Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questa esercitazione presenta un esempio end-to-end di un workflow di Synapse Data Science in Microsoft Fabric. Questo scenario crea un modello di rilevamento delle frodi in linguaggio R, con algoritmi di Machine Learning sottoposti a training sui dati cronologici. Lo scenario usa quindi il modello per rilevare le transazioni fraudolente future.
La guida illustra questi passaggi:
- Installare librerie personalizzate
- Carica i dati
- Comprendere ed elaborare i dati con l'analisi esplorativa dei dati e mostrare l'uso della funzionalità Fabric Data Wrangler
- Eseguire il training di modelli di Machine Learning con LightGBM
- Usare i modelli di Machine Learning per assegnazione di punteggi e previsioni
Prerequisiti
Ottenere una sottoscrizione Microsoft Fabric. In alternativa, iscriversi per ottenere una versione di valutazione gratuita Microsoft Fabric.
Accedere a Microsoft Fabric.
Passare a Fabric usando il selettore di esperienza nell'angolo in basso a sinistra della home page.
Screenshot che mostra la selezione di Fabric nel menu di commutazione dell'esperienza.
- Se è necessario, creare un Microsoft Fabric lakehouse come descritto in Creare una lakehouse in Microsoft Fabric.
Segui con un quaderno
Per seguire la procedura in un notebook, sono disponibili queste opzioni:
- Aprire ed eseguire il notebook predefinito nell'esperienza di data science di Synapse
- Caricare il notebook da GitHub all'esperienza di data science di Synapse
Aprire il notebook predefinito
Il notebook di esempio Rilevamento delle frodi accompagna questa esercitazione.
Per aprire il notebook di esempio per questa esercitazione, seguire le istruzioni riportate in Preparare il sistema per le esercitazioni sull'analisi scientifica dei dati.
Assicurati di collegare una lakehouse al notebook prima di iniziare a eseguire il codice.
Importare il notebook da GitHub
Il notebook AIsample - R Fraud Detection.ipynb accompagna questo tutorial.
Per aprire il notebook di accompagnamento per questa esercitazione, seguire le istruzioni riportate in Preparare il sistema per le esercitazioni di data science per importare il notebook nell'area di lavoro.
Se si preferisce copiare e incollare il codice da questa pagina, è possibile creare un nuovo notebook.
Assicurarsi di collegare un lakehouse al notebook prima di iniziare a eseguire il codice.
Passaggio 1: installare librerie personalizzate
Per lo sviluppo di modelli di Machine Learning o l'analisi dei dati ad hoc, potrebbe essere necessario installare rapidamente una libreria personalizzata per la sessione di Apache Spark. Sono disponibili due opzioni per installare le librerie.
- Usare le risorse di installazione inline, ad esempio
install.packagesedevtools::install_version, per eseguire l'installazione solo nel notebook corrente. - In alternativa, è possibile creare un ambiente Fabric e installare librerie da origini pubbliche o caricarvi librerie personalizzate. L'amministratore dell'area di lavoro può quindi collegare l'ambiente come predefinito per l'area di lavoro. Tutte le librerie presenti nell'ambiente diventano quindi disponibili per l'uso in qualsiasi notebook e definizioni di job Spark nell'area di lavoro. Per altre informazioni sugli ambienti, visitare creare, configurare e usare un ambiente in Microsoft Fabric.
In questa esercitazione usare install.version() per installare la libreria imbalanced-learn:
# Install dependencies
devtools::install_version("bnlearn", version = "4.8")
# Install imbalance for SMOTE
devtools::install_version("imbalance", version = "1.0.2.1")
Il completamento di questo passaggio di installazione potrebbe richiedere da 8 a 10 minuti.
Passaggio 2: caricare i dati
Il set di dati di rilevamento delle frodi contiene le transazioni con carta di credito di settembre 2013, effettuate da titolari di carte europei nel corso di due giorni. Il set di dati contiene solo funzionalità numeriche, a causa di una trasformazione PCA (Principal Component Analysis) applicata alle funzionalità originali. Il PCA ha trasformato tutte le funzionalità ad eccezione di Time e Amount. Per proteggere la riservatezza, le funzionalità originali o più informazioni di base sul set di dati non sono disponibili.
