Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo illustra come usare Apache Spark MLlib per creare un'applicazione di Machine Learning che esegue un'analisi predittiva semplice in un set di dati aperto di Azure. Spark offre librerie di Machine Learning predefinite. In questo esempio viene usata la classificazione tramite la regressione logistica.
SparkML e MLlib sono librerie Spark di base che offrono molte utilità utili per le attività di Machine Learning, incluse le utilità adatte per:
- Classification
- Regression
- Clustering
- Modellazione di argomenti
- Scomposizione di valori singolari (SVD) e analisi dei componenti principali (PCA)
- Test di ipotesi e calcolo delle statistiche di esempio
Informazioni sulla classificazione e la regressione logistica
La classificazione, un'attività di Machine Learning comune, è il processo di ordinamento dei dati di input in categorie. È il processo di un algoritmo di classificazione per capire come assegnare etichette ai dati di input forniti. Ad esempio, è possibile pensare a un algoritmo di Machine Learning che accetta le informazioni sulle scorte come input e dividere le azioni in due categorie: azioni che è consigliabile vendere e azioni che è necessario mantenere.
La regressione logistica è un algoritmo che è possibile usare per la classificazione. L'API di regressione logistica di Spark è utile per la classificazione binaria o la classificazione dei dati di input in uno dei due gruppi. Per altre informazioni sulla regressione logistica, vedere Wikipedia.
In sintesi, il processo di regressione logistica produce una funzione logistica che è possibile usare per stimare la probabilità che un vettore di input appartenga a un gruppo o all'altro.
Esempio di analisi predittiva sui dati dei taxi di New York
In questo esempio, viene usato Spark per eseguire un'analisi predittiva dei dati relativi alle mance sui taxi di New York. I dati sono disponibili tramite Set di dati aperti di Azure. Questo sottoinsieme del set di dati contiene informazioni sulle corse dei taxi gialle, incluse informazioni su ogni corsa, ora di inizio e fine e località, sui costi e su altri attributi interessanti.
Importante
Potrebbero essere previsti costi aggiuntivi per il pull di questi dati dalla posizione di archiviazione.
Nei passaggi seguenti viene sviluppato un modello per stimare se una particolare corsa includa una mancia o meno.
Creare un modello di Machine Learning apache Spark
Creare un notebook usando il kernel PySpark. Per istruzioni, vedere Creare un notebook.
Importare i tipi necessari per questa applicazione. Copiare e incollare il codice seguente in una cella vuota, quindi premere MAIUSC+INVIO. In alternativa, eseguire la cella usando l'icona di riproduzione blu a sinistra del codice.
import matplotlib.pyplot as plt from datetime import datetime from dateutil import parser from pyspark.sql.functions import unix_timestamp, date_format, col, when from pyspark.ml import Pipeline from pyspark.ml import PipelineModel from pyspark.ml.feature import RFormula from pyspark.ml.feature import OneHotEncoder, StringIndexer, VectorIndexer from pyspark.ml.classification import LogisticRegression from pyspark.mllib.evaluation import BinaryClassificationMetrics from pyspark.ml.evaluation import BinaryClassificationEvaluatorA causa del kernel PySpark, non è necessario creare contesti in modo esplicito. Il contesto Spark viene creato automaticamente quando si esegue la prima cella di codice.
Costruire il dataframe di input
Poiché i dati non elaborati sono in formato Parquet, è possibile usare il contesto di Spark per caricare direttamente il file in memoria come DataFrame. Anche se il codice nei passaggi seguenti usa le opzioni predefinite, è possibile forzare il mapping dei tipi di dati e di altri attributi dello schema, se necessario.
Eseguire le righe seguenti per creare un dataframe Spark incollando il codice in una nuova cella. Questo passaggio recupera i dati tramite l'API Open Datasets. L'estrazione di tutti questi dati genera circa 1,5 miliardi di righe.
A seconda delle dimensioni del pool di Apache Spark serverless, i dati non elaborati potrebbero essere troppo grandi o richiedere troppo tempo per funzionare. È possibile filtrare i dati in base a qualcosa di più piccolo. Nell'esempio di codice seguente,
start_dateeend_datevengono usati per applicare un filtro che seleziona i dati di un solo mese.from azureml.opendatasets import NycTlcYellow from datetime import datetime from dateutil import parser end_date = parser.parse('2018-05-08 00:00:00') start_date = parser.parse('2018-05-01 00:00:00') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) filtered_df = spark.createDataFrame(nyc_tlc.to_pandas_dataframe())Lo svantaggio di un filtro semplice è che, dal punto di vista statistico, potrebbe introdurre distorsioni nei dati. Un altro approccio consiste nell'usare il campionamento incorporato in Spark.
Il codice seguente riduce il set di dati a circa 2.000 righe, se applicato dopo il codice precedente. È possibile usare questo passaggio di campionamento anziché il filtro semplice o in combinazione con il filtro semplice.
