Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
In questa guida introduttiva si apprenderà come creare un pool di Apache Spark serverless in Azure Synapse usando gli strumenti Web. Si apprenderà quindi a connettersi al pool di Apache Spark ed eseguire query Spark SQL su file e tabelle. Apache Spark consente l'analisi rapida dei dati e il calcolo del cluster usando l'elaborazione in memoria. Per informazioni su Spark in Azure Synapse, vedere Panoramica: Apache Spark in Azure Synapse.
Importante
La fatturazione delle istanze di Spark è calcolata al minuto, sia che vengano utilizzate o meno. Assicurarsi di arrestare l'istanza di Spark al termine dell'uso o di impostare un breve timeout. Per altre informazioni, vedere la sezione Pulire le risorse di questo articolo.
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Prerequisiti
- Sarà necessaria una sottoscrizione di Azure. Se necessario, creare un account Azure gratuito
- Area di lavoro synapse Analytics
- Pool di Apache Spark serverless
Accedere al portale di Azure
Accedi al portale di Azure.
Se non si ha una sottoscrizione di Azure, creare un account Azure gratuito prima di iniziare.
Crea un notebook
Un notebook è un ambiente interattivo che supporta vari linguaggi di programmazione. Il notebook consente di interagire con i dati, combinare il codice con markdown, testo ed eseguire visualizzazioni semplici.
Nella visualizzazione del portale di Azure per l'area di lavoro di Azure Synapse da usare selezionare Avvia Synapse Studio.
Dopo l'avvio di Synapse Studio, selezionare Sviluppa. Selezionare quindi l'icona "+" per aggiungere una nuova risorsa.
Da qui selezionare Notebook. Viene creato e aperto un nuovo notebook con un nome generato automaticamente.

Nella finestra Proprietà specificare un nome per il notebook.
Sulla barra degli strumenti fare clic su Pubblica.
Se nell'area di lavoro è presente un solo pool di Apache Spark, viene selezionato per impostazione predefinita. Usare l'elenco a discesa per selezionare il pool di Apache Spark corretto qualora non ne sia stato selezionato uno.
Fare clic su Aggiungi codice. La lingua predefinita è
Pyspark. Si userà una combinazione di Pyspark e Spark SQL, quindi la scelta predefinita è corretta. Altri linguaggi supportati sono Scala e .NET per Spark.Successivamente si crea un semplice oggetto DataFrame Spark da modificare. In questo caso, è possibile crearlo dal codice. Sono presenti tre righe e tre colonne:
new_rows = [('CA',22, 45000),("WA",35,65000) ,("WA",50,85000)] demo_df = spark.createDataFrame(new_rows, ['state', 'age', 'salary']) demo_df.show()Ora, esegui la cella usando uno dei metodi seguenti:
Premere MAIUSC + INVIO.
Selezionare l'icona di riproduzione blu a sinistra della cella.
Selezionare il pulsante Esegui tutto sulla barra degli strumenti.
Se l'istanza del pool di Apache Spark non è già in esecuzione, viene avviata automaticamente. È possibile visualizzare lo stato dell'istanza del pool di Apache Spark sotto la cella in esecuzione e anche nel pannello di stato nella parte inferiore del notebook. A seconda delle dimensioni del pool, l'avvio dovrebbe richiedere 2-5 minuti. Al termine dell'esecuzione del codice, le informazioni sotto la cella mostrano il tempo impiegato e i dettagli dell'esecuzione. Nella cella di output vedi il risultato.
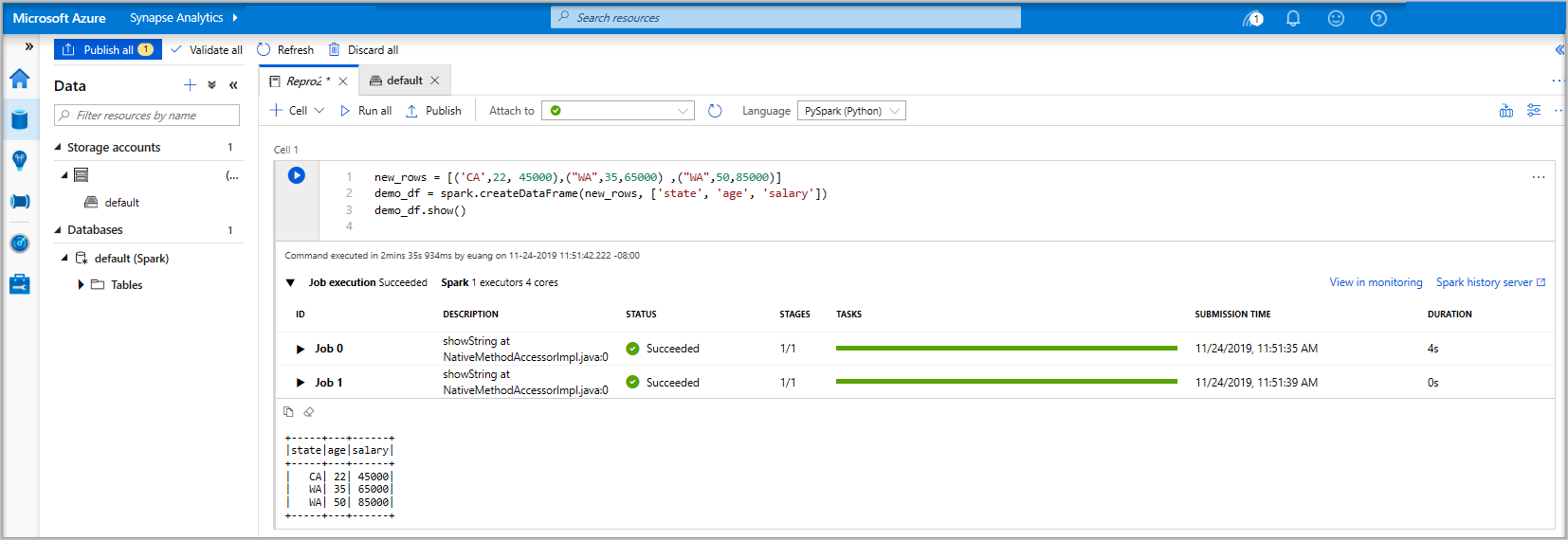
I dati sono ora presenti in un dataframe da cui è possibile usare i dati in molti modi diversi. Saranno necessari in formati diversi per la parte restante di questa guida di avvio rapido.
Immettere il codice seguente in un'altra cella ed eseguirlo, in questo modo viene creata una tabella Spark, un file CSV e un file Parquet tutti con copie dei dati:
demo_df.createOrReplaceTempView('demo_df') demo_df.write.csv('demo_df', mode='overwrite') demo_df.write.parquet('abfss://<<TheNameOfAStorageAccountFileSystem>>@<<TheNameOfAStorageAccount>>.dfs.core.windows.net/demodata/demo_df', mode='overwrite')Se si usa Storage Explorer, è possibile vedere l'impatto dei due modi diversi di scrivere un file usato in precedenza. Quando non viene specificato alcun file system, viene usato il valore predefinito, in questo caso
default>user>trusted-service-user>demo_df. I dati vengono salvati nel percorso del file system specificato.Notare che nei formati "csv" e "parquet" durante le operazioni di scrittura viene creata una directory con molti file partizionati.


