono usati indirizzi IP privati, non è possibile configurare firewall IP o un endpoint privato per la sicurezza di rete.
Configurare le connessioni della stessa area usando uno degli approcci seguenti:
Sicurezza della rete
La sicurezza di rete protegge le risorse da accessi o attacchi non autorizzati applicando controlli al traffico di rete. Ricerca di intelligenza artificiale di Azure supporta le funzionalità di rete che possono essere la prima linea di difesa contro l'accesso non autorizzato.
Connessione in ingresso tramite firewall IP
Viene effettuato il provisioning di un servizio di ricerca con un endpoint pubblico che consente l'accesso usando un indirizzo IP pubblico. Per limitare il traffico proveniente dall'endpoint pubblico, creare una regola del firewall in ingresso che ammette le richieste da un indirizzo IP specifico o da un intervallo di indirizzi IP. Tutte le connessioni client devono essere effettuate tramite un indirizzo IP consentito oppure la connessione viene negata.
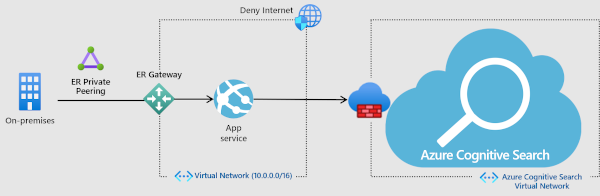
È possibile usare il portale per configurare l'accesso al firewall.
In alternativa, è possibile usare le API REST di gestione. A partire dall'API versione 2020-03-13, con il parametro IpRule , è possibile limitare l'accesso al servizio identificando gli indirizzi IP, singolarmente o in un intervallo, che si vuole concedere l'accesso al servizio di ricerca.
Connessione in ingresso a un endpoint privato (isolamento della rete, nessun traffico Internet)
Per una maggiore sicurezza, è possibile stabilire un endpoint privato per Ricerca intelligenza artificiale di Azure consente a un client in una rete virtuale di accedere in modo sicuro ai dati in un indice di ricerca in un collegamento privato.
L'endpoint privato usa un indirizzo IP dallo spazio di indirizzi della rete virtuale per le connessioni al servizio di ricerca. Il traffico di rete tra il client e il servizio di ricerca attraversa la rete virtuale e un collegamento privato nella rete backbone Microsoft, eliminando l'esposizione dalla rete Internet pubblica. Una rete virtuale consente la comunicazione sicura tra le risorse, con la rete locale e Internet.
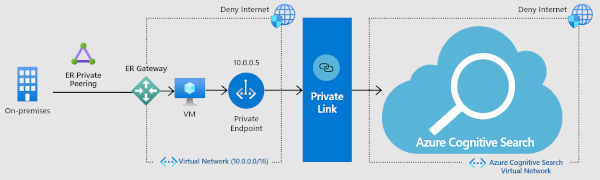
Anche se questa soluzione è la più sicura, l'uso di più servizi è un costo aggiuntivo, quindi assicurarsi di avere una chiara comprensione dei vantaggi prima di immergersi. Per altre informazioni sui costi, vedere la pagina dei prezzi. Per altre informazioni sul funzionamento di questi componenti, guardare questo video. La copertura dell'opzione endpoint privato inizia alle 5:48 nel video. Per istruzioni su come configurare l'endpoint, vedere Creare un endpoint privato per Ricerca di intelligenza artificiale di Azure.
Autenticazione
Una volta ammessa al servizio di ricerca, una richiesta deve comunque essere sottoposta a autenticazione e autorizzazione che determina se la richiesta è consentita. Ricerca di intelligenza artificiale di Azure supporta due approcci:
L'autenticazione di Microsoft Entra stabilisce il chiamante (e non la richiesta) come identità autenticata. Un'assegnazione di ruolo di Azure determina l'autorizzazione.
L'autenticazione basata su chiave viene eseguita sulla richiesta (non sull'app chiamante o sull'utente) tramite una chiave API, in cui la chiave è una stringa composta da numeri e lettere generati in modo casuale che dimostrano che la richiesta proviene da un'origine attendibile. Le chiavi sono necessarie per ogni richiesta. L'invio di una chiave valida è considerato come prova che la richiesta ha origine da un'entità attendibile.
È possibile usare entrambi i metodi di autenticazione o disabilitare un approccio non disponibile nel servizio di ricerca.
Autorizzazione
Ricerca di intelligenza artificiale di Azure offre modelli di autorizzazione per la gestione dei servizi e la gestione dei contenuti.
Autorizzare la gestione dei servizi
La gestione delle risorse è autorizzata tramite il controllo degli accessi in base al ruolo nel tenant di Microsoft Entra.
