Formato di testo delimitato in Data Factory in Microsoft Fabric
Questo articolo illustra come configurare il formato di testo delimitato nella pipeline di dati di Data Factory in Microsoft Fabric.
Funzionalità supportate
Il formato di testo delimitato è supportato per le attività e i connettori seguenti come origine e destinazione.
| Categoria | Connettore/attività |
|---|---|
| Connettore supportato | Amazon S3 |
| Compatibile con Amazon S3 | |
| Archiviazione BLOB di Azure | |
| Azure Data Lake Storage Gen1 | |
| Azure Data Lake Storage Gen2 | |
| File di Azure | |
| File system | |
| FTP | |
| Google Cloud Storage | |
| HTTP | |
| File Lakehouse | |
| Oracle Cloud Storage | |
| SFTP | |
| Attività supportata | attività Copy (origine/destinazione) |
| Attività Lookup | |
| Attività GetMetadata | |
| Attività Delete |
Formato di testo delimitato nell'attività di copia
Per configurare il formato di testo delimitato, scegliere la connessione nell'origine o nella destinazione dell'attività di copia della pipeline di dati e quindi selezionare DelimitedText nell'elenco a discesa Formato file. Selezionare Impostazioni per un'ulteriore configurazione di questo formato.
Formato testo delimitato come origine
Dopo aver selezionato Impostazioni nella sezione Formato file, le proprietà seguenti vengono visualizzate nella finestra di dialogo Impostazioni formato file popup.
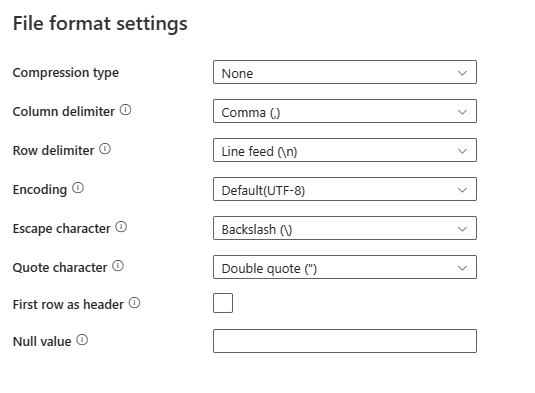
Tipo di compressione: codec di compressione usato per leggere file di testo delimitati. È possibile scegliere tra Tipo none, bzip2, gzip, deflate, ZipDeflate, TarGzip o tar nell'elenco a discesa.
Se si seleziona ZipDeflate come tipo di compressione, mantenere il nome del file ZIP come cartella verrà visualizzato in Impostazioni avanzate nella scheda Origine .
- Mantieni il nome del file ZIP come cartella: indica se mantenere il nome del file ZIP di origine come struttura di cartelle durante la copia.
- Se questa casella è selezionata (impostazione predefinita), il servizio scrive i file decompressi in
<specified file path>/<folder named as source zip file>/. - Se questa casella è deselezionata, il servizio scrive i file decompressi direttamente in
<specified file path>. Assicurarsi di non avere nomi di file duplicati in file ZIP di origine diversi per evitare corse o comportamenti imprevisti.
- Se questa casella è selezionata (impostazione predefinita), il servizio scrive i file decompressi in
Se si seleziona TarGzip/tar come tipo di compressione, mantieni il nome del file di compressione come cartella verrà visualizzato in Impostazioni avanzate nella scheda Origine .
- Mantieni il nome del file di compressione come cartella: indica se mantenere il nome del file compresso di origine come struttura di cartelle durante la copia.
- Se questa casella è selezionata (impostazione predefinita), il servizio scrive i file decompressi in
<specified file path>/<folder named as source compressed file>/. - Se questa casella è deselezionata, il servizio scrive i file decompressi direttamente in
<specified file path>. Assicurarsi di non avere nomi di file duplicati in file ZIP di origine diversi per evitare corse o comportamenti imprevisti.
