Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo illustra come configurare il formato Parquet nella pipeline di dati di Data Factory in Microsoft Fabric.
Funzionalità supportate
Il formato Parquet è supportato per le attività e i connettori seguenti come origine e destinazione.
| Categoria | Connettore/attività |
|---|---|
| Connettori supportati | Amazon S3 |
| Amazon S3 Compatibile | |
| Archiviazione BLOB di Azure | |
| Azure Data Lake Storage Gen1 | |
| Azure Data Lake Storage Gen2 | |
| File di Azure | |
| File system | |
| FTP | |
| Google Cloud Storage | |
| HTTP | |
| File Lakehouse | |
| Archiviazione in Oracle Cloud | |
| SFTP | |
| Attività supportata | Attività Copy (origine/destinazione) |
| Attività Lookup | |
| Attività GetMetadata | |
| Attività Delete |
Formato Parquet nell'attività di copia
Per configurare il formato Parquet, scegliere la connessione nell'origine o nella destinazione dell'attività di copia della pipeline di dati e quindi selezionare Parquet nell'elenco a discesa Formato file. Selezionare Impostazioni per configurare ulteriormente questo formato.
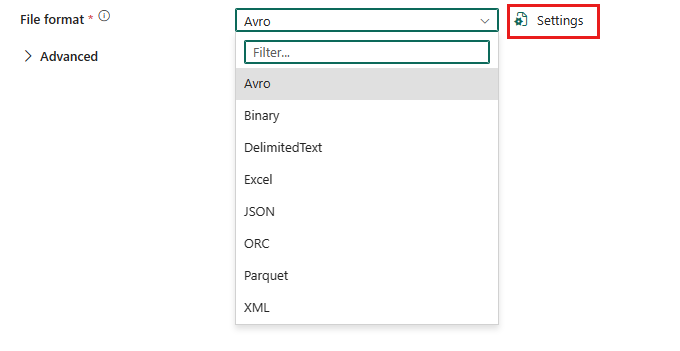
Formato Parquet come origine
Dopo aver selezionato Impostazioni nella sezione Formato file, nella finestra di dialogo Impostazioni formato file vengono visualizzate le seguenti proprietà.
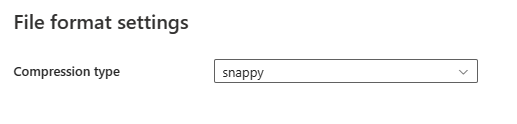
- Tipo di compressione: scegliere il codec di compressione usato per leggere i file Parquet nell'elenco a discesa. È possibile scegliere tra Nessuno, gzip (.gz), snappy, lzo, Brotli (.br), Zstandard, lz4, lz4frame, bzip2 (.bz2), or lz4hadoop.
Formato Parquet come destinazione
Dopo aver selezionato Impostazioni, vengono visualizzate le proprietà seguenti nella finestra di dialogo Impostazioni formato file popup.
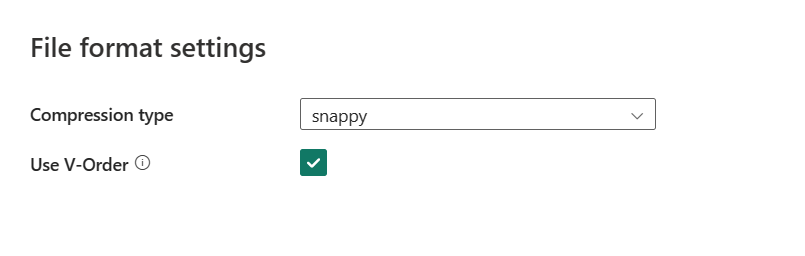
Tipo di compressione: scegliere il codec di compressione usato per scrivere i file Parquet nell'elenco a discesa. È possibile scegliere tra Nessuno, gzip (.gz), snappy, lzo, Brotli (.br), Zstandard, lz4, lz4frame, bzip2 (.bz2), or lz4hadoop.
Usare V-Order: abilitare un'ottimizzazione dell'ora di scrittura nel formato di file parquet. Per altre informazioni, vedere Ottimizzazione tabella Delta Lake e V-Order. È abilitata per impostazione predefinita.
In Impostazioni avanzate nella scheda Destinazione vengono visualizzate le proprietà correlate al formato Parquet seguenti.
- Numero massimo di righe per file: quando si scrivono dati in una cartella, è possibile scegliere di scrivere su più file e specificare il numero massimo di righe per file. Specificare il numero massimo di righe da scrivere per ogni file.
- Prefisso del nome file: Applicabile quando è configurato il numero massimo di righe per file. Specificare il prefisso del nome file durante la scrittura di dati in più file ha dato luogo a questo motivo:
<fileNamePrefix>_00000.<fileExtension>. Se non specificato, il prefisso del nome file è generato automaticamente. Questa proprietà non si applica quando l'origine è l'archivio basato su file o archivio dati abilitato per l'opzione di partizione.
Tabella riepilogativa
Parquet come origine
Le seguenti proprietà sono supportate nella sezione Origine dell'attività di copia quando si utilizza il formato Parquet.
| Nome | Descrizione | valore | Richiesto | Proprietà script JSON |
|---|---|---|---|---|
| Formato di file | Formato che si desidera usare. | Parquet | Sì | tipo (in datasetSettings):Parquet |
| Tipo di compressione | Codec di compressione usato per leggere file di testo. | Scegliere tra: Nessuno gzip (.gz) snappy lzo Brotli (.br) Zstandard lz4 lz4frame bzip2 (.bz2) lz4hadoop |
No | compressionCodec: gzip snappy lzo brotli zstd lz4 lz4frame bz2 lz4hadoop |
Parquet come destinazione
Le seguenti proprietà sono supportate nella sezione Destinazione dell'attività Copy quando si utilizza il formato Parquet.
| Nome | Descrizione | valore | Richiesto | Proprietà script JSON |
|---|---|---|---|---|
| Formato di file | Formato che si desidera usare. | Parquet | Sì | tipo (in datasetSettings):Parquet |
| Usare l’ordine V | Ottimizzazione dell'ora di scrittura nel formato di file parquet. | Selezionato o deselezionato | No | enableVertiParquet |
| Tipo di compressione | Codec di compressione usato per scrivere file Parquet. | Scegliere tra: Nessuno gzip (.gz) snappy lzo Brotli (.br) Zstandard lz4 lz4frame bzip2 (.bz2) lz4hadoop |
No | compressionCodec: gzip snappy lzo brotli zstd lz4 lz4frame bz2 lz4hadoop |
| Numero massimo di righe per file | Quando si scrivono dati in una cartella, è possibile scegliere di scrivere su più file e specificare il numero massimo di righe per file. Specificare il numero massimo di righe da scrivere per ogni file. | <numero massimo di righe per file> | No | maxRowsPerFile |
| Prefisso del nome file | Applicabile quando è configurato il numero massimo di righe per file. Specificare il prefisso del nome file durante la scrittura di dati in più file ha dato luogo a questo motivo: <fileNamePrefix>_00000.<fileExtension>. Se non specificato, il prefisso del nome file è generato automaticamente. Questa proprietà non si applica quando l'origine è l'archivio basato su file o archivio dati abilitato per l'opzione di partizione. |
<prefisso del nome file> | No | fileNamePrefix |