Questi dettagli descrivono il set di dati:
- Le funzionalità
V1,V2,V3, ...,V28sono i componenti principali ottenuti con PCA - La funzionalità
Timecontiene i secondi trascorsi tra una transazione e la prima transazione nel set di dati - La funzionalità
Amountè l'importo della transazione. È possibile usare questa funzionalità per l'apprendimento sensibile ai costi dipendente dall'esempio - La colonna
Classè la variabile di risposta (destinazione). Ha il valore1per le frodi e0in caso contrario
Solo 492 transazioni, su un totale di 284.807 transazioni, sono fraudolente. Il set di dati è altamente sbilanciato, perché la classe di minoranza (fraudolenta) rappresenta solo circa lo 0,172% dei dati.
Questa tabella mostra un'anteprima dei dati creditcard.csv:
| Tempo | V1 | V2 | V3 | V4 | V5 | V6 | V7 | V8 | V9 | V10 | V11 | Versione 12 | V13 | V14 | V15 | V16 | V17 | V18 | V19 | V20 | V21 | V22 | V23 | V24 | V25 | V26 | V27 | V28 | Importo | Classe |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -1,3598071336738 | -0,0727811733098497 | 2,53634673796914 | 1,37815522427443 | -0,338320769942518 | 0,462387777762292 | 0,239598554061257 | 0,0986979012610507 | 0,363786969611213 | 0,0907941719789316 | -0,551599533260813 | -0,617800855762348 | -0,991389847235408 | -0,311169353699879 | 1,46817697209427 | -0,470400525259478 | 0,207971241929242 | 0,0257905801985591 | 0,403992960255733 | 0,251412098239705 | -0,018306777944153 | 0,277837575558899 | -0,110473910188767 | 0,0669280749146731 | 0,128539358273528 | -0,189114843888824 | 0,133558376740387 | -0,0210530534538215 | 149,62 | 0 |
| 0 | 1,19185711131486 | 0,26615071205963 | 0,16648011335321 | 0,448154078460911 | 0,0600176492822243 | -0,0823608088155687 | -0,0788029833323113 | 0,0851016549148104 | -0,255425128109186 | -0,166974414004614 | 1,61272666105479 | 1,06523531137287 | 0,48909501589608 | -0,143772296441519 | 0,635558093258208 | 0,463917041022171 | -0,114804663102346 | -0,183361270123994 | -0,145783041325259 | -0,0690831352230203 | -0,225775248033138 | -0,638671952771851 | 0,101288021253234 | -0,339846475529127 | 0,167170404418143 | 0,125894532368176 | -0,00898309914322813 | 0,0147241691924927 | 2,69 | 0 |
Scaricare il set di dati e caricarlo nel lakehouse
Definire questi parametri, in modo da poter usare questo notebook con set di dati diversi:
IS_CUSTOM_DATA <- FALSE # If TRUE, the dataset has to be uploaded manually
IS_SAMPLE <- FALSE # If TRUE, use only rows of data for training; otherwise, use all data
SAMPLE_ROWS <- 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_ROOT <- "/lakehouse/default"
DATA_FOLDER <- "Files/fraud-detection" # Folder with data files
DATA_FILE <- "creditcard.csv" # Data file name
Questo codice scarica una versione disponibile pubblicamente del set di dati e quindi archivia i dati in un Fabric lakehouse:
Importante
Assicurati di aggiungere un lakehouse al notebook prima di eseguirlo. In caso contrario, viene visualizzato un errore.
if (!IS_CUSTOM_DATA) {
# Download data files into a lakehouse if they don't exist
library(httr)
remote_url <- "https://synapseaisolutionsa.blob.core.windows.net/public/Credit_Card_Fraud_Detection"
fname <- "creditcard.csv"
download_path <- file.path(DATA_ROOT, DATA_FOLDER, "raw")
dir.create(download_path, showWarnings = FALSE, recursive = TRUE)
if (!file.exists(file.path(download_path, fname))) {
r <- GET(file.path(remote_url, fname), timeout(30))
writeBin(content(r, "raw"), file.path(download_path, fname))
}
message("Downloaded demo data files into lakehouse.")