- Se questa casella è selezionata (impostazione predefinita), il servizio scrive i file decompressi in
- Mantieni il nome del file ZIP come cartella: indica se mantenere il nome del file ZIP di origine come struttura di cartelle durante la copia.
Livello di compressione: specificare il rapporto di compressione quando si seleziona un tipo di compressione. È possibile scegliere tra Ottimale o Più veloce.
- Fastest: l'operazione di compressione deve essere completata il più rapidamente possibile, anche se il file risultante non viene compresso in modo ottimale.
- Optimal: l'operazione di compressione deve comprimere il file in modo ottimale, anche se il completamento richiede più tempo. Per maggiori informazioni, vedere l'argomento relativo al livello di compressione .
Delimitatore di colonna: i caratteri usati per separare le colonne in un file. Il valore predefinito è virgola (
,).Delimitatore di riga: specificare il carattere utilizzato per separare le righe in un file. È consentito un solo carattere. Il valore predefinito è avanzamento
\nriga.Codifica: tipo di codifica usato per leggere/scrivere file di test. Il valore predefinito è UTF-8.
Carattere di escape: carattere singolo di escape tra virgolette all'interno di un valore tra virgolette. Il valore predefinito è barra rovesciata
\. Quando il carattere di escape è definito come stringa vuota, anche il carattere virgolette deve essere impostato come stringa vuota, nel qual caso assicurarsi che tutti i valori di colonna non contengano delimitatori.Carattere virgolette: carattere singolo da virgolettere i valori di colonna se contiene il delimitatore di colonna. Il valore predefinito è virgolette
"doppie. Quando il carattere virgolette è definito come stringa vuota, significa che non è presente alcuna virgoletta e il valore della colonna non è racchiuso tra virgolette e il carattere di escape viene usato per eseguire l'escape del delimitatore di colonna e se stesso.Prima riga come intestazione: specifica se trattare o impostare la prima riga come riga di intestazione con nomi di colonne. I valori consentiti sono selezionati e deselezionati (impostazione predefinita). Quando la prima riga come intestazione non è selezionata, prendere nota dell'anteprima dei dati dell'interfaccia utente e l'output dell'attività di ricerca genera automaticamente nomi di colonna come Prop_{n} (a partire da 0), l'attività di copia richiede il mapping esplicito dall'origine alla destinazione e individua le colonne in base all'ordinale (a partire da 1).
Valore Null: specifica la rappresentazione di stringa del valore Null. Il valore predefinito è una stringa vuota.
In Impostazioni avanzate nella scheda Origine vengono esposte altre proprietà correlate al formato di testo delimitato.
Formato testo delimitato come destinazione
Dopo aver selezionato Impostazioni nella sezione Formato file, le proprietà seguenti vengono visualizzate nella finestra di dialogo Impostazioni formato file popup.
Tipo di compressione: codec di compressione usato per scrivere file di testo delimitati. È possibile scegliere tra Tipo none, bzip2, gzip, deflate, ZipDeflate, TarGzip o tar nell'elenco a discesa.
Livello di compressione: specificare il rapporto di compressione quando si seleziona un tipo di compressione. È possibile scegliere tra Ottimale o Più veloce.
- Fastest: l'operazione di compressione deve essere completata il più rapidamente possibile, anche se il file risultante non viene compresso in modo ottimale.
- Optimal: l'operazione di compressione deve comprimere il file in modo ottimale, anche se il completamento richiede più tempo. Per maggiori informazioni, vedere l'argomento relativo al livello di compressione .
Delimitatore di colonna: i caratteri usati per separare le colonne in un file. Il valore predefinito è virgola (
,).Delimitatore di riga: carattere utilizzato per separare le righe in un file. È consentito un solo carattere. Il valore predefinito è avanzamento
\nriga.Codifica: tipo di codifica usato per scrivere file di test. Il valore predefinito è UTF-8.