# To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234)È ora possibile esaminare i dati per vedere cosa è stato letto. In genere è preferibile esaminare i dati con un subset anziché il set completo, a seconda delle dimensioni del set di dati.
Il codice seguente offre due modi per visualizzare i dati. Il primo modo è di base. Il secondo modo offre un'esperienza griglia molto più completa, insieme alla possibilità di visualizzare i dati graficamente.
#sampled_taxi_df.show(5) display(sampled_taxi_df)A seconda delle dimensioni del set di dati generato e della necessità di sperimentare o eseguire il notebook più volte, potrebbe essere necessario memorizzare nella cache il set di dati in locale nell'area di lavoro. Esistono tre modi per eseguire la memorizzazione nella cache esplicita:
- Salvare il dataframe in locale come file.
- Salvare il dataframe come tabella o vista temporanea.
- Salvare il dataframe come tabella permanente.
I primi due di questi approcci sono inclusi negli esempi di codice seguenti.
La creazione di una tabella o vista temporanea fornisce percorsi di accesso diversi ai dati, ma dura solo per la durata della sessione dell'istanza di Spark.
sampled_taxi_df.createOrReplaceTempView("nytaxi")
Preparare i dati
I dati nel formato non elaborato spesso non sono adatti per passare direttamente a un modello. È necessario eseguire una serie di azioni sui dati per ottenerle in uno stato in cui il modello può utilizzarlo.
Nel codice seguente si eseguono quattro classi di operazioni:
- Rimozione di outlier o valori non corretti tramite il filtro.
- Rimozione delle colonne, che non sono necessarie.
- Creazione di nuove colonne derivate dai dati non elaborati per rendere il modello più efficace. Questa operazione viene talvolta definita definizione delle funzionalità.
- Etichettatura. Dato che si sta eseguendo la classificazione binaria (una determinata corsa prevederà o meno una mancia?), è necessario convertire l'importo della mancia in un valore 0 o 1.
taxi_df = sampled_taxi_df.select('totalAmount', 'fareAmount', 'tipAmount', 'paymentType', 'rateCodeId', 'passengerCount'\
, 'tripDistance', 'tpepPickupDateTime', 'tpepDropoffDateTime'\
, date_format('tpepPickupDateTime', 'hh').alias('pickupHour')\
, date_format('tpepPickupDateTime', 'EEEE').alias('weekdayString')\
, (unix_timestamp(col('tpepDropoffDateTime')) - unix_timestamp(col('tpepPickupDateTime'))).alias('tripTimeSecs')\
, (when(col('tipAmount') > 0, 1).otherwise(0)).alias('tipped')
)\
.filter((sampled_taxi_df.passengerCount > 0) & (sampled_taxi_df.passengerCount < 8)\
& (sampled_taxi_df.tipAmount >= 0) & (sampled_taxi_df.tipAmount <= 25)\
& (sampled_taxi_df.fareAmount >= 1) & (sampled_taxi_df.fareAmount <= 250)\
& (sampled_taxi_df.tipAmount < sampled_taxi_df.fareAmount)\
& (sampled_taxi_df.tripDistance > 0) & (sampled_taxi_df.tripDistance <= 100)\
& (sampled_taxi_df.rateCodeId <= 5)
& (sampled_taxi_df.paymentType.isin({"1", "2"}))
)
Si esegue quindi un secondo passaggio sui dati per aggiungere le funzionalità finali.
taxi_featurised_df = taxi_df.select('totalAmount', 'fareAmount', 'tipAmount', 'paymentType', 'passengerCount'\
, 'tripDistance', 'weekdayString', 'pickupHour','tripTimeSecs','tipped'\
, when((taxi_df.pickupHour <= 6) | (taxi_df.pickupHour >= 20),"Night")\
.when((taxi_df.pickupHour >= 7) & (taxi_df.pickupHour <= 10), "AMRush")\
.when((taxi_df.pickupHour >= 11) & (taxi_df.pickupHour <= 15), "Afternoon")\
.when((taxi_df.pickupHour >= 16) & (taxi_df.pickupHour <= 19), "PMRush")\
.otherwise(0).alias('trafficTimeBins')
)\
.filter((taxi_df.tripTimeSecs >= 30) & (taxi_df.tripTimeSecs <= 7200))
Creare un modello di regressione logistica
L'attività finale consiste nel convertire i dati etichettati in un formato che può essere analizzato tramite la regressione logistica. L'input di un algoritmo di regressione logistica deve essere un set di coppie etichetta/vettore di funzionalità, in cui il vettore di funzionalità è un vettore di numeri che rappresentano il punto di input.
È quindi necessario convertire le colonne categorica in numeri. In particolare, è necessario convertire le trafficTimeBins colonne e weekdayString in rappresentazioni integer. Esistono più approcci per eseguire la conversione. Nell'esempio seguente viene usato l'approccio OneHotEncoder comune.