}
Leggere i dati non elaborati di data dal lakehouse
Questo codice legge i dati grezzi dalla sezione File del lakehouse:
data_df <- read.csv(file.path(DATA_ROOT, DATA_FOLDER, "raw", DATA_FILE))
Passaggio 3: eseguire l'analisi esplorativa dei dati
Usare il comando display per visualizzare le statistiche di alto livello del set di dati:
display(as.DataFrame(data_df, numPartitions = 3L))
# Print dataset basic information
message(sprintf("records read: %d", nrow(data_df)))
message("Schema:")
str(data_df)
# If IS_SAMPLE is True, use only SAMPLE_ROWS of rows for training
if (IS_SAMPLE) {
data_df = sample_n(data_df, SAMPLE_ROWS)
}
Stampare la distribuzione del set di dati delle classi:
# The distribution of classes in the dataset
message(sprintf("No Frauds %.2f%% of the dataset\n", round(sum(data_df$Class == 0)/nrow(data_df) * 100, 2)))
message(sprintf("Frauds %.2f%% of the dataset\n", round(sum(data_df$Class == 1)/nrow(data_df) * 100, 2)))
Questa distribuzione di classi mostra che la maggior parte delle transazioni non è fraudolenta. Pertanto, la pre-elaborazione dei dati è necessaria prima dell'addestramento del modello, per evitare overfitting.
Visualizzare la distribuzione di transazioni fraudolente e non fradulente
Per visualizzare lo squilibrio della classe nel set di dati, visualizzare la distribuzione delle transazioni fraudolente e nonfradulenti con un tracciato:
library(ggplot2)
ggplot(data_df, aes(x = factor(Class), fill = factor(Class))) +
geom_bar(stat = "count") +
scale_x_discrete(labels = c("no fraud", "fraud")) +
ggtitle("Class Distributions \n (0: No Fraud || 1: Fraud)") +
theme(plot.title = element_text(size = 10))
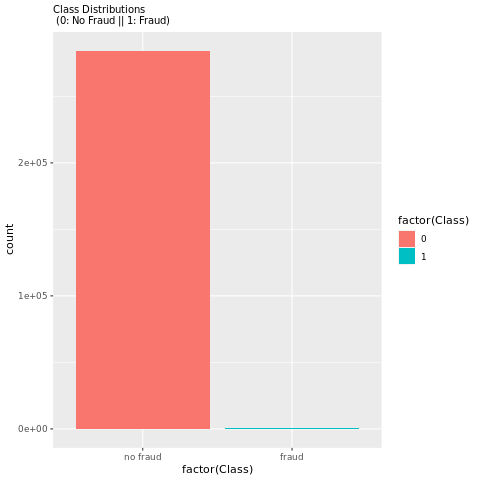
Il tracciato mostra chiaramente lo squilibrio del set di dati.