Eseguire istruzioni SPARK SQL
Structured Query Language (SQL) è il linguaggio più comune e ampiamente usato per l'esecuzione di query e la definizione dei dati. Spark SQL funziona come estensione di Apache Spark per l'elaborazione di dati strutturati, usando la sintassi SQL familiare.
Incollare il codice seguente in una cella vuota e quindi eseguire il codice. Il comando elenca le tabelle nel pool.
%%sql SHOW TABLESQuando si usa un notebook con il pool di Apache Spark di Azure Synapse, si ottiene un set di impostazioni
sqlContextche è possibile usare per eseguire query usando Spark SQL.%%sqlindica al notebook di usare il set di impostazionisqlContextper eseguire la query. La query recupera le prime 10 righe da una tabella di sistema fornita con tutti i pool di Apache Spark di Azure Synapse per impostazione predefinita.Eseguire un'altra query per visualizzare i dati in
demo_df.%%sql SELECT * FROM demo_dfIl codice produce due celle di output, una che contiene i risultati dei dati e l'altra, che mostra la visualizzazione del lavoro.
Per impostazione predefinita, la visualizzazione dei risultati mostra una griglia. Tuttavia, c'è un commutatore di visualizzazione sotto la griglia che consente alla visualizzazione di passare tra le visualizzazioni griglia e grafico.

Nell'interruttore Visualizza selezionare Grafico.
Selezionare l'icona Visualizza opzioni sul lato destro.
Nel campo Tipo di grafico selezionare "grafico a barre".
Nel campo colonna Asse X selezionare "stato".
Nel campo colonna asse Y selezionare "salary".
Nel campo Aggregazione selezionare "AVG".
Selezionare Applica.

È possibile ottenere la stessa esperienza di esecuzione di SQL, ma senza dover cambiare linguaggio. A tale scopo, sostituire la cella SQL precedente con questa cella PySpark, l'esperienza di output è la stessa perché viene usato il comando display :
display(spark.sql('SELECT * FROM demo_df'))Ognuna delle celle eseguite in precedenza conteneva l’opzione per passare al server di cronologia e a Monitoraggio. Facendo clic sui collegamenti si passa a diverse parti dell'esperienza utente.
Annotazioni
Una parte della documentazione ufficiale di Apache Spark si basa sull'uso della console Spark, che non è disponibile in Synapse Spark. Usare al suo posto un notebook o IntelliJ.
Pulire le risorse
Azure Synapse salva i dati in Azure Data Lake Storage. Puoi tranquillamente permettere che un'istanza di Spark si spenga quando non è in uso. Vengono addebitati costi per un pool di Apache Spark serverless, purché sia in esecuzione, anche quando non è in uso.
Poiché gli addebiti per il pool sono molto superiori agli addebiti per l'archiviazione, è opportuno lasciare che le istanze di Spark vengano spente quando non sono in uso.
Per assicurarsi che l'istanza di Spark venga arrestata, terminare tutte le sessioni connesse (notebook). Il pool si arresta quando viene raggiunto il tempo di inattività specificato nel pool di Apache Spark. È anche possibile selezionare la sessione di fine dalla barra di stato nella parte inferiore del notebook.
Passaggi successivi
In questa guida introduttiva si è appreso come creare un pool di Apache Spark serverless ed eseguire una query Spark SQL di base.