Carattere di escape: carattere singolo di escape tra virgolette all'interno di un valore tra virgolette. Il valore predefinito è barra rovesciata
\. Quando il carattere di escape è definito come stringa vuota, anche il carattere virgolette deve essere impostato come stringa vuota, nel qual caso assicurarsi che tutti i valori di colonna non contengano delimitatori.Carattere virgolette: carattere singolo da virgolettere i valori di colonna se contiene il delimitatore di colonna. Il valore predefinito è virgolette
"doppie. Quando il carattere virgolette è definito come stringa vuota, significa che non è presente alcuna virgoletta e il valore della colonna non è racchiuso tra virgolette e il carattere di escape viene usato per eseguire l'escape del delimitatore di colonna e se stesso.Prima riga come intestazione: specifica se trattare o impostare la prima riga come riga di intestazione con nomi di colonne. I valori consentiti sono selezionati e deselezionati (impostazione predefinita). Quando la prima riga come intestazione non è selezionata, prendere nota dell'anteprima dei dati dell'interfaccia utente e l'output dell'attività di ricerca genera automaticamente nomi di colonna come Prop_{n} (a partire da 0), l'attività di copia richiede il mapping esplicito dall'origine alla destinazione e individua le colonne in base all'ordinale (a partire da 1).
Valore Null: specifica la rappresentazione di stringa del valore Null. Il valore predefinito è una stringa vuota.
In Impostazioni avanzate nella scheda Destinazione vengono visualizzate altre proprietà correlate al formato di testo delimitato.
Virgolette tutto il testo: racchiudere tutti i valori tra virgolette.
Estensione file: estensione di file usata per denominare i file di output,
.csvad esempio ,.txt.Numero massimo di righe per file: quando si scrivono dati in una cartella, è possibile scegliere di scrivere in più file e specificare il numero massimo di righe per file.
Prefisso del nome file: applicabile quando è configurato il numero massimo di righe per file. Specificare il prefisso del nome file durante la scrittura di dati in più file, con questo modello:
<fileNamePrefix>_00000.<fileExtension>. Se non specificato, il prefisso del nome file verrà generato automaticamente. Questa proprietà non si applica quando l'origine è l'archivio basato su file o l'opzione di partizione abilitata per l'archivio dati.
Riepilogo tabella
Testo delimitato come origine
Le proprietà seguenti sono supportate nella sezione Origine dell'attività di copia quando si usa il formato di testo delimitato.
| Nome | Descrizione | Valore | Obbligatorio | Proprietà script JSON |
|---|---|---|---|---|
| Formato file | Formato di file che si desidera utilizzare. | DelimitedText | Sì | type (in datasetSettings):DelimitedText |
| Tipo di compressione | Codec di compressione utilizzato per leggere file di testo delimitati. | Scegliere tra: Nessuno bzip2 gzip sgonfiare ZipDeflate TarGzip catrame |
No | type (in compression): bzip2 gzip sgonfiare ZipDeflate TarGzip tar |
| Mantenere il nome del file ZIP come cartella | Indica se mantenere il nome del file ZIP di origine come struttura di cartelle durante la copia. Si applica quando si seleziona Compressione ZipDeflate . | Selezionato o deselezionato | No | preserveZipFileNameAsFolder (under compressionProperties->type as ZipDeflateReadSettings) |