Visualizzare il riepilogo dei cinque numeri
Mostra il riepilogo a cinque numeri (punteggio minimo, primo quartile, mediano, terzo quartile e punteggio massimo) per l'importo della transazione, con tracciati box:
library(ggplot2)
library(dplyr)
ggplot(data_df, aes(x = as.factor(Class), y = Amount, fill = as.factor(Class))) +
geom_boxplot(outlier.shape = NA) +
scale_x_discrete(labels = c("no fraud", "fraud")) +
ggtitle("Boxplot without Outliers") +
coord_cartesian(ylim = quantile(data_df$Amount, c(0.05, 0.95)))
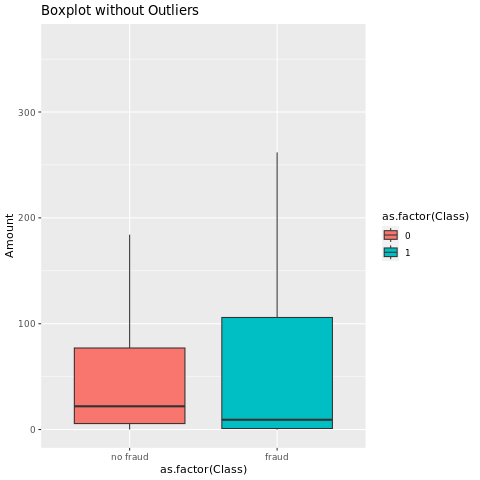
Per i dati altamente sbilanciati, i diagrammi a scatola potrebbero non fornire approfondimenti accurati. Tuttavia, è possibile risolvere prima il problema di squilibrio Class e quindi creare gli stessi tracciati per approfondimenti più accurati.
Passaggio 4: eseguire il training e valutare i modelli
Addestrare un modello LightGBM per classificare le transazioni fraudolente. In questo caso viene eseguito il training di un modello LightGBM sia nel set di dati sbilanciato che nel set di dati bilanciato. Quindi, confrontare le prestazioni di entrambi i modelli.
Preparare i set di dati di addestramento e di prova
Prima dell'addestramento, suddividere i dati nei set di addestramento e di test.
# Split the dataset into training and test datasets
set.seed(42)
train_sample_ids <- base::sample(seq_len(nrow(data_df)), size = floor(0.85 * nrow(data_df)))
train_df <- data_df[train_sample_ids, ]
test_df <- data_df[-train_sample_ids, ]
Applicare SMOTE al dataset di addestramento
La classificazione sbilanciata presenta un problema. Ci sono troppo pochi esempi di classe di minoranza perché un modello possa apprendere efficacemente il limite decisionale. La Tecnica di Sovracampionamento delle Minoranze Sintetiche (SMOTE) può gestire questo problema. SMOTE è l'approccio più diffuso per sintetizzare nuovi esempi per la classe di minoranza. È possibile accedere a SMOTE con la imbalance libreria installata nel passaggio 1.
Applicare SMOTE solo al set di dati di training anziché al set di dati di test. Quando si assegna un punteggio al modello con i dati di test, è necessaria un'approssimazione delle prestazioni del modello sui dati non visualizzati nell'ambiente di produzione. Per un'approssimazione valida, i dati di test si basano sulla distribuzione originale sbilanciata per rappresentare i dati di produzione il più possibile.
# Apply SMOTE to the training dataset
library(imbalance)
# Print the shape of the original (imbalanced) training dataset
train_y_categ <- train_df %>% select(Class) %>% table
message(
paste0(
"Original dataset shape ",
paste(names(train_y_categ), train_y_categ, sep = ": ", collapse = ", ")
)
)
# Resample the training dataset by using SMOTE
smote_train_df <- train_df %>%
mutate(Class = factor(Class)) %>%
oversample(ratio = 0.99, method = "SMOTE", classAttr = "Class") %>%
mutate(Class = as.integer(as.character(Class)))
# Print the shape of the resampled (balanced) training dataset
smote_train_y_categ <- smote_train_df %>% select(Class) %>% table
message(
paste0(
"Resampled dataset shape ",