In Ricerca di intelligenza artificiale di Azure Resource Manager viene usato per creare o eliminare il servizio, gestire le chiavi API, ridimensionare il servizio e configurare la sicurezza. Di conseguenza, le assegnazioni di ruolo di Azure determineranno chi può eseguire tali attività, indipendentemente dal fatto che usino il portale, PowerShell o le API REST di gestione.
Tre ruoli di base (Proprietario, Collaboratore, Lettore) si applicano all'amministrazione del servizio di ricerca. Le assegnazioni di ruolo possono essere effettuate usando qualsiasi metodologia supportata (portale, PowerShell e così via) e vengono rispettate a livello di servizio.
Nota
Usando meccanismi a livello di Azure, è possibile bloccare una sottoscrizione o una risorsa per impedire l'eliminazione accidentale o non autorizzata del servizio di ricerca da parte degli utenti con diritti di amministratore. Per altre informazioni, vedere Bloccare le risorse per impedire l'eliminazione imprevista.
Autorizzare l'accesso al contenuto
La gestione del contenuto fa riferimento agli oggetti creati e ospitati in un servizio di ricerca.
Per l'autorizzazione basata sui ruoli, usare le assegnazioni di ruolo di Azure per stabilire l'accesso in lettura/scrittura alle operazioni.
Per l'autorizzazione basata su chiave, una chiave API e un endpoint qualificato determinano l'accesso. Un endpoint può essere il servizio stesso, l'insieme degli indici, un indice specifico, una raccolta documenti o un documento specifico. In caso di concatenamento, l'endpoint, l'operazione (ad esempio, una richiesta di creazione) e il tipo di chiave (amministratore o query) autorizzano l'accesso al contenuto e alle operazioni.
Limitazione dell'accesso agli indici
Usando i ruoli di Azure, è possibile impostare le autorizzazioni per singoli indici purché venga eseguita a livello di codice.
Usando le chiavi, chiunque disponga di una chiave di amministratore per il servizio può leggere, modificare o eliminare qualsiasi indice nello stesso servizio. Per la protezione da eliminazioni accidentali o dannose di indici, il controllo del codice sorgente interno per gli asset di codice è la soluzione per ripristinare un'eliminazione o una modifica indesiderata dell'indice. Ricerca di intelligenza artificiale di Azure ha failover all'interno del cluster per garantire la disponibilità, ma non archivia o esegue il codice proprietario usato per creare o caricare indici.
Per le soluzioni multi-tenancy che richiedono limiti di sicurezza a livello di indice, è comune gestire l'isolamento degli indici nel livello intermedio nel codice dell'applicazione. Per altre informazioni sul caso d'uso multi-tenant, vedere Modelli di progettazione per applicazioni SaaS multi-tenant e Ricerca di intelligenza artificiale di Azure.
Limitazione dell'accesso ai documenti
Le autorizzazioni utente a livello di documento, note anche come sicurezza a livello di riga, non sono supportate in modo nativo in Ricerca di intelligenza artificiale di Azure. Se si importano dati da un sistema esterno che fornisce sicurezza a livello di riga, ad esempio Azure Cosmos DB, tali autorizzazioni non verranno trasferite con i dati come indicizzati da Ricerca di intelligenza artificiale di Azure.
Se è necessario l'accesso autorizzato al contenuto nei risultati della ricerca, è disponibile una tecnica per l'applicazione di filtri che includono o escludono documenti in base all'identità utente. Questa soluzione alternativa aggiunge un campo stringa nell'origine dati che rappresenta un gruppo o un'identità utente, che è possibile rendere filtrabile nell'indice. La tabella seguente descrive due approcci per limitare i risultati della ricerca di contenuto non autorizzato.
| Approccio | Descrizione |
|---|---|
| Limitazione per motivi di sicurezza in base ai filtri delle identità | Documenta il flusso di lavoro di base per implementare il controllo di accesso dell'identità utente. Illustra l'aggiunta di ID di sicurezza a un indice e quindi illustra l'applicazione di filtri a tale campo per limitare i risultati di contenuto non consentito. |
| Taglio della sicurezza basato sulle identità di Microsoft Entra | Questo articolo si espande nell'articolo precedente, fornendo i passaggi per il recupero delle identità dall'ID Microsoft Entra, uno dei servizi gratuiti nella piattaforma cloud di Azure. |
Residenza dei dati
Quando si configura un servizio di ricerca, si sceglie un'area che determina dove vengono archiviati ed elaborati i dati dei clienti. Ogni area esiste all'interno di un'area geografica (geo) che spesso include più aree geografiche( ad esempio, la Svizzera è un'area geografica che contiene la Svizzera settentrionale e la Svizzera occidentale). Ricerca di intelligenza artificiale di Azure potrebbe replicare i dati in un'altra area all'interno della stessa area geografica per durabilità e disponibilità elevata. Il servizio non archivia o elabora i dati dei clienti all'esterno dell'area geografica specificata, a meno che non si configuri una funzionalità con una dipendenza da un'altra risorsa di Azure e che venga effettuato il provisioning di tale risorsa in un'area diversa.