| Mantenere il nome del file di compressione come cartella | Indica se mantenere il nome del file compresso di origine come struttura di cartelle durante la copia. Si applica quando si seleziona Compressione TarGzip/tar . | Selezionato o deselezionato | No | preserveCompressionFileNameAsFolder (in compressionProperties->type come TarGZipReadSettings o TarReadSettings) |
| Livello di compressione | Rapporto di compressione. I valori consentiti sono Optimal o Fastest. | Ottimale o più veloce | No | livello (in compression): Il più rapido Ottimale |
| Delimitatore di colonna | Caratteri utilizzati per separare le colonne in un file. | < delimitatore di colonna selezionato > virgola , (per impostazione predefinita) |
No | columnDelimiter |
| Delimitatore di riga | carattere usato per separare le righe in un file. | < delimitatore di riga selezionato > \r,\n (per impostazione predefinita) o r\n |
No | rowDelimiter |
| Encoding | Tipo di codifica utilizzato per leggere/scrivere file di test. | "UTF-8" (per impostazione predefinita),"UTF-8 without BOM", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "US-ASCII", "UTF-7", "BIG5", ""BIG5", "EUC-JP, "EUC-KR", "GB2312", "GB18030", "JOHAB", "SHIFT-JIS", "CP875", "CP866", "IBM00858", "IBM037", "IBM273", "IBM437", "IBM437", ""IBM500", "IBM737", "IBM775", "IBM850", "IBM852", "IBM855", "IBM857", "IBM860", "IBM861", "IBM863", "IBM864", "IBM865", "IBM869", "IBM870", "IBM01140", "IBM01141", "IBM01142", "IBM01143", "IBM01144", "IBM01145", "IBM01146", "IBM01147", "IBM01148", "IBM01149", "IBM01149", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-3", "ISOO-8859-4", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", ""ISO-8859-9", "ISO-8859-13", "ISO-8859-15", "WINDOWS-874", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1251 " WINDOWS-1252", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255", "WINDOWS-1256", "WINDOWS-1257", "WINDOWS-1258" | No | encodingName |
| Carattere di escape | Carattere singolo di escape tra virgolette all'interno di un valore tra virgolette. Quando il carattere di escape è definito come stringa vuota, anche il carattere virgolette deve essere impostato come stringa vuota, nel qual caso assicurarsi che tutti i valori di colonna non contengano delimitatori. | < il carattere di escape selezionato > barra \ rovesciata (per impostazione predefinita) |
No | escapeChar |
| Carattere virgolette | Carattere singolo da virgolettere i valori di colonna se contiene il delimitatore di colonna. Quando il carattere virgolette è definito come stringa vuota, significa che non è presente alcuna virgoletta e il valore della colonna non è racchiuso tra virgolette e il carattere di escape viene usato per eseguire l'escape del delimitatore di colonna e se stesso. | < il carattere di virgoletta selezionato > virgolette " doppie (per impostazione predefinita) |
No | quoteChar |
| Prima riga come intestazione | Specifica se considerare la prima riga del foglio di lavoro/intervallo specificato come riga di intestazione con nomi di colonne. | Selezionato o non selezionato | No | firstRowAsHeader: true o false (impostazione predefinita) |
| Valore Null | Specifica la rappresentazione di stringa del valore Null. Il valore predefinito è una stringa vuota. | < rappresentazione di stringa di valore Null > stringa vuota (per impostazione predefinita) |
No | nullValue |
Testo delimitato come destinazione
Nella sezione Destinazione dell'attività di copia sono supportate le proprietà seguenti quando si usa il formato di testo delimitato.