paste(names(smote_train_y_categ), smote_train_y_categ, sep = ": ", collapse = ", ")
)
)
Addestrare il modello con LightGBM
Addestrare il modello LightGBM sia con il dataset sbilanciato che con il dataset bilanciato (tramite SMOTE). Confrontare quindi le loro prestazioni:
# Train LightGBM for both imbalanced and balanced datasets and define the evaluation metrics
library(lightgbm)
# Get the ID of the label column
label_col <- which(names(train_df) == "Class")
# Convert the test dataset for the model
test_mtx <- as.matrix(test_df)
test_x <- test_mtx[, -label_col]
test_y <- test_mtx[, label_col]
# Set up the parameters for training
params <- list(
objective = "binary",
learning_rate = 0.05,
first_metric_only = TRUE
)
# Train for the imbalanced dataset
message("Start training with imbalanced data:")
train_mtx <- as.matrix(train_df)
train_x <- train_mtx[, -label_col]
train_y <- train_mtx[, label_col]
train_data <- lgb.Dataset(train_x, label = train_y)
valid_data <- lgb.Dataset.create.valid(train_data, test_x, label = test_y)
model <- lgb.train(
data = train_data,
params = params,
eval = list("binary_logloss", "auc"),
valids = list(valid = valid_data),
nrounds = 300L
)
# Train for the balanced (via SMOTE) dataset
message("\n\nStart training with balanced data:")
smote_train_mtx <- as.matrix(smote_train_df)
smote_train_x <- smote_train_mtx[, -label_col]
smote_train_y <- smote_train_mtx[, label_col]
smote_train_data <- lgb.Dataset(smote_train_x, label = smote_train_y)
smote_valid_data <- lgb.Dataset.create.valid(smote_train_data, test_x, label = test_y)
smote_model <- lgb.train(
data = smote_train_data,
params = params,
eval = list("binary_logloss", "auc"),
valids = list(valid = smote_valid_data),
nrounds = 300L
)
Determinare l'importanza di funzionalità
Determinare l'importanza delle caratteristiche per il modello addestrato sul set di dati sbilanciato.
imp <- lgb.importance(model, percentage = TRUE)
ggplot(imp, aes(x = Frequency, y = reorder(Feature, Frequency), fill = Frequency)) +
scale_fill_gradient(low="steelblue", high="tomato") +
geom_bar(stat = "identity") +
geom_text(aes(label = sprintf("%.4f", Frequency)), hjust = -0.1) +
theme(axis.text.x = element_text(angle = 90)) +
xlim(0, max(imp$Frequency) * 1.1)
Schermata di un grafico a barre che mostra l'importanza delle caratteristiche per il modello non bilanciato.
Per il modello addestrato sul set di dati bilanciato (tramite SMOTE), calcolare l'importanza delle caratteristiche.
smote_imp <- lgb.importance(smote_model, percentage = TRUE)
ggplot(smote_imp, aes(x = Frequency, y = reorder(Feature, Frequency), fill = Frequency)) +
geom_bar(stat = "identity") +
scale_fill_gradient(low="steelblue", high="tomato") +
geom_text(aes(label = sprintf("%.4f", Frequency)), hjust = -0.1) +
theme(axis.text.x = element_text(angle = 90)) +
xlim(0, max(smote_imp$Frequency) * 1.1)
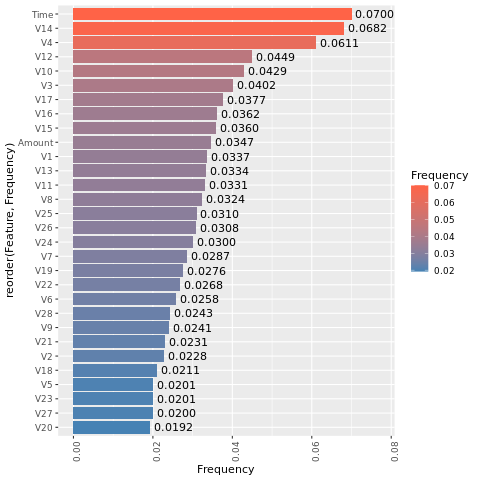
Un confronto di questi tracciati mostra chiaramente che i set di dati di training bilanciati e sbilanciati presentano notevoli differenze di importanza delle caratteristiche.