# Because the sample uses an algorithm that works only with numeric features, convert them so they can be consumed
sI1 = StringIndexer(inputCol="trafficTimeBins", outputCol="trafficTimeBinsIndex")
en1 = OneHotEncoder(dropLast=False, inputCol="trafficTimeBinsIndex", outputCol="trafficTimeBinsVec")
sI2 = StringIndexer(inputCol="weekdayString", outputCol="weekdayIndex")
en2 = OneHotEncoder(dropLast=False, inputCol="weekdayIndex", outputCol="weekdayVec")
# Create a new DataFrame that has had the encodings applied
encoded_final_df = Pipeline(stages=[sI1, en1, sI2, en2]).fit(taxi_featurised_df).transform(taxi_featurised_df)
Questa azione comporta un nuovo dataframe con tutte le colonne nel formato corretto per eseguire il training di un modello.
Addestrare un modello di regressione logistica
La prima attività consiste nel suddividere il set di dati in un set di training e in un set di test o di convalida. La divisione qui è arbitraria. Sperimentare diverse impostazioni di suddivisione per verificare se influiscono sul modello.
# Decide on the split between training and testing data from the DataFrame
trainingFraction = 0.7
testingFraction = (1-trainingFraction)
seed = 1234
# Split the DataFrame into test and training DataFrames
train_data_df, test_data_df = encoded_final_df.randomSplit([trainingFraction, testingFraction], seed=seed)
Ora che sono presenti due dataframe, l'attività successiva consiste nel creare la formula del modello ed eseguirla sul dataframe di training. È quindi possibile eseguire la convalida rispetto al dataframe di test. Sperimentare versioni diverse della formula del modello per visualizzare l'impatto di combinazioni diverse.
Annotazioni
Per salvare il modello, assegnare il ruolo Collaboratore ai dati del BLOB di archiviazione all'ambito della risorsa del server di database SQL di Azure. Per la procedura dettagliata, vedere Assegnare ruoli di Azure usando il portale di Azure. Solo i membri con privilegi di proprietario possono eseguire questo passaggio.
## Create a new logistic regression object for the model
logReg = LogisticRegression(maxIter=10, regParam=0.3, labelCol = 'tipped')
## The formula for the model
classFormula = RFormula(formula="tipped ~ pickupHour + weekdayVec + passengerCount + tripTimeSecs + tripDistance + fareAmount + paymentType+ trafficTimeBinsVec")
## Undertake training and create a logistic regression model
lrModel = Pipeline(stages=[classFormula, logReg]).fit(train_data_df)
## Saving the model is optional, but it's another form of inter-session cache
datestamp = datetime.now().strftime('%m-%d-%Y-%s')
fileName = "lrModel_" + datestamp
logRegDirfilename = fileName
lrModel.save(logRegDirfilename)
## Predict tip 1/0 (yes/no) on the test dataset; evaluation using area under ROC
predictions = lrModel.transform(test_data_df)
predictionAndLabels = predictions.select("label","prediction").rdd
metrics = BinaryClassificationMetrics(predictionAndLabels)
print("Area under ROC = %s" % metrics.areaUnderROC)
L'output di questa cella è:
Area under ROC = 0.9779470729751403
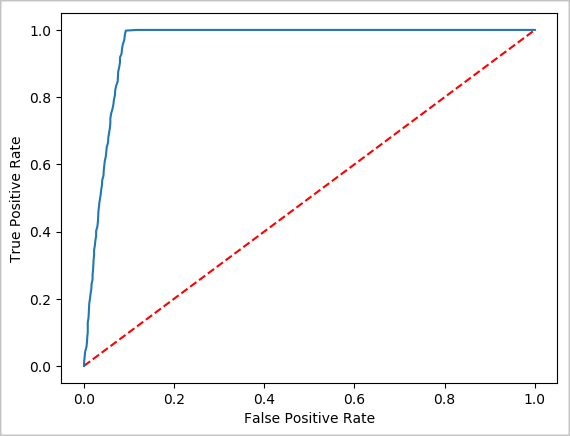
Creare una rappresentazione visiva della stima
È ora possibile costruire una visualizzazione finale per aiutarti a ragionare sui risultati di questo test. Una curva ROC è un modo per esaminare il risultato.
## Plot the ROC curve; no need for pandas, because this uses the modelSummary object
modelSummary = lrModel.stages[-1].summary
plt.plot([0, 1], [0, 1], 'r--')
plt.plot(modelSummary.roc.select('FPR').collect(),
modelSummary.roc.select('TPR').collect())
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.show()
Spegnere l'istanza di Spark
Al termine dell'esecuzione dell'applicazione, arrestare il notebook per rilasciare le risorse chiudendo la scheda. In alternativa, selezionare Termina sessione nel pannello di stato nella parte inferiore del notebook.