| Nome | Descrizione | Valore | Obbligatorio | Proprietà script JSON |
|---|---|---|---|---|
| Formato file | Formato di file che si desidera utilizzare. | DelimitedText | Sì | type (in datasetSettings):DelimitedText |
| Tipo di compressione | Codec di compressione utilizzato per scrivere file di testo delimitati. | Scegliere tra: Nessuno bzip2 gzip sgonfiare ZipDeflate TarGzip catrame |
No | type (in compression): bzip2 gzip sgonfiare ZipDeflate TarGzip tar |
| Mantenere il nome del file ZIP come cartella | Indica se mantenere il nome del file ZIP di origine come struttura di cartelle durante la copia. | Selezionato o deselezionato | No | preserveZipFileNameAsFolder (under compressionProperties->type as ZipDeflateReadSettings) |
| Mantenere il nome del file di compressione come cartella | Indica se mantenere il nome del file compresso di origine come struttura di cartelle durante la copia. | Selezionato o deselezionato | No | preserveCompressionFileNameAsFolder (in compressionProperties->type come TarGZipReadSettings o TarReadSettings) |
| Livello di compressione | Rapporto di compressione. I valori consentiti sono Optimal o Fastest. | Ottimale o più veloce | No | livello (in compression): Il più rapido Ottimale |
| Delimitatore di colonna | Caratteri utilizzati per separare le colonne in un file. | < delimitatore di colonna selezionato > virgola , (per impostazione predefinita) |
No | columnDelimiter |
| Delimitatore di riga | carattere usato per separare le righe in un file. | < delimitatore di riga selezionato > \r,\n (per impostazione predefinita) o r\n |
No | rowDelimiter |
| Encoding | Tipo di codifica utilizzato per leggere/scrivere file di test. | "UTF-8" (per impostazione predefinita),"UTF-8 without BOM", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "US-ASCII", "UTF-7", "BIG5", ""BIG5", "EUC-JP, "EUC-KR", "GB2312", "GB18030", "JOHAB", "SHIFT-JIS", "CP875", "CP866", "IBM00858", "IBM037", "IBM273", "IBM437", "IBM437", ""IBM500", "IBM737", "IBM775", "IBM850", "IBM852", "IBM855", "IBM857", "IBM860", "IBM861", "IBM863", "IBM864", "IBM865", "IBM869", "IBM870", "IBM01140", "IBM01141", "IBM01142", "IBM01143", "IBM01144", "IBM01145", "IBM01146", "IBM01147", "IBM01148", "IBM01149", "IBM01149", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-3", "ISOO-8859-4", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", ""ISO-8859-9", "ISO-8859-13", "ISO-8859-15", "WINDOWS-874", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1251 " WINDOWS-1252", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255", "WINDOWS-1256", "WINDOWS-1257", "WINDOWS-1258" | No | encodingName |
| Carattere di escape | Carattere singolo di escape tra virgolette all'interno di un valore tra virgolette. Quando il carattere di escape è definito come stringa vuota, anche il carattere virgolette deve essere impostato come stringa vuota, nel qual caso assicurarsi che tutti i valori di colonna non contengano delimitatori. | < il carattere di escape selezionato > barra \ rovesciata (per impostazione predefinita) |
No | escapeChar |
| Carattere virgolette | Carattere singolo da virgolettere i valori di colonna se contiene il delimitatore di colonna. Quando il carattere virgolette è definito come stringa vuota, significa che non è presente alcuna virgoletta e il valore della colonna non è racchiuso tra virgolette e il carattere di escape viene usato per eseguire l'escape del delimitatore di colonna e se stesso. | < il carattere di virgoletta selezionato > virgolette " doppie (per impostazione predefinita) |
No | quoteChar |
| Prima riga come intestazione | Specifica se considerare la prima riga del foglio di lavoro/intervallo specificato come riga di intestazione con nomi di colonne. | Selezionato o non selezionato | No | firstRowAsHeader: true o false (impostazione predefinita) |
| Virgolette tutto il testo | Racchiudere tutti i valori tra virgolette. | Selezionato (impostazione predefinita) o deselezionato | No | quoteAllText: true (impostazione predefinita) o false |
| Estensione file | Estensione di file utilizzata per denominare i file di output. | < estensione del file > .txt (per impostazione predefinita) |
No | fileExtension |
| Numero massimo di righe per file | Quando si scrivono dati in una cartella, è possibile scegliere di scrivere in più file e specificare il numero massimo di righe per file. | < numero massimo di righe per file > | No | maxRowsPerFile |
| Prefisso del nome file | Applicabile quando è configurato il numero massimo di righe per file . Specificare il prefisso del nome file durante la scrittura di dati in più file, con questo modello: <fileNamePrefix>_00000.<fileExtension>. Se non specificato, il prefisso del nome file verrà generato automaticamente. Questa proprietà non si applica quando l'origine è l'archivio basato su file o l'opzione di partizione abilitata per l'archivio dati. |
< prefisso del nome file > | No | fileNamePrefix |