Valutare i modelli
Valutare i due modelli sottoposti a training:
-
modeladdestrato su dati grezzi e sbilanciati -
smote_modeladdestrato su dati bilanciati
preds <- predict(model, test_mtx[, -label_col])
smote_preds <- predict(smote_model, test_mtx[, -label_col])
Valutare le prestazioni del modello con una matrice di confusione
Una matrice di confusione visualizza il numero di
- veri positivi (TP)
- veri negativi (TN)
- falsi positivi (FP)
- falsi negativi (FN)
che un modello produce quando viene ottenuto un punteggio con i dati di test. Per la classificazione binaria, il modello restituisce una matrice di confusione 2x2. Per la classificazione multiclasse, il modello restituisce una matrice di confusione nxn, dove n è il numero di classi.
Usare una matrice di confusione per riepilogare le prestazioni dei modelli di Machine Learning sottoposti a training sui dati di test:
plot_cm <- function(preds, refs, title) { library(caret) cm <- confusionMatrix(factor(refs), factor(preds)) cm_table <- as.data.frame(cm$table) cm_table$Prediction <- factor(cm_table$Prediction, levels=rev(levels(cm_table$Prediction))) ggplot(cm_table, aes(Reference, Prediction, fill = Freq)) + geom_tile() + geom_text(aes(label = Freq)) + scale_fill_gradient(low = "white", high = "steelblue", trans = "log") + labs(x = "Prediction", y = "Reference", title = title) + scale_x_discrete(labels=c("0", "1")) + scale_y_discrete(labels=c("1", "0")) + coord_equal() + theme(legend.position = "none") }Traccia la matrice di confusione per il modello addestrato su un dataset sbilanciato.
# The value of the prediction indicates the probability that a transaction is fraud # Use 0.5 as the threshold for fraud/no-fraud transactions plot_cm(ifelse(preds > 0.5, 1, 0), test_df$Class, "Confusion Matrix (Imbalanced dataset)")
Traccia la matrice di confusione per il modello allenato sul set di dati bilanciato.
plot_cm(ifelse(smote_preds > 0.5, 1, 0), test_df$Class, "Confusion Matrix (Balanced dataset)")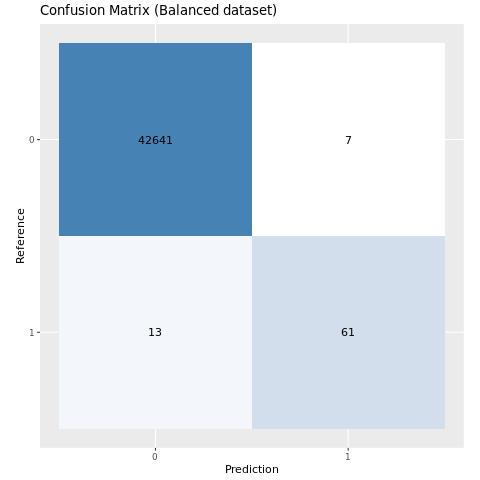
Valutare le prestazioni del modello con misure AUC-ROC e AUPRC
La misura Area sotto la caratteristica operativa del ricevitore della curva (AUC-ROC) valuta le prestazioni dei classificatori binari. Il grafico AUC-ROC visualizza il compromesso tra il tasso di veri positivi (TPR) e il tasso di falsi positivi (FPR).
In alcuni casi, è più appropriato valutare il classificatore in base alla misura Area Under the Precision-Recall Curve (AUPRC). La curva AUPRC combina questi tassi:
- La precisione o valore predittivo positivo (PPV)
- Il richiamo o TPR
# Use the PRROC package to help calculate and plot AUC-ROC and AUPRC
install.packages("PRROC", quiet = TRUE)
library(PRROC)
Calcolare le metriche AUC-ROC e AUPRC
Calcolare e tracciare le metriche AUC-ROC e AUPRC per i due modelli.
Set di dati sbilanciato
Calcolare le previsioni:
fg <- preds[test_df$Class == 1]
bg <- preds[test_df$Class == 0]
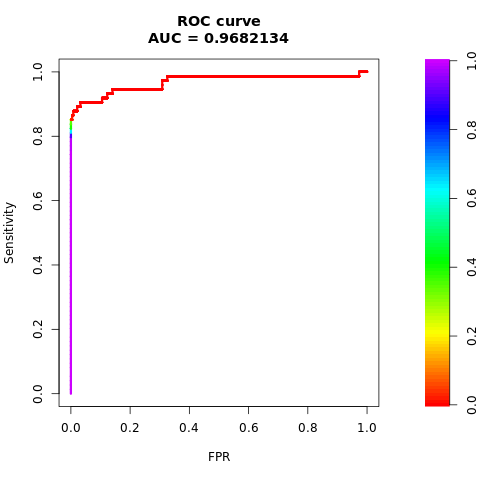
Stampare l'area sotto la curva AUC-ROC:
# Compute AUC-ROC
roc <- roc.curve(scores.class0 = fg, scores.class1 = bg, curve = TRUE)
print(roc)
Tracciare la curva AUC-ROC:
# Plot AUC-ROC
plot(roc)
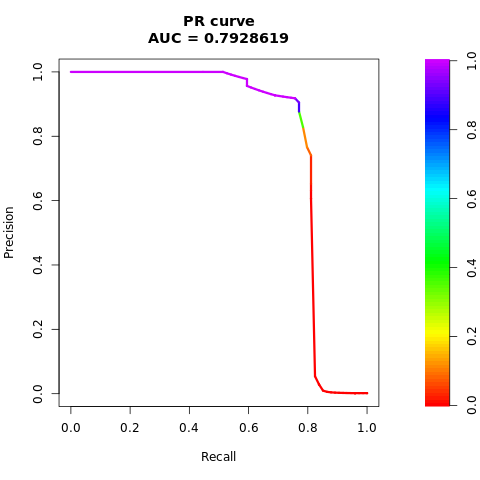
Stampare la curva AUPRC:
# Compute AUPRC
pr <- pr.curve(scores.class0 = fg, scores.class1 = bg, curve = TRUE)
print(pr)
Tracciare la curva AUPRC:
# Plot AUPRC
plot(pr)
Set di dati bilanciato (tramite SMOTE)
Calcolare le previsioni:
smote_fg <- smote_preds[test_df$Class == 1]
smote_bg <- smote_preds[test_df$Class == 0]
Stampare la curva AUC-ROC:
# Compute AUC-ROC
smote_roc <- roc.curve(scores.class0 = smote_fg, scores.class1 = smote_bg, curve = TRUE)
print(smote_roc)
Tracciare la curva AUC-ROC:
# Plot AUC-ROC
plot(smote_roc)
Stampare la curva AUPRC:
# Compute AUPRC
smote_pr <- pr.curve(scores.class0 = smote_fg, scores.class1 = smote_bg, curve = TRUE)
print(smote_pr)
Tracciare la curva AUPRC:
# Plot AUPRC
plot(smote_pr)
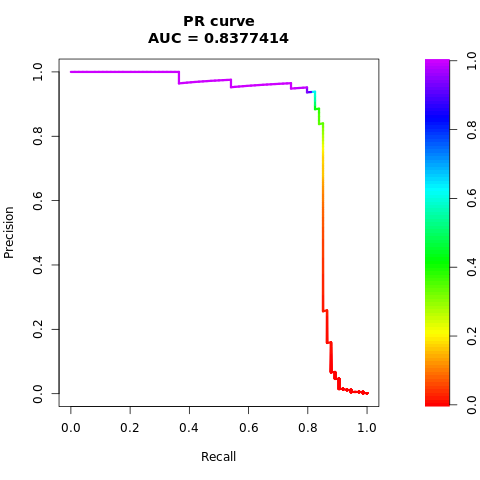
Le cifre precedenti mostrano chiaramente che il modello sottoposto a training sul set di dati bilanciato supera le prestazioni del modello sottoposto a training sul set di dati sbilanciato, sia per i punteggi AUC-ROC che AUPRC. Questo risultato suggerisce che SMOTE migliora efficacemente le prestazioni del modello quando si lavora con dati altamente sbilanciati.