Attualmente, l'unica risorsa esterna in cui scrive un servizio di ricerca è Archiviazione di Azure. L'account di archiviazione è uno fornito e può trovarsi in qualsiasi area. Un servizio di ricerca scrive in Archiviazione di Azure se si usa una delle funzionalità seguenti:
Per altre informazioni sulla residenza dei dati, vedere Residenza dei dati in Azure.
Eccezioni agli impegni di residenza dei dati
I nomi degli oggetti vengono visualizzati nei log di telemetria usati da Microsoft per fornire supporto per il servizio. I nomi degli oggetti vengono archiviati ed elaborati all'esterno dell'area o della posizione selezionata. I nomi degli oggetti includono i nomi di indici e campi di indice, alias, indicizzatori, origini dati, set di competenze, mappe sinonimiche, risorse, contenitori e archivio dell'insieme di credenziali delle chiavi. I clienti non devono inserire dati sensibili nei campi dei nomi o creare applicazioni progettate per archiviare i dati sensibili in questi campi.
I log di telemetria vengono conservati per un anno e mezzo. Durante tale periodo, Microsoft potrebbe accedere e fare riferimento ai nomi degli oggetti nelle condizioni seguenti:
Diagnosticare un problema, migliorare una funzionalità o correggere un bug. In questo scenario, l'accesso ai dati è solo interno, senza accesso di terze parti.
Durante il supporto, queste informazioni potrebbero essere usate per fornire una risoluzione rapida ai problemi ed eseguire l'escalation del team del prodotto, se necessario
Protezione dei dati
A livello di archiviazione, la crittografia dei dati è incorporata per tutto il contenuto gestito dal servizio salvato su disco, inclusi indici, mappe sinonimiche e definizioni di indicizzatori, origini dati e set di competenze. La crittografia gestita dal servizio si applica sia all'archiviazione dei dati a lungo termine che all'archiviazione temporanea dei dati.
Facoltativamente, è possibile aggiungere chiavi gestite dal cliente (CMK) per la crittografia supplementare del contenuto indicizzato per la doppia crittografia dei dati inattivi. Per i servizi creati dopo il 1° agosto 2020, la crittografia cmk si estende ai dati a breve termine nei dischi temporanei.
Dati in transito
Per le connessioni al servizio di ricerca su Internet pubblico, Ricerca intelligenza artificiale di Azure è in ascolto sulla porta HTTPS 443.
Ricerca di intelligenza artificiale di Azure supporta TLS 1.2 e 1.3 per la crittografia del canale da client a servizio:
- TLS 1.3 è l'impostazione predefinita nei sistemi operativi client e nelle versioni più recenti di .NET.
- TLS 1.2 è l'impostazione predefinita nei sistemi meno recenti, ma è possibile impostare in modo esplicito TLS 1.3 in una richiesta client.
Le versioni precedenti di TLS (1.0 o 1.1) non sono supportate.
Per altre informazioni, vedere Supporto TLS in .NET Framework.
Dati inattivi
Per i dati gestiti internamente dal servizio di ricerca, nella tabella seguente vengono descritti i modelli di crittografia dei dati. Alcune funzionalità, ad esempio l'archivio conoscenze, l'arricchimento incrementale e l'indicizzazione basata su indicizzatore, leggono o scrivono in strutture di dati in altri servizi di Azure. I servizi che hanno una dipendenza da Archiviazione di Azure possono usare le funzionalità di crittografia di tale tecnologia.
| Modello | Chiavi | Requisiti | Restrizioni | Si applica a |
|---|---|---|---|---|
| crittografia lato server | Chiavi gestite da Microsoft | Nessuno (predefinito) | Nessuno, disponibile in tutti i livelli, in tutte le aree, per il contenuto creato dopo il 24 gennaio 2018. | Contenuto (indici e mappe sinonimiche) e definizioni (indicizzatori, origini dati, set di competenze), su dischi dati e dischi temporanei |
| crittografia lato server | Chiavi gestite dal cliente | Azure Key Vault | Disponibile nei livelli fatturabili, in aree specifiche, per il contenuto creato dopo il 1° agosto 2020. | Contenuto (indici e mappe sinonimi) nei dischi dati |
| crittografia completa lato server | Chiavi gestite dal cliente | Azure Key Vault | Disponibile nei livelli fatturabili, in tutte le aree, nei servizi di ricerca dopo il 13 maggio 2021. | Contenuto (indici e mappe sinonimi) su dischi dati e dischi temporanei |
Chiavi gestite dal servizio
La crittografia gestita dal servizio è un'operazione interna di Microsoft che usa la crittografia AES a 256 bit. Si verifica automaticamente su tutti gli indici, inclusi gli aggiornamenti incrementali agli indici non completamente crittografati (creati prima di gennaio 2018).
La crittografia gestita dal servizio si applica a tutto il contenuto nell'archiviazione a lungo termine e a breve termine.
Chiavi gestite dal cliente (CMK)
Le chiavi gestite dal cliente richiedono un altro servizio fatturabile, Azure Key Vault, che può trovarsi in un'area diversa, ma nella stessa sottoscrizione, di Ricerca di intelligenza artificiale di Azure.
Il supporto della chiave gestita dal cliente è stato implementato in due fasi. Se il servizio di ricerca è stato creato durante la prima fase, la crittografia della chiave gestita dal cliente era limitata all'archiviazione a lungo termine e a aree specifiche. I servizi creati nella seconda fase, dopo maggio 2021, possono usare la crittografia cmk in qualsiasi area. Nell'ambito dell'implementazione del secondo ciclo, il contenuto è crittografato dalla chiave gestita dal cliente sia per l'archiviazione a lungo termine che per l'archiviazione a breve termine. Per altre informazioni sul supporto della chiave gestita dal cliente, vedere Crittografia doppia completa.
L'abilitazione della crittografia della chiave gestita dal cliente aumenta le dimensioni dell'indice e degrada le prestazioni delle query. In base alle osservazioni fino ad oggi, è possibile prevedere un aumento del 30-60% nei tempi di query, anche se le prestazioni effettive variano a seconda della definizione dell'indice e dei tipi di query. A causa dell'impatto negativo sulle prestazioni, è consigliabile abilitare questa funzionalità solo negli indici che lo richiedono realmente. Per altre informazioni, vedere Configurare le chiavi di crittografia gestite dal cliente in Ricerca di intelligenza artificiale di Azure.
Amministrazione della sicurezza
Gestire le chiavi API
La dipendenza dall'autenticazione basata su chiave API significa che è necessario avere un piano per rigenerare la chiave di amministrazione a intervalli regolari, in base alle procedure consigliate per la sicurezza di Azure. Sono disponibili al massimo due chiavi di amministrazione per ogni servizio di ricerca. Per altre informazioni sulla protezione e la gestione delle chiavi API, vedere Creare e gestire le chiavi API.
Log attività e log risorse
Ricerca di intelligenza artificiale di Azure non registra le identità utente, quindi non è possibile fare riferimento ai log per informazioni su un utente specifico. Tuttavia, il servizio registra operazioni create-read-update-delete, che potrebbe essere possibile correlare con altri log per comprendere l'agenzia di azioni specifiche.
Usando gli avvisi e l'infrastruttura di registrazione in Azure, è possibile raccogliere picchi di volume di query o altre azioni che deviano dai carichi di lavoro previsti. Per altre informazioni sulla configurazione dei log, vedere Raccogliere e analizzare i dati di log e Monitorare le richieste di query.
Certificazioni e conformità
Ricerca di intelligenza artificiale di Azure partecipa a controlli regolari ed è stata certificata in base a molti standard globali, regionali e specifici del settore sia per il cloud pubblico che per Azure per enti pubblici. Per l'elenco completo, scaricare il white paper Sulle offerte di conformità di Microsoft Azure dalla pagina ufficiale dei report di controllo.
Per la conformità, è possibile usare Criteri di Azure per implementare le procedure consigliate per la sicurezza elevata di Microsoft Cloud Security Benchmark. Il benchmark della sicurezza cloud Microsoft è una raccolta di raccomandazioni sulla sicurezza, codificate in controlli di sicurezza che eseguono il mapping alle azioni chiave da intraprendere per attenuare le minacce ai servizi e ai dati. Attualmente sono disponibili 12 controlli di sicurezza, tra cui sicurezza di rete, registrazione e monitoraggio e protezione dei dati.
Criteri di Azure è una funzionalità integrata in Azure che consente di gestire la conformità per più standard, inclusi quelli di Microsoft Cloud Security Benchmark. Per i benchmark noti, Criteri di Azure fornisce definizioni predefinite che forniscono criteri e una risposta praticabile che risolve la mancata conformità.
Per Ricerca di intelligenza artificiale di Azure è attualmente disponibile una definizione predefinita. È per la registrazione delle risorse. È possibile assegnare un criterio che identifichi i servizi di ricerca che mancano la registrazione delle risorse e quindi attivarlo. Per altre informazioni, vedere Criteri di Azure controlli di conformità alle normative per Ricerca di intelligenza artificiale di Azure.
Guarda il video
Guardare questo video rapido per una panoramica dell'architettura di sicurezza e di ogni categoria di funzionalità.
Vedi